




PLAY3R
Members
-
Joined
-
Last visited
-
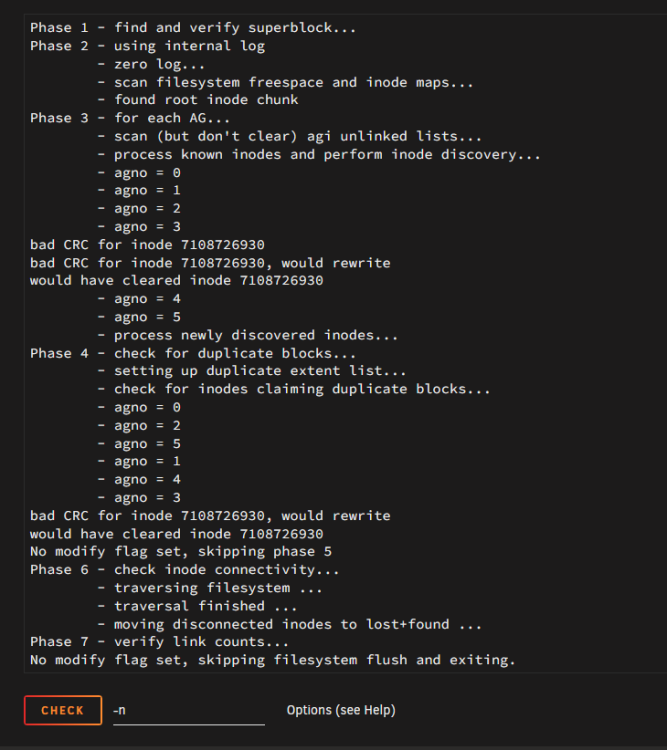
Thought so, but wasn't sure. Below is the output without options, and below that, it ran again, from what i see, it fixed it? Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 bad CRC for inode 7108726930 bad CRC for inode 7108726930, will rewrite cleared inode 7108726930 - agno = 4 - agno = 5 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 5 - agno = 2 - agno = 3 - agno = 4 clearing reflink flag on inodes when possible Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... done ------------------------------------------------------------------------------------------------------------------------------------------------------------ Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 4 - agno = 1 - agno = 3 - agno = 2 - agno = 5 Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... done
-
