




Andiroo2
Members
-
Joined
-
Last visited
Everything posted by Andiroo2
-
Success! I deleted the ../appdata/pihole/ directory completely and pulled a new image. No go. Then I changed the IP from .99 to .98 and it worked. Something must be using .99 on my network already, even though my Unifi controller shows it as available. More research to come, but for now my backup Pihole is running. Thanks!
-
I just tried a fresh pull and still the same behaviour. I can't get the GUI to load, but the system reports positive status: pihole status [✓] FTL is listening on port 53 [✓] UDP (IPv4) [✓] TCP (IPv4) [✓] UDP (IPv6) [✓] TCP (IPv6) [✓] Pi-hole blocking is enabled ...and if I tail the log, I see activity: # pihole -t [i] Press Ctrl-C to exit 08:09:17: forwarded 197.1.168.192.in-addr.arpa to 1.0.0.2 08:09:17: forwarded 197.1.168.192.in-addr.arpa to 1.0.0.2 08:09:19: query[AAAA] diag.meethue.com from 192.168.1.103 08:09:19: forwarded diag.meethue.com to 1.1.1.2 08:09:19: forwarded diag.meethue.com to 1.0.0.2 08:09:19: forwarded diag.meethue.com to 1.0.0.2 08:09:22: query[PTR] 197.1.168.192.in-addr.arpa from 127.0.0.1 I just can't get the GUI to load to set it up fully. Screenshot of the docker page is attached. What am I missing?
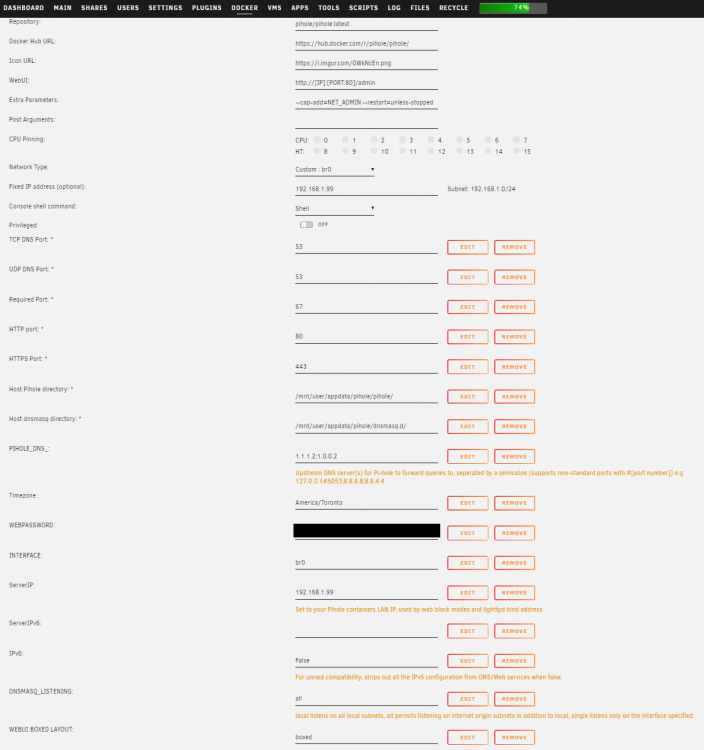
-
For those that are coming here to troubleshoot a new Pihole docker setup in 2022, the app marked "Official" in Community Apps doesn't yet work on Unraid out of the box. The template being pulled from docker has changed and the Unraid template hasn't been updated to use the new/correct variables yet. There are some changes listed in the thread here that may get it working for you, but for now, don't pull your hair out if it's not working out of the box. If I'm wrong, please delete this post or flag it...I'm not a spokesperson for this docker template...just someone that has pulled some hair out and now (I think?) understands where things stand.
