




nomisco
Members
-
Joined
-
Last visited
Everything posted by nomisco
-
Thanks Jorge. I shall ignore it, though somewhat strange that it has appeared after the server has been running for nearly 18 days.
-
This appeared in my log earlier today, from what is a very error-free server. Aug 8 10:15:11 unRAID kernel: WARNING: CPU: 4 PID: 2190177 at fs/notify/fdinfo.c:55 show_mark_fhandle+0x79/0xe8 Aug 8 10:15:11 unRAID kernel: Modules linked in: xt_nat xt_tcpudp veth xt_conntrack xt_MASQUERADE nf_conntrack_netlink nfnetlink xfrm_user xfrm_algo ip6table_nat iptable_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 xt_addrtype br_netfilter bridge stp llc md_mod zfs(PO) spl(O) nct6775 nct6775_core hwmon_vid ip6table_filter ip6_tables iptable_filter ip_tables x_tables efivarfs macvtap macvlan tap intel_rapl_common x86_pkg_temp_thermal intel_powerclamp coretemp kvm_intel i915 kvm iosf_mbi drm_buddy ttm crct10dif_pclmul i2c_algo_bit crc32_pclmul crc32c_intel ghash_clmulni_intel drm_display_helper sha512_ssse3 sha256_ssse3 sha1_ssse3 aesni_intel drm_kms_helper crypto_simd cryptd mei_pxp mei_hdcp rapl intel_cstate intel_wmi_thunderbolt mxm_wmi i2c_i801 drm e1000e intel_uncore mpt3sas i2c_smbus mei_me ahci intel_gtt mei raid_class agpgart libahci i2c_core scsi_transport_sas thermal fan video wmi backlight acpi_pad acpi_tad button Aug 8 10:15:11 unRAID kernel: CPU: 4 PID: 2190177 Comm: lsof Tainted: P O 6.8.12-Unraid #3 Aug 8 10:15:11 unRAID kernel: Hardware name: Micro-Star International Co., Ltd. MS-7B49/Z370 PC PRO (MS-7B49), BIOS 1.B3 11/15/2021 Aug 8 10:15:11 unRAID kernel: RIP: 0010:show_mark_fhandle+0x79/0xe8 Aug 8 10:15:11 unRAID kernel: Code: ff 00 00 00 89 c1 74 04 85 c0 79 22 80 3d 0a 40 2c 01 00 75 5e 89 ce 48 c7 c7 4b 4a 27 82 c6 05 f8 3f 2c 01 01 e8 23 28 d8 ff <0f> 0b eb 45 89 44 24 0c 8b 44 24 04 48 89 ef 31 db 48 c7 c6 89 4a Aug 8 10:15:11 unRAID kernel: RSP: 0018:ffffc9000899fc30 EFLAGS: 00010282 Aug 8 10:15:11 unRAID kernel: RAX: 0000000000000000 RBX: ffff8881347dc020 RCX: 0000000000000027 Aug 8 10:15:11 unRAID kernel: RDX: 0000000082440510 RSI: ffffffff82258ed4 RDI: 00000000ffffffff Aug 8 10:15:11 unRAID kernel: RBP: ffff888106ed5258 R08: 0000000000000000 R09: ffffffff82440510 Aug 8 10:15:11 unRAID kernel: R10: 00007fffffffffff R11: 0000000000000000 R12: ffff888106ed5258 Aug 8 10:15:11 unRAID kernel: R13: ffff888106ed5258 R14: ffffffff812f1e37 R15: ffff888105e0c878 Aug 8 10:15:11 unRAID kernel: FS: 00001554f9b5af00(0000) GS:ffff88845ed00000(0000) knlGS:0000000000000000 Aug 8 10:15:11 unRAID kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Aug 8 10:15:11 unRAID kernel: CR2: 00000000004b75d8 CR3: 00000001191dc001 CR4: 00000000003706f0 Aug 8 10:15:11 unRAID kernel: DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 Aug 8 10:15:11 unRAID kernel: DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 Aug 8 10:15:11 unRAID kernel: Call Trace: Aug 8 10:15:11 unRAID kernel: <TASK> Aug 8 10:15:11 unRAID kernel: ? __warn+0x99/0x11a Aug 8 10:15:11 unRAID kernel: ? report_bug+0xdb/0x155 Aug 8 10:15:11 unRAID kernel: ? show_mark_fhandle+0x79/0xe8 Aug 8 10:15:11 unRAID kernel: ? handle_bug+0x3c/0x63 Aug 8 10:15:11 unRAID kernel: ? exc_invalid_op+0x13/0x60 Aug 8 10:15:11 unRAID kernel: ? asm_exc_invalid_op+0x16/0x20 Aug 8 10:15:11 unRAID kernel: ? __pfx_inotify_fdinfo+0x10/0x10 Aug 8 10:15:11 unRAID kernel: ? show_mark_fhandle+0x79/0xe8 Aug 8 10:15:11 unRAID kernel: ? __pfx_inotify_fdinfo+0x10/0x10 Aug 8 10:15:11 unRAID kernel: ? seq_vprintf+0x33/0x49 Aug 8 10:15:11 unRAID kernel: ? seq_printf+0x53/0x6e Aug 8 10:15:11 unRAID kernel: ? preempt_latency_start+0x2b/0x46 Aug 8 10:15:11 unRAID kernel: inotify_fdinfo+0x83/0xaa Aug 8 10:15:11 unRAID kernel: show_fdinfo.isra.0+0x63/0xab Aug 8 10:15:11 unRAID kernel: seq_show+0x151/0x172 Aug 8 10:15:11 unRAID kernel: seq_read_iter+0x16e/0x353 Aug 8 10:15:11 unRAID kernel: ? do_filp_open+0x8e/0xb8 Aug 8 10:15:11 unRAID kernel: seq_read+0xe2/0x109 Aug 8 10:15:11 unRAID kernel: vfs_read+0xa3/0x197 Aug 8 10:15:11 unRAID kernel: ? __do_sys_newfstat+0x35/0x5c Aug 8 10:15:11 unRAID kernel: ksys_read+0x76/0xc2 Aug 8 10:15:11 unRAID kernel: do_syscall_64+0x6c/0xdc Aug 8 10:15:11 unRAID kernel: entry_SYSCALL_64_after_hwframe+0x78/0x80 Aug 8 10:15:11 unRAID kernel: RIP: 0033:0x1554f9de95cd Aug 8 10:15:11 unRAID kernel: Code: 41 48 0e 00 f7 d8 64 89 02 b8 ff ff ff ff eb bb 66 2e 0f 1f 84 00 00 00 00 00 0f 1f 00 80 3d 59 cc 0e 00 00 74 17 31 c0 0f 05 <48> 3d 00 f0 ff ff 77 5b c3 66 2e 0f 1f 84 00 00 00 00 00 48 83 ec Aug 8 10:15:11 unRAID kernel: RSP: 002b:00007ffcea2d27b8 EFLAGS: 00000246 ORIG_RAX: 0000000000000000 Aug 8 10:15:11 unRAID kernel: RAX: ffffffffffffffda RBX: 000000000043f600 RCX: 00001554f9de95cd Aug 8 10:15:11 unRAID kernel: RDX: 0000000000000400 RSI: 0000000000446ae0 RDI: 0000000000000007 Aug 8 10:15:11 unRAID kernel: RBP: 00001554f9ecd230 R08: 0000000000000001 R09: 0000000000000000 Aug 8 10:15:11 unRAID kernel: R10: 0000000000000000 R11: 0000000000000246 R12: 00001554f9ecd0e0 Aug 8 10:15:11 unRAID kernel: R13: 0000000000001000 R14: 0000000000000000 R15: 000000000043f600 Aug 8 10:15:11 unRAID kernel: </TASK> Aug 8 10:15:11 unRAID kernel: ---[ end trace 0000000000000000 ]--- unraid-diagnostics-20240808-1034.zip
-
As a further bit of information, I updated to the latest build about two days after this event, and upon reboot, a different disk was disabled, so I repeated the process. The server has been stable for in excess of a year, so it is troubling as to why I might suddently be seeing this. I purchased another LSI 9211 and a breakout cable (as a spare) as I don't want this suddenly failing over the holiday period!
