




HNGamingUK
Members
-
Joined
-
Last visited
-
The plugin would work yes however it automatically stops the sessions without any user input or knowledge. My feature request is for a prompt and list so the user has full knowledge of the process(es) stopping shutdown of the array and can action it all within the unraid UI.
-
It was mentioned today on the unoffical Discord that when you shutdown the array it has the potential to hang and does not inform you of any open processes and expects you to find them and close them before it will finish the shutdown. This request is therefore to add a prompt in the GUI (maybe also CLI) that when a user issues a command that will shutdown the array to display a message to the user. This message would be something to the affect of "The following processes are stopping shutdown of the array" at which point it lists the processes and PIDs. (Likely will need to have this auto refresh as other processes could start to use the system) In addition to the simple message, it could include a prompt asking the user if they would like to kill the processes and force the array shutdown. I believe adding such a feature will be a very good addition and improve the overall user experience.
-
Yeh I saw the only thing is that due to this being a new setup there is no wireguard .conf file in the wireguard directory for me to be able to change the endpoint....
-
Hello I am trying to start a container from fresh using wireguard and PIA but I am getting the following in the docker logs? 2021-04-15 00:15:40,475 DEBG 'start-script' stderr output: parse error: Invalid numeric literal at line 4, column 0 2021-04-15 00:15:40,600 DEBG 'start-script' stderr output: parse error: Invalid numeric literal at line 1, column 7 2021-04-15 00:15:40,600 DEBG 'start-script' stdout output: [warn] Unable to successfully download PIA json to generate token from URL 'https://143.244.41.129/authv3/generateToken' [info] Retrying in 10 secs... I assume this just means it's an issue with PIA and I just have to wait? But was also concerned about the previous two parse errors...
-
Hello, So this is the 3rd time this has happened now but basically I keep finding that my shares are no longer avaliable and when checking on the server the /mnt/user/ filesystem is gone (notably however /mnt/user0 is not gone) This originally happend once after 28 days of uptime, I found the segfault in the logs and rebooted. It then happened again ~5 days later, again rebooted. Then another time it happened just a couple days ago, which is then where I decided to run a memtest and with 3 runs it had no errors. Finally today it has happened again and I am having difficulties trying to figure out what is causing it... Please find my diags attached. I am having to reboot now since I need my server to be in a usable state. diagnostics-20210203-0757.zip
-
Appologies to sound like an annoying teenager, but do you have an ETA or maybe roadmap of features. Equally is there a github page for this so that maybe people can help develop the feature?
-
This has been requested atleast once before by @aptalca back in 2018 however this still doesn't seem to have been implemented? Basically instead of one tarball of all the appdata directories, please could we have the option to have it seperated per directory? This will make a restore much easier for people who only want to restore one application. Currently they would have to manually untarball the file and move the directory. So the feature request is: Backup: In the backup config page have a option called "Backup Directories Seperately" If this option is selected it will backup each directory in the provided appdata directory into a time and dated folder within the provided backup directory. In addition to this if the "Compression" option is ticked then compress each directory. Restore: When someone chooses the restore option, along with the date/time selection provide a directory selection to restore (using checkboxes to allow for multiple selections and an "all" option to restore everything) Hopefully this is enough detail for the feature request to be actioned... @Squid
-
So I seem to be having a strange issue with the above mentioned plugin... I am not sure if @dlandon just needs to provide an update so it will work with 6.9? Basically what it means is I can't attach or detach any USB devices... When I click attach or dettach I get the following: Which seems to just be HTML of the whole page I am on.... I have tried reinstalling the plugin but it still shows the same when trying to attach or dettach a USB device 🙁
-
HNGamingUK changed their profile photo
-
Okay brilliant so setting the following in Auto Update: and then the following in backup: Will backup every Sunday at 3:05 and once complete trigger an update.

