




Andiroo2
Members
-
Joined
-
Last visited
Everything posted by Andiroo2
-
Same here.
-
Did you ever resolve this? I found this thread while looking for information on pinning VM CPUs and I see that you have pinned CPU 0/1 to your VM. Everything I read says that you should not pin these, but you should ISOLATE these cores so that Unraid can use them exclusively for system management.
-
As suddenly as it started, my issue has disappeared. The container is working as expected again.
-
Docker Inspect QDirStat.txtQDirStat Logs.rtf Logs attached. I updated the container, no change. I also installed another QDirStat container and have a similar issue (not exactly, but similar). Something is wonky in my display driver perhaps?
-
Unclear...I opened it up like I usually do and it's just not working for me. Perhaps it's just me then if nobody else is reporting issues. It's been a few months since I last used it.
-
This container is suddenly not working for me (after many years). I get a black screen when I load the WebUI, and I see this in the logs: [xvnc ] Underlying X server release 12101021 [xvnc ] MESA-LOADER: failed to open iris: Error loading shared library /usr/lib/xorg/modules/dri/iris_dri.so: No such file or directory (search paths /usr/lib/xorg/modules/dri, suffix _dri) [xvnc ] MESA-LOADER: failed to open kms_swrast: Error loading shared library /usr/lib/xorg/modules/dri/kms_swrast_dri.so: No such file or directory (search paths /usr/lib/xorg/modules/dri, suffix _dri) [xvnc ] MESA-LOADER: failed to open swrast: Error loading shared library /usr/lib/xorg/modules/dri/swrast_dri.so: No such file or directory (search paths /usr/lib/xorg/modules/dri, suffix _dri) [xvnc ] MESA-LOADER: failed to open iris: Error loading shared library /usr/lib/xorg/modules/dri/iris_dri.so: No such file or directory (search paths /usr/lib/xorg/modules/dri, suffix _dri) [xvnc ] MESA-LOADER: failed to open kms_swrast: Error loading shared library /usr/lib/xorg/modules/dri/kms_swrast_dri.so: No such file or directory (search paths /usr/lib/xorg/modules/dri, suffix _dri) [xvnc ] MESA-LOADER: failed to open swrast: Error loading shared library /usr/lib/xorg/modules/dri/swrast_dri.so: No such file or directory (search paths /usr/lib/xorg/modules/dri, suffix _dri) [xvnc ] MESA-LOADER: failed to open iris: Error loading shared library /usr/lib/xorg/modules/dri/iris_dri.so: No such file or directory (search paths /usr/lib/xorg/modules/dri, suffix _dri) [xvnc ] MESA-LOADER: failed to open kms_swrast: Error loading shared library /usr/lib/xorg/modules/dri/kms_swrast_dri.so: No such file or directory (search paths /usr/lib/xorg/modules/dri, suffix _dri) [xvnc ] MESA-LOADER: failed to open swrast: Error loading shared library /usr/lib/xorg/modules/dri/swrast_dri.so: No such file or directory (search paths /usr/lib/xorg/modules/dri, suffix _dri) [xvnc ] Fri Feb 20 09:33:45 2026 [xvnc ] vncext: VNC extension running! [xvnc ] vncext: Listening for VNC connections on /tmp/vnc.sock (mode 0660) [xvnc ] vncext: Listening for VNC connections on all interface(s), port 5900 [xvnc ] vncext: Created VNC server for screen 0 [xvnc ] [mi] mieq: warning: overriding existing handler 0 with 0x1510c2e4f0bd for event 2 [xvnc ] [mi] mieq: warning: overriding existing handler 0 with 0x1510c2e4f0bd for event 3 [supervisor ] starting service 'openbox'... [supervisor ] starting service 'xcompmgr'... [supervisor ] starting service 'dbus'... [supervisor ] starting service 'xrdb'... [supervisor ] starting service 'nginx'... [nginx ] Listening for HTTP connections on port 5800. [supervisor ] starting service 'app'... [supervisor ] all services started. [supervisor ] service 'xrdb' exited (with status 0). [app ] Logging to /config/log/qdirstat.log [xvnc ] Fri Feb 20 09:35:45 2026 [xvnc ] Connections: Accepted: /tmp/vnc.sock [xvnc ] SConnection: Client needs protocol version 3.8 [xvnc ] SConnection: Client requests security type None(1) [xvnc ] VNCSConnST: Server default pixel format depth 24 (32bpp) little-endian rgb888 [xvnc ] VNCSConnST: Client pixel format depth 24 (32bpp) little-endian bgr888 I reinstalled the container and have the same issue...thoughts?
