




Larz
Members
-
Joined
-
Last visited
-
That's good to know that spaces are allowed in OpenZFS.
-
Hi All, I find that the Convert to Dataset action is dismissing the Copying Directory progress dialogue before the copy is complete. I have launched the Convert to Dataset operation from the action button menu. I see that the directory is renamed, the Dataset is created, and see the Copying Directory dialogue showing the copy progress. I have left the computer alone for half an hour while the directory containing a 300+GB img file is copied into the Dataset. Upon returning, I see that the copying dialogue has been dismissed and the system is displaying the ZFS Master page. The copy is still in process. Htop shows the rsync process is running, I see disk I/Os, and the drive lights blinking. If I select a Move/Rename action on a different directory while this is running, the system displays the Move/Rename dialogue with the field for specifying the new name/location, after less than a second, the copy progress indicator is displayed in place of the editable field. Images below. After selecting Action, Move/Rename: A fraction of a second later: The name field is replaced with the progress indicator for the rsync copy that is running in the background. I have seen the Copying Directory dismissed before the copy has completed several times. There is no cancel button on this dialogue, and upon return to the computer, I see it is still on the ZFS Master page. Is there anything I may be doing that is dismissing the dialogue? For now, I am checking the Dataset contents watching for the in-progress files with the arbitrary six character extension before attempting further operations. Please let me know what you think. Thanks, Larz
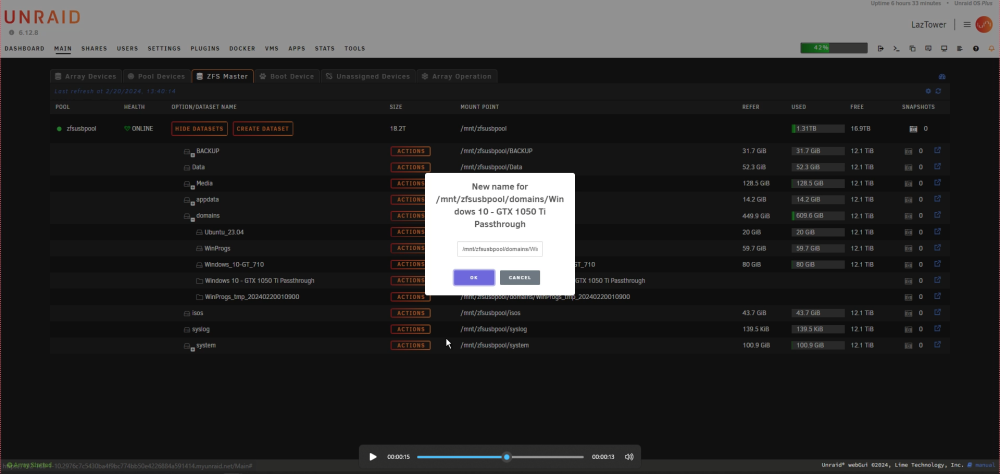
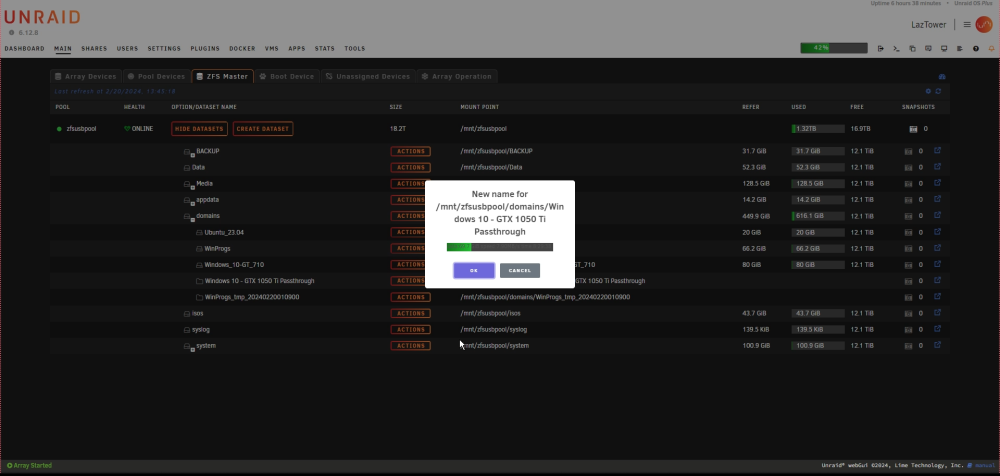
-
Hello Iker, thank you for your reply. The rsync was long done at the time of the convert action. I reviewed ulimit and the system reported unlimited. Running ulimit -n reports 40960 file descriptors. I tested setting the limit to 42960, but received the same result. I had re-tested after a server reboot as well. In the end, the issue was a blank space character in the directory name. I've revised the post above with the details. I believe the blank space is invalid in a Dataset name per the ZFS documentation. ZFS Component Naming Requirements Adding an edit check to the convert dialogue displaying a message indicating that the directory name contains invalid characters and allowing a revised Dataset name to be specified and re-checked would be helpful. Nonetheless, I'm back in business and exercising more discipline in my directory naming. I'll test following the failed copy process with a manual copy from the renamed directory to the new Dataset. I'm interested to know how ZFS behaves with an invalidly named Dataset. Thanks for your help and for this fine product, Larz
-
