




Bolagnaise
Members
-
Joined
-
Last visited
Everything posted by Bolagnaise
-
Just a quick update Holy shit they implemented it! @mgutt Literally almost 3 years to the day. Back to ram transcoding I go.
-
also seeing issues with flash update not working
-
For those switching to local storage and don't want to buy HDD's constantly, i have used the power of chatGPT and created a script to cleanup TV and Movies after a certain time period or if a min storage space threshold is met. This combined along with OVERSEER and Sonarr/Radarr integration means i can just request anything i want to watch and it will stay on my server until the threshold of time of space is met and it will deleted. If in the future you want to download it again, you use the unmonitorr feature in ARRs to allow overseer to re-request it. This combined along with FileFlows for HEVC conversion should allow me to store content for a significant amount of time. The trick is to add stuff you want to your watchlist so you dont forget about it in plex! https://github.com/bolagnaise/plex-cleaner-script
-
Just posting if anyone see’s an error like this after changing the line to -e TAG… mv: cannot overwrite directory '/bin/mergerfs' with non-directory To fix this issue, open a terminal and type: cd /bin rm -rf /mergerfs
-
Yeah it wont break your plex transcode folder. If it does, all you need to do is stop plex, delete the transcode folder and restart the container and it will recreate the folder with the correct user:nobody permissions. BTW the root permissions in rclone mean absolutely nothing, google drive has no ability to store permission metadata inside the folder structure. The --allow other flag means that even if the file is root inside your local mergerFS location prior to upload, then other users can access it. The reason your google drive still shows as root user is because you have not added a \ after each entry, your syntax is wrong. Heres what i would do to fix your issues: 1. Fix your mount script syntax. 2. Disable your mount script schedule 3. Make sure all your containers are using 99/100 umask 022 4.reboot your server 5. upon restart, run the new permissions tool for all shares including cache 6. Delete the transcode folder for plex if have not set it up as a user share/its on tmp 7. run your mount script 8.start your dockers
-
Nope not needed, You need to run the new permissions option inside tools after stopping docker to update their perms. You can also run this script to update permissions for other folders seperate to the new permissions tool or to force it. #!/bin/sh for dir in "/mnt/user/!!you folder path here!!" do echo $dir chmod -R ug+rw,ug+X,o-rwx $dir chown -R nobody:users $dir done The reason it works in 6.9 is because 6.10-rc3 introduced a bug fix where in the user share file system permissions were not being honoured, and containers with permissions assigned as 99:100 (nobody:user) actually had root access, 6.10 fixed this. Limetech should really make this new permissions tool default upon first boot of 6.10 as a lot of people have had this issue.
-
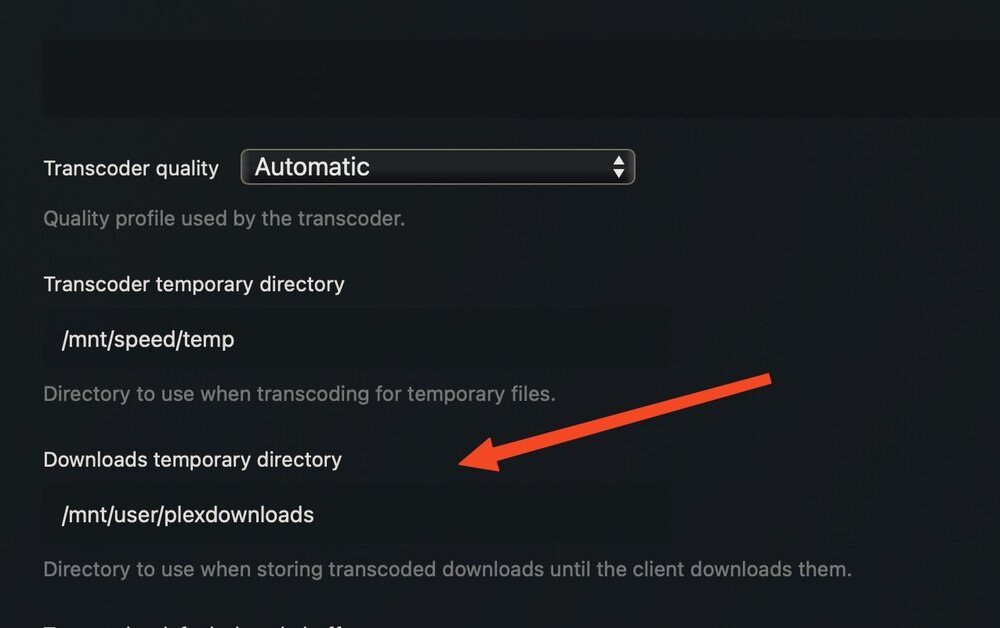
yep so not really viable, Anyway, i submitted a feature request to try and resolve this. See you in 3 years when it gets implemented. https://forums.plex.tv/t/feature-request-ability-to-map-new-downloads-feature-transcodes-to-seperate-path/803203
-