-
Where do I add this? Is this in the flash drive config page, under Syslinux config?
-
Update: It was my router. I changed from a Bell Giga Hub v1.0 to v2.0 and then all this started happening with my qBit access on VPN. I switched back to the Unifi Dream Machine Pro as my main router and all issues went away. Lesson learned -- ISP modem/routers are terrible.
-
Confirmed with PIA support that there is no limit to the number of connections or devices. Surely there IS a limit, but I am not hitting it. I did another test today though that (I think) eliminates the VPN as the issue. I set VPN_Enabled=No, loaded the WebUI and loaded a torrent. I then made sure it started transferring. I stopped the container, set VPN_Enabled=Yes and restarted the container. The torrent resumed and completed, because i was able to see it move from the in-progress folder to the completed folder. So, the VPN is connecting just fine, the app is loading, and it’s just the WebUI that isn’t loading. Where do I go from here? I don’t know, but now I will look at the network and IPTables.
-
No errors...see attached for a fresh restart and log file. supervisord.log
-
I have tried multiple different endpoints in different countries. I have also used the same OVPN file from the working container in the non-working containers, but that doesn’t help. I have copied the whole openvpn folder from the working container to the non-working one, but still the same result. Tried changing the IP of the container. Changing the WebUI port, changing my PIA password, port forwarding… I noticed that on my iOS app, I can connect but I don’t gat a VPN IP displayed on screen:
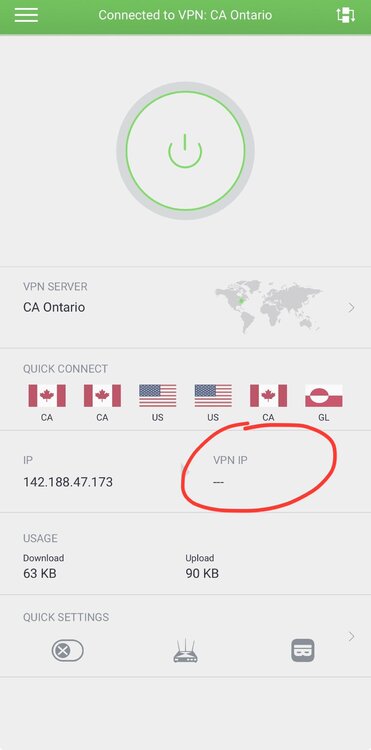
-
Been working on this one all day. Still no progress. I have gone through all 30 FAQs and added/removed/updated things to no avail. I can’t explain why one container works and another does not. The minute i disable VPN_ENABLED, it works immediately. Could there be an issue with PIA? Keep in mind this is affecting my binhex and non-binhex qbit containers (except one that inexplicably started working??)…
-
We’ll, one of my older qbit instances just started working again like nothing happened. No additional lines in the logs. Other instances are still down. It’s got to be an issue connecting to VPN somewhere.
-
I just went to the house, got on local network, disabled Tailscale in Unraid, restarted docker containers, same issue. As I was walking back I thought, maybe I should have rebooted the server with Tailscale disabled before trying again…I will try this next time I am back at the house.
-
Yes, I use Tailscale baked into Unraid to access my server remotely. I don’t want to turn this off for fear of losing access while troubleshooting. EDIT to add, I am NOT using Tailscale in the Docker container.
-
Can't access WebUI. PIA VPN. Long time user of an older container which started having the issue, installed this newer binhex version to troubleshoot and have the same issue. WebUI works when VPN_ENABLED='no', which makes me think it's a VPN connection issue. Changed VPN password, verified credentials on other devices, changed OpenVPN files. Looking for options here. Thanks! supervisord.logdocker run.txt EDIT: I am using Tailscale on the server but not in the container. I keep getting an activity timeout from the VPN server every minute, and the process seems to restart: 2025-12-01 11:22:43,314 DEBG 'start-script' stdout output: 2025-12-01 11:22:43 [UNDEF] Inactivity timeout (--ping-restart), restarting 2025-12-01 11:22:43,314 DEBG 'start-script' stdout output: 2025-12-01 11:22:43 SIGHUP[soft,ping-restart] received, process restarting
-
Huge thanks! I changed modems and had this issue...port 80 wasn't mapped and I couldn't renew my certs. Appreciate the solution!
-
This was it…a ZFS scrub. Thanks!
-
Pulling my hair out here...what is scanning my disks? Nothing showing up on HTOP I/O tab but my ZFS pool is showing 200+ MBps reads per disk for hours. What can I check? Open Files plugin doesn't give anything concrete.

