




1activegeek
Members
-
Joined
-
Last visited
Everything posted by 1activegeek
-
I hadn't, but it looks like perhaps it was just premature. I saw it did mount when I was making some changes today. Sorry for muddying the thread!!
-
I think this is obvious, but wanted to check - should I just create a duplicate version of the script and set it to run on array start, and then also have a second one to run every say 10 min like your git outlines? Reason I'm asking, restarted the server earlier today - current script is set with a run every 10 min cron setup like your example, but after having restarted earlier today the server doesn't have anything mounted and appears it hasn't for most of the day. Just curious if I'm missing something, or if I'm facing a different issue.
-
Ok, so after some consolidated and focused testing - I think I'm ok. I think I had a mixup of signals, way too much chaos at work, and extreme late nights trying to play with tech and not remembering what I did. The short of my issue I believe - and to help in case others do similar - is that I was switching between rclone variants, and testing the new shortcuts function, and shifting between running the script in the UR UI vs running in background. The initial tests I think had an issue because of the rclone vs rclone-beta because I was testing the new shortcuts. Then I tried shifting to the beta, and tried simply running the script - a few times I left the window open, but after time I eventually closed the window. This is what I believe led to the "miraculous disappearance" scenario I was left with. I had originally been doing it with the background, but when I hit an issue initially, it was annoying finding the process to kill so I just ran it via the GUI And left it there. That switch is where I believe I messed it up. Right now, I've got it up and running using rclone-beta with shortcuts enabled (that 1a_mediaz is a pool from multiple TD locations under one mount). Next I'll venture into the territory with the merger_fs stuff, but at the moment that's not a requirement for me. I just want to be sure I've got a solid mount/unmount for my core rclone location. I'll adjust the script for my need to add other mounts beyond the one. This is awesome, thank you for the work and effort. Sorry for the firedrill over nothing!!
-
Yes, correct. That's just one mount, I have some others I'll work on and/or work on adjusting to point at crypt volume - but for now yes that's the example I'm working with to make sure its working as expected first. Did I miss something about this being reliant on crypt mount? I figured it should work either way as long as the destination is my intended destination.
-
[1a_mediaz] type = drive scope = drive team_drive = ~~REDACTED~~ service_account_file = /boot/config/plugins/rclone-beta/sa/1.json server_side_across_configs = TRUE Sorry for the lack of details. So I mean as in after I mount it, I can LS and see the contents. A few moments will pass, then if I try and LS on the directory - the folders are gone and hence the "disappear". rclone_mount.sh
-
hey @DZMM finally got around to testing out your script, but I seem to be hitting a wall. I've gotten the script to run successfully, and it seems at first glance to be working. Problem is, as soon as I try to touch any of the data - aka mount anything, move anything, copy anything, etc - the mouths disconnect and are going away. Any tips on where I can start to look to debug? I know not a lot of detail, hoping to start with debug so I can see what I can find first before bogging you down with lots of info to troubleshoot. I'll add an edit - I thought it might be relative to the whole mapping scenario you highlighted, but another issue I've noticed before I could even get to that - after a short while the mounts actually disappear. So whether I do anything or not, they seem to disappear after a short time as well. I'm really scratching my head.
-
I think I was thrown off by his post though, as under the changelog it says: 3/1/20 - switched from mergerfs to unionfs Though it looks like in the script and GitHub page he mentions MergerFS, so I'm not sure. Perhaps I'll DM him.
-
Sorry to necro a slightly outdated thread, but wanted to add that you can also use the unRAID Go file in the config to achieve this and would likely be the best option. You could (depending on the size) simply store this somewhere on the UR USB boot drive, and set the go file to copy this into the bin folder. I’ll be checking this out as well since I’d like to also use mergerfs along with some rclone magic. Thanks for the help guys!
-
Yup, I noticed the same thing. It's that evil version (6.6.6)
-
Yup, that's what I'm going to use. I'm an Org guy - so of course running this all in Org.
-
Ya I thought it looked odd. Thank you though, that was foolish of me to not try clearing the cache. That was it! It is still odd though that I'm not able as "guacadmin" to change ANY of the settings on the guacadmin user. I had to login as my user, set with permissions for everything, and change them for that account. Little weird, seems like some sort of wacky permissions bug? Anyhow - all set now. Thanks for the work on this, now with OTP I feel better opening this up without hiding it behind my proxy. Though I'm going to look at setting up Fail2Ban in conjunction anyway.
-
Yes I had read that in the documentation as well. I ensured that was set on both my local user and the admin. Interestingly though I tried my user again, this time I'm receiving a new message: catalina.out PS - is there a way to change the admin password? I'm noticing now that it won't let me change the admin password from the default - really not a safe thing.
