



(Small).png.20e01e54adf9a0993af949e43e312763.png)
CorneliousJD
Members
-
Joined
-
Last visited
Everything posted by CorneliousJD
-
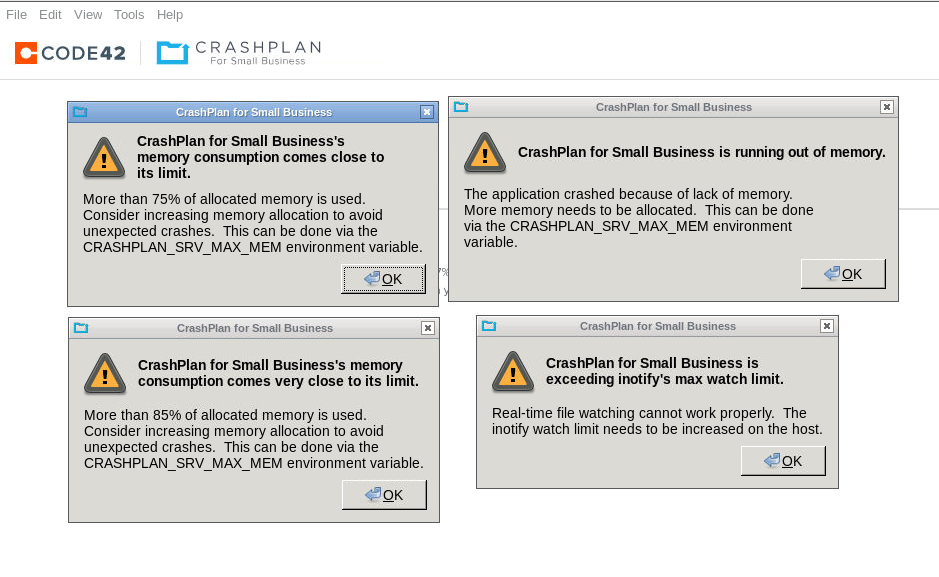
I have gotten my monthly email update and noticed that I haven't had a 100% backup completed in nearly 60 days. When launching the container I see the following errors. Note my server uptime is only 17 days, so this container has recently been restarted a little over 2 weeks ago. Would love to know how to fix these for good so I don't have non-completed backups and so that it runs effectively. EDIT: Also it looks like a partial cause of my backups not being fully complete for 60 days is that 3 files are not backing up? Where can I find detailed logs that show me which files are having these issues so I can take the appropriate actions? In the crashplanpro.com "history" for this device I see the following in December 12/29/18 09:00PM [User Shares] Starting backup to CrashPlan PRO Online: 275 files (9GB) to back up 12/29/18 09:10PM [User Shares] Completed backup to CrashPlan PRO Online in 0h:10m:03s: 307 files (16.80GB) backed up, 55.60MB encrypted and sent @ 2.4Mbps (Effective rate: 319.6Mbps) 12/29/18 09:10PM - Unable to backup 3 files (next attempt within 15 minutes) And then the following now. 01/20/19 08:45PM CrashPlan for Small Business started, version 6.9.0, GUID 831523038531747495 01/20/19 08:45PM [User Shares] Scanning for files to back up 01/20/19 08:45PM [User Shares] Starting backup to CrashPlan PRO Online: 57 files (1.20GB) to back up 01/20/19 08:46PM [User Shares] Scanning for files stopped 01/20/19 08:46PM CrashPlan for Small Business started, version 6.9.0, GUID 831523038531747495 01/20/19 08:46PM [User Shares] Scanning for files to back up 01/20/19 08:46PM [User Shares] Starting backup to CrashPlan PRO Online: 57 files (1.20GB) to back up 01/20/19 08:47PM [User Shares] Scanning for files stopped
-
Well I did end up fixing this, but not in a way that I found many answers for, but this works and still gives me an A+ on the NextCloud security and I get the following in Nextcloud too! All I did to fix this on my end was going into my LetsEncrypt site-conf for nextcloud, and under the ### Add HTTP Strict Transport Security ### section I added this header line. add_header Referrer-Policy no-referrer; After saving this and restarting LE and Nextcloud and re-checking, all checks pass and I'm getting an A+ on the security check!