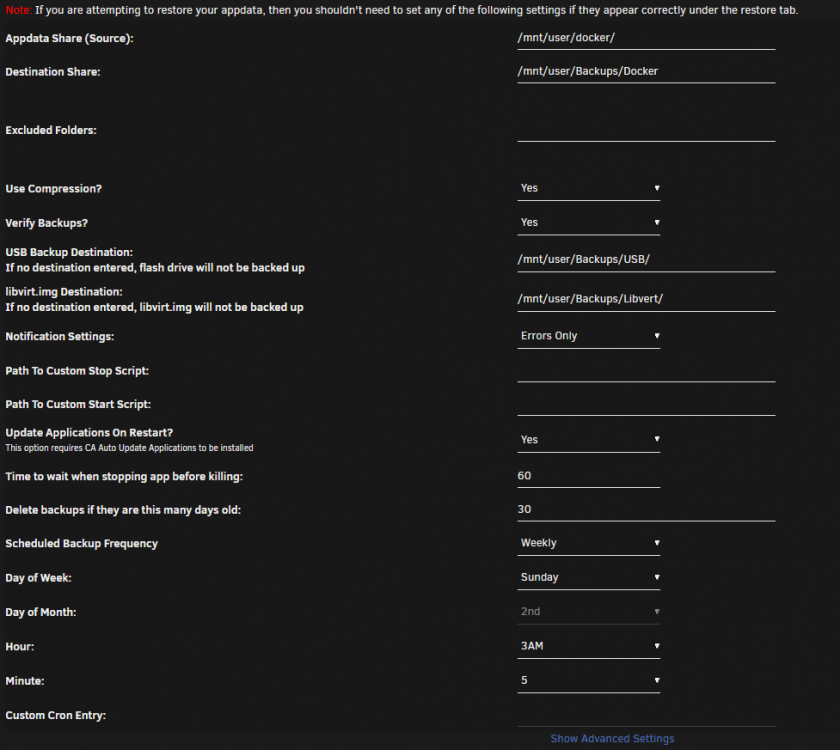
-
Could someone explain how the "Update Applications On Restart?" setting works on this plugin? If I have this set to yes what should I set in the "CA Auto Update Applications" settings?
-
Hello, Is anyone having issues with PIA (specifically the france enpdpoint) I am getting the following: 2020-03-31 07:16:56,249 DEBG 'start-script' stdout output: [info] PIA endpoint 'france.privateinternetaccess.com' is in the list of endpoints that support port forwarding 2020-03-31 07:16:56,249 DEBG 'start-script' stdout output: [info] List of PIA endpoints that support port forwarding:- [info] ca-toronto.privateinternetaccess.com [info] ca-montreal.privateinternetaccess.com [info] ca-vancouver.privateinternetaccess.com [info] de-berlin.privateinternetaccess.com [info] de-frankfurt.privateinternetaccess.com [info] sweden.privateinternetaccess.com [info] swiss.privateinternetaccess.com [info] france.privateinternetaccess.com [info] czech.privateinternetaccess.com [info] spain.privateinternetaccess.com [info] ro.privateinternetaccess.com [info] israel.privateinternetaccess.com [info] Attempting to get dynamically assigned port... 2020-03-31 07:16:56,254 DEBG 'start-script' stdout output: [info] Attempting to curl http://209.222.18.222:2000/?client_id= 2020-03-31 07:16:56,282 DEBG 'start-script' stdout output: [warn] Response code 000 from curl != 2xx [warn] Exit code 7 from curl != 0 [info] 12 retries left [info] Retrying in 10 secs... Settings:
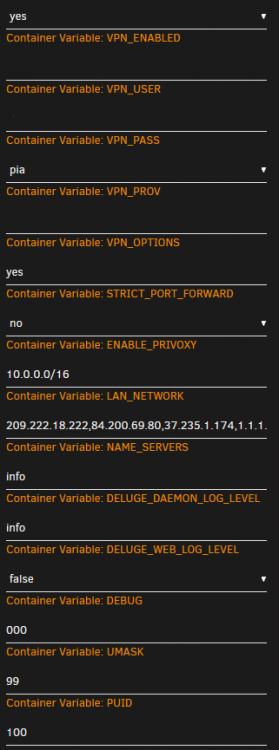
-
May I ask why you are going for the smaller brand VPN providers as apposed to say PIA, AirVPN or NordVPN?
-
Thanks for the info, I have done this and changed the required settings in ltConfig. I can confirm that the speeds are now much better in the region of 45 - 50MB/s which is the max speed of my connection.
-
Okay so I use the Label plugin and it currently has: "enabled_plugins": [ "Label" ], Do I just change that to: "enabled_plugins": [ "Label" "ltConfig" ],
-
Well I was able to build the plugin and it shows on the plugins tab. The only issue I have is I can enable the plguin in the plugins tab and do the "Apply settingsd on startup", I make sure enable_outgoing_utp and enable_incoming_utp are disabled. However when I reboot the docker it disables the plugin in the plugins tab...




