




cholzer
Members
-
Joined
-
Last visited
Everything posted by cholzer
-
I think I figured it out. Goal: Short Version: Use ssh to have UnassignedDevices mount/umount a specific disk and create an SMB/CIFS share for that disk. Long Version - my usecase: (pre-backup script) a Server on my network connects to UNRAID via SSH and instructs UD to mount a specific disk which also creates the share this server then runs a backup job which has this UD share as target (post-backup script) once the backup is done the server connects to UNRAID via SSH and instructs UD to unmount this specific disk which also removes the share Step-by-step guide: I assume that your disk already has a single partition Connect the disk to your Unraid system go to the settings of the disk, enable the 'share' setting mount the disk, make sure that the share is created and can be accessed note the disk id (sd* i.e. sdg) next to the drive serial in the UD GUI ssh into the UNRAID server or open the terminal in the webgui run "ls -ahlp /dev/disk/by-uuid" to list all drives by their UUID (look for the sd* to find your disk's UUID) now you can use these 2 commands to mount/unmount this specific disk via SSH or a script on your UNRAID machine. /usr/local/sbin/rc.unassigned mount '/dev/disk/by-uuid/THEUUIDOFYOURDISK' /usr/local/sbin/rc.unassigned umount '/dev/disk/by-uuid/THEUUIDOFYOURDISK' Hope this might help someone who finds himself in the same situation as I was in.
-
Is it possible to ssh into unraid and then remotely call UD to unmount or mount a disk? I did take a look at the scripts in the first post but these dont seem to hold the answer. 😅 Reason for my question is that as it truns out I run into several issues with the SMB share creation/destruction when I remotely SSH into unraid and then just mount/unmount the disk. These problems do not exists when I use the "mount" button in the UD gui, so I guess the solution would be to call UD remotelly via SSH and let it do the mount/umount. But how? Thanks in advance!
-
I noticed that it can sometimes take 60 seconds or more for the SMB share to get accessible after the disk has been mounted. Is that.... normal? 😅
-
Thx! I found a way to have Veeam Backup & Replication remotely mount the disk via ssh before the backup starts then then unmount it once the backup is done.
-
thx! Ideally I would have Veeam Backup & Replication SSH into unraid, ensure that the disk is mounted before the backup and unmount it when its done. But I need to see if I can execute that pre/post backup job. (ESXi is on a different machine - Unraid is 'only' used to store onsite backups and as 'provider' for the offsite backup media) As a quick solution I have now created a userscript to unmount the disk - scheduled to run ~2hours after the backup task is always finished. This worked nicely in my test! I assume there is no way how I could have a cron job run sometime at night to let Unraid/Linux forget that a disk was safely removed - in case that this would happen at some point - so that a reboot isnt required.
-
Thank you! I will reboot and see what happens. Is there a way to have a cron job unmount the disk? I'd like to have this offsite-backup as "end-user" proof as possible. Which means I do not want to unmount it manually every Monday evening before it gets unplugged. 😅
-