Thanks for the reply, finally have time to look into this. All my "critical" data is backed up and the drive removed, checked disk 1 file system, please see below. I know two of the disks have CRC errors (one per drive) but they have been like that for months without issue, this locking up started almost a month ago. It has locked up 2 more times since my post. I have also done some searching and not found how to use custom MAC addresses with ipvlan, can you explain more please.
-
Running the check now, I use macvlan because i use custom MACs on some docker containers, if i switch to ipvlan, i cannot use custom MACs, i'll try that as a second option Thanks so far though!
-
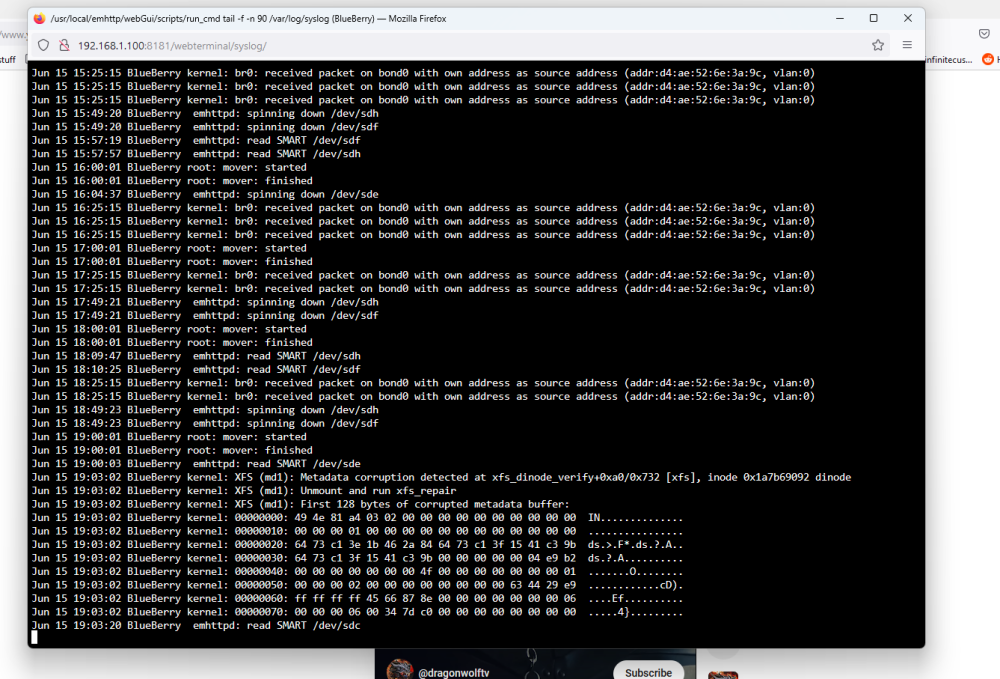
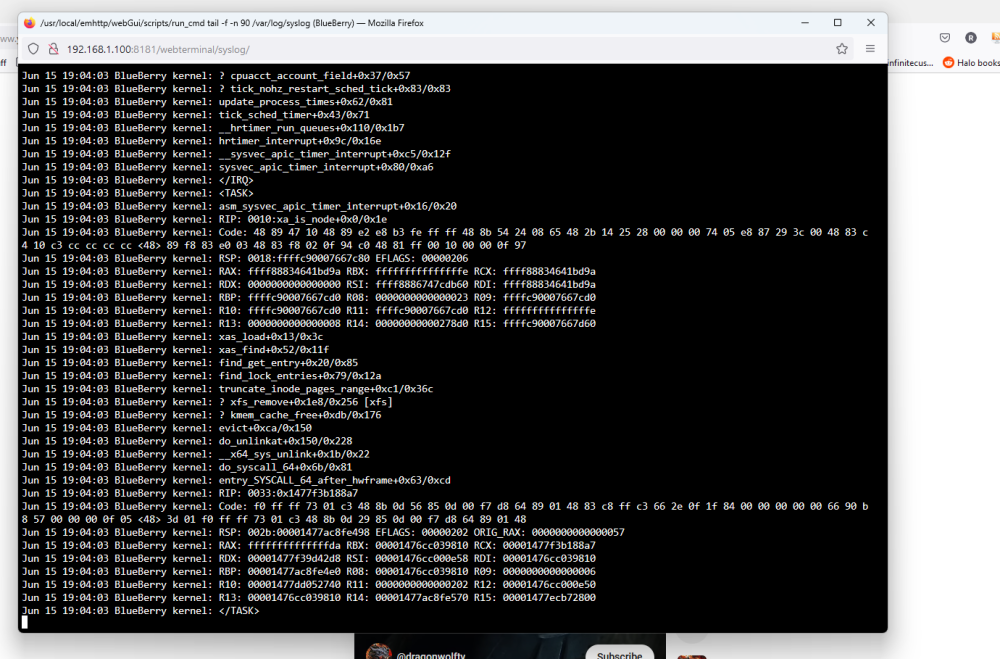
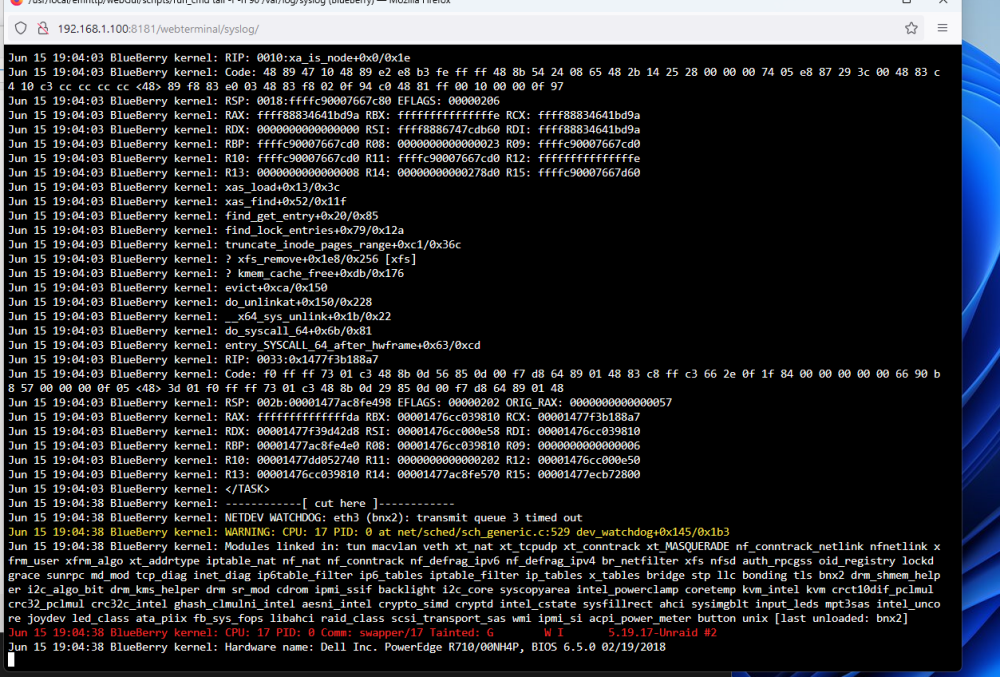
Hey all. Been having an issue off and on for a bit where the server will get into a "loop" and i have to cold boot it, 3 times so far, not happy doing this, but when i have no access at all ( even the GUI on the servers VGA is frozen, there is not much more to do ) Happened again tonight, with