




Wisnaeme
Members
-
Joined
-
Last visited
Everything posted by Wisnaeme
-
I just tried the exact same with the same result. Not sure of a work around but it would be good to have Unraid capable of recording from this camera.
-
Not sure if this is new, but the logging is not currently reflecting the selected Timezone.
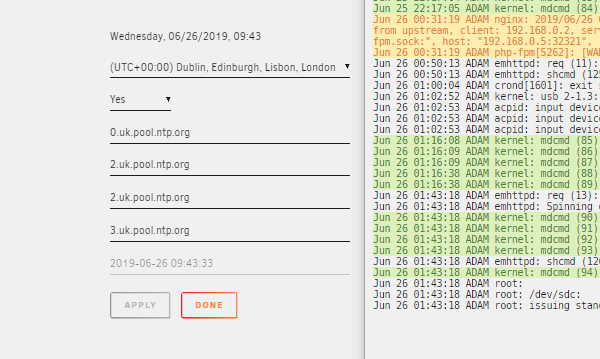
-
I lost access to my server for about an hour while I sorted these broken settings after update to 672. Changed after install Network name Custom UI Port Workgroup name SSL/TLS from OFF to AUTO All TIME settings. FTP re-enabled Not what I really wanted to start fixing after a long day. The other server can wait.
-
Just installed this and it works perfectly for my Trust Oxxtron 1500VA UPS and it works well. Always struggled with PC software for this UPS so glad I can get it working on my Unraid box. Thanks for the work. Showing as: USB DEVICE: Bus 001 Device 003: ID 0925:1234 Lakeview Research Screenshot is for anyone else struggling with this UPS.
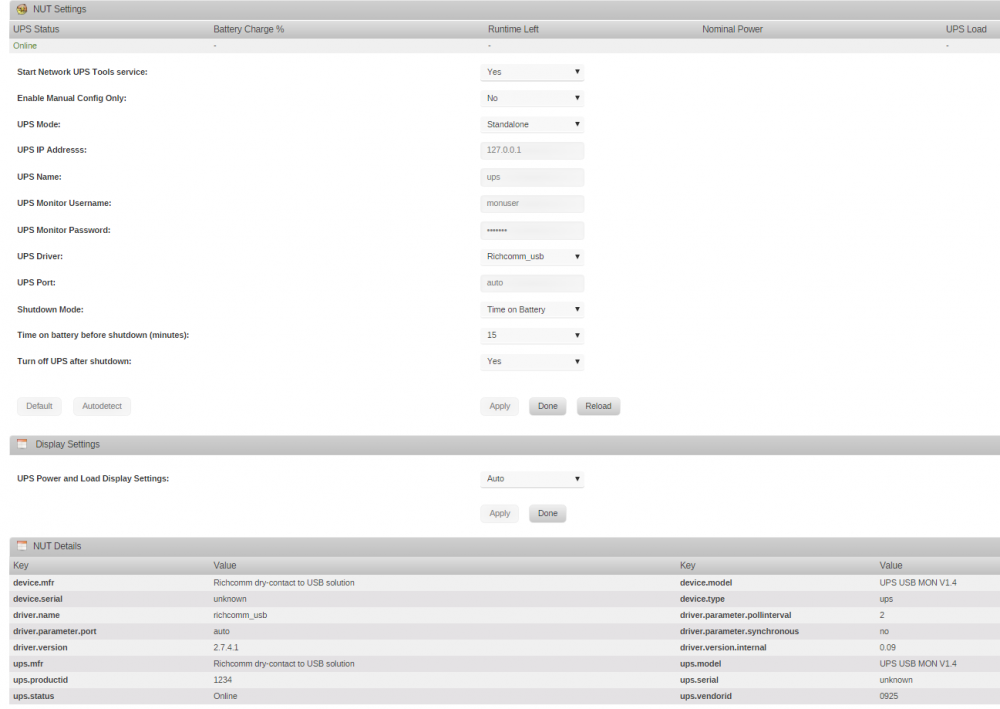
-
Yeah. I worked it out in the end. Weird thing is I got the link from the one at the start of this thread, the usual place I get it. Seems odd.
-
Currently getting a 404 on the CA plugin url. Any ideas? Been down for a couple of hours just as I need to setup a new server. ? https://raw.githubusercontent.com/Squidly271/community.applications/master/plugins/community.applications.plg