-
Sure! catalina.out
-
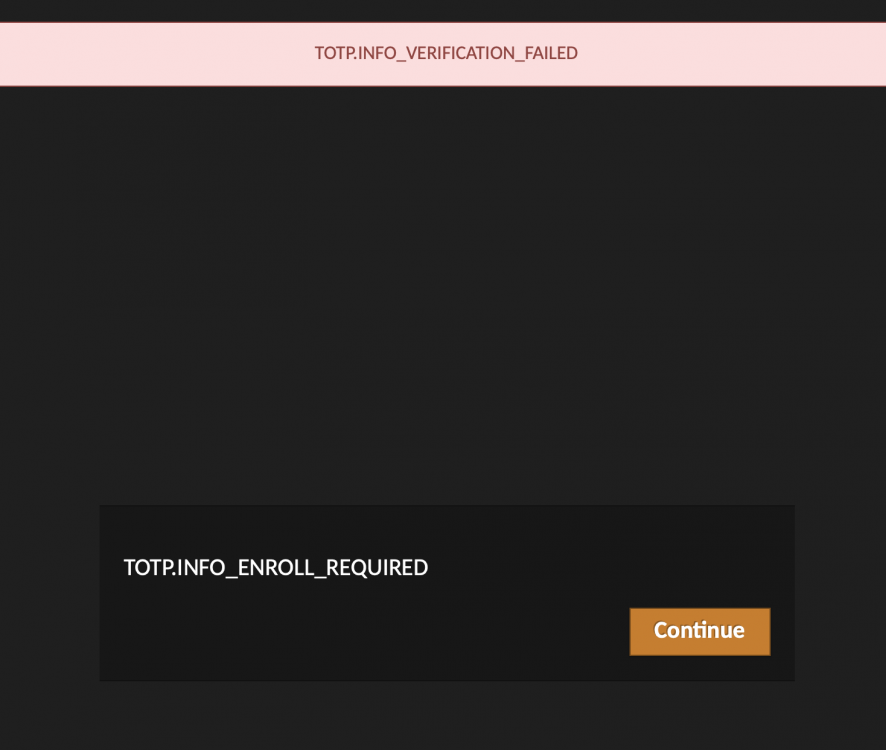
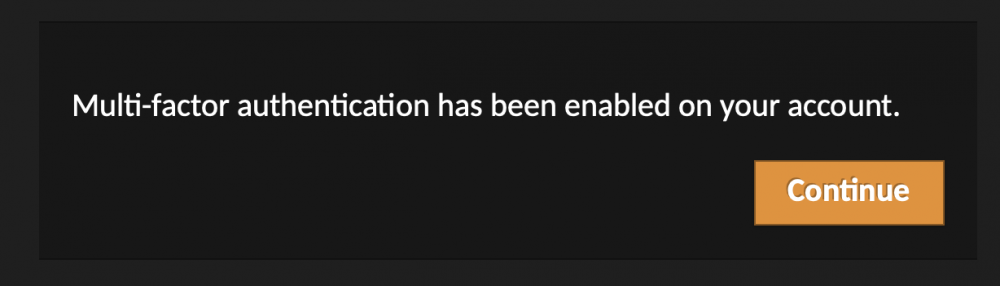
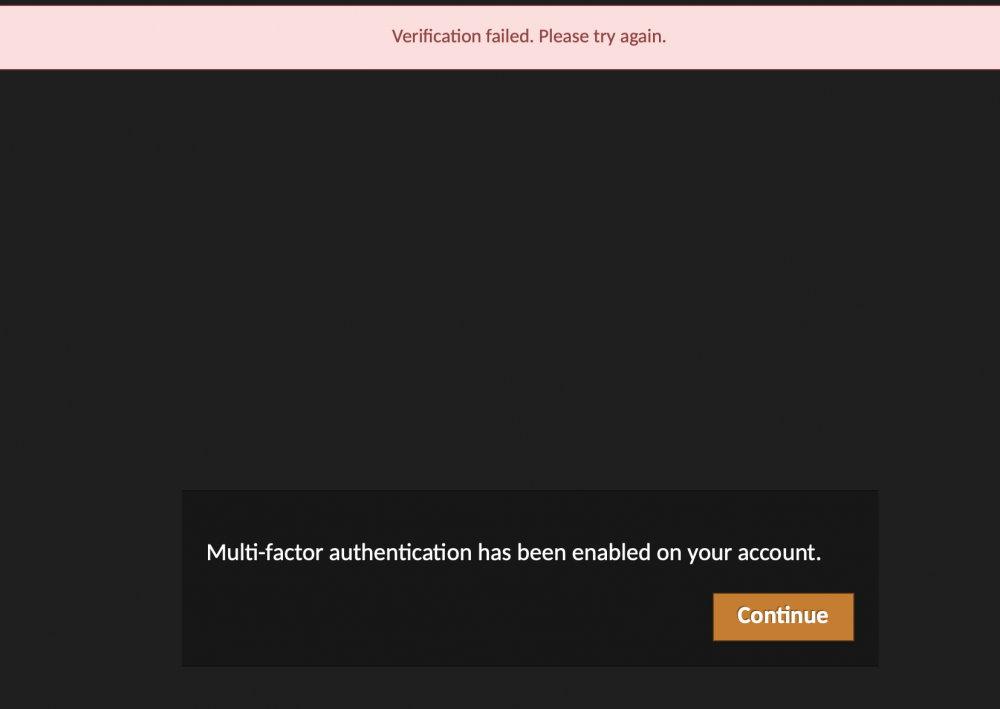
Is there something I'm missing to get the TOTP working? I've flipped the switch to Y on the option and even blew away the container thinking perhaps I had something in the DB just stuck. At this point, it will let me login with user/pass, then it says Multi Factor Auth has been enabled with the ONLY option of clicking a Continue button. The screen does a simple shake notification and the top bar saying "Verification failed, please try again."
-
Is there a way to successfully make changes to the config files and have it saved? I've tried making changes via the UI and saving then restarting, but the settings get wiped out. Also tried from the command line, but same thing - wiped out upon restart of the plugin. I'm assuming there is something in the plugin that writes the settings to the files on start, but I'm not sure. Any advice? Trying to modify the battery.charge.low setting to turn off ESXi boxes almost immediately (90%) after an event - long story as to why this method is being sought - but I can't seem to get this setting adjusted. Forgive my lack of understanding the options - seems you can use the manual option to use the files. I see the help outlines if I set to No, some options may be overridden in the config files. Seems the ups.conf file is one of such - which makes sense as some of the entries were options of setting the config for that ups device. Makes sense. Thanks for the great plugin!!
-
So I let me start with - I love this plugin! It's fantastic for some various tasks. Recently I've been exploring some options with UPS activity and in many cases it involves running another service/daemon to just run a script. I was thinking it might be great if I could just do so from unRAID instead of setting up individual installs. Would it be possible and/or is it feasible to extend this plugin to allow for another drop-down option for the schedule to happen on power-loss or power-restore from the UPS? Assuming of course unRAID is powered on, I'd love to be able to kick off the shutdown scripts for example that I'd be sending to my ESXi boxes, my Rock64, an extraneous piece of network equipment, etc.
-
But that squirreling geeky part of me just needs a solution to the problem!! ?? Ya I hear you. Thanks for giving me some background. I think this is a docker problem more than unRAID, just wasn't sure if it was possible unRAID had some mix in with it too or not.
-
Yes, this is why I run "docker system prune -f" via script weekly. It takes care of all the "dangling" things (images, volumes, networks, containers, etc). I guess that is my concern here - it feels like a nuclear option to cleanup every so many months when this piles up again. I guess I can understand if the btrfs is not a problem - but I thought I had read another thread someone saying it was a problem to see that FS becoming so large compared to the size of the docker image file. Either way - I think honestly there is something bigger here that needs to be addressed. Because in reality, it looks like the docker install is taking up potentially more space than needed overall. I get the layer component you mention - but there seems to be WAY more duplication than actually exists with even shared layers. My bigger concern is that something in here caused my more recent system hang up somehow. But thats neither here nor there. I'll keep an eye over time I guess to see how this progresses.