I'm building a new NAS and I have a reeeeeeally funky issue. Unraid 6.9.2 The Array consists out of 3x 4TB Seagate Ironwolf's and a 120GB Plextor SSD Cache. But that has nothing to do with the funky stuff. I have 2x 2TB Seagate Compute drives, these are used for off-site backups. The usecase is this: Monday morning 2TB Seagate Compute "A" is plugged in, auto mounted and SMB shared by UD later that day a backup is executed on a different system which stores the backup on that disk/share Monday night 2TB Seagate Compute "A" is disconnected and stored off site Next week on Monday morning 2TB Seagate Compute "B" is plugged in, auto mounted and SMB shared shared by UD later that day a backup is executed on a different system which stores the backup on that disk/share Monday night 2TB Seagate Compute "B" is disconnected and stored off site etc..... Now here is the funky part: I connected 2TB Seagate Compute "A", configured auto mount and auto share in UD disconnected 2TB Seagate Compute "A" I connected 2TB Seagate Compute "B", configured auto mount and auto share in UD disconnected 2TB Seagate Compute "B" Whenever I now connect either 2TB Seagate Compute "A" or "B" I get this greyed out "ARRAY" button in UD and the disk is not shared 😬🙃🤪 I connected the drives to a different machine and deleted the partition. Yet they still show up with that greyed out "ARRAY" button in UD. Below is the log taken when I connected one of the drives while it had no partition anymore. It complains about a mismatch in line 4 as if it does not like that different disks get connected to that sata port. Mar 31 13:56:32 NAS kernel: ata6: SATA link down (SStatus 0 SControl 300) Mar 31 13:56:42 NAS kernel: ata6: link is slow to respond, please be patient (ready=0) Mar 31 13:56:44 NAS kernel: ata6: SATA link up 3.0 Gbps (SStatus 123 SControl 300) Mar 31 13:56:44 NAS kernel: ata6.00: serial number mismatch ' WFL3RRLV' != ' WFL2P4XZ' Mar 31 13:56:44 NAS kernel: ata6.00: revalidation failed (errno=-19) Mar 31 13:56:44 NAS kernel: ata6: limiting SATA link speed to 1.5 Gbps Mar 31 13:56:49 NAS kernel: ata6: SATA link up 1.5 Gbps (SStatus 113 SControl 310) Mar 31 13:56:49 NAS kernel: ata6.00: serial number mismatch ' WFL3RRLV' != ' WFL2P4XZ' Mar 31 13:56:49 NAS kernel: ata6.00: revalidation failed (errno=-19) Mar 31 13:56:49 NAS kernel: ata6.00: disabled Mar 31 13:56:55 NAS kernel: ata6: SATA link up 3.0 Gbps (SStatus 123 SControl 300) Mar 31 13:56:55 NAS kernel: ACPI BIOS Error (bug): Could not resolve symbol [\_SB.PCI0.SAT0.SPT5._GTF.DSSP], AE_NOT_FOUND (20200925/psargs-330) Mar 31 13:56:55 NAS kernel: ACPI Error: Aborting method \_SB.PCI0.SAT0.SPT5._GTF due to previous error (AE_NOT_FOUND) (20200925/psparse-529) Mar 31 13:56:55 NAS kernel: ata6.00: ATA-10: ST2000DM008-2FR102, WFL2P4XZ, 0001, max UDMA/133 Mar 31 13:56:55 NAS kernel: ata6.00: 3907029168 sectors, multi 16: LBA48 NCQ (depth 32), AA Mar 31 13:56:55 NAS kernel: ACPI BIOS Error (bug): Could not resolve symbol [\_SB.PCI0.SAT0.SPT5._GTF.DSSP], AE_NOT_FOUND (20200925/psargs-330) Mar 31 13:56:55 NAS kernel: ACPI Error: Aborting method \_SB.PCI0.SAT0.SPT5._GTF due to previous error (AE_NOT_FOUND) (20200925/psparse-529) Mar 31 13:56:55 NAS kernel: ata6.00: configured for UDMA/133 Mar 31 13:56:55 NAS kernel: ata6.00: detaching (SCSI 7:0:0:0) Mar 31 13:56:55 NAS kernel: sd 7:0:0:0: [sdl] Synchronizing SCSI cache Mar 31 13:56:55 NAS kernel: sd 7:0:0:0: [sdl] Stopping disk Mar 31 13:56:55 NAS unassigned.devices: Reload: A udev 'remove disk' initiated a reload of udev info. Mar 31 13:56:55 NAS unassigned.devices: Updating udev information... Mar 31 13:56:55 NAS unassigned.devices: Udev: Update udev info for /dev/disk/by-id/ata-ST2000DM008-2FR102_WFL3RRLV. Mar 31 13:56:55 NAS unassigned.devices: Udev: Update udev info for /dev/disk/by-id/wwn-0x5000c500cf867c17. Mar 31 13:56:55 NAS kernel: scsi 7:0:0:0: Direct-Access ATA ST2000DM008-2FR1 0001 PQ: 0 ANSI: 5 Mar 31 13:56:55 NAS kernel: sd 7:0:0:0: Attached scsi generic sg6 type 0 Mar 31 13:56:55 NAS kernel: sd 7:0:0:0: [sdl] 3907029168 512-byte logical blocks: (2.00 