




zenmak
Members
-
Joined
-
Last visited
Everything posted by zenmak
-
Thank you!! I did the first one because I'm sure there would have been some weirdness with parity with the HBA going offline the way it did. It screwed up one of my mysql db's, but I have backups, so I'm not worried. Thank you again for the help! Jack
-
Hi All! So I had something really odd happen with my server earlier today. I was in unraid and then all of the sudden a bunch of disks started to have issues, including the parity drives. I shut down the server and then went to investigate. I found that one of my HBAs' heatsink had fallen off! It looks like the plastic pushpins that hold on the heatsink deteriorated and then broke off.. I found the heatsink dangling! I'm like that's not good! So, I had some long screws with some paper washers and then fixed it up.. I cleaned up the heatsink and then reapplied the thermal grease and put everything back in.. it worked! The issue now is that all the drives seem to be fine except for the two parity drives. They both say "Parity Device is Disabled" with red X's next to them. I did verify that the drives are "online", like unraid is seeing them, but the parity is disabled.. I'm guessing that there were just too many disconnections due to the HBA failure. How can I put the parity back on? Do I need to do a new config with everything in it's place and then put parity back in again? Thanks Jack
-
Hi All, I have a friend that is upgrading his array from 2tb to 8tb drives. He currently has 1 2tb parity drive and a few 2tb data drives in the array. He had a question that he asked me and I wasn't sure, so I said I would post it and ask for him. The question.. I know he install 2 8tb parity drives, do a new config and have dual parity rebuild. If he takes out his current 2tb parity drive and replaces it with the 2 8tb ones and let's say a data drive fails during rebuild, can he then shut the system down, take out the 2 8tb new parity drives, put in the old parity drive, power on the system, do a new config, say parity is valid, then recover the failed data drive? I know it's a lot, but it is just a question we both had, like a just in case/what if type of thing. The safest way, correct me if I'm wrong, is to have him shut down, put in a 2nd parity disk, so he'd have 1 2tb, and 1 8tb, do a new config, assign the 2nd new 8tb drive and let it rebuild, then repeat for the other 2tb drive, correct? Thanks for any advice!
-