-
I'm going to revive this thread as I'm facing what I think is a similar issue. Something is not adding up, and I can tell you with fairly high certainty I don't have containers that are "leaking" extra data. I found one, and nipped that in the butt (thanks pihole for your atrocious error log!!). I've seen a lot of things around here and yes I've read the FAQ to be certain I don't have the generic issues listed here. What I've identified is mismatched BTRFS filesystem compared to the docker image file. Perhaps I misunderstand something here, but I don't think I am. The details: My docker image file was 30GB, I've now upped it to 50GB. Pretty sure the recent warning about the docker image size was from pihole log, but it prompted be to dig into this all. But as I was reading some other posts, I checked out the /var/lib/docker folder and listed sizes to find: @:/mnt/user/appdata$ sudo du -h -d 1 /var/lib/docker/ 3.8G /var/lib/docker/containers 0 /var/lib/docker/plugins 86G /var/lib/docker/btrfs 36M /var/lib/docker/image 48K /var/lib/docker/volumes 0 /var/lib/docker/trust 192K /var/lib/docker/network 0 /var/lib/docker/swarm 16K /var/lib/docker/builder 0 /var/lib/docker/unraid 1.1M /var/lib/docker/containerd 0 /var/lib/docker/runtimes 0 /var/lib/docker/tmp 90G /var/lib/docker/ You will see that my BTRFS is being reported as 86G, which is larger than the docker image file even is (now 50GB, but this was in place when it was 30GB as well). Taking a look it is in sub volumes that we have a ton of extra sub volumes. I currently have 30 containers running which is on the high side - but I've never (prior to unRAID and consequently btrfs filesystem for containers) had any type of a storage leak in my /var/lib/docker before. The output of these sub volumes are nothing egregious either: root@atlantis:/var/lib/docker/btrfs/subvolumes# du -sxh * | sort -h 1.1M eae47d8a38ed1eedbc002014f17c680c76b4cde2a5b4250d308a61549d6ee153 2.6M 2f93f2b7b7811af0b32f463d7f1e39674427eff7f7b44e0d3e585a1095af7434 5.2M 60f306eade39f8854337230270c9a06f392328063f643541b74a2a18371b154c 5.4M d42edb5656bad4df518d0f9d5e19569790f0b69e0bdf74c8ea30623fe5206f9a 5.4M e1fcd3ce1b28f7a70e491076bfb1f717589345a32fa1ba978c408e9937843c6d 5.7M 1826c5d8f5db82b82f2147d115115f5ff3c73adbe4ce9da1e88a83e014ea6642 5.8M 51150ab124d86e87504b9887f1e2faf10ca5a48ad86e6e0a6a30395e63cd5d77 5.8M 6e2640f1ad6635163d7b475a1946f813ae81bb44fb01ea8e9eee1935b1233ac9 5.8M f3b099991fd73ed23bcb3f7cc371c67eb280253e002d5ea53fc1953b72853775 16M 1b8f55ec77fa310426338fffed1f398ba813d1025140f0b6b5978196bc3c6dd7 21M 4023ac1ebd1ae9b5f6df830a4655c90a7a31449169f2c6993472a7bc60498072 34M 45089d9aaee13cb70ea2204afd93d3caf8519c8be4a87c9cadd570ebce73bfd5 34M 7eee4c44813fb040826268bcb9a9acca3778a8cc07463065416231d58f18dd7c 34M 85a3e9176d0e2e86f3606bc452513acc832c286ee74a28887944ad049e346253 34M aea04f7e63c556b6adac7b72a09b9430b4ccd1abcc187a270de4e08f1d177d9f 34M c1abbae59ea2a9fc62de72b769141c0dc4d9f06ddd817f4c1924f114e76c7f87 34M c2c3e264fb8c385d01ddf7bcbc1a71dd946ddaf73db32d15b779b36f851490c7 50M 31da84c5e712f5bfeae00791fc2305364719d3c9b0bc894f113631c1e77aab37 50M d81c62a217a883da32db9408cccf5f91e7d005c23f5ce4305ffae9f4ea751c11 50M dba43c99d7bf64ac1f5f7c32917158c4623176eb88439155ec902985a0912bb2 50M dba43c99d7bf64ac1f5f7c32917158c4623176eb88439155ec902985a0912bb2-init 65M 0cf4dacae886d490812d88fd40c439cdc50f58d1718e6ffe4c47dbae50028452 73M 0bb2cb81b16f30d37e880e29eb668d4c81c916cff41680102537f662e19a2f6f 73M 51a293900b87b155ed4be8f16f199c32a78a756533418c3e0a93917ba8117a54 73M b07901e11a867812b3487447e45237439bed37e76f1b696f05f2d71bc8d06e6f 73M cee1023cac19f9ee496b2b3fcb3a9453694b5c981885649cdf49a48aef375e99 83M 159aacd58dd1681b2c48cb4c538c37ed08b3bdd365e83decae12dac00b542631 83M 306cd9fd31fd4820e54335fdb35f55db350deca133a76ee99758bb8d282829af 83M 42ecf01e16982e8bf62758faa6708a23779c7a010319381346dd09b0c003ebda 83M 42ecf01e16982e8bf62758faa6708a23779c7a010319381346dd09b0c003ebda-init 83M bd72e0cd897e33c408fefba80b2428b797d24a92bd68e28789261bc352208554 86M 317b384e3c623644af98b3b2b2c3fa334ca65813dc134ac9cc05dd6019088742 86M 57e7a57eed037f56f626fb3061d59e55e4d9c3460006f1877e2a3cee401fd9e2 86M 6ceaa3a15538b3d0d9ab2347e37b30c2bdfe8f260dd92279ce19575c705f5e55 86M 6ceaa3a15538b3d0d9ab2347e37b30c2bdfe8f260dd92279ce19575c705f5e55-init 93M 27dd71c86dee5c4ac2ec6413c52824ae20ce53323c49317ee4fa56013bed4bbf 93M 27dd71c86dee5c4ac2ec6413c52824ae20ce53323c49317ee4fa56013bed4bbf-init 93M 3cb0a13d5f426ba16ebc102660719721eda9d26b61bf2da04399b397e0bb87e8 