Not a sure if this is an rc1 issue or plugin issue due to backend gui changes, but in rc1 both apps throw multiple errors during installation and the GUI no longer loads. plugin: installing: DevPack.plg plugin: downloading: DevPack.plg ... 100% plugin: downloading: DevPack.plg ... done Executing hook script: pre_plugin_checks plugin: downloading: DevPack-2021.08.11-x86_64-1.txz ... 100% plugin: downloading: DevPack-2021.08.11-x86_64-1.md5 ... 100% plugin: downloading: DevPack-2021.08.11-x86_64-1.md5 ... done +============================================================================== | Installing new package /boot/config/plugins/DevPack/DevPack-2021.08.11-x86_64-1.txz +============================================================================== Verifying package DevPack-2021.08.11-x86_64-1.txz. Installing package DevPack-2021.08.11-x86_64-1.txz: PACKAGE DESCRIPTION: # Developmental Pack for unRAID Plugin # # unRAID plugin wrapper for dev packages, mostly for advanced # users to compile packages. Use at your own risk. # Not officially supported by LimeTech. # # https://github.com/dmacias72/unRAID-DevPack # Executing install script for DevPack-2021.08.11-x86_64-1.txz. Package DevPack-2021.08.11-x86_64-1.txz installed. Processing Packages... Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Installing curl-7.67.0 package... Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Installing glib2-2.62.4 package... Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Installing glibc-2.30 package... Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Installing gnutls-3.6.11.1 package... Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Installing libgcrypt-1.8.5 package... Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Installing libgpg-error-1.36 package... Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Installing libjpeg-turbo-2.0.3 package... Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Installing libxml2-2.9.10 package... Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Installing openssl-1.1.1d package... Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Installing pcre-8.43 package... Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Installing sqlite-3.30.1 package... Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Installing xz-5.2.4 package... Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Warning: preg_grep() expects parameter 2 to be array, string given in /usr/local/emhttp/plugins/DevPack/scripts/devmanager on line 72 Cleaning up packages... All packages processed... ----------------------------------------------------------- DevPack has been installed. This plugin requires Dynamix webGui to operate Copyright 2016-2019, dmacias72, eschultz Version: 2021.08.11 ----------------------------------------------------------- plugin: DevPack.plg installed Executing hook script: post_plugin_checks Updating support link
-
6.11 RC1 ISSUES- Dev pack and Nerd pack both will not load the full gui. Here's the logs.
-
Yep same issue. Here are the logs from installing it.
-
MY 5950x is similar, runs at about 70c with 4 x 480mm radiators under even a small load. drops down to 50c at idle. TBH i think it might have something to do with the current linux kernel, 6.11 will introduce kernel updates much faster and some improvements in temp reporting for asus and gigabyte motherboards so im waiting out for that to see if there’s any difference. For the time being, you can install tips and tweaks plugin and set the cpu governor to performance but disable AMD turbo boost, this will lock the cpu to 3.8Ghz and significantly lower temps with zero effect on containers, but will obviously significantly affect VMs and their responsiveness.