-
I'm seeing this error in my logs over and over: Dec 28 08:23:15 Tower root: Starting Samba: /usr/sbin/smbd -D Dec 28 08:23:15 Tower root: /usr/sbin/nmbd -D Dec 28 08:23:15 Tower root: /usr/sbin/wsdd Dec 28 08:23:15 Tower root: /usr/sbin/winbindd -D Dec 28 08:23:15 Tower wsdd[5326]: set_multicast: Failed to set IPv4 multicast Dec 28 08:23:15 Tower wsdd[5326]: Failed to add multicast for WSDD: Address already in use Dec 28 08:23:15 Tower wsdd[5326]: set_multicast: Failed to set IPv4 multicast Dec 28 08:23:44 Tower emhttpd: Starting services... Dec 28 08:23:44 Tower emhttpd: shcmd (101438): /etc/rc.d/rc.samba restart Dec 28 08:23:46 Tower root: Starting Samba: /usr/sbin/smbd -D Dec 28 08:23:46 Tower root: /usr/sbin/nmbd -D Dec 28 08:23:46 Tower root: /usr/sbin/wsdd Dec 28 08:23:46 Tower root: /usr/sbin/winbindd -D Dec 28 08:23:46 Tower wsdd[8659]: set_multicast: Failed to set IPv4 multicast Dec 28 08:23:46 Tower wsdd[8659]: Failed to add multicast for WSDD: Address already in use Dec 28 08:23:46 Tower wsdd[8659]: set_multicast: Failed to set IPv4 multicast Dec 28 08:24:19 Tower emhttpd: Starting services... Dec 28 08:24:19 Tower emhttpd: shcmd (101481): /etc/rc.d/rc.samba restart Dec 28 08:24:22 Tower root: Starting Samba: /usr/sbin/smbd -D Dec 28 08:24:22 Tower root: /usr/sbin/nmbd -D Dec 28 08:24:22 Tower root: /usr/sbin/wsdd Dec 28 08:24:22 Tower root: /usr/sbin/winbindd -D Dec 28 08:24:22 Tower wsdd[12383]: set_multicast: Failed to set IPv4 multicast Dec 28 08:24:22 Tower wsdd[12383]: Failed to add multicast for WSDD: Address already in use Dec 28 08:24:22 Tower wsdd[12383]: set_multicast: Failed to set IPv4 multicast Dec 28 08:24:40 Tower emhttpd: Starting services... Dec 28 08:24:40 Tower emhttpd: shcmd (101510): /etc/rc.d/rc.samba restart Dec 28 08:24:43 Tower root: Starting Samba: /usr/sbin/smbd -D Dec 28 08:24:43 Tower root: /usr/sbin/nmbd -D Dec 28 08:24:43 Tower root: /usr/sbin/wsdd Dec 28 08:24:43 Tower root: /usr/sbin/winbindd -D Dec 28 08:24:43 Tower wsdd[14670]: set_multicast: Failed to set IPv4 multicast Dec 28 08:24:43 Tower wsdd[14670]: Failed to add multicast for WSDD: Address already in use Dec 28 08:24:43 Tower wsdd[14670]: set_multicast: Failed to set IPv4 multicast Thoughts on where to start looking?
-
+1 for the H O T C A C H E.
-
Do I MV the files to /mnt/cache/<share>/ or CP them? Is that the correct path I should be targeting? When I want them to go back to the array, do I run mover, or MV/CP them pack to /mnt/disk#/<share>/?
-
My movies folder is set to use cache (cache:yes) until cache hits 90%, then mover runs. I’d like to move most of my Christmas movies back to the cache while they are in demand and save my array from spinning up. Can I move files BACK to the cache without forcing the whole share to Cache:Prefer? My cache is a raid1 pool, so I’m not concerned about protection for the files.
-
One of us.
