




jbartlett
Community Developer
-
Joined
-
Last visited
Everything posted by jbartlett
-
Attention:If you are getting errors scanning hardware or submitting benchmarks, please update the DiskSpeed docker app, it should reflect version 2.10.10.3. I updated the URL for the public site to strangejourney.net, removing the www prefix. I moved the domain to a new server and currently the www prefix is returning another one of my domains and as of this posting, it was quicker to update the Docker app than to figure out why the domains are serving incorrectly even though the config looks correct. Database ErrorsMoving from a Windows server to a Unix server and switching from MySQL to MariaDB also introduced forced lower case table names. I believe I caught them all but please let me know if you get any table not found errors.
-
@rerror @jrfbal @StylishQuoter Please update the DiskSpeed docker app, it should report version 2.10.10.2. I added logic to catch devices that report that it's mounted on the controller on port 0 (invalid) and skip them.
-
Nice, I am able to duplicate with that LCUS module
-
I've ordered one of these, should be here a couple days. Hopefully I'll be able to duplicate.
-
This is really odd. Historically, if the app server counts from one to zero, it just skips the loop entirely. I'll take a look....
-
I just ordered one to try to duplicate the issue. Need one for my main NAS box at any rate....
-
Do you mean with benchmarking? I've had some success with kicking off a Benchmark from the main page on version 2.10.10 and then manually selecting a much larger test file size.
-
From what I can tell so far, it may be related to a USB device that's detected as SDB with the description of "File-Stor Gadget". Do you have a phone or Quest or other USB device connected? If so, try disconnecting and restart the Docker app. i can add an exclusion for this like i have for an empty card reader but want to verify the cause first.
-
If you click on the "Rescan Controllers", your 10TB & 14TB drives will now have images. Also, if you want your other drives to have a uniform capacity overlay, you can edit just one of them and then set the checkbox to apply the same changes to all like-model drives. That typically happens from different people uploading the first image for the drive and they had differing opinions of the overlay text.
-
Have you tried changing the PCIe slots the cards are plugged into? I've ran into scenarios on my DiskSpeed dev box where a card wouldn't have the expected speeds if it was plugged in x slot vs y slot, even though the slots had enough PCI lanes for it and the bios hadn't changed the number of lanes utilized (that may also be an issue, check your MB docs). Awesome to see my DiskSpeed app being used to troubleshoot issues.
-
First, thank you for reporting this issue. I can't fix issues I don't know about. I'm not able to duplicate with my two setups but I added code to try to ensure the IsSSD flag exists. Please remove the version off the repo to download 2.10.10.1. Issues fixed: Catch rare spin up error Check for missing "IsSSD" flag during benchmarking Abort benchmarks on drives that work enough to be detected but fails to read
-
Version 2.10.10: USB & SSD Pool Benchmarking Catch rare error fetching platter info Allow benchmarking of SSD pools Allow benchmarking of USB devices Allow editing of USB devices Correct scaling of left side axis of SSD benchmarks Version 3 is taking awhile due to life stuff so I added into the version 2 branch the ability to benchmark SSD pools and USB devices. On fresh installs or reset, it'll try to identify images for any USB drives. You can now edit the image on existing USB devices. When benchmarking pools, select the first drive in the pool to see the benchmark button. If you click the "Benchmark" button on the home page, you can set the checkbox for the first drive in a pool but not for any other drives in the pool. Benchmark of three Samsung 990 EVO nvme's on the motherboard in a ZFS ZRAID1 pool with the default 4 GB test file size With ZFS pools, try a larger test file to see if it steadies out the benchmark.
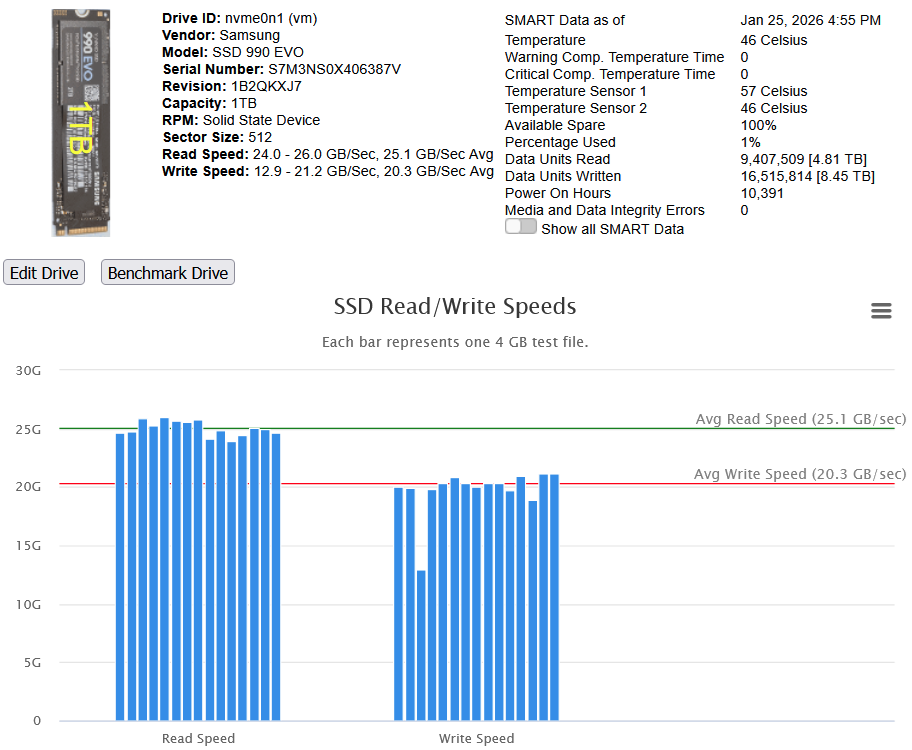
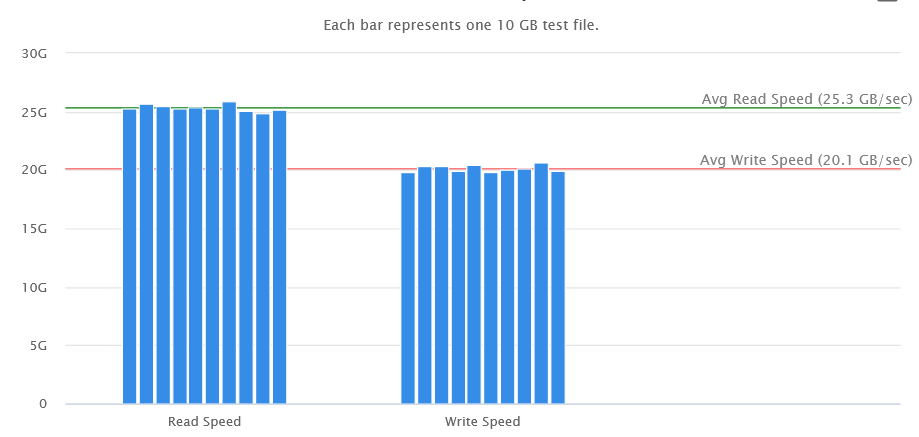
-
Not yet on solid state devices. I haven't found a means to satisfactory bypass or mitigate ZFS's built in caching.