-
Not too sure off hand, it may be something going off with mixing SpaceInvader One's guide with the one I linked. You may want to blow it out and start over with the guide I linked above, that worked well for me with no issues roughly 6/7 months ago when I setup my container.
-
Try this URL - check the ending with the Nextcloud config files. https://blog.linuxserver.io/2017/05/10/installing-nextcloud-on-unraid-with-letsencrypt-reverse-proxy/ It has to match the domain name you're trying to access from (your public facing DuckDNS domain)
-
Ok, so far I am still really struggling with this error. I have searched around and found that the setup I followed had me put this in my reverse proxy (LetsEncrypt container) in my nextcloud site-config. ### Add HTTP Strict Transport Security ### add_header Strict-Transport-Security "max-age=63072000; includeSubdomains"; Reasoning behind this I guess is that Nextcloud's own NGINX will issue those headers now after the update, and having them both cancels them out. I've tried removing that from my LetsEncrypt site config and restarting both containers and no dice, the error still shows up. Not sure what I'm doing wrong here - the post I initailly followed to set this all up is here: https://blog.linuxserver.io/2017/05/10/installing-nextcloud-on-unraid-with-letsencrypt-reverse-proxy/
-
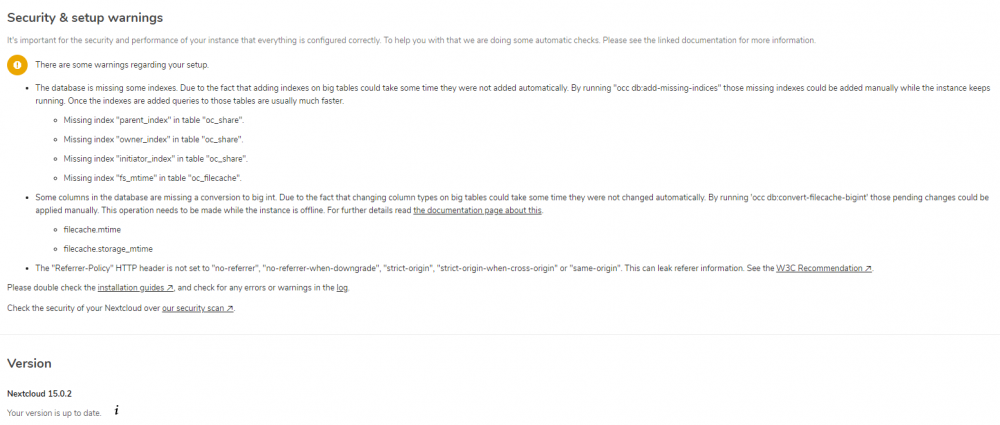
Sorry to bother, I did try searching for this and found others with the issue but not a resolution. I had 13.0.0 installed, updated to 14.x and then 15.0.2 after that - all via WebUI and that went very smoothly. I just now have these warnings, before the upgrades I didn't have any warnings or issues here listed, I also still continue to get an A+ rating on the Nextcloud security scan, but I would like to resolve all of these issues listed here for good measure. EDIT - got the tables updated w/ the sudo -u -abc command in the docker shell, but still not sure why the refer-policy is kicking that back, i had thought i had that issue on 13.x originally and fixed it. I'll have to look around some more, but if someone has a link or info handy feel free to send it my way! Any help is appreciated!
-
From the issues last month that had us roll back to :145 - are those still present or have those been fixed? Deluge right now is my only container not at :latest and would like to get it updated again to the latest and greatest if those issues have been fixed. Thanks in advance for anyone that knows!
-
Did you try to configure your dashboards before hand? Try removing any dashboard and config other than getting it to connect to HA -- it should show you either successfully connecting to HA or give you a reason for the failure. If there's a failure you can then use that to troubleshoot why, if it DOES connect then you can add your dashboards back one by one to see where the issue lies perhaps?