a twist, it came out of it. after failing to figure it out the first 2 times, i left the Syslog window open, and watched it till it happened again, tonight is when it decided to "act up". You can always tell, because the server starts acting like its under some load and the fans kick in to cool it all down. After about 3-4 min, everything came back on its own, shares, GUI, Ping etc. so i quickly downloaded the Diagnostics and came here, i also have screenshots of the log as this was happening, if it helps. Anymore information, please ask' Edit #1: Only errors Fix Common Problems is finding are "macvlan call traces found" can this be the cause? blueberry-diagnostics-20230615-1907.zip
-
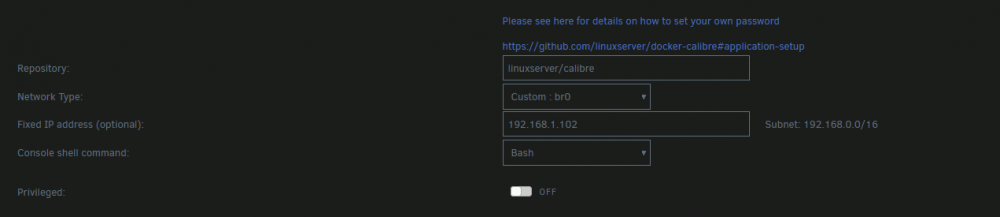
Hello All!!! If anyone is having an issue not being able to connect their e-reader to Calbire and it just gives a 172.x.x.x IP. Change the Network Type to custom and get it a set IP. After, you will see the IP, and be able to connect with the default settings.