TB/1.82 TiB) Mar 31 13:56:55 NAS kernel: sd 7:0:0:0: [sdl] 4096-byte physical blocks Mar 31 13:56:55 NAS kernel: sd 7:0:0:0: [sdl] Write Protect is off Mar 31 13:56:55 NAS kernel: sd 7:0:0:0: [sdl] Mode Sense: 00 3a 00 00 Mar 31 13:56:55 NAS kernel: sd 7:0:0:0: [sdl] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA Mar 31 13:56:56 NAS kernel: sdl: Mar 31 13:56:56 NAS kernel: sd 7:0:0:0: [sdl] Attached SCSI disk Mar 31 13:56:56 NAS unassigned.devices: Hotplug: A udev 'add disk' initiated a Hotplug event. Mar 31 13:56:56 NAS unassigned.devices: Updating udev information... Mar 31 13:56:56 NAS unassigned.devices: Udev: Update udev info for /dev/disk/by-id/ata-ST2000DM008-2FR102_WFL2P4XZ. Mar 31 13:56:56 NAS unassigned.devices: Udev: Update udev info for /dev/disk/by-id/wwn-0x5000c500cf6a8b34. Mar 31 13:56:59 NAS unassigned.devices: Processing Hotplug event... but even when I connect one of the drives to a different SATA port now it still shows up with that greyed out "array" button and shows that "mismatch" error in the log. Mar 31 14:01:33 NAS kernel: ata3: SATA link up 3.0 Gbps (SStatus 123 SControl 300) Mar 31 14:01:33 NAS kernel: ata3.00: serial number mismatch ' WFL2P4XZ' != ' WFL3RRLV' Mar 31 14:01:33 NAS kernel: ata3.00: revalidation failed (errno=-19) EDIT! Now it gets even funky'er!!! 🤣 If I do the exact same thing with these 2 disks: HGST_HDS724040ALE640 dev3HGST_HDS724040ALE640 Then it works just fine! Only with the 2 ST2000DM008-2FR102 it does not work and I run into this greyed out "ARRAY" button.

-
I just stumbled over this thread. Please expose the ChatID in the Telegram settings area! That would make setting this up so much easier!
-
The Telegram agent is extremely useful! However if you'd like to have the agent send messages to a telegram group then the agent needs to know the ChatID of that telegram group. Currently you have to use the terminal for that. cd /boot/config/plugins/dynamix/telegram nano chatid Please expose a 'chatid' field in the Configuration of the Telegram Agent to make this process more user friendly. @limetech
-
Hey everyone! I just got the Telegram Agent to work. However we are 2 admins and we'd both like to get notifications via telegram from UNRAID. Is it possible to have the telegram Agent send messages to a telegram group? I could not figure it out. 😅 Thanks in advance!
-
How can this still be am issue? I am about to setup an UnRAID machine for a friend and I ran into the exact same problem that this garbage USB creator does not detect ANY of the 10 different drives I tried. The manual method created a working USB drive that this UnRAID machine now runs on (so my sandisk usb drive is okay) but c'mon @limetech !!! Fix that USB creator!!!! This is a HORRIBLE first impression for anyone who considers trying UnRAID!!!
-
Already changed the HBA and all cables. I still get this error in the log several times throughout the day. I do not recall getting that error prior to the upgrade to 6.9.2 RC2 What does it even mean? What is this task it tries to abort? *edit* Recently replaced the LSI 3008 with a LSI 2008 (including the cables), this error message still shows up. Jan 18 07:23:17 NAS kernel: sd 3:0:4:0: attempting task abort!scmd(0x000000006d823564), outstanding for 15380 ms & timeout 15000 ms Jan 18 07:23:17 NAS kernel: sd 3:0:4:0: [sdf] tag#789 CDB: opcode=0x85 85 06 20 00 00 00 00 00 00 00 00 00 00 40 e5 00 Jan 18 07:23:17 NAS kernel: scsi target3:0:4: handle(0x000d), sas_address(0x4433221106000000), phy(6) Jan 18 07:23:17 NAS kernel: scsi target3:0:4: enclosure logical id(0x590b11c05321f300), slot(5) Jan 18 07:23:20 NAS kernel: sd 3:0:4:0: task abort: SUCCESS scmd(0x000000006d823564) Jan 18 07:23:20 NAS