-
I have 6x 8TB HDDs in a ZFS pool. It’s currently made of 2 vdevs (3x8TB each) in RaidZ1. Is there any supported way to shrink the pool back down to a single 3x8TB vdev, or do I simply need to create a new pool?
-
This worked for me as well.
-
Same issue here.
-
Overdue update -- this is working perfectly fine for me on 6.12.10.
-
I’m on v6.12.10, not v7.
-
Here's an example of the call traces I am seeing in my logs. I get these off and on every few days, and they don't always cause a crash immediately: Aug 9 05:00:43 Tower kernel: ------------[ cut here ]------------ Aug 9 05:00:43 Tower kernel: Can't encode file handler for inotify: 255 Aug 9 05:00:43 Tower kernel: WARNING: CPU: 4 PID: 22231 at fs/notify/fdinfo.c:55 show_mark_fhandle+0x73/0xe2 Aug 9 05:00:43 Tower kernel: Modules linked in: xt_mark veth wireguard curve25519_x86_64 libcurve25519_generic libchacha20poly1305 chacha_x86_64 poly1305_x86_64 ip6_udp_tunnel udp_tunnel libchacha udp_diag xt_CHECKSUM ipt_REJECT nf_reject_ipv4 ip6table_mangle ip6table_nat xt_nat xt_tcpudp iptable_mangle vhost_net tun vhost vhost_iotlb tap ipvlan xt_conntrack xt_MASQUERADE nf_conntrack_netlink nfnetlink xfrm_user xfrm_algo iptable_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 xt_addrtype br_netfilter md_mod tcp_diag inet_diag nct6683 ip6table_filter ip6_tables iptable_filter ip_tables x_tables efivarfs bridge stp llc intel_rapl_msr intel_rapl_common i915 x86_pkg_temp_thermal intel_powerclamp zfs(PO) coretemp kvm_intel kvm iosf_mbi drm_buddy i2c_algo_bit ttm drm_display_helper zunicode(PO) drm_kms_helper zzstd(O) crct10dif_pclmul crc32_pclmul drm crc32c_intel ghash_clmulni_intel sha512_ssse3 zlua(O) sha256_ssse3 sha1_ssse3 aesni_intel sr_mod cdrom zavl(PO) mei_hdcp crypto_simd mei_pxp intel_gtt Aug 9 05:00:43 Tower kernel: cryptd icp(PO) rapl zcommon(PO) znvpair(PO) spl(O) mxm_wmi wmi_bmof intel_cstate intel_uncore nvme i2c_i801 agpgart ahci mei_me i2c_smbus input_leds mpt3sas igc i2c_core mei nvme_core led_class joydev libahci syscopyarea sysfillrect raid_class sysimgblt scsi_transport_sas fb_sys_fops thermal fan tpm_crb video tpm_tis tpm_tis_core wmi tpm backlight acpi_pad intel_pmc_core acpi_tad button unix Aug 9 05:00:43 Tower kernel: CPU: 4 PID: 22231 Comm: lsof Tainted: P O 6.1.79-Unraid #1 Aug 9 05:00:43 Tower kernel: Hardware name: Micro-Star International Co., Ltd. MS-7D30/MPG Z690 FORCE WIFI (MS-7D30), BIOS A.G0 01/19/2024 Aug 9 05:00:43 Tower kernel: RIP: 0010:show_mark_fhandle+0x73/0xe2 Aug 9 05:00:43 Tower kernel: Code: ff 00 00 00 89 c1 74 04 85 c0 79 22 80 3d 71 ec 10 01 00 75 5e 89 ce 48 c7 c7 4e 7c 0e 82 c6 05 5f ec 10 01 01 e8 f5 bb de ff <0f> 0b eb 45 89 44 24 0c 8b 44 24 04 48 89 ef 31 db 48 c7 c6 8c 7c Aug 9 05:00:43 Tower kernel: RSP: 0018:ffffc9004c727c28 EFLAGS: 00010286 Aug 9 05:00:43 Tower kernel: RAX: 0000000000000000 RBX: ffff888d786d9c70 RCX: 0000000000000027 Aug 9 05:00:43 Tower kernel: RDX: 0000000000000002 RSI: ffffffff820d8b42 RDI: 00000000ffffffff Aug 9 05:00:43 Tower kernel: RBP: ffff8881070acf78 R08: 0000000000000000 R09: ffffffff829533f0 Aug 9 05:00:43 Tower kernel: R10: 