Hi All, I'm moving my unraid server to different hardware. I'm virtualizing unraid and passing through HBAs, GPU, etc. All of it is working fine. If I pass through the NIC's that unraid was using, everything continues to work as normal, but unfortunately, passing through 2 of the 4 server NICs is causing instability. The way around that is to just use port groups and assign vswitches with their own NICs. I can do this just fine and unraid sees the NICs and networking is fine on the first one, and second NIC, but the only thing that isn't working is the docker network when trying to do a br1 to an IP on the network. It is not vmware related, I had this issue ages ago when I swapped bare metal hardware and I can't remember how I fixed it. On current hardware everything is working as it should. I can go into my docker containers and choose br1 and then give an IP address and it works. On the new setup, no matter what settings I do, I cannot get br1 to "talk" to the gateway, even though all the settings are the same. At the end of the day, there are still two NICs being used by unraid and the only thing that's really changed is the MAC addresses.. I've been using unraid for ages.. I'm wondering if there isn't a setting "stuck" somewhere.. I've even go as far as deleting the network.cfg file and trying to start over, but I'm convinced that there is a setting, or routing that is somewhere I can't see that may need to be reset. I am attaching screenshots of the current hardware. I am willing to destroy all networking everywhere if I have to to reset things, just need to know where to do it. Any help is appreciated! Jack
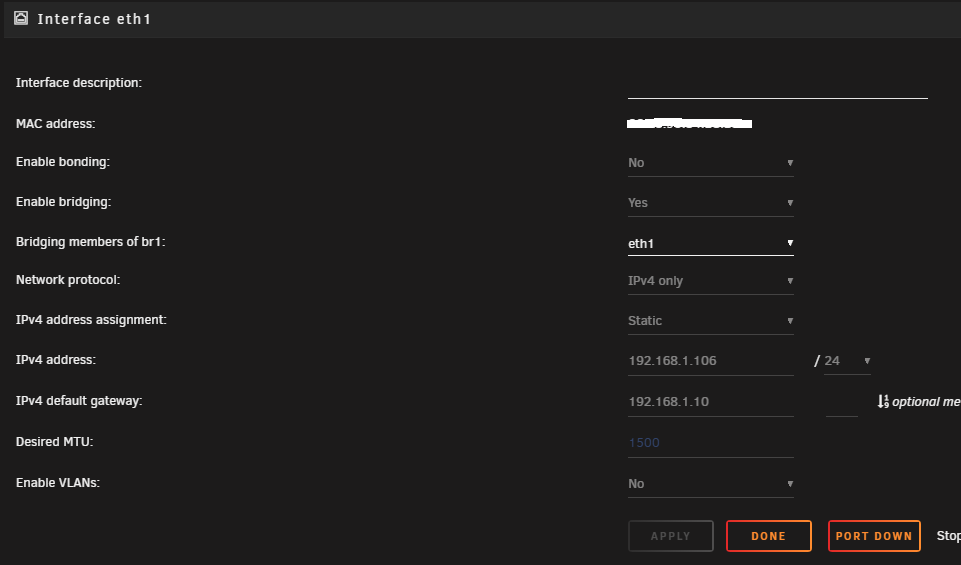
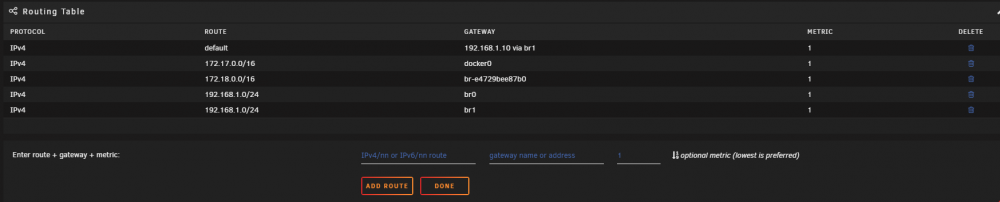

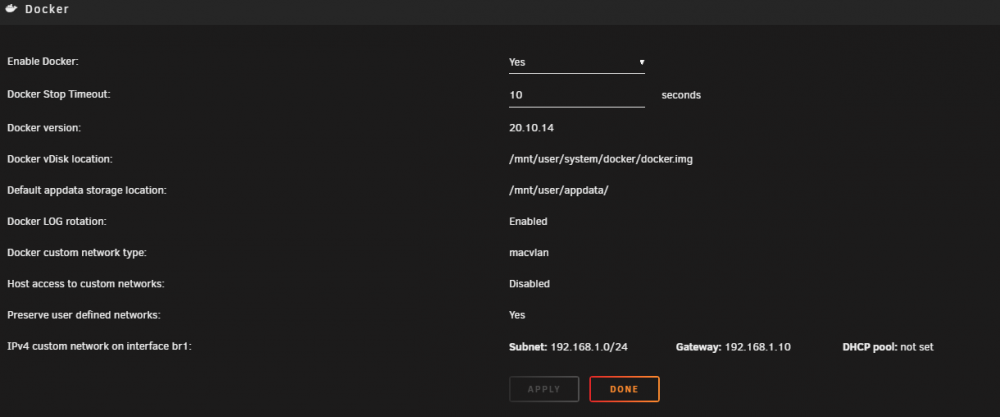
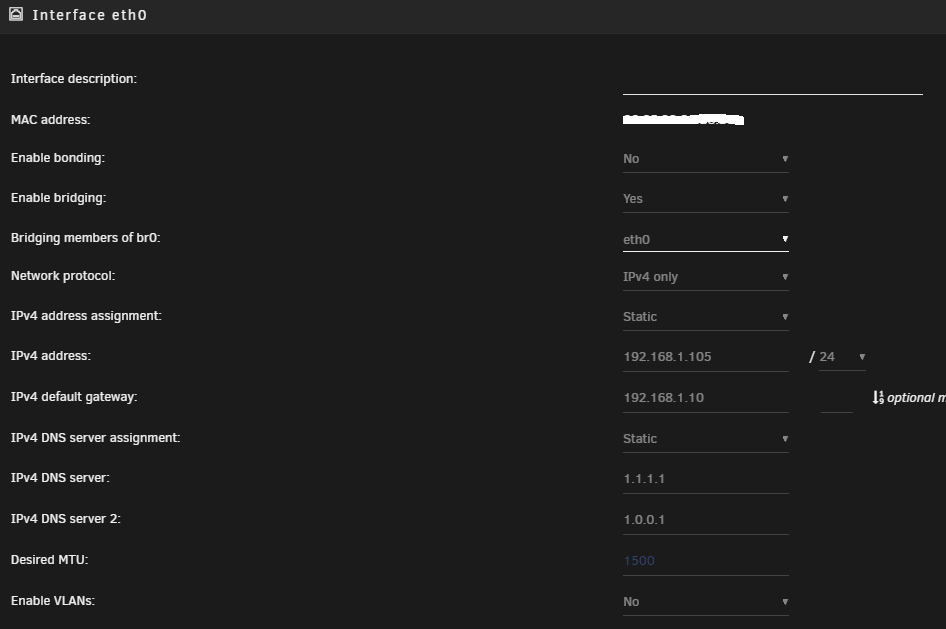
-
Hi All, I have a Supermicro X9DR3-LN4F+ in a Supermicro server case. It has currently 4 sticks of HMT42GR7AFR4C-RD RAM.. They are 16GB each Dual Rank RDIMM’s. When I bought my server I didn’t touch the included 64GB of RAM. I bought an additional 64GB of RAM for it today with the same exact memory type and size. When following the directions in the manual for a dual CPU Setup, CPU1 + CPU2 P1-DIMMA1/P1-DIMMB1, P2-DIMME1/P2-DIMMF1, P1-DIMMC1/P1-DIMMD1, P2-DIMMG1/P2-DIMMH1 and boot the system it stops at B7. I noticed that my original configuration was B1 D1 F1 H1. When swapping out my memory for the new memory in THAT configuration, it will fully post with no issues, so I know the new RAM is fine. If I try and use the motherboard manual guide for dual CPU for 4 sticks, it should be A1 B1 E1 F1. With that configuration the system gives me a black screen and doesn’t post. Is there another configuration I should try to use to get 8 sticks working? I’m worried that there might be a socket failure. Any advice will be appreciated. EDIT - Solved: Reached out to Supermicro support and a really nice tech responded with some suggestions. It turns out I had to reseat the CPU's to get this to work.