93M 9b0b1d71544915b1210476d2340b26a5277c211f537695c5824c5fb12ea9e3ae 94M 56a44721d58f48e559d79bf85847dd860943a26eaab7e934065dbdca6edc301b 94M 5c25926e3af13548660502514877e0b5390cd972c7e3e27ad4cf8895d3d22011 94M 5e864b1d0d89e7360a3d1aa8252c6ab016a0deda89d4b5e087f50f31fca13bbb 94M 6ae4666e4d4c96fe2249c9b0d95246b179038b87c61546b3496fd22b38168982 94M c89f25c72c98a7f1bdb38d1dd81b3f49bbe508ecb9f335b0390ea07c1195b828 94M c9aede6a2d59183fdaac12c1b816c7a3e063acc5a01685686a3f11711a4239fe 94M d69a7046d531c93cfe5a33876a85a197783b5a2108c4d2cbc2a59ab0418c26a5 95M 21fb4ec4c2b9204c248dbb7ae6976c067c628418ee1d5c1a916f8618402f9426 100M 019df745833ce1d95edf1f7afe8c2627a012e1bb556236b92f269fb5150dddcc 106M 03a5ef8b72e943aa7b9f303467bf1ccf4df5ab964d38bf098c7f0b7a75c64556 106M 161fabdbfcc4e41e659a12fd0a5cb6f4e556fdc005dbc994bfbf69ee8bc18ccb 106M 641a16797713760becbcf42d68611094fcb25b56189c852ed2beffefc335b9bf 106M d23b5ed845f9fbe261e85771eed9466eae1a3b98527ee3fe8fb38e59d7525157 106M dd7551838a62b4e947c9ecf55430b11f27b32b7389a15fdd50f94d85b001dc14 113M 1dcffa13be14052fab6d8a6db8cd41a87472436f57f342624eb862c16d4837d3 113M 256c7a8edfc82497014ff897551e4519599de3688cecb999e4f617f23023be76 113M 409c79857f7783d27df51d52957243e008b56182bd9301c84547c842e27542be 113M 4638e084710c470c404e06429a80794bed3fe5907ef97f3d12538f2bb816a782 113M c48577aa04ae0485eaf7d05bbe94276c7770a837b358d6f4df1a81d4156eb590 113M dbe120d606a5df704ea96c532e4e2d0c3400d04c76975a15a2c39c08e333a066 113M faabee41407d94c07d6ac0146f8e08ad24c46d709c523a0b8fcdb9feee50a9ab 120M 6627a10bf36b0c854107eaf725ea4bb1c362d57b4f9484dc312134624291ea39 120M 7571b5e746dceed177a36256bad295fc85bd430533279f06c558c173e6a18f1c 122M 827031c7bf504eebc164cbc7ba3d8eb4d00a13599b15b784d1805b92972daa05 122M b448f31dbc02653bf848a23bb23880eb67ecaaecf9755682c8ccd2640e457535 125M c1934537f27888874518f4d12eae742a3437f170dbe8bae855fed9eff7dce4fc 125M cba72de932a2782e8d1e5a79beba8be692fbc76e828abff43cfe2cff15143667 125M d83f56c20f1c6f0f0fce87d209960bfde39b45812b65643b4c99dbbb092c9018 125M dd1e61ea89e104f5b5d6044c4d9d1fca230aa862b264a28360edfd12318915f4 137M a51ead5b2d0ea7b361c5b1a825937aa60ecb8c70ad7bc51bd71cdb1f12b21632 139M d1d77ab385587fbed68276c867eca96d785a3370dbcce74cf9f6daa9c443e095 139M e85f9385cd956676316ab343ef8fdeeed324b34d78ffb9d21da4f819a9b909b4 142M 6a973648522183e0418e236fc9258b3e5328df63ae021a29d0cbd2c6aed0d69b 142M 71ae07821da62e7cb846b996e84ff6e8e032eadcc1a6282686e115174b7bb590 142M eaf8e7bbd236d39ee0c14b40ff337c5eb44896fb688accf39f6283443cae2045 144M c3b849058523eb1b17f7d5efb57f16f72a3ffc742fe7c850b2f5eba95424e0d6 144M ccec025d23f751325de96efd70ead044b4f66f587a190fafa403e7140b1c2129 146M e99c026bdc378b6a244c14244eb478793c603625824991083434ac251688aaaa 146M f845b4e4e0979989cbd62dda016324a98f4a453ead777ee581aedc4553599ffe 149M d7141babf8de1cdf9c946b8c7be077d1e096d615a462e2b388f6c914631033d4-init 150M b881d0a6881adf5cc5376fe93420f4f98c86ec0f6842fc6a39e932c1ae44c4e9 150M d7141babf8de1cdf9c946b8c7be077d1e096d615a462e2b388f6c914631033d4 167M a66ee2cbcb02df2128656e0c768dfcbe7a19407bc1576601f93e3039ca157ec1-init 167M dc35396a56b298b990640022659da5273c044fd6aec20ac9114699dbd7a1c768 167M ecc06b0d8b34dd8bc9b064a94262c4cd46e5aefa581131c33b4f6a998bf01cbe 184M 0b7035bd4ecaad2f77c3f488ee5c36e7cf0053abce73d8bb98dcde706bc18497 184M f353be15438616285235b88821dec1a848bef64be4c72d49f0aff7b877a5b876 184M f353be15438616285235b88821dec1a848bef64be4c72d49f0aff7b877a5b876-init 184M fdbed6438e461d49fe324b951e6de7f5f11d16c41ba005846f66a10870c870f2 200M 36457934f80ea3e3cf96134a75e3d9a8892b902a85878804b37ea05ecf703adf 200M b1864394511acdd896e8b9cc064a89364a39a077e377ed01a517c7df36519249 200M ba57ac95517eeef742a1f863eb49e62a34df6c7355bc506ca73890f48e5019ef 202M 1d1aeeda3c77bdb3dbae28188f70c649bfcdf389a52b8a10836133ff4e345ca2 202M 90e428748d489c7d6554ac4e5a97a5887332d08c56e6647ae36399dc163071a3 202M 90e428748d489c7d6554ac4e5a97a5887332d08c56e6647ae36399dc163071a3-init 202M e0a548276482eb1bf2801f465e3fcdcf8175ace03ce372cf63e23402ddfe39ee 207M 0b57bb19ef75abf6913300b00ed9cea58321d2424fe3377993fd0429bbc83bf1 207M 1018431690cc6aa0e4afde37cc24bf77c49dc8eef4a6ce33392836b7ac060e9a 207M 117865ea514494a8477f856c8ac2d7ff3874ce3edb4c1c6c8772134d271a82b2 207M 1ee75f9042b6e8fa956295b1f70dc563073f93815d15318050912628e67fe1a5 207M 24b4d5a4fd90b28f35d8c00e0e02374aa36a101d4ab6155fab546402ed95e818 207M 60db46e9c9f992adc1cfee6417c0eb7cbed4ec21f70af53febd64c5d0f76c0e2 207M c1b4b507874c4721884b695351c5d1b81d10f944cd3e58e9c754ceb0e07a7f4f 