




walle
Members
-
Joined
-
Last visited
-
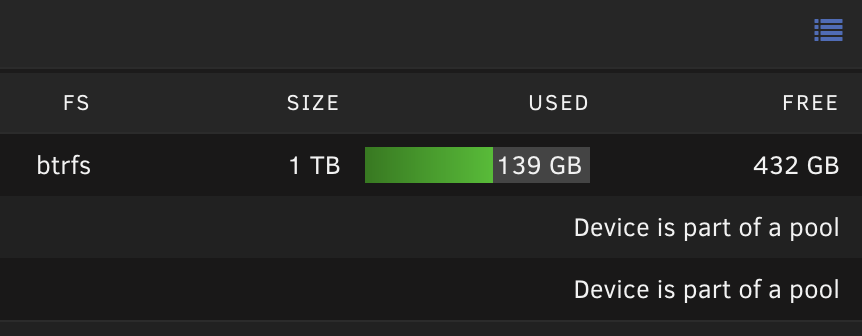
I recently added a 1 tb SSD to my existing 2x 500 gb SSD cache pool. As I understand it, I should have 1 tb useful space for file storage(source: the btrfs disk usage calculator). However GUI indicates I only have round 570 GB (432+139) useful storage. Have I missed something? What's the reason I don't get 1 tb with raid 1?
-
I looked into if it was possible to run autossh as a demon on my Unifi console, it seems to not be possible (without do a bunch of hacky stuff). Put a Raspberry PI on the network is most likely workaround I will probably do if it can't be solved with Unraid.
-
Humm, good idea. My router is a Unifi console and maybe possible to run autossh with a demon on that. Otherwise my plan B is to run a Raspberry PI with Rasbian + autossh and use the configuration I mentioned in my first post. In case of autossh fails on my Unraid server, I can still login via the pi to the network.
-
My use case is my Unraid server is behind a CG-NAT, aka. the public IP number is shared, so it isn't possible to SSH to the server directly over the internet. The workaround I have for this is to let the server connect via a tunnel to a VPS. When I need to access my server remotely, I do a reverse tunnel connection via the VPS to my server. In other words, If the tunnel goes down, I can no longer access the server. In order to keep the tunnel alive, I currently use autossh and trigger it in the GO-file. But this doesn't seem to be enough, sense I have seen autossh process die time to time. So I need some kind of solution that can monitor autossh and restart it when needed. I don't think, as far as I know, either cron or user scripts plugin can do that. In regards to Docker, it's normally my go-to solution to solve most of my problems and could maybe partly solves the issue with health checks. But I don't think it's a good fit in this case for two reasons. First of all, I don't want to SSH into the container and I think there is no good way to "break out" from it in order to access the host. Second, Docker will not run unless the array have started. I need to have remote access to server even if the array goes down or the array can't start for some reason.
-
Thank you for your rely Apandey. Currently I have this bottom of the go-file: # Autossh relay /usr/bin/autossh -M 0 -o ServerAliveInterval=60 -o ServerAliveCountMax=3 -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null -NTfi /etc/ssh/id_ed25519 -R 1234:localhost:22 [email protected] The thing is autossh instance sometimes dies without any apparent reason. I have seen behavior for a few of my other servers where I have initiated autossh with a cronjob. This is quite worrisome for me sense this may be the only way I can remotely connect to the server. The other servers I have runs autossh with systemd have worked flawlessly. This is why I want to run autossh as a service/demon or whatever else that is similar to systemd and that works even if the array haven't started. So I don't think either user scripts or Docker based solutions will not work for me.
-
On my Debian based servers, I use systemd to make sure my reverse SSH tunnel starts at boot and make sure it's running. Now I want to do similar to my Unraid server. What is the equivalent to this file [Unit] Description=My AutoSSH tunnel service After=network.target [Service] Environment="AUTOSSH_GATETIME=0" ExecStart=/usr/bin/autossh -M 0 -o ServerAliveInterval=60 -o ServerAliveCountMax=3 -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null -NTi /etc/ssh/id_ed25519 -R 1234:localhost:22 [email protected] [Install] WantedBy=multi-user.target ?