-
Hi All, I recently purchased a new nvme for my server to replace the SATA SSD I had in it. I changed my shares that were set to Prefer to Yes and then ran the mover to get the files off the SSD. Most files transferred and those that were left I wasn't all that concerned with. I stopped the array and replaced the cache drive with the new nvme, then started the array again. I formatted the new cache drive and then set the shares back to Prefer and ran the mover. For some reason there was no files being moved yet a lot of activity on the array. I looked at the processes in tools and could see that files were being scanned.. I thought maybe there had to be a file count or something before mover would actually move anything, and there is A LOT of files in the appdata share to move, so I gave it a couple hours. I checked again and there were no files that were transferred back to the cache drive. I was like fine, I'll just use MC and do it manually.. I go in MC and find that my /mnt/user folder is missing and instead there is a /mnt/user0 folder. I then check my shares and all my shares are gone. I'm not sure what happend. I have backups for my flash drive that are fairely recent that I can restore if needed. Also I can put the old SSD back as the cache drive if needed as well.. It still in the server. I'm in IT by trade, but I'm a little lost on how to proceed with this one.. Attached are my diagnostics. Thanks for any help. Jack Edit: Found another post similar to mine: I rebooted and the shares came back, but now have a /mnt/user and /mnt/user0 folder. I found another post that describes the functions of both.. I'm ok with that, but kind of curious to know why I never had both of these folders before when I had a cache drive, or if that /mnt/user0 folder was added at a later build. Either way, I invoked the mover again and it looks like files are now being moved. Will edit again with final results later on. towerone-diagnostics-20220217-1509.zip
-
so i got the QR code to show up but in the app there is no where to scan it, android app btw edit: i ended up manually adding the server and then it worked.. it also turned out that since i use pihole, i needed to add towerone.local in my dns settings for that to resolve correctly, after i did that it worked fine. thanks for the help!