-
My container suddenly won't start on a server reboot. Logs show one error but apparently unrelated. ------------------------------------- _ () | | ___ _ __ | | / __| | | / \ | | \__ \ | | | () | |_| |___/ |_| \__/ Brought to you by linuxserver.io ------------------------------------- To support LSIO projects visit: https://www.linuxserver.io/donate/ ------------------------------------- GID/UID ------------------------------------- User uid: 99 User gid: 100 ------------------------------------- [cont-init.d] 10-adduser: exited 0. [cont-init.d] 40-chown-files: executing... [cont-init.d] 40-chown-files: exited 0. [cont-init.d] 45-plex-claim: executing... [cont-init.d] 45-plex-claim: exited 0. [cont-init.d] 50-gid-video: executing... [cont-init.d] 50-gid-video: exited 0. [cont-init.d] 60-plex-update: executing... No update required [cont-init.d] 60-plex-update: exited 0. [cont-init.d] 90-custom-folders: executing... [cont-init.d] 90-custom-folders: exited 0. [cont-init.d] 99-custom-scripts: executing... [custom-init] no custom files found exiting... [cont-init.d] 99-custom-scripts: exited 0. [cont-init.d] done. [services.d] starting services [services.d] done. Starting Plex Media Server. Critical: libusb_init failed Dolby, Dolby Digital, Dolby Digital Plus, Dolby TrueHD and the double D symbol are trademarks of Dolby Laboratories. If I manually start the docker it works fine.
-
I started removing plugins based on their update dates. I removed only one: CA Mover Tuning ...and I was able to restart. I then saw there is an update today for the Unassigned Devices plugin that I still had installed. This is in the release notes for that update: Unassigned.devices 2021.12.08 Fix: Deal gracefully with udev not returning any information on a partition. Fix: Issue with loss of GUI on 6.9. 2021.12.07 Add: Show a disk that drops out of the array and ends up as an unassigned device as unmountable and mark it as 'Array'. Fix: Rewrite check for used share name because the scheme used interferred with a device mount. I wonder if the "Loss of GUI on 6.9" is my issue. In any case, I updated to it and was able to reboot again. I'll mark this SOLVED for now.
-
Been an interesting few days. Timeline: Tried to remove some cache drives, borked it. Had to rebuild my cache from backups and resize the pool. Got the system working as usual again, backups restores, parity synced, etc. All set. Installed a new plugin (VM Backup) and ran it once. Rebooted the system, and no GUI came up. I can log into the terminal and SSH without issue Booted into safe mode, all seems fine. Removed the VMBackup .plg and folder from /boot/config/plugins Still can't boot into normal mode Diagnostics attached. I do have a brand new flash drive handy if drive corruption is suspected. Thoughts? Thanks for the help. tower-diagnostics-20211209-0803.zip
-
Any options to configure the Speedtest docker to use Appdata so we can edit the telemetry settings? I would love to log the Speedtest results from external users.
-
This is where a cache disk will be helpful. Large capacity SSD or ideally NVME used as a write cache will speed up your writes as fast as your network and sending disks can handle.
-
Restarting the server fixed it for me.
-
Running into this issue today myself. Did you ever figure this out? My error is coming from Telegraf when connecting to the Docker service to get the CPU and memory stats.
-
Examples where this is useful: It's Halloween or Christmas and lots of people are watching Halloween/Christmas movies on Plex. Those movies get moved to the warm cache when the first person watches them and then they are available faster with fewer disk spin-ups in the warm cache when lots of people start watching them. This assumes that the user has lots of space in the warn cache pool, and they specify that mkv files can go to the warm cache in settings Working on a project using some digital assets that have been on the array for a few months, Lots of accesses coming to those files over a period of weeks, so they sit in the warm cache while the project runs and then they get returned to the array when the project finishes
-
Would be great to make more use of a cache pool for frequently accessed files that may normally live on the array. Files that are accessed from the array could be copied to cache after the first use, and then handled by the mover process to be flushed from the cache after a period of time with no activity (no need to copy back to the array, as it's already there). User can specify the shares that utilize warm cache by selecting a new option in the share options (Yes, Prefer, Warm, etc.). User should be able to specify file types and sizes that would be in scope for warm caching. Warm cache should be used in conjunction with advanced mover features like those available in the Mover Tuning plugin to allow the user to specify how long files stay in cache after a cache hit. User could specify a dedicated cache for warm caching use only via the share settings (one pool for regular cache, one pool for warm caching). Files that are modified while in the warm cache would be deleted from the array and the updated version copied back to the array via the mover. Files that are unchanged in the warm cache will just be flushed by the mover.