-
Click on the DiskSpeed icon on the UNRAID Plugin page and select "Console" At the command prompt, run the same command, it should come back instantaneously but for some reason, it doesn't for you. You may have to wait a bit to get the true error that's happening at the OS - DiskSpeed tosses out a timeout error here because it's waiting for the OS to respond - and since it shouldn't ever toss an error here, I didn't trap errors so I could see it happen and know how to code a specific catch for it. /bin/df -B 1KB
-
Out of curiosity, does your nvme drive also have a dash in the name?
-
I'd like it too, it's on my To Do list.
-
There's something caching the read/writes and isn't honoring the cache bypass. The program uses FIO to do the benchmarking, try using a larger file size in the benchmark scan.
-
Sorry, that is currently not available. It's on my To Do list but I haven't been able to spend much time programming of late, unfortunately.
-
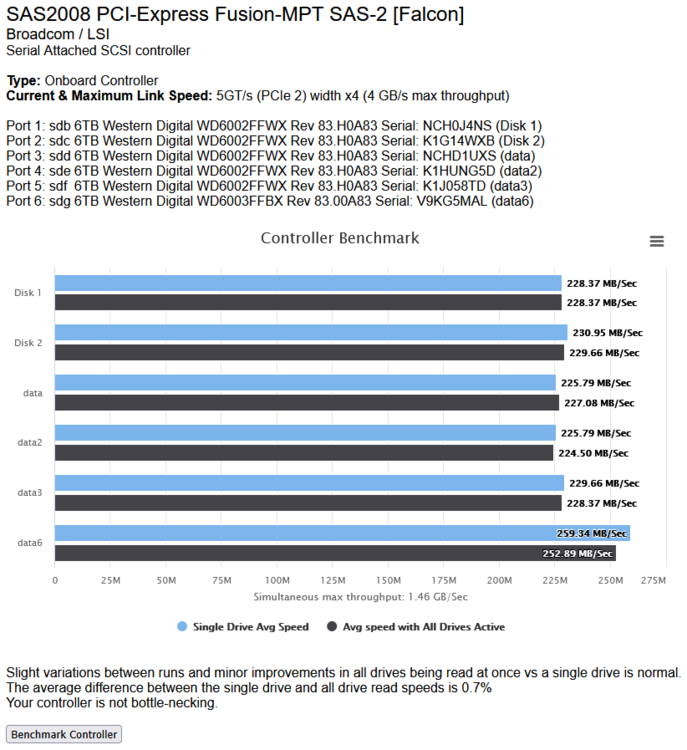
You can do this by clicking on the icon next to your controller. Then click on the "Benchmark Controller" button. It will then read all drives attached to the controller for 15 seconds each in sequence, then all of the drives on the controller at the same time for 15 seconds, then display a graph showing both the isolated speed and the speed the drives got when reading all at the same time.

-
The current version doesn't allow benchmarking USB attached drives. I do plan on adding support in the futureTM
-
Benchmarking ZFS solid state drives is not yet supported, but if you're using spinners, it doesn't matter what the file system is, or if there is one at all.
-
Please update, it should reflect version 2.10.9.9, and you should get your Kioxia love back
-
I had the intention to unlock USB bench marking - it was originally coded to not as it has the strong possibility of skewing the speeds to the low end - but it seems I had partially unlocked it in the drive selection but not in the benchmarking logic. I'll see about taking a look at it.
-
It shouldn't, it does log things as it runs but the impact wouldn't be high enough to be noticeable, no more than the margin of error from running any kind of benchmark on any device over & over. I am working on a method of benchmarking using random data without hitting against /dev/random as I've seen the generation speed to be slow.
-
It only needs /mnt on the host mapped to /mnt/UNRAID on the docker. Ensure you have it set to Read/Write as well. You can also try clicking on the DiskSpeed docker icon and selecting "Console", then entering "df | grep cache$" and see what the free percentage is that Docker sees.