-
It would be nice if Autossh cloud be added: https://slackware.pkgs.org/current/slackers/autossh-1.4g-x86_64-2cf.txz.html
-
I'm really happy to see a Nerdpack replacement! Good work! The only package I missing now is mtr or mtr-tiny. For everyone that doesn't know, mtr is similar traceroute but with additional useful information that's really useful tool for troubleshooting network issues. You can read more about it here: https://www.linode.com/docs/guides/troubleshooting-basic-connection-issues/#mtr
-
I would like to have the option to install autossh with Nredpack if possible.
-
Same issue here.
-
I have a Docker image that needs the hostname paramter. For example: docker run --name backup-container --hostname backup-instance How do I set this parameter in a container template?
-
My disk also got stuck at "unRAID's signature on the MBR is valid", but all I needed to do was to stop pre-clear and resume the operation again. See my post above, if you got stuck on "Starting", try to restart the server then try again.
-
I found the problem with the plugin (sort of)! For some reason a old tmux pre-clear session got stuck: $ ps uax | grep tmux root 1695 0.0 0.0 28968 7364 ? Ss Aug31 1:07 /usr/bin/tmux new-session -d -x 140 -y 200 -s preclear_disk_WD-WCC7K6SFD5TJ root 10801 0.0 0.0 9812 2136 pts/1 S+ 02:28 0:00 grep tmux After I killed the process (`kill 1695`), it seams that it works as expected (it has passed "Started..." and currently running pre-read) An other way to solve it would be to restart the server. Thank you for your help!
-
Ahh, didn't read that. Thank you! But how can I install previews version of the plugin it self (not the scripts)? Older updates worked for my other drives I pre-cleared. Yeah, I know. But I don't really like screen, I prefer tmux wish is much better in my opinion. Now I haven't debug this much, but currently I getting this error: $ ./preclear_disk.sh -t /dev/sdj ./preclear_disk.sh: line 1307: strings: command not found sfdisk: invalid option -- 'R' Try 'sfdisk --help' for more information. Sorry: Device /dev/sdj is busy.: 1 I the script I downloaded was this (version 1.15): https://forums.unraid.net/applications/core/interface/file/attachment.php?id=11467 And I got this link from bottom on first post: Line 1307 is this (plus above comment): #---------------------------------------------------------------------------------- # First, do some basic tests to ensure the disk is not part of the arrray # and not mounted, and not in use in any way. #---------------------------------------------------------------------------------- devices=`/root/mdcmd status | strings | grep rdevName | sed 's/\([^=]*\)=\([^=]\)/\/dev\/\2/'` For some reason there is no strings command in my installation of unraid, so I guess I need to install additonal packages somewhere else?
-
Does anyone know what the issue can be? Shall I test and install an older version of the plugin and see if that helps? If so, how do I do that? Here is my diagnostics data. It seams that doesn't on my system. Did I miss something? $ ls -l /boot/config/plugins/preclear.disk/ total 1960 -rwxrwxrwx 1 root root 263640 Sep 4 07:48 libevent-2.1.8-x86_64-1.txz -rwxrwxrwx 1 root root 1289920 Sep 4 07:48 ncurses-6.1_20180324-x86_64-1.txz -rwxrwxrwx 1 root root 63 Sep 4 07:48 preclear.disk-2018.08.27.md5 -rwxrwxrwx 1 root root 163992 Sep 4 07:48 preclear.disk-2018.08.27.txz -rwxrwxrwx 1 root root 244556 Sep 4 07:48 tmux-2.6-x86_64-1.txz -rwxrwxrwx 1 root root 15624 Sep 4 07:48 utempter-1.1.6-x86_64-2.txz