-
I’ve even thinking about this for a while, their is a SWAP file plugin for Unraid 6.9 and above. This may be a workaround to getting transcoding back onto ram. I will test and report back.
-
yep nice, just be aware in my script im using a permanent blacklist, which means that if those 2 remaining IPs ever become slow (which it seems they can do as some servers are becoming slow at random) then you will not be able to connect to google api. Change the variable to use a permanent blacklist by commenting it out if this happens.
-
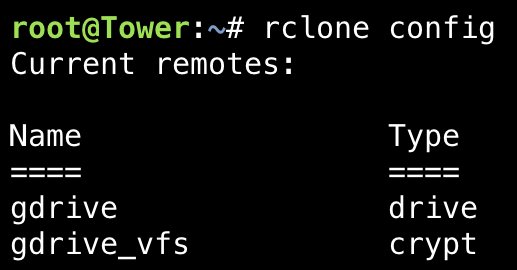
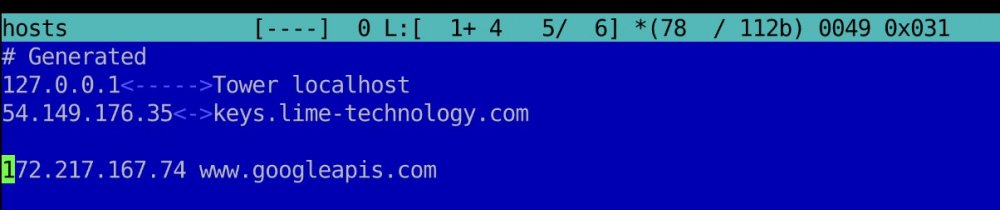
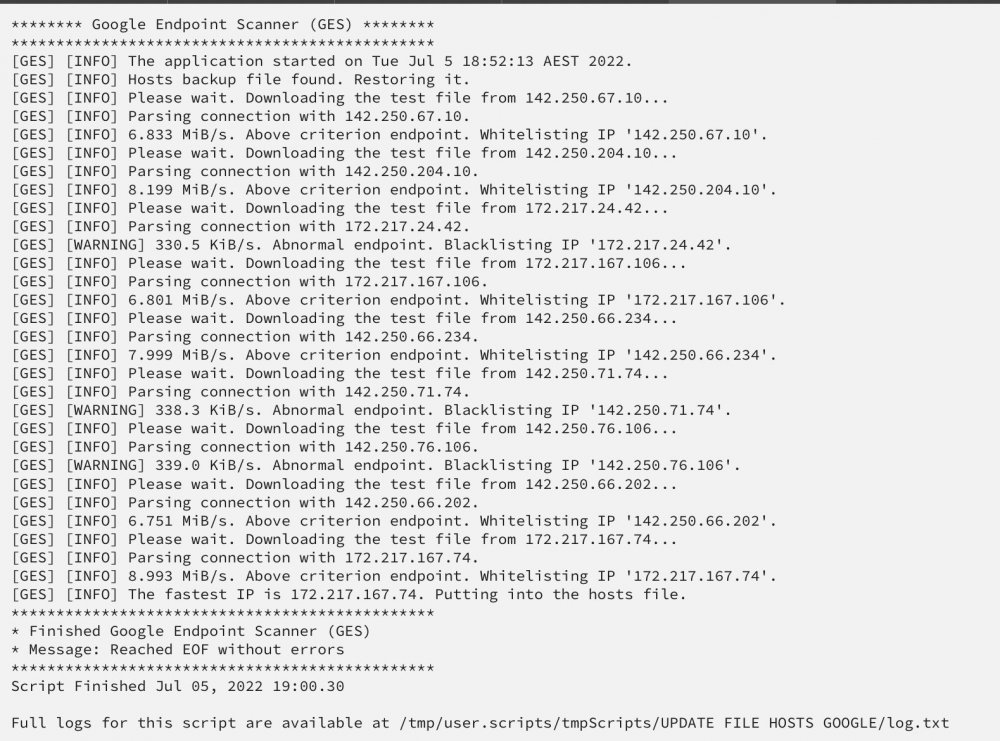
Another rclone forum member has posted an even better script, ill post how to get it working for Unraid users. I will try to lay this out as easily as possible for newer unraid users and im definitely no linux god so it took me a while to understand. Link to original script https://github.com/cgomesu/mediscripts-shared/blob/main/googleapis.sh 1. Open a terminal window and run fallocate -l 50M dummythicc This will create a 50MB dummy file called dummythicc. This dummyfile will be created in /root (use midnight commander to view it). 2. Upload the dummy script to google drive rclone copy dummythicc gdrive_vfs:/temp/ example: Please note, my crypt name is the same as @DZMM (gdrive_vfs) so if you are using another crypt remote name then you will need to change this part to reflect the remote name. To get you çrypt remote name type ‘’’rclone config’’in terminal: 3. Create a new script in the user plugins section. Find below my script which i think should work for 99% of unraid users using dzmm’s naming structure. if your crypt name is different to gdrive_vfs update it in the script. MAKE SURE TO REMOVE THE /BIN/BASH COMMAND THAT IS AUTO CREATED WHEN YOU MAKE A NEW SCRIPT #!/usr/bin/env sh ################################################################################### # Google Endpoint Scanner (GES) # - Use this script to blacklist GDrive endpoints that have slow connections # - This is done by adding one or more Google servers available at the time of # testing to this host's /etc/hosts file. # - Run this script as a cronjob or any other way of automation that you feel # comfortable with. ################################################################################### # Installation and usage: # - install 'dig' and 'git'; # - in a dir of your choice, clone the repo that contains this script: # 'git clone https://github.com/cgomesu/mediscripts-shared.git' # 'cd mediscripts-shared/' # - go over the non-default variables at the top of the script (e.g., REMOTE, # REMOTE_TEST_DIR, REMOTE_TEST_FILE, etc.) and