207M cad7b9ab15e3f8c43514e470fc547e279df5f7a6c83f55082f6a6b0cbbf6bce1 207M e952946c9126b082e7f16d07773ab087cbcd5b284290a1a580faa064094ba0e6 207M ea413a0712246af162f303b6b540d43054515a8180ba62be8b7b01f6ddd37882 207M f757633150ef97474470a8b9072b66473a2f489775549533d2733b59b21182ba 210M 6510a8f21d9b8a9629ab0a88b8c517a315bf4075f9df71eac1a8e839c52f8e4d 210M 6ea90a39fa380cbc7b7202e629db0ac7c2952e1f8b193484db1965a18306a95d 210M ae0fa8e88f693ecf28ea87831321945118244346de46b75d979186708c273ce7 210M b7ba5569d12cc29398712257f286008dd18a02bc126c238e22f872dc968bb6c4 210M e06ad5c010f619704b600e482acbf28ffa2f7f8096ce208c22f1db2f34053123 210M e95146d30a484c634f6259b741975c52794b6233d3725d845c997ae7af1249ec 214M 0ca85375bbaa7dd0f1246ac1f5441c5b919a7183e4012d9ae519f0141fc81155 214M 43d18a73e4fd8de8b777b3f6f24e5c723323ab3767ae394406ede49bf4d7eaa9 214M 43d18a73e4fd8de8b777b3f6f24e5c723323ab3767ae394406ede49bf4d7eaa9-init 214M 94c1770635600a96b567491a6b05ebde3acb6646316e01c60fdcdab4821fcdb1 214M 9c1c82c61c48baa4816da750a1044a60bf8b368d30849e4b317cef43db6b3f9a-init 214M cd74edbbdd5ff89fa478d32d75556b13e1ddb74389911010fc1fd55932408a03 214M dae84cdff5db65c5ed82259d4a9ed3b464ebc762df72809bff1c2cfef1e7c2e9 214M e6cdc860bf2f7c629aae2e223416b2b2aa0799befe60d941e6807ba5c948fb03 214M f224ae2f08c0f1b005c7bdd64520ff09c06aa05b2802f7f8e3512f758a6d8538 218M 9c1c82c61c48baa4816da750a1044a60bf8b368d30849e4b317cef43db6b3f9a 227M 53581e50c7f962dbb4d09fa2cb3c3f2092e4645b510f3655b3a947fe866be736 229M b92522200e55746c8cf910e6504800512268bf7460f8657052944f76ae1664fa 239M 1ef890602c1eb86eb9dece32887a1cc2cba5513e80b2db7d99a10f584db08155 239M 25f0870c902813c5342fd90ae28ed094c6cea915ee4a5f4b4137f08618822f64 239M 3848de1aab0a0bfabb5f0b6964f7ab3d2c0928fbfca451c39343b76e23ff6003 239M 5ed3ec92b5e40b7b5c933afa677984f336f79164b443acffd8170621c40fc8b3 239M 7f3bfb06deb2413caa2d28b1f4d119731c15c28ea562e539728435aefd7328d5 239M 9284cda28205144f0db06878e0810f3ad1fb2afa25ac472d3687589ad2b73c30 239M 9284cda28205144f0db06878e0810f3ad1fb2afa25ac472d3687589ad2b73c30-init 239M a8ad9a415344b48a99d8a33eb71e9a9b62280e78296b2de3995def0f440641ee 239M b11f49f28a2edb14d422064f094a19ab8e09eed96dbdc5a29a19a90259de9a90 239M cb227117316c6c8ca915b619c59920e5100ebae7b04b2dcd1313040d9e2a2a19 239M e36d593727e46c1050eb0894bb5bbc107db5260a32249fe0e33b7d5a0808866c 251M 0c1f948368b05fd51eed24917938f15630bcc23895397147bc7e99a2d73825e3 251M 4a459acf6511b5a80d4361f7c838c5a6cddf23f9bbdefe500f58bff39440c8f1 251M 4a459acf6511b5a80d4361f7c838c5a6cddf23f9bbdefe500f58bff39440c8f1-init 251M 63341cdb2b2d11a6861c8518c1e32a6c47104bf3ec5a8b75285c230157a7dd56 261M 35e6d0e909bb54b312cbb5e0f6192ce5b6204d8d5fd38985ece71cab49d3ae4c-init 261M a6e66922ee6b455ee27645863c8a4edfe66b9aa133b361378dde018cf8246912 261M a9d70cadb8c6c3f45261f730a612f3903f1c65c15f4f830bcdfb599c24bb7f72 264M 35e6d0e909bb54b312cbb5e0f6192ce5b6204d8d5fd38985ece71cab49d3ae4c 286M a66ee2cbcb02df2128656e0c768dfcbe7a19407bc1576601f93e3039ca157ec1 289M 218c750bc650e1f37ae104a3c8780d7c47f2f2023c475c133db4c7bac3a5c2f2 289M 3310f9160a13bc00d5fc1bdd540526ecb3bffdfcd9b6a045b4ae172117663cd5-init 304M b955b9dfa67d22b3d11279f8831018f96b8f6d390fbe44dfd182c1381d1519a1 304M be9a3ab2c43a14c61d017f1ff9de0dcd786323642a75204a19feab901a8b6fab 304M ddf748d6849b94920f0a7ecf3cb6fb7976493a70d97d366323f5c76829c8cbe9 304M ddf748d6849b94920f0a7ecf3cb6fb7976493a70d97d366323f5c76829c8cbe9-init 315M 9e9a8cd2841707be24879d6c1ccb8b821076e53f7638919ed3e622d669aebcc4 334M 3310f9160a13bc00d5fc1bdd540526ecb3bffdfcd9b6a045b4ae172117663cd5 336M 082a6cf663ba5601c5a2e465453a8cc9bf9f3a0749b56ffdc95ca37d18aebd85 336M 2c8438056e0d2869464ed5bbbd1b39d446b26b1082189aa3408c8c9489be7140 336M d1f9c2d2235edba86240c081462df24ab8fad97659bddb249cce88807542e510 337M 11e0e0437524a7c98366c7055555778b4a8837b3e518acfdba8e3c3bde6736e9 337M 11e0e0437524a7c98366c7055555778b4a8837b3e518acfdba8e3c3bde6736e9-init 337M 5dfd628ec5a1a2c3a3465d1b825175c5c7d09ea4a1016488666a66aaf42ace56 337M 7dea7749dc96b738dcc958563a2b6e9dab0e64a0b5296abf2339c59c4c9dfe3b 346M 38cdf9ed1e0787e63fd9243f6b495ccd207c1d7338f180b2917ea16baaa80135 346M 38cdf9ed1e0787e63fd9243f6b495ccd207c1d7338f180b2917ea16baaa80135-init 346M 5d18cbddd20ae6d544bbf34d29d559ea350353ca1f3c09842c5d81a08be34740 380M 563802d72a33e15a896a2e14a02112217d9a5fcb8ebf831ab7bafc29763c44f1 380M eacd2672bcd318217578db6bb9fa6ae61be3e3b15a8f07009780135e0ad06bef 380M eb337dd451f1af89a38213834adb32583b9738f2246687bf3a2180b5d090e684 380M