-
Thank you. It is rebuilding at the moment.
-
I've been playing around with it - perhaps foolishly. I can now see the contents of the drive and it appears in the array, without a specific error message, but it still has a red X next to it. Could someone advise what I need to do next? unraid-diagnostics-20231202-1018.zip
-
Please can I have soome assistance with a disk becoming disabled? Unfortunately I have rebooted since it happened so am probably missing log files. Nothing has changed; the server was sitting idle and it suddenly happened. It had been up for nearly a month. Obviously I want to avoid any data loss. I have no idea what I'm doing beyond basic setup so I'd appreciate some explicit guidance. Thanks! Edit: I've tried the repair in maintenance mode and it says: Phase 1 - find and verify superblock... - block cache size set to 1117984 entries Phase 2 - using internal log - zero log... zero_log: head block 118210 tail block 118206 ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this. I have no idea what this means. unraid-diagnostics-20231202-0827.zip
-
Mine is showing a blank page this morning (not 500 error), though SMB and docker services such as Plex are still available.
-
It's in Settings > SMB in unraid.
-
ljm42: Changed the port to something else. trurl: Yes, I do recognise the IP address, that's OK. And I'm aware of the corruption in the cache pool. I don't know if it's a failing SSD or not. No further attempts to access the server. The only things which are forwardded on my router are the Plex server (running on unRAID) and the port aforementioned which I've changed for the WebUI remote access.
-
Haven't done anything as far as I know. The password is long and not the kind you could guess. unraid-diagnostics-20230126-1719.zip
-
I've just seen this in my log. Never seen anything like this before. Is this someone trying to gain access to my server? Anything I should worry about? Jan 26 15:43:38 unRAID nginx: 2023/01/26 15:43:38 [crit] 24956#24956: *1977125 SSL_do_handshake() failed (SSL: error:141CF06C:SSL routines:tls_parse_ctos_key_share:bad key share) while SSL handshaking, client: 152.32.141.142, server: 0.0.0.0:443 That IP address is from Nigeria. Thanks
-
Start an iperf server with iperf -s to create a server and then run iperf -c <serverIP> on the client.
-
There may be a perfect storm of something in my case with the many recent changes to the SMB implementation. It most certainly used to saturate the Gb network during SMB transfers. I shall do a fresh install in the next day or two and report back. Thanks for your help.
-
The disk settings are set to reconstruct write. It is writing to the largest available space, which is about 2TB of space on a 4TB disk. The write speed is still ~50MB/s from the client to unraid, but it appears to buffer in the unraid memory, then dump large chunks to disk before waiting for some buffer to fill on unraid, they repeating. Hopefully the below images give you some idea of the behaviour. The disk writes in the top image are to the parity and array disk. Cache disk (SDD) is not used during test.