-
Yep, its always something i forget. Thanks, its running now
-
Help! What am I doing wrong? Thanks fetch http://dl-cdn.alpinelinux.org/alpine/v3.12/main/x86_64/APKINDEX.tar.gz fetch http://dl-cdn.alpinelinux.org/alpine/v3.12/community/x86_64/APKINDEX.tar.gz v3.12.3-119-gadcf08925b [http://dl-cdn.alpinelinux.org/alpine/v3.12/main] v3.12.3-114-g726dc65b43 [http://dl-cdn.alpinelinux.org/alpine/v3.12/community] OK: 12751 distinct packages available OK: 58 MiB in 36 packages OK: 58 MiB in 36 packages 2021-02-21T02:12:38Z I! Starting Telegraf 1.17.2 2021-02-21T02:12:38Z I! Using config file: /etc/telegraf/telegraf.conf 2021-02-21T02:12:38Z E! [telegraf] Error running agent: Error loading config file /etc/telegraf/telegraf.conf: plugin inputs.smart: line 2329: configuration specified the fields ["endpoint"], but they weren't used telegraf.conf
-
Ah, well, makes sense. Thanks
-
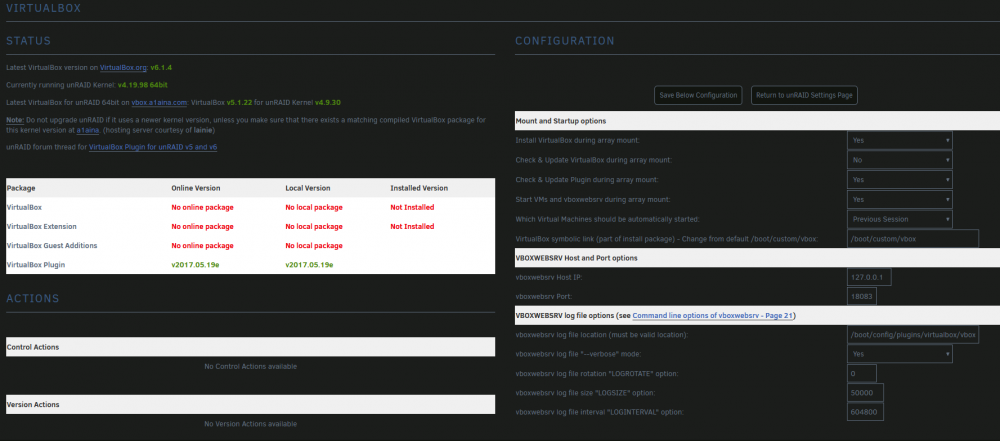
Ok, now getting this Exception Object ( [message:protected] => Could not connect to host (http://192.168.1.100:18083/) [string:Exception:private] => [code:protected] => 64 [file:protected] => /web/VB/endpoints/api.php [line:protected] => 134 [trace:Exception:private] => Array ( ) [previous:Exception:private] => )
-
What step am i missing?
-
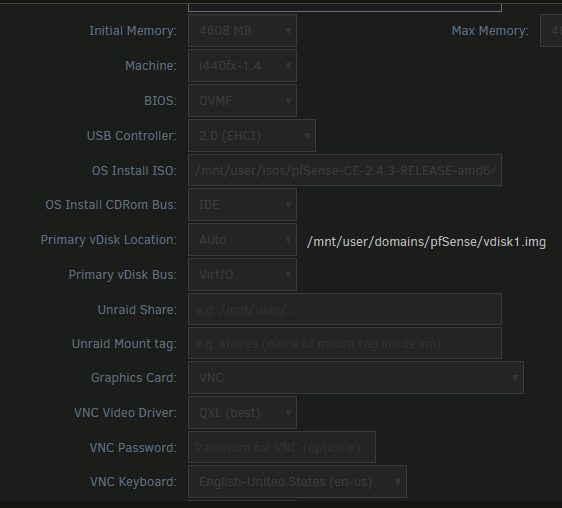
I feel silly, read your logs and you can fix anything. I fixed this and now am using pfSense with no issues (and two ports) after creating the VM with Machine: i440fx-1.4
-
Hello all!! So, using the below, <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x02' slot='0x00' function='0x0'/> </source> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x02' slot='0x00' function='0x1'/> </source> </hostdev> and stubbing out the two ports i wish to use, I can see both ports that i wish to use while creating a VM. However, pfSense is only seeing one port. I am confused and have searched quite a bit, Sorry if this has been covered somewhere else. my GoogleFu has failed me today. Please let know know another information that is needed. Thanks!
.png.e61937ce35bcbd29c71a2c8cffa7c3e5.png)
.png.9d7d0e5f71e834503acf0eb787935914.png)
-
I get the same error, even if i have "strict_protocol_version_checking = false" un-commented out in the config Logs don't show any useful info, that i can see







.png.e61937ce35bcbd29c71a2c8cffa7c3e5.png)
.png.9d7d0e5f71e834503acf0eb787935914.png)