edit them to your liking: # 'nano googleapis.sh' # - if you have not selected or created a dummy file to test the download # speed from your remote, then do so now. a file between 50MB-100MB should # be fine; # - manually run the script at least once to ensure it works. using the shebang: # './googleapis.sh' (or 'sudo ./googleapis.sh' if not root) # or by calling 'sh' (or bash or whatever POSIX shell) directly: # 'sh googleapis.sh' (or 'sudo sh googleapis.sh' if not root) ################################################################################### # Noteworthy requirements: # - rclone; # - dig: in apt-based distros, install it via 'apt install dnsutils'; # - a dummy file on the remote: you can point to an existing file or create an # empty one via 'fallocate -l 50M dummyfile' and # then copying it to your remote. ################################################################################### # Author: @cgomesu (this version is a rework of the original script by @Nebarik) # Repo: https://github.com/cgomesu/mediscripts-shared ################################################################################### # This script is POSIX shell compliant. Keep it that way. ################################################################################### # uncomment and edit to set a custom name for the remote. REMOTE="gdrive_vfs" DEFAULT_REMOTE="gcrypt" # uncomment and edit to set a custom path to a config file. Default uses # rclone's default ("$HOME/.config/rclone/rclone.conf"). CONFIG="/boot/config/plugins/rclone/.rclone.conf" # uncomment to set the full path to the REMOTE directory containing a test file. REMOTE_TEST_DIR="/temp/" DEFAULT_REMOTE_TEST_DIR="/temp/" # uncomment to set the name of a REMOTE file to test download speed. REMOTE_TEST_FILE="dummythicc" DEFAULT_REMOTE_TEST_FILE="dummyfile" # Warning: be careful where you point the LOCAL_TMP dir because this script will # delete it automatically before exiting! # uncomment to set the LOCAL temporary root directory. LOCAL_TMP_ROOT="/tmp/" DEFAULT_LOCAL_TMP_ROOT="/tmp/" # uncomment to set the LOCAL temporary application directory. TMP_DIR="ges/" DEFAULT_LOCAL_TMP_DIR="ges/" # uncomment to set a default criterion. this refers to the integer (in mebibyte/s, MiB/s) of the download # rate reported by rclone. lower or equal values are blacklisted, while higher values are whitelisted. # by default, script whitelists any connection that reaches any MiB/s speed above 0 (e.g., 1, 2, 3, ...). SPEED_CRITERION=5 DEFAULT_SPEED_CRITERION=0 # uncomment to append to the hosts file ONLY THE BEST whitelisted endpoint IP to the API address (single host entry). # by