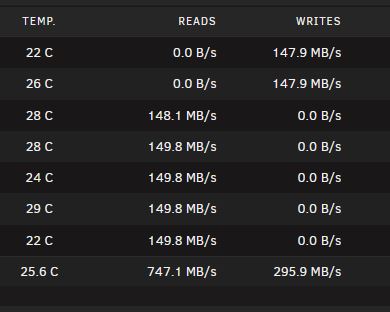
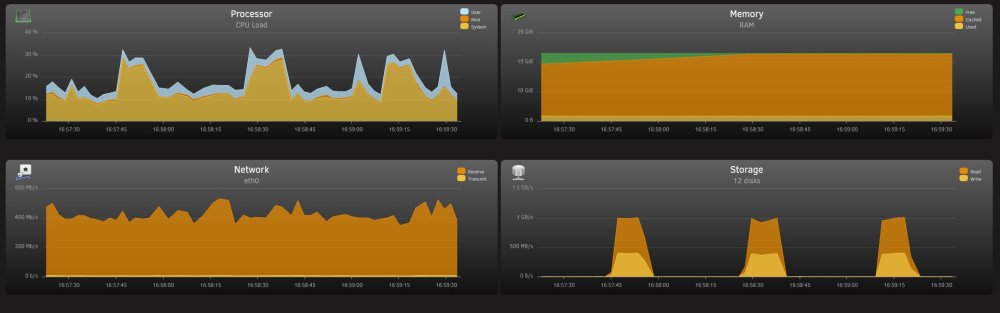
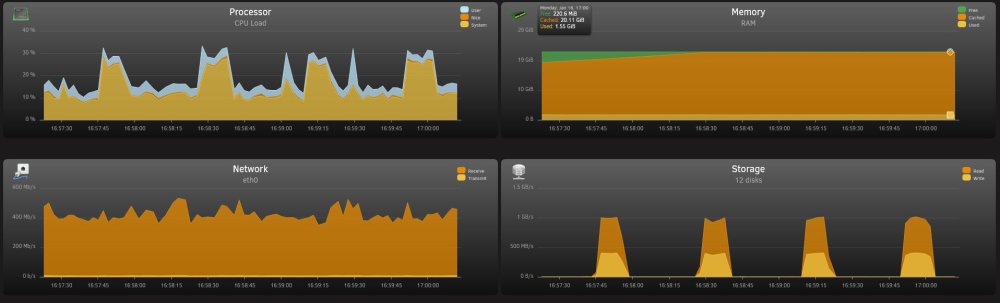
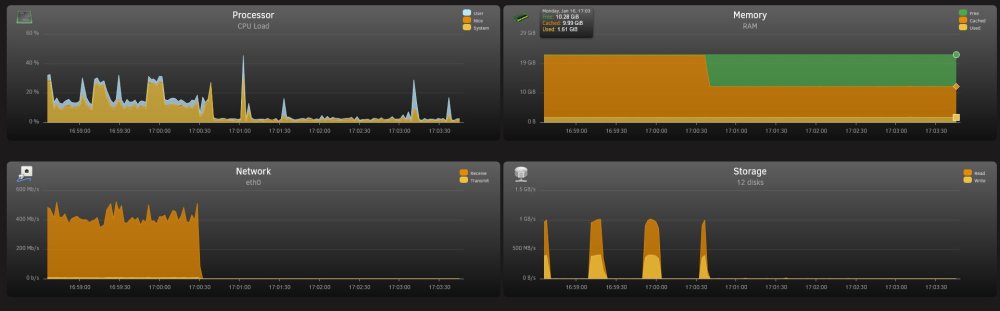
-
Same problem. It used to max the link speed. About 50% of that now both ways. Only unraid and SMB are the common factors.