eb337dd451f1af89a38213834adb32583b9738f2246687bf3a2180b5d090e684-init 385M 817971bea6f4732e34051372338034bc0f57bb8bbb19929acd34118be7ddfde5 386M 0278c225a446adc6566811030b688d184724c633c298c15854e5f0e85e8d2ed4 386M 6bd0ee78bef1b133ab9ff361d4b623154fd736c367c3685e5cba8979f8c92e52 386M 7a7597e35408d5c7786ab074b48ac681bbb7a33f95941d0cc6c72149ee4b2e7a-init 386M 8d38ba99bb191aaf95c7e8a46f3f2ee340f334f0d4cb9a322636994b6eea9f02 386M 9155856eac6e9355b4fa53484c0e0e9c497b0cdeb32abf9aeaf6e265d1499615 423M 1ace2cef3b922889ae5186cb4ad55fbb2ec83d94043384f3f39a81e5536b6ed0 423M 72f8e9eef9c88df02fd5e9c6fd99f94cc7b2b24b14330c4c95937380c8f5ab04 423M 8e3c1902111cd91313b26eb3fadcd7aeca60a3ec550a15c708e2287ecb3f9115-init 424M 8e3c1902111cd91313b26eb3fadcd7aeca60a3ec550a15c708e2287ecb3f9115 427M 08ec002bd02665d43216c18a69c495d7de89d59e2d9465d97c69c1fe936c5bd9 439M 7a7597e35408d5c7786ab074b48ac681bbb7a33f95941d0cc6c72149ee4b2e7a 476M 29aad61aca3a16c250a53a57b4a9a30a44d13386c5b69c445f6ac72a73af13b3 476M 2f77202a233fa1d11303f1860a646d14fdeb0ade9e52b3e207d8232a7fb0bf1f 476M 38bc90ad2404ec64efd0003e7f2b6feeaab1299f37b1d11ef3275dad25290b9b 476M 3bd3899449ee458869a80aec539a909218d47cc2afd76cd81f360b6278aa38ed 476M 8fac4629baba102902ef29ff8f24429bf033408f8d5bcd5ac1231f4064923064 476M e543352573c9c6c6cd0abf7d5376293cbd60e5aed8b878c2727a39e27488245f 476M f046f7e59bd06a6bf0c12742ae729485a08238d99d3c62003528a7b5a84dbdee 476M f49ea2fc3973dfbb9a5c535be83348544b856b83041aa27113301714b2b5343b 479M 3a58e005f2f0c0713fe8a6194c8e81f4e7407916808a05fb8d9a628e4237e126 496M 002546e778c5dc5ec3c13f65af5f1f9984e37eeb56320d327259b6baf1b80b76 496M 235a4810a75bff22e31b17bc883026cbb18aa05ba0e574b0e17b6bd2203022a1 496M 28df5a7c9031ab77499efa9aac616443ffc7adf9709676d716b9d66473164456-init 513M 28df5a7c9031ab77499efa9aac616443ffc7adf9709676d716b9d66473164456 537M 0f5841ec5bcf2aca6d6395b4d72d4c4c1dc47f0383cb02b26808fe63b40090f6 537M 247b47dcc57fe868b28cb046b4b3f34d623ff712cea2dfec19016c09e791bac3 537M 413ddbf96a7cd9fd4e9308aae10302304483eb0464982e2a3ff6539458b5f6cf 537M 7d6af6f6515d8813e2a09c591d5b66a1e38efdd82ae9d740b1d9b6577dae9c71 537M 831417954f90d123329e1171126960676c03e686aa81649cecef7b2d3d9970a2 537M bb3f3b8b2695de0ae312d39137eb2c8552ad2ad721561b387ff7d9de62347b45 541M 5b0832fd5bdd4479ed740392793ad30bc689372a11931c6c2d1237ea1219b9b3 554M 537a85f65d73849fe38228382a18b549209c26904602d9b5f24c4942b2439e7f 554M b772706804a30d91f301e1c1e31ea8239079cefd81f97ba2aacd9042ac3ff13a 554M b772706804a30d91f301e1c1e31ea8239079cefd81f97ba2aacd9042ac3ff13a-init 554M ba112638425105902d2f00183777d361f5ec0a1fb442a83d77cad457fa2ff9b6 559M 08ecd517b2dce318568664afc70e69cf2886f1d5c6e96d43ce23ab33a2d73432-init 559M 5088f5868303978258828bb622982a759d1be59307006d92b39f9d25d0137e72 559M 87433e1dd2431662312cbfa358eb45d0fad1325cefbf1024dde1dbf181d6c240 563M 1ca332e4ad1457390e6dfd11e6d9bafb624cb8759bee9a3904474188e7b27260 563M 1cafc07cf9709febea022d494bb2491c73c55718011bb6aed036217b513ca5cb-init 563M 42c573ccd695ea2fc8a397b1059e79f4b878ce4c959657b81bc45bc106a5f4f6 563M a6500c11bfa795928a6d514154f6b4b9191dee11da9a8a404676db94d5a1d45c-init 565M 1cafc07cf9709febea022d494bb2491c73c55718011bb6aed036217b513ca5cb 567M a6500c11bfa795928a6d514154f6b4b9191dee11da9a8a404676db94d5a1d45c 577M 08ecd517b2dce318568664afc70e69cf2886f1d5c6e96d43ce23ab33a2d73432 619M 502dee745012138f372c15434aa708cd8e682e3d85d090bca30fff334389db1e-init 619M be1e2559baf73e3c58e29e13dd12c46bccf06495022fad3f2f9c11524b9b277b 627M 502dee745012138f372c15434aa708cd8e682e3d85d090bca30fff334389db1e 709M 5e0113493bf36106842c6dfe16dbf954918cecf825e91bb128bcdf887a989b72 723M 125a9fecd423d475c0037ef1008af448990eb864c2e0b6cd9b2635706558c3fb 723M a20bc29aa68567f3a9911f79a5ea303e2d168141948a53cbaa3ac217581d6714 731M 5aae520ecc18a9789dcb3635b511aad45e49fc51291366f593347df3a7d16bdd 741M 7d112d8e163d9e4271c95180555610b341ec66425be87177db29607d5616e3e5 742M 708fba493697769ebdf1de0511367bcead6824bb0b1d288cae19db0f31a2e93b 743M 05ef5ee983ebb49cc1d91aa2f79acf497d28619b0858690aa6f3d10fd6e1a2dc 743M 0a661ca9ecefdcfc59f7ba2d88cf3ab2dbeb26f4e3cbb8a8193748dba63d4f59 743M 10464d9e5a9a83fa9bbd3f225248ff2c4e08ca311d5073851326bafc909a8a36 743M 135df251013e0504aa9a21fb052da199a029039e2174a56b6297c59d1e8f34c2 743M 31cbcfb7611cd1d852f99c820f46e3a079b31d244f03a29079b48de702be4337 743M 5ed78f59ab9211ffc3ee365d5809b07884d5fb502ee977232d5baabc329b3026 743M 5f92385dbbd7d72f0d60f9cdd58fb5b510bed7f3f9baa3a67a5c97579e1472d3 743M 6ea063a2c8b3d327617361f1eba58c62252ce341817e2c82851b7684713f47c4 