-
i got it to work.. the link is opening to port 2379, when in fact it should be 2378, but in addition, the link is using SSL and i get a SSL protocol failure: towerone.local sent an invalid response. ERR_SSL_PROTOCOL_ERROR it works if I change it back to: http://192.168.1.105:2378
-
Hi. I'm currently on unraid version 6.10.0-rc2 and just loaded the 3.0v of the plugin.. the issue is that when I click the link, the page doesn't load. I have tried to uninstall/reinstall the plugin as well as enable/disable. This site can’t be reached towerone.local refused to connect. Try: Checking the connection Checking the proxy and the firewall ERR_CONNECTION_REFUSED
-
Hi All, I recently got a nice supermicro server from a friend of mine with 8 bays.. I bought 8 SAS 2TB drives, stuck them in there and ran 3 cycles of preclear on the drives (they were refurbs), they all passed with no issues. I also have a separate DAS case with a bunch of drives from the original server in it that I connected externally and they are all working fine. I've had the "new" system up for a couple weeks now and no issues really until the other day. I got a notification on my phone that there was an issue with the array with two of the SAS drives.. The 8 drives are connected with their own seperate HBA LSI adaptor (latest FW). There was nothing on the drives btw, but I had downloaded the SAS plugin to allow the drives to go to sleep. I had spun down the drives manually, and they were sitting there for a few days asleep with no issues. All of the sudden the other night they woke up with these errors on them.. I ran SMART against the drive and one appeared to have failed while the other said it was OK. I took them out of the array and rebuilt the array without them since these drives were empty, I didn't lose anything. I ran another preclear on them and the preclear came out fine with no issues... I was doing some reading on here and seen that maybe it was the because the drives were spun down I had this issue? I purposely haven't spun down anything since.. Normally, I wouldn't spin anything down, but since I wasn't using them for anything, I had. Here are the error messages in question: Aug 22 04:31:28 TowerOne kernel: blk_update_request: I/O error, dev sds, sector 1953531096 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 Aug 22 04:31:28 TowerOne kernel: sd 11:0:5:0: [sds] tag#2453 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 cmd_age=0s Aug 22 04:31:28 TowerOne kernel: sd 11:0:5:0: [sds] tag#2453 Sense Key : 0x2 [current] Aug 22 04:31:28 TowerOne kernel: sd 11:0:5:0: [sds] tag#2453 ASC=0x4 ASCQ=0x2 Aug 22 04:31:28 TowerOne kernel: sd 11:0:5:0: [sds] tag#2453 CDB: opcode=0x2a 2a 00 74 70 84 d8 00 00 08 00 Aug 22 04:31:28 TowerOne kernel: blk_update_request: I/O error, dev sds, sector 1953531096 op 0x1:(WRITE) flags 0x0 phys_seg 1 prio class 0 I'm attaching my diagnostics as well. On a side question about rebuilding the array/parity.. If when I removed these drives from the array with "new config", could I have selected "parity is valid" already if removing the drives? or does it have to rebuild the array? I wasn't sure, so I rebuilt the parity on the array to be safe. Thanks! Jacktowerone-diagnostics-20210823-1923.zip
-
Hi. Wanted to say that I'm also having the exact same error message. I could try to remove the container and image and reload if you'd like me to try that. Edit: Forgot to mention that this was an existing container. I updated it a couple nights ago and it seemed fine. Thanks for any help! *** Running /etc/my_init.d/00_regen_ssh_host_keys.sh... *** Running /etc/my_init.d/05_set_the_time.sh... *** Running /etc/my_init.d/06_set_php_time.sh... *** Running /etc/my_init.d/07_set_dri_permissions.sh... Granting permissions on /dev/dri/* devices... *** Running /etc/my_init.d/10_syslog-ng.init... Jul 2 19:15:09 