-
I prefer a backup on any file change, even if that’s 10x per day. If my flash drive dies, I want to know that the latest config is available to restore. Not one from a week ago before I made some change (and you KNOW that would happen right before the drive dies…).
-
Can you confirm that you’re using an nvidia GPU? The nvenc error implies that it can’t find one. Can you transcode with CPU properly? Make sure that’s working for all types of files before addressing your GPU trouble.
-
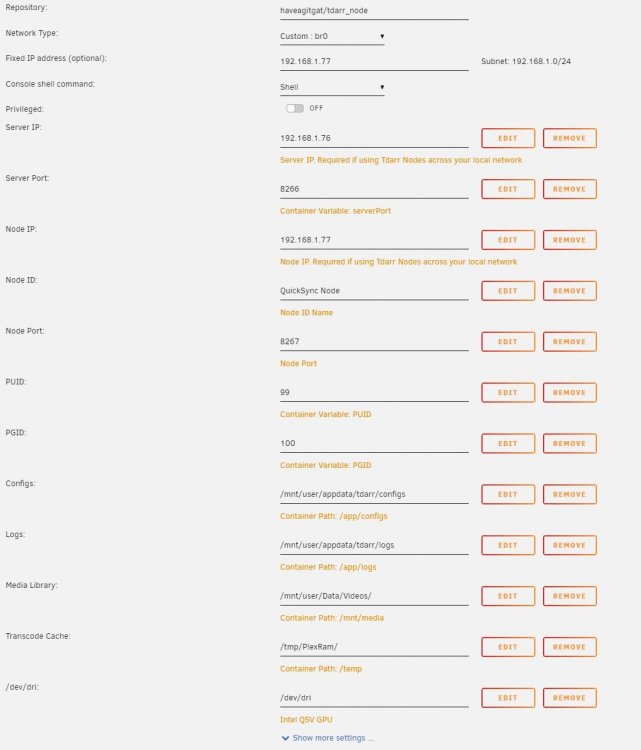
It sounds like your Tdarr docker is writing to the Unraid cache/RAM instead of your SSD. I would check that the “Transcode Cache” path in the Tdarr server and node docker settings are the same, and that they are pointing at a share that is set to use your cache (share set to ‘Yes’ or ‘Prefer’). The ‘/temp’ setting for transcode cache in the Tdarr GUI will point to this path in the docker settings, so double check that it’s set to the SSD (e.g. : /mnt/cache/<share_name> ) and not /tmp on the server.
-
I was getting this error as well before I cracked my GPU issue. If you are using QuickSync GPU, check my earlier post for the 3 steps I took to get it working.
-
I'm using "Tdarr_Plugin_drdd_standardise_all_in_one" which converts audio to aac. I lied. I am using these two: - Tdarr_Plugin_JB69_JBHEVCQSV_MinimalFile (I edited this plugin to ignore all files that were already in HEVC completely) - Tdarr_Plugin_JB69_JBHEVCQSZ_PostFix
-
Update: I have resolved my issues. Here is what I did to get Quick Sync GPU transcode working in Tdarr on a 10th gen CPU: Set the Tdarr_node docker to Privileged Change the node options (on Tdarr main page > Nodes > (select your node) > Options) to use "vaapi" hardware encoding, and NOT "qsv" I then ran the following command within the Tdarr_node docker container's console: apt install vainfo intel-media-va-driver-non-free After doing these steps, I was able to get GPU transcode working on my i7 10700k iGPU.