743M 7c48436be2fab9ea67fe16cd12772c1b177e85497be587e9fd5926ac2378bce2 743M 9d352569400bb984d2eca57dd24fcb822a5431476716ea085d8b612f44453e6a 743M ad38c19c3f2ed69a2b55506a049dc5287197ddbaea8c401538b16537a5965ed4-init 743M c7de33d0cf66430830bdb02705449c04a048ccf656c7afae7e78d71872a01802 784M ad38c19c3f2ed69a2b55506a049dc5287197ddbaea8c401538b16537a5965ed4 875M 7239d63cda86041cdcfcb2e6bc1c4513b9ad0a01dedd340ad8e03f713dbee26a 875M c18bd9a461d538fa18fe7994559eb7d9f817264f57e8495245d4583a09d981a8 875M c18bd9a461d538fa18fe7994559eb7d9f817264f57e8495245d4583a09d981a8-init 1.1G 0a07ce1bdade19c3275ee33782f32fbfc1ebeddd6393a2de491fb4fb7964d1da 1.1G 327b85be34d8fdb6042b8baf61fc4291b21ece5e5668dbf4df303adcd8d1ff15 1.1G 39daea1185657afe105be1a929a2de10f25583fd79ab5d2b0f9ecbe07d7e39cc 1.1G f81eddba418afe7cfa6540c8341aea690e7ebd4f1347c93e863a66a47c0a836f 1.4G 5e98c0f75d41caf2dc705c94cc6d1039012cc04014acbf1d502ca31d18fd70d7 1.4G 6e72c4b6b0b4e87511776c0b142c466131e87361a36c4c6cf3669890c431812d 1.4G 6e72c4b6b0b4e87511776c0b142c466131e87361a36c4c6cf3669890c431812d-init 1.4G 95901513e8e2f932844dfbada270bb507c88fc52855c297c105f5e56435d96e7 1.4G ba40fbae24440c154ad51657e9a2121280e119d448872bb602515d76620a9630 1.4G d77b5a5f6f8c4a9b3d80a070b5d6f231cf9bc2cbd54f588d2780011ff607a73a 1.8G 2af09ce414b6af6cab378861ebb104a7dcfa613037c66a976b7bcd46b666c8d7 1.8G fef68223fc9f013c16a3583983684bc899d3066e400ee5a9039773d1a92227d3 1.8G fef68223fc9f013c16a3583983684bc899d3066e400ee5a9039773d1a92227d3-init Not trying to say specifically this is a unRAID doing something wrong - could be unRAID, could be BTRFS, could be Docker. But something is not correct here. I'm linking two threads I found on github for issues with Docker where users are reporting similar circumstances. What many will illustrate as well as its usually a gradual growth, which mine has tended to be since I've not been bugged about the docker image size very often at all. Once when I started adding all my containers initially (30 is probably above the norm), and second was today as it approached the 30GB mark. What's most interesting about the above output, is that there are a plethora of duplicate sizes which leads me to think something is not working quite right when updates are pulled and new containers launched. It's more than likely these are duplicates but I can't find an easy way to identify which ones could be removed. I regularly pull all new updates to images on a weekly basis, so it seems very plausible and likely that when new containers are being created - something is happening incorrectly with regard to docker and the btrfs filesystem. I also have "docker system prune" run via user-scripts the day following the updates to remove any leftover dangling images volumes containers etc. Validated by running manually that there isn't anything to cleanup. Github related issues: https://github.com/moby/moby/issues/9939 https://github.com/moby/moby/issues/27653 EDIT - Updating Analysis: As seen in the output below, 3 of these sub volumes are EXACTLY the same data. Same dates and sizes of the underlying filesystem that is seen. The file content is exactly the same as well. I could likely do this among many more, but its difficult to output this analysis easily. It will also be massive in size. Will see if Tree is an option to output and visualize the duplicate structure. (Output from above, focusing on one set of the data) 1.1G 327b85be34d8fdb6042b8baf61fc4291b21ece5e5668dbf4df303adcd8d1ff15 1.1G 39daea1185657afe105be1a929a2de10f25583fd79ab5d2b0f9ecbe07d7e39cc 1.1G f81eddba418afe7cfa6540c8341aea690e7ebd4f1347c93e863a66a47c0a836f (All three subvolumes directory listings - EXACT matches - perms, dates, sizes) @:/var/lib/docker/btrfs/subvolumes# ls -la 327b85be34d8fdb6042b8baf61fc4291b21ece5e5668dbf4df303adcd8d1ff15/ total 24 drwxr-xr-x 1 root root 132 Jun 25 17:24 . drwx------ 1 root root 32300 Jul 14 11:36 .. -rw-r--r-- 1 root root 1276 Mar 1 10:13 README lrwxrwxrwx 1 root root 7 Jan 5 2018 bin -> usr/bin drwxr-xr-x 1 root root 12 Mar 28 16:45 boot -rw-r--r-- 1 root root 101 Mar 28 16:22 build.txt drwxr-xr-x 1 root root 1594 Jun 8 16:22 etc drwxr-xr-x 1 root root 12 Jun 8 17:36 home lrwxrwxrwx 1 root root 7 Jan 5 2018 lib -> usr/lib lrwxrwxrwx 1 root root 7 Jan 5 2018 lib64 -> usr/lib drwxr-xr-x 1 root root 0 Oct 17 2017 mnt drwxr-xr-x 1 root root 0 Oct 17 2017 opt drwxr-x--- 1 root root 124 Jun 8 17:36 root drwxr-xr-x 1 root root 72 Jun 8 16:21 run lrwxrwxrwx 1 root