Hello All, When converting a Directory to a Dataset, I was receiving the message, "Too many open files in system" in the Convert Result dialogue. This occurred when the directory to be converted contained invalid characters for a ZFS Dataset name. In my case, it was a blank space in the directory named "Ubuntu 23.04". The convert action renames the directory appending TMP_dateTime to the directory name, creates the dataset with the blank space in its name, briefly displays the Copying dialogue, then terminates displaying the Convert Result dialogue shown below. I believe creating the dataset name with a blank space character is incorrect per the : ZFS Component Naming Requirements. Could an edit check be added to the Convert to Dataset action? Perhaps with a dialogue noting the issue and prompting the user to specify a valid Dataset name that can be re-checked upon submission? This is a great tool. Thanks for making it available! Best Regards, Larz
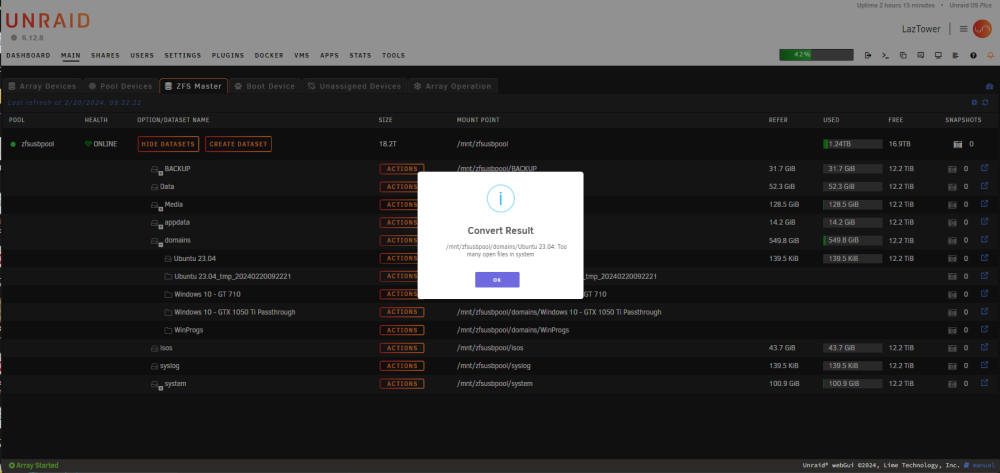
-
How can I tell which processes are using the drive?
-
I find that Chromium/Chrome/Edge will render the dashboard in three columns at 100% zoom if the browser window is sized with a width of 1902 pixels or more. That works with the Windows Scaling set greater that 100% as well. Font size as specified on Settings, Display Settings has no effect on the column configuration. Developing for all of the varieties of display configurations, operating systems and browsers is no small feat. I commend the Unraid developers for their excellent work making the dashboard display as flexible and comfortable as it is. It is truly more functional that I need. Cheers!
-
Open the Docker tab and switch to advanced view. The system will list CPU and RAM utilisation for each Docker container.
-
Hi, were you able to resolve this issue? Try accessing your external backup disk from the Duplicati Docker console. Can you read and write to the "Path: /backups" directory from within the console? Regarding the consumption of the vdisk space; Is Duplicati creating backup or working files in the vdisk? How is your "external disk" defined? I've been running Duplicati for several months and primarily backup to iDrive Cloud, but I have also had success backing up to local shares. Let us know how you get on with this. Cheers, Larz
-
Thanks dlandon, This is nice!
-
Hi dnLL, I'm doing the same thing you were doing WAY BACK in 2019, backing up the whole VM, .img, .xml and nvram files in a Duplicati backup. Have you been happy with this approach? I'm getting efficient results with the .img files. I have two big VMs, 50GB+ each. Once the initial full backup is done, the changed block backups go pretty quickly. I've not done a restore yet, but that's next on my list. I want to add in the xml & nvram files to complete the package. Did you adjust the owner/permissions on the relevant files in /etc/libvirt/qemu? (What permissions have you used?) I hope it's all been positive. Please let me know. Thanks, Larz
-
I have installed the CloudBerry Backup Docker container and it is working well. Thanks very much for setting this up for us. I have configured the system to store to IDrive Cloud using CloudBerry-specific configuration details provided by IDrive. Good job IDrive. I first configured CloudBerry to use the S3 compatible API, but I would not get a list of my buckets in the Storage Add Account Bucket drop-down list. I tried several times with the S3 keys and endpoint specified by IDrive. Switching to the Open Stack API worked fine. Have others been successful using the S3 compatible storage API? Have others worked with IDrive Cloud? Thanks in advance for any feedback. P.S. IDrive Cloud offers 2TB of cloud storage for $69.50US discounted to $6.95 for the first year. Ther offer a 5TB account for under $100.