00003fffffffffff R11: ffff88987f7b1b42 R12: ffff8881070acf78 Aug 9 05:00:43 Tower kernel: R13: ffff8881070acf78 R14: ffffffff81281eba R15: ffff888108d7cc78 Aug 9 05:00:43 Tower kernel: FS: 00001496a286ae00(0000) GS:ffff88981f300000(0000) knlGS:0000000000000000 Aug 9 05:00:43 Tower kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Aug 9 05:00:43 Tower kernel: CR2: 00000000004dd788 CR3: 0000000995492000 CR4: 0000000000752ee0 Aug 9 05:00:43 Tower kernel: PKRU: 55555554 Aug 9 05:00:43 Tower kernel: Call Trace: Aug 9 05:00:43 Tower kernel: Aug 9 05:00:43 Tower kernel: ? __warn+0xab/0x122 Aug 9 05:00:43 Tower kernel: ? report_bug+0x109/0x17e Aug 9 05:00:43 Tower kernel: ? show_mark_fhandle+0x73/0xe2 Aug 9 05:00:43 Tower kernel: ? handle_bug+0x41/0x6f Aug 9 05:00:43 Tower kernel: ? exc_invalid_op+0x13/0x60 Aug 9 05:00:43 Tower kernel: ? asm_exc_invalid_op+0x16/0x20 Aug 9 05:00:43 Tower kernel: ? fanotify_fdinfo+0xfd/0xfd Aug 9 05:00:43 Tower kernel: ? show_mark_fhandle+0x73/0xe2 Aug 9 05:00:43 Tower kernel: ? show_mark_fhandle+0x73/0xe2 Aug 9 05:00:43 Tower kernel: ? fanotify_fdinfo+0xfd/0xfd Aug 9 05:00:43 Tower kernel: ? seq_vprintf+0x33/0x49 Aug 9 05:00:43 Tower kernel: ? seq_printf+0x53/0x6e Aug 9 05:00:43 Tower kernel: ? preempt_latency_start+0x2b/0x46 Aug 9 05:00:43 Tower kernel: inotify_fdinfo+0x83/0xaa Aug 9 05:00:43 Tower kernel: show_fdinfo.isra.0+0x63/0xab Aug 9 05:00:43 Tower kernel: seq_show+0x13f/0x15d Aug 9 05:00:43 Tower kernel: seq_read_iter+0x169/0x346 Aug 9 05:00:43 Tower kernel: ? slab_post_alloc_hook+0x4d/0x15e Aug 9 05:00:43 Tower kernel: seq_read+0x92/0xbc Aug 9 05:00:43 Tower kernel: vfs_read+0xa4/0x19f Aug 9 05:00:43 Tower kernel: ? __do_sys_newfstatat+0x35/0x5c Aug 9 05:00:43 Tower kernel: ksys_read+0x76/0xc2 Aug 9 05:00:43 Tower kernel: do_syscall_64+0x68/0x81 Aug 9 05:00:43 Tower kernel: entry_SYSCALL_64_after_hwframe+0x64/0xce Aug 9 05:00:43 Tower kernel: RIP: 0033:0x1496a2af6afd Aug 9 05:00:43 Tower kernel: Code: 31 c0 e9 e6 fe ff ff 50 48 8d 3d 36 a1 0a 00 e8 49 15 02 00 66 0f 1f 84 00 00 00 00 00 80 3d e1 ca 0e 00 00 74 17 31 c0 0f 05 <48> 3d 00 f0 ff ff 77 5b c3 66 2e 0f 1f 84 00 00 00 00 00 48 83 ec Aug 9 05:00:43 Tower kernel: RSP: 002b:00007fff152c5f18 EFLAGS: 00000246 ORIG_RAX: 0000000000000000 Aug 9 05:00:43 Tower kernel: RAX: ffffffffffffffda RBX: 00000000004362c0 RCX: 00001496a2af6afd Aug 9 05:00:43 Tower kernel: RDX: 0000000000000400 RSI: 000000000046d410 RDI: 0000000000000005 Aug 9 05:00:43 Tower kernel: RBP: 00001496a2bd8600 R08: 0000000000000001 R09: 0000000000000000 Aug 9 05:00:43 Tower kernel: R10: 0000000000001000 R11: 0000000000000246 R12: 000000000000000a Aug 9 05:00:43 Tower kernel: R13: 0000000000000a68 R14: 00001496a2bd7d00 R15: 0000000000000a68 Aug 9 05:00:43 Tower kernel: Aug 9 05:00:43 Tower kernel: ---[ end trace 0000000000000000 ]--- Memtest passes after 24 hours (this was several months ago now), the board was RMA'd when I got it new, so now I'm wondering if it's the CPU after all. I have a 13500, non-K model, which is not even listed as at risk (for now), but I'm still wondering about the moderate instability.