-
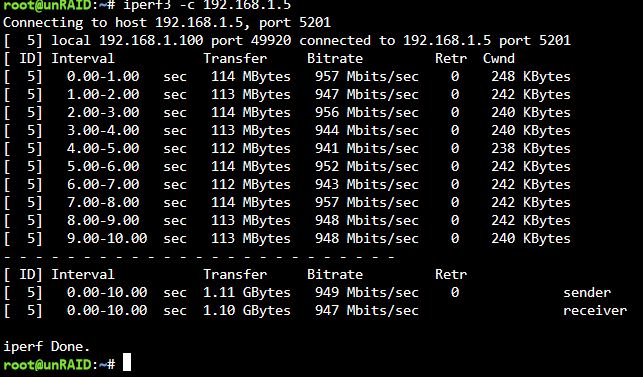
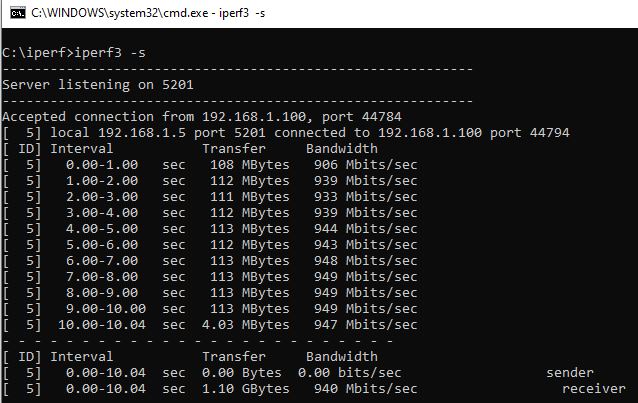
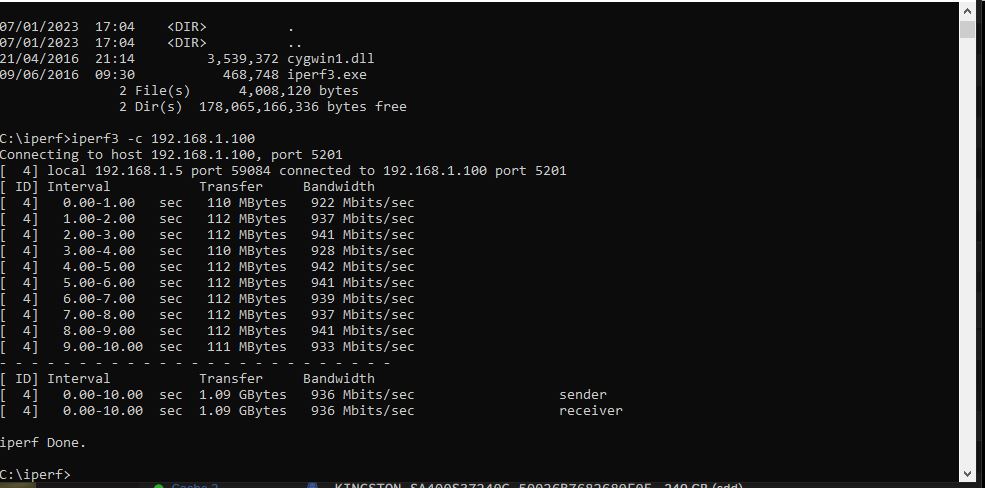
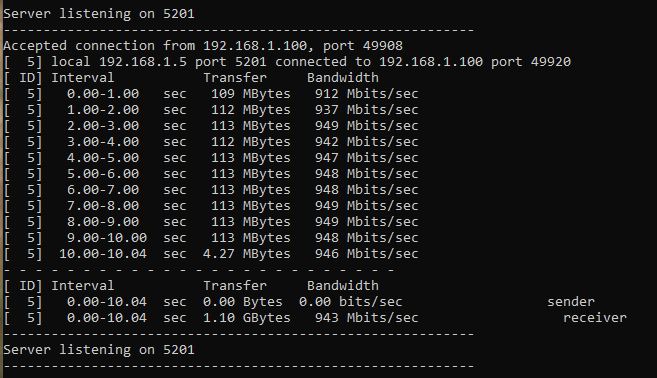
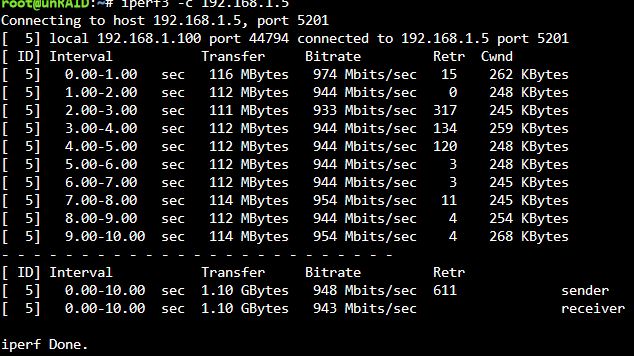
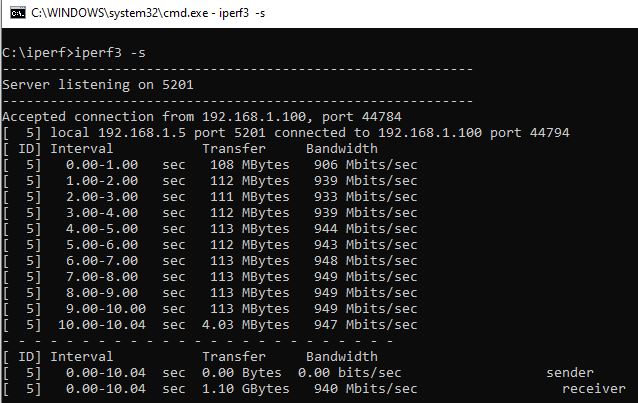
Bypassed the entire segment of the network, so Win10 > switch > unraid. No change. SMB still about half the data rate it used to be. I can transfer from the win10 machine to another on the network at ~110MB/s. The iPefr tests show good performance. SMB is the problem.