kernel: sd 3:0:4:0: Power-on or device reset occurred Jan 18 07:23:20 NAS emhttpd: read SMART /dev/sde Jan 18 07:23:20 NAS emhttpd: read SMART /dev/sdf Jan 18 07:23:37 NAS kernel: sd 3:0:5:0: attempting task abort!scmd(0x00000000191fe81f), outstanding for 15232 ms & timeout 15000 ms Jan 18 07:23:37 NAS kernel: sd 3:0:5:0: [sdg] tag#787 CDB: opcode=0x85 85 06 20 00 00 00 00 00 00 00 00 00 00 40 e5 00 Jan 18 07:23:37 NAS kernel: scsi target3:0:5: handle(0x000e), sas_address(0x4433221105000000), phy(5) Jan 18 07:23:37 NAS kernel: scsi target3:0:5: enclosure logical id(0x590b11c05321f300), slot(6) Jan 18 07:23:39 NAS kernel: sd 3:0:5:0: task abort: SUCCESS scmd(0x00000000191fe81f) Jan 18 07:23:39 NAS emhttpd: read SMART /dev/sdg Jan 18 07:23:39 NAS emhttpd: read SMART /dev/sdb Jan 18 07:36:08 NAS kernel: sd 3:0:4:0: Power-on or device reset occurred nas-diagnostics-20210118-0830.zip
-
The same 2 disks (sdb is the parity disk) seem to get spun up to read SMART (?) throughout the day. Time is AM, everyone was asleep during that time, no one accessed the NAS. There are no VM's and no dockers in Unraid, I use it as a "simple" NAS. Fusion-MPT 12GSAS SAS3008 PCI-Express in IT Mode The following plugins are installed: CA User Scripts Community Applications Dynamix Cache Dirs Dynamix Schedules Dynamix SSD Trim openVMTools_compiled Recycle Bin Tips and Tweaks Unassigned Devices Unassigned Devices Plus (Addon) Jan 12 03:02:13 NAS emhttpd: read SMART /dev/sde Jan 12 03:02:32 NAS emhttpd: read SMART /dev/sdd Jan 12 04:01:19 NAS emhttpd: spinning down /dev/sdd Jan 12 04:01:21 NAS emhttpd: spinning down /dev/sde Jan 12 04:07:29 NAS emhttpd: read SMART /dev/sde Jan 12 04:27:05 NAS emhttpd: read SMART /dev/sdd Jan 12 05:31:27 NAS emhttpd: spinning down /dev/sdd Jan 12 05:31:27 NAS emhttpd: spinning down /dev/sde
-
Generally speaking disks spin up / down fine for me in RC2, but there is one usecase where I have noticed unnecessary spin ups. Steps to reproduce: 1. create a share which is set to "cache only" 2. wait for unraid to spin down all disks 3. access that "cache only" share (in my case from a Windows 10 PC where it is mapped as a network drive) 4. copy a file to that "cache only" share (while all other array disks are spun down!) Expected behaviour: file gets copied to the cache drive, all array disks stay spun down Result: (some) disks spin up, log shows "read smart" entries for those array disks Jan 6 05:53:07 NAS emhttpd: read SMART /dev/sde Jan 6 05:53:26 NAS emhttpd: read SMART /dev/sdd
-
Thank you! I was only looking at the log next to the disk in UD which did not show anything. Looking at the correct log I guess there is indeed something wrong with that partition. I did shutdown the PC as usual though before I removed it. Well... lets investigate. Dec 30 22:17:36 NAS unassigned.devices: Mount warning: The disk contains an unclean file system (0, 0). Metadata kept in Windows cache, refused to mount. Falling back to read-only mount because the NTFS partition is in an unsafe state. Please resume and shutdown Windows fully (no hibernation or fast restarting.)
-
RC2 with 2020.12.19 For a long time I used UD to share a 6TB drive, which was previosuly used in a Windows PC and only contains a single NTFS partition. That drive/smb share still works nicely! 👍 However today I added a 512GB SSD (using the same settings in UD as the 6TB drive). When I access that share from a Windows PC it tells me that it is "write proteced"!?!? Even though "read only" is not enabled in UD. The settings are identical to the 6TB drive and the same SMB user is used as for the 6TB drive. Another thing I just noticed is that the "Change Disk UUID" dropdown list in the UD settings is empty.