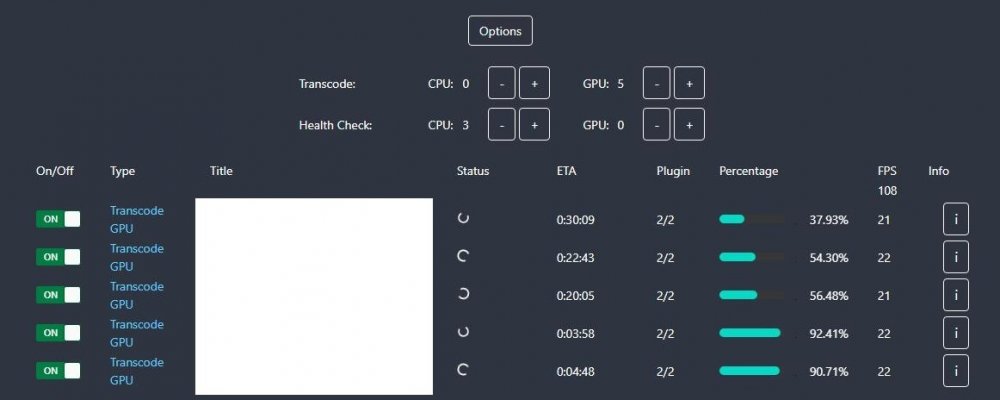
-
I've looked thought the thread and can't find what I am looking for -- help with Quick Sync GPU setup for the new v2 tdarr dockers. I have my iGPU working in Plex via /dev/dri, and passed it to the tdarr node the same way. I have tried a few different QSV plugins but none seem to work. I can convert with a CPU plugin without issue, so I know the containers and directories are set up properly. Can someone recommend a QSV plugin that works for them? I've tried the ones listed in the default options and one I found online but no dice. Some logs from the node showing the processing starts, but nothing really happens: [32m[2021-10-04T09:06:03.055] [INFO] Tdarr_Node - [39mStarting Tdarr_Node Preparing environment [32m[2021-10-04T09:06:03.075] [INFO] Tdarr_Node - [39mUpdating plugins [32m[2021-10-04T09:06:03.079] [INFO] Tdarr_Node - [39mTdarr_Node listening at http://localhost:8267 [32m[2021-10-04T09:06:03.173] [INFO] Tdarr_Node - [39m---------------Binary tests start---------------- [32m[2021-10-04T09:06:03.181] [INFO] Tdarr_Node - [39mhandbrakePath:HandBrakeCLI [32m[2021-10-04T09:06:03.190] [INFO] Tdarr_Node - [39mffmpegPath:ffmpeg [32m[2021-10-04T09:06:03.201] [INFO] Tdarr_Node - [39mmkvpropedit:mkvpropedit [32m[2021-10-04T09:06:03.201] [INFO] Tdarr_Node - [39mBinary test 1: handbrakePath working [32m[2021-10-04T09:06:03.201] [INFO] Tdarr_Node - [39mBinary test 2: ffmpegPath working [32m[2021-10-04T09:06:03.201] [INFO] Tdarr_Node - [39mBinary test 3: mkvpropeditPath working [32m[2021-10-04T09:06:03.201] [INFO] Tdarr_Node - [39m---------------Binary tests end------------------- [32m[2021-10-04T09:06:03.356] [INFO] Tdarr_Node - [39mCloning plugins [32m[2021-10-04T09:06:03.679] [INFO] Tdarr_Node - [39mFinished downloading plugins! [32m[2021-10-04T09:06:05.095] [INFO] Tdarr_Node - [39mNode registered [32m[2021-10-04T09:06:05.790] [INFO] Tdarr_Node - [39m[2.435s]Plugin update finished [32m[2021-10-04T09:07:04.156] [INFO] Tdarr_Node - [39mProcessing file: /mnt/media/Unsorted/movie1.mkv [32m[2021-10-04T09:07:36.176] [INFO] Tdarr_Node - [39mProcessing file: /mnt/media/Unsorted/movie1.mkv
-