-
I don't believe that the number of retries is of concern when the network is being saturated. 1Gb/s can max out at about 80,00+ packets per second and the network was minimally in use elsewhere; skpe, online gaming etc (which would have prioritised packets). I'll subsitiute a segment of the network with a long cable which will byass a couple of switches, but because there's a 50% drop in throughput I don't have much hope for that. Just to add, iPerf shows that the network performance is largely as expected, and I see better when using a different protocol through lancache, so it points to an SMB problem to me.
-
As I understand, using the iPerf switch -P would have tested with parallel streams. As I didn't use this, I'm assuming that these tests are with a single stream.
-
Is that not what I've done here?
-
I know there are several posts on here about this, and a few appear to have solutions, but none of those apply to my situation. I used to be able to max my 1Gbps network connection when copying from my Windows 10 machine over SMB to unRAID. It would max out at ~ 110MB/s. Now it will max at a consistent half of that - about 52MB/s. I don't know when it first happened, but I'm guessing it's been slow for about 6 months or so. Don't want to spam this thread with screenshots (so I've added them as an archive). I've tested: Windows to unRAID using iPerf with both tested as client and server. Results are > 930Mb/s Benchmarks of the drives and controller (LSI 9211-8i). Spinners and SSDs. The slowest drive is around 100MB/s at its slowest point. Windows to Windows machine on the same network ~ 110MB/s. SSD on both ends. Tested with cache SSD and direct to array with no change. Tested in safe mode. Tested with all dockers stopped. Played with network settings, turbo write etc, but I can see that the disks and network don't appear to be the bottleneck. I've recently set up Lancache for gaming downloads. Those cache only on an SSD and may contain a lot of small files, but even installing to both machines I am seeing a consistent 75 - 80MB/s. Screens archive also shows that array parity check speed is consistently ~150MB/s average. Test file is 60GB ISO. Attached screens.zip shows the screenshots I took whilst running the tests. Thanks screens.zip unraid-diagnostics-20230104-1924.zip
-
Looking for some guidance on how to set up Pushover to send alerts to my Android phone. I've installed the Android app and got a Pushover account, along with the user key. I have no idea what should be in the app token line (Settings > Notifications). Clicking on the link sends me to a page on the Pushover website. All I want to do is simple alerts from the OS, not from Dockers etc. My Linux and SysAdmin skills are weak. I need an idiots guide!
-
Thought it might be worth an update: Now over two weeks of uptime without anything unusual in the logs. I re-enabled the i915 driver about a week ago and it's being used for Plex HW transcoding - the same as the last couple of years. I may reinstall the MyServers Plugin to see what happens. I am still running 6.10 RC2.
-
I remember the Quantum Bigfoot, that 5.25" monstrosity.
-
I've uninstalled the 'My Servers' plugin and so far I have a completely uneventful log, with just disk spin ups / downs.
-
So is it possible for me to look in the running processes to see an abundance of these?