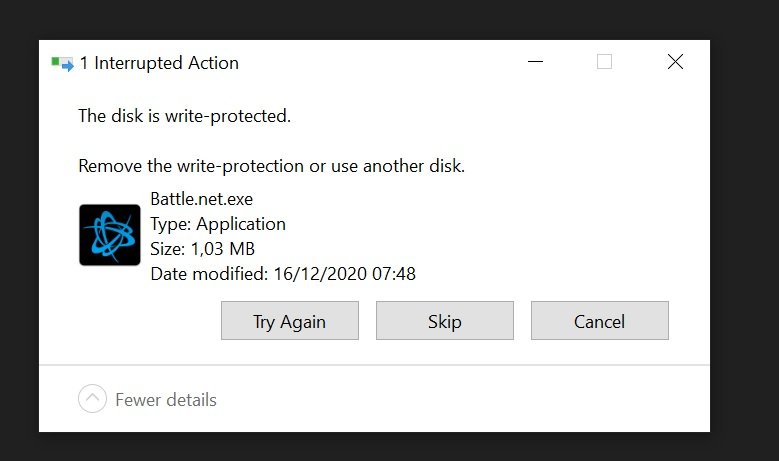
-
That did not happen either.
-
Thx I just read your reply in the 6.9RC1 thread! But I guess I will wait for RC2 which fixes some spinup/down issues remaining in RC1?
-
So I just need to upgrade to 6.9RC1 to get that functionality. Guess I will check the thread about known issues in the RC and if it is worth to wait for the final. Thank you! Good thing I RTFM
-
Oh, so the current "Spin down disks?" setting in the Unassigned Devices configuration will only start to work with 6.9 RC1?
-
Cache Plugin Seems like the "include folders" feature does not support folders that use a & Fotoalbum Anita & Chris Software & Resources Dec 15 07:37:52 NAS cache_dirs: ERROR: included directory 'Fotoalbum\ Anita\ &\ Chris' does not exist. Dec 15 07:37:52 NAS cache_dirs: ERROR: included directory 'Software\ &\ Resources' does not exist. Could the plugin support that in the near future?
-
Hi there! :) My "unassigned devices" hdd does not spin down automatically while the array devices spin down nicely (see attached image). Cache Dir Plugin uses "include" folders as recommended. Updated all plugins to the latest version. All drives connected to the same HBA you can spin down/up the array devices by clicking on the dot left to the disk#, could that functionality be added to the unassigned devices plugin where clicking on the icon does nothing. :)
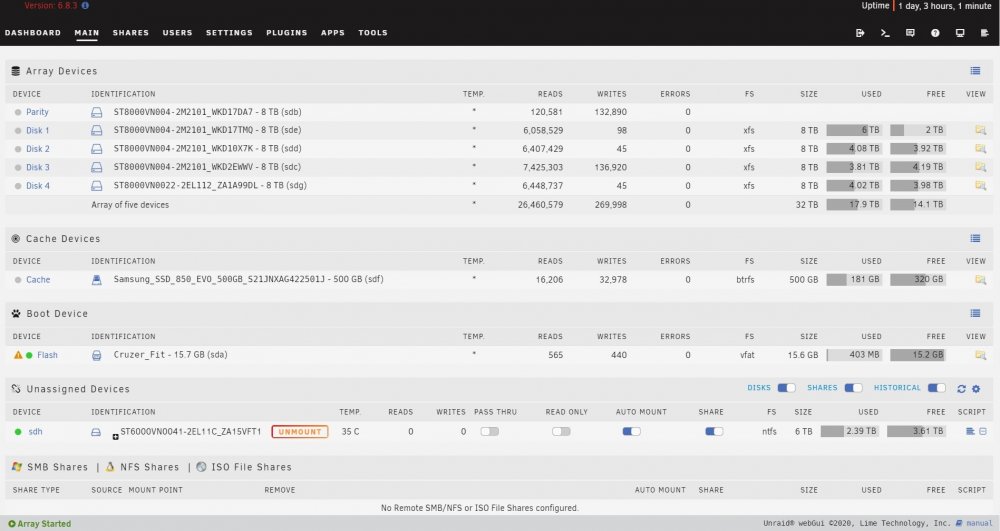
-
@StevenD thanks a lot! There is no kind of configuration required, right?
-
Rebuild worked like a charm, thanks a lot!
-
Rebuild is running now. Looking good so far!