-
ha_key can now be replaced with token -- fore more information on how to create a token see here: https://appdaemon.readthedocs.io/en/latest/CONFIGURE.html
-
Hi there, I don't actually run this docker itself, this is the official HADashboard/Appdaemon docker but I just created the template for it, and published it for unRAID. That being said it should be just a matter of the creator of Appdaemon/HADashboard updating this and then the docker will update for everyone as well after that. Right now it would be something you'd have to reach out to them for (ACockburn) to see if/when they plan to update. Thanks!
-
The first line I left there is most important, your config doesn't have dashboards enabled. Please see the AppDaemon/HADashboard website, but it bascially boils down to adding something like this to your appdaemon.yaml file in /config/ hadashboard: dash_url: http://UNRAIDIP:5050 This should enable dashboards for you to use.
-
Unfortunately this is the unRAID forums and the docker template was created for use on unRAID boxes. Not sure if you'll find much help here for your QNAP unfortunately.
-
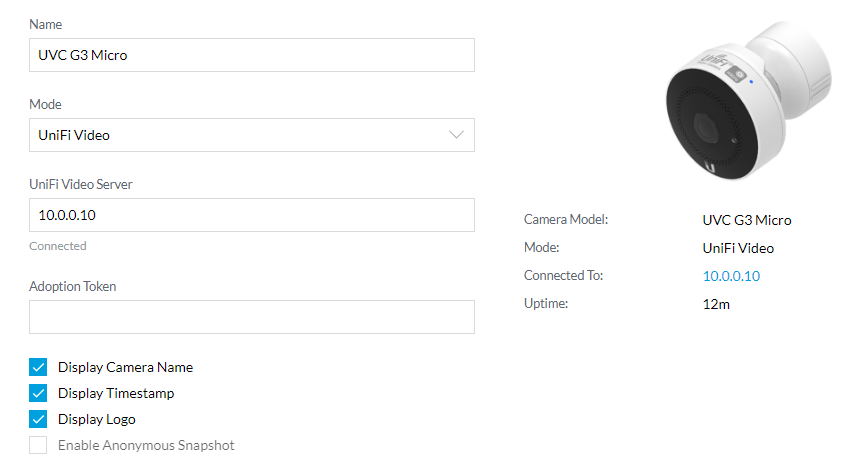
Ah ok, yep, I've got 10.0.0.10 in mine - my unRAID IP and it's all connected in the controller and accessible via UniFi video cloud account I think I'm good now - time to start tinkering with these more and order a couple more now -- Thanks for the SUPER fast reply on all this, saved me from a night of frustration!
-
Ok so I put it in br0 mode, did the adoption and flipped it back to bridge mode, then logged into camera interface and change the IP to my unRAIAD IP address - it's showing up now normally in the unifi video container -- seems ok, but I still see the 172.X address you mention in my container settings but I see no way of changing that - how do I go about changing it? Thanks!
-
New UniFi Video docker - set to Bridge mode - which I would realllllly like to keep it at, but unfortuantely it's having issues now with adopting a new G3 Micro - this is my first UniFi video cam and it wont adopt into the NVR unless I have the container on its own IP w/ br0 mode set. This means it cannot talk to my other containers in bridge mode now though because of this, which means I can't use the cameras in the way I was hoping. Any way to get it working again in bridge mode as it was templated? Thanks!