d131fac144ab syslog-ng[20]: syslog-ng starting up; version='3.25.1' *** Running /etc/my_init.d/20_apt_update.sh... Performing updates... Get:1 http://security.ubuntu.com/ubuntu focal-security InRelease [114 kB] Hit:2 http://ppa.launchpad.net/iconnor/zoneminder-1.36/ubuntu focal InRelease Hit:3 http://archive.ubuntu.com/ubuntu focal InRelease Get:1 http://security.ubuntu.com/ubuntu focal-security InRelease [114 kB] Hit:2 http://ppa.launchpad.net/iconnor/zoneminder-1.36/ubuntu focal InRelease Hit:3 http://archive.ubuntu.com/ubuntu focal InRelease Get:4 http://archive.ubuntu.com/ubuntu focal-updates InRelease [114 kB] Hit:5 http://ppa.launchpad.net/ondrej/apache2/ubuntu focal InRelease Hit:6 http://ppa.launchpad.net/ondrej/php/ubuntu focal InRelease Get:7 http://archive.ubuntu.com/ubuntu focal-backports InRelease [101 kB] Fetched 328 kB in 11s (28.6 kB/s) Reading package lists... Fetched 328 kB in 11s (28.6 kB/s) Reading package lists... Reading package lists... Building dependency tree... Reading state information... Calculating upgrade... 0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded. Reading package lists... Building dependency tree... Reading state information... 0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded. *** Running /etc/my_init.d/30_gen_ssl_keys.sh... using existing keys in "/config/keys" *** Running /etc/my_init.d/40_firstrun.sh... Using existing conf folder File zm.conf already copied File zmeventnotification.ini already moved File secrets.ini already moved Event notification server already moved Pushover api already moved Using existing ssmtp folder Using existing mysql database folder Copy /config/control/ scripts to /usr/share/perl5/ZoneMinder/Control/ Copy /config/conf/ scripts to /etc/zm/conf.d/ Creating symbolink links usermod: no changes usermod: no changes usermod: no changes Using existing data directory for events Using existing data directory for images Using existing data directory for temp Using existing data directory for cache no crontab for root Starting services... * Starting Apache httpd web server apache2 * * Starting MariaDB database server mysqld ...fail! DBI connect('database=zm;host=localhost','zmuser',...) failed: Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (111) at /usr/share/perl5/ZoneMinder/Database.pm line 110. DBI connect('database=zm;host=localhost','zmuser',...) failed: Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (111) at /usr/share/perl5/ZoneMinder/Database.pm line 110. DBI connect('database=zm;host=localhost','zmuser',...) failed: Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (111) at /usr/share/perl5/ZoneMinder/Database.pm line 110. Unable to connect to DB. ZM Cannot continue. BEGIN failed--compilation aborted at /usr/share/perl5/ZoneMinder/Config.pm line 150. Compilation failed in require at /usr/bin/zmupdate.pl line 74. BEGIN failed--compilation aborted at /usr/bin/zmupdate.pl line 74. Jul 2 19:16:00 d131fac144ab zmupdate[1121]: ERR [Error reconnecting to db: errstr:Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (111) error val:] Jul 2 19:16:00 d131fac144ab zmupdate[1121]: ERR [Error reconnecting to db: errstr:Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (111) error val:] DBI connect('database=zm;host=localhost','zmuser',...) failed: Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (111) at /usr/share/perl5/ZoneMinder/Database.pm line 110. DBI connect('database=zm;host=localhost','zmuser',...) failed: Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (111) at /usr/share/perl5/ZoneMinder/Database.pm line 110. Jul 2 19:16:00 d131fac144ab zmupdate[1123]: ERR [Error reconnecting to db: errstr:Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (111) error val:] DBI connect('database=zm;host=localhost','zmuser',...) failed: Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (111) at /usr/share/perl5/ZoneMinder/Database.pm line 110. Unable to connect to DB. ZM Cannot continue. BEGIN failed--compilation aborted at /usr/share/perl5/ZoneMinder/Config.pm line 150. Compilation failed in require at /usr/bin/zmupdate.pl line 74. BEGIN failed--compilation aborted at /usr/bin/zmupdate.pl line 74. Jul 2 19:16:00 d131fac144ab zmupdate[1123]: ERR [Error reconnecting to db: errstr:Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (111) error val:] Starting ZoneMinder: DBI connect('database=zm;host=localhost','zmuser',...) failed: Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (111) at /usr/share/perl5/ZoneMinder/Database.pm line 110. DBI connect('database=zm;host=localhost','zmuser',...) failed: Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (111) at /usr/share/perl5/ZoneMinder/Database.pm line 110. DBI connect('database=zm;host=localhost','zmuser',...) failed: Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (111) at /usr/share/perl5/ZoneMinder/Database.pm line 110. Jul 2 19:16:00 d131fac144ab zmpkg[1133]: ERR [Error reconnecting to db: errstr:Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (111) error val:] Unable to connect to DB. ZM Cannot continue. BEGIN failed--compilation aborted at /usr/share/perl5/ZoneMinder/Config.pm line 150. Compilation failed in require at /usr/share/perl5/ZoneMinder.pm line 33. BEGIN failed--compilation aborted at /usr/share/perl5/ZoneMinder.pm line 33. Compilation failed in require at /usr/bin/zmpkg.pl line 34. BEGIN failed--compilation aborted at /usr/bin/zmpkg.pl line 34. Jul 2 19:16:00 d131fac144ab zmpkg[1133]: ERR [Error reconnecting to db: errstr:Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (111) error val:] ZoneMinder failed to start *** /etc/my_init.d/40_firstrun.sh failed with status 255 *** Killing all processes... Jul 2 19:16:00 d131fac144ab syslog-ng[20]: syslog-ng shutting down; version='3.25.1'
-
no idea.. it's working fine now under Brave since I cleared out my cache and cookies.. browser app is also working now as well under Brave.
-
Hi. I should have tried this before, but I tried with FireFox and it worked fine.. I ended up clearing out all the cookies from Brave and it started to work fine under the original letsencrypt conf file. I did try the other one as well and both seemed to work fine. Odd that a cookie issue would also stop the main bitwarden app from working as well... but stranger things have happened I guess.. Thanks for the help and the replies!
-
I'm having the same issue... I go to https://dnsname.domain.com to login and it now tries to resolve to: https://_/ or https://_/admin (if using admin). dcpdad is correct in that if you try to resolve outside your network, it resolves fine. as of last night, it was working fine. after the latest update, it stopped working.
-
Hi. After the 6.7 update, my plex docker kept saying "no route to host". I have it configured to use it's own IP address. Reverted back to previous version and it is fine.
-
Thanks for the reply, but the point is, that the preferences are not saving for me, and I'd like to fix that. Do you have any suggestions for that? Edit: I've tried multiple plugins and none of them are saving, it's not just the blocklist plugin. Edit 2 (Solved): I've solved my issue. The problem is that an extension in Chrome is causing the preferences not to be saved. I tried in firefox and it's working fine. Thanks.
-
Hi. I installed the docker container and was able to login with the default password and change it. I was enabled the blocklist plugin, put the URL in it, it grabbed the data and imported the list, then pressed apply and OK. If I stop and restart the container, the preferences don't save. I've looked at the core.conf file and did a chmod 666 to it as someone else said in the forums here, but that didn't change anything. Thoughts? Thanks for any input.