root 7 Jan 5 2018 sbin -> usr/bin drwxr-xr-x 1 root root 14 Mar 28 16:45 srv drwxrwxrwt 1 root root 0 Jun 8 16:22 tmp drwxr-xr-x 1 root root 70 Jun 8 16:22 usr drwxr-xr-x 1 root root 100 Jun 8 16:21 var @:/var/lib/docker/btrfs/subvolumes# ls -la 39daea1185657afe105be1a929a2de10f25583fd79ab5d2b0f9ecbe07d7e39cc/ total 24 drwxr-xr-x 1 root root 132 Jun 25 17:24 . drwx------ 1 root root 32300 Jul 14 11:36 .. -rw-r--r-- 1 root root 1276 Mar 1 10:13 README lrwxrwxrwx 1 root root 7 Jan 5 2018 bin -> usr/bin drwxr-xr-x 1 root root 12 Mar 28 16:45 boot -rw-r--r-- 1 root root 101 Mar 28 16:22 build.txt drwxr-xr-x 1 root root 1594 Jun 8 16:22 etc drwxr-xr-x 1 root root 12 Jun 8 16:22 home lrwxrwxrwx 1 root root 7 Jan 5 2018 lib -> usr/lib lrwxrwxrwx 1 root root 7 Jan 5 2018 lib64 -> usr/lib drwxr-xr-x 1 root root 0 Oct 17 2017 mnt drwxr-xr-x 1 root root 0 Oct 17 2017 opt drwxr-x--- 1 root root 124 Jun 8 17:36 root drwxr-xr-x 1 root root 72 Jun 8 16:21 run lrwxrwxrwx 1 root root 7 Jan 5 2018 sbin -> usr/bin drwxr-xr-x 1 root root 14 Mar 28 16:45 srv drwxrwxrwt 1 root root 0 Jun 8 16:22 tmp drwxr-xr-x 1 root root 70 Jun 8 16:22 usr drwxr-xr-x 1 root root 100 Jun 8 16:21 var @:/var/lib/docker/btrfs/subvolumes# ls -la f81eddba418afe7cfa6540c8341aea690e7ebd4f1347c93e863a66a47c0a836f/ total 24 drwxr-xr-x 1 root root 132 Jun 25 17:24 . drwx------ 1 root root 32300 Jul 14 11:36 .. -rw-r--r-- 1 root root 1276 Mar 1 10:13 README lrwxrwxrwx 1 root root 7 Jan 5 2018 bin -> usr/bin drwxr-xr-x 1 root root 12 Mar 28 16:45 boot -rw-r--r-- 1 root root 101 Mar 28 16:22 build.txt drwxr-xr-x 1 root root 1594 Jun 8 16:22 etc drwxr-xr-x 1 root root 12 Jun 8 16:22 home lrwxrwxrwx 1 root root 7 Jan 5 2018 lib -> usr/lib lrwxrwxrwx 1 root root 7 Jan 5 2018 lib64 -> usr/lib drwxr-xr-x 1 root root 0 Oct 17 2017 mnt drwxr-xr-x 1 root root 0 Oct 17 2017 opt drwxr-x--- 1 root root 124 Jun 8 16:22 root drwxr-xr-x 1 root root 72 Jun 8 16:21 run lrwxrwxrwx 1 root root 7 Jan 5 2018 sbin -> usr/bin drwxr-xr-x 1 root root 14 Mar 28 16:45 srv drwxrwxrwt 1 root root 0 Jun 8 16:22 tmp drwxr-xr-x 1 root root 70 Jun 8 16:22 usr drwxr-xr-x 1 root root 100 Jun 8 16:21 var (Same 3 files cat ouput, exact match) @:/var/lib/docker/btrfs/subvolumes# cat 327b85be34d8fdb6042b8baf61fc4291b21ece5e5668dbf4df303adcd8d1ff15/build.txt bootstrap tarball creation date: 2018.03.01 root tarball creation date: Wed 28 Mar 20:22:35 UTC 2018 @:/var/lib/docker/btrfs/subvolumes# cat 39daea1185657afe105be1a929a2de10f25583fd79ab5d2b0f9ecbe07d7e39cc/build.txt bootstrap tarball creation date: 2018.03.01 root tarball creation date: Wed 28 Mar 20:22:35 UTC 2018 @:/var/lib/docker/btrfs/subvolumes# cat f81eddba418afe7cfa6540c8341aea690e7ebd4f1347c93e863a66a47c0a836f/build.txt bootstrap tarball creation date: 2018.03.01 root tarball creation date: Wed 28 Mar 20:22:35 UTC 2018
-
Ok so to be sure I have no issue, I'll want to just re-create those scripts ensuring only LF endings. So I don't want to link to this directly. Thanks for the direction, and the great plugins!
-
Aha, ok cool. Glad I asked. I was thinking it was like an override. I would assume this means I should be able to easily link to scripts setup in the UserScripts plugin, just pointing to /boot/config/plugins/user.scripts/scripts/pause_statuscake/script for example?
-
So forgive me if this is mentioned somewhere, but my searches on this forum don't always seem to come up properly. Aka sometimes I see no hits when something exists. I wanted to see if there could be any clarity provided on the "custom start script" and "custom stop script" options. I'm trying to understand 2 things about these: Are these for custom scripts that run the backups? Like to override the scripts that are actually being used? Or are these intended to allow a user running a custom script at start/stop. Are the start/stop referencing the start/stop of the backup? Or the start/stop of the docker containers to process the backups?
-
I would like to suggest an option to backup the header of encrypted disks. Currently if something catastrophic was to happen to a disk and just screw up the headers - the data would be irretrievable. While I know a solid backup strategy should be utilized - there are scenarios wherein a simple recovery of the header could void the need for restore from backups. This can result in a quicker/easier time in restoring data on an encrypted disk. It's also possible that this could be used to simply get a system back up and running.