-
AppDaemon is an execution environment for writing automation apps for Home Assistant home automation software. It also provides a configurable dashboard (HADashboard) suitable for wall mounted tablets. For full instructions on installation and use check out the AppDaemon Project Documentation. I did not create Appdaemon or HADashboard, I simply created the template for unRAID because I wanted to share Appdaemon and HADashboard with the unRAID community. This docker container REQUIRES Home Assistant as well. A docker container for Home Assistant already exists, just search "HomeAssistant" in the apps tab! The variables you need to set when setting up this container for the first time are as follows. HA_URL: This is the URL to your Home Assistant installation. Example: http://192.168.1.100:8123 Make sure you do NOT add a trailing / at the end, this will break AppDaemon and prevent it from connecting to HomeAssistant. TOKEN: This is a LLAT (Long Lived Access Token) from HomeAssistant. DASH_URL: This is a hidden paramater and can be left alone, you can change it if you know what you're doing though. Note that the first time you launch this container it will fail and exit. This is because it created an example appdaemon.yaml in /mnt/user/appdata/appdaemon/ Go ahead and edit that file (I use nano via the terminal to do so personally) and add a few lines that are required. In particular for the current release you need to add time_zone, latitutde, longitude, and elevation in order to get Appdaemon to actually run in the container without crashing. Here's a base example config, please change to suit your own timezone, latitude, longitude, and elevation. Note that your HA_URL, Token, and Dash URL will automatically all be filled in. appdaemon: time_zone: America/Detroit latitude: 0 longitude: 0 elevation: 0 plugins: HASS: type: hass ha_url: http://X.X.X.X:8123 token: REMOVED FOR SECURITY http: url: http://$HOSTNAME:5050 admin: api: hadashboard:
-
Awesome, thanks for confirming! The container works great and I'm loving it, makes backups so easy and have successfully restored after losing my entire cache drive too. Couldn't be happier with it!
-
I am getting a warning about 75% of max memory being used. Only actively backing up ~500GB of data with this. Just to note I installed this container fresh and setup all new backups for this server, I did not migrate from anything else. This is the first time I've seen this error since setting it up about 4 months ago.

-
Looks like OpenVPN-as in Host mode was causing some overlap which made discovery not work at all... Turning off OpenVPN-as and then booting this container up seems to let it run fine. I should probably change OpenVPN to use br0 mode instead of host mode I guess.
-
I'm having some trouble with this container also. I want to use the letsencrypt container to do a reverse proxy on this so I can access from outside, however the issue I'm running into is whether in bridge or host mode, HomeAssistant can never see any of my devices, and can only be seen if I put it into br0 mode and give it its own IP address. I have tried privilege on/off in bridge/host most but it cannot auto-discover my devices still. Is there a way to get this to work without assigning it a separate IP? Once I do that I lose access to allow my letsencrypt container to do a reverse proxy, unless I go back and reconfigure a bunch of containers... Oof.
-
I was able to sort this out by following the guide a bit more closely for the specific file that they make - i had originally tried adding it to default site-conf, but after I copied the existing nextcloud config they had up in the tutorial all is well.
-
I've gotten everything up and running but am seeing the following 3 errors in the admin section on nextcloud. The "X-XSS-Protection" HTTP header is not set to "1; mode=block". This is a potential security or privacy risk, as it is recommended to adjust this setting accordingly. The "X-Content-Type-Options" HTTP header is not set to "nosniff". This is a potential security or privacy risk, as it is recommended to adjust this setting accordingly. The "X-Robots-Tag" HTTP header is not set to "none". This is a potential security or privacy risk, as it is recommended to adjust this setting accordingly. Do I need to make changes in the nextcloud site config or the letsencrypt site config? I am reverse-proxying via letsencrypt container. Thanks!
-
Thanks so much for this - I tweaked their setup every so slightly but it's working great for me now! Uploading my existing data into nextcloud now. Excellent! Thanks!
-
I'm with you! I know we're staying off the pihole container support here but willing to help provide logs/sepcs/etc from my build that's not having any issues if needed anywhere, feel free to PM me if ever needed to drop more logs into something. I have a 4U supermicro w/ 4x onboard gigabit NIC ports.
-
Thanks, I don't have much data to bring INTO next cloud really, since Plex allows access to all my media I'm not worried about media files, so it's all just documents/photos for one user (just me) and I can import those in fairly easily I think. What did you do in MariaDB for setting up NextCloud, did you just use your root user/pass?
(Small).thumb.png.b884b0484e848c502a315fc27b995f59.png)