default, the script appends ALL whitelisted IPs to the host file. USE_ONLY_BEST_ENDPOINT="true" # uncomment to indicate the application to store blacklisted ips PERMANENTLY and use them to filter # future runs. by default, blacklisted ips are NOT permanently stored to allow the chance that a bad server # might become good in the future. USE_PERMANENT_BLACKLIST="true" PERMANENT_BLACKLIST_DIR="/root/" DEFAULT_PERMANENT_BLACKLIST_DIR="$HOME/" PERMANENT_BLACKLIST_FILE="blacklisted_google_ips" DEFAULT_PERMANENT_BLACKLIST_FILE="blacklisted_google_ips" # uncomment to set a custom API address. CUSTOM_API="www.googleapis.com" DEFAULT_API="www.googleapis.com" # full path to hosts file. HOSTS_FILE="/etc/hosts" # do NOT edit these variables. TEST_FILE="${REMOTE:-$DEFAULT_REMOTE}:${REMOTE_TEST_DIR:-$DEFAULT_REMOTE_TEST_DIR}${REMOTE_TEST_FILE:-$DEFAULT_REMOTE_TEST_FILE}" API="${CUSTOM_API:-$DEFAULT_API}" LOCAL_TMP="${LOCAL_TMP_ROOT:-$DEFAULT_LOCAL_TMP_ROOT}${TMP_DIR:-$DEFAULT_LOCAL_TMP_DIR}" PERMANENT_BLACKLIST="${PERMANENT_BLACKLIST_DIR:-$DEFAULT_PERMANENT_BLACKLIST_DIR}${PERMANENT_BLACKLIST_FILE:-$DEFAULT_PERMANENT_BLACKLIST_FILE}" # takes a status ($1) as arg. used to indicate whether to restore hosts file from backup or not. cleanup () { # restore hosts file from backup before exiting with error if [ "$1" -ne 0 ] && check_root && [ -f "$HOSTS_FILE_BACKUP" ]; then cp "$HOSTS_FILE_BACKUP" "$HOSTS_FILE" > /dev/null 2>&1 fi # append new blacklisted IPs to permanent list if using it and exiting wo error if [ "$1" -eq 0 ] && [ "$USE_PERMANENT_BLACKLIST" = 'true' ] && [ -f "$BLACKLIST" ]; then if [ -f "$PERMANENT_BLACKLIST" ]; then tee -a "$PERMANENT_BLACKLIST" < "$BLACKLIST" > /dev/null 2>&1; fi fi # remove local tmp dir and its files if the dir exists if [ -d "$LOCAL_TMP" ]; then rm -rf "$LOCAL_TMP" > /dev/null 2>&1 fi } # takes msg ($1) and status ($2) as args end () { cleanup "$2" echo '***********************************************' echo '* Finished Google Endpoint Scanner (GES)' echo "* Message: $1" echo '***********************************************' exit "$2" } start () { echo '***********************************************' echo '******** Google Endpoint Scanner (GES) ********' echo '***********************************************' msg "The application started on $(date)." 'INFO' } # takes message ($1) and level ($2) as args msg () { echo "[GES] [$2] $1" } # checks user is root check_root () { if [ "$(id -u)" -eq 0 ]; then return 0; else return 1; fi } # create temporary dir and files create_local_tmp () { LOCAL_TMP_SPEEDRESULTS_DIR="$LOCAL_TMP""speedresults/" LOCAL_TMP_TESTFILE_DIR="$LOCAL_TMP""testfile/" mkdir -p "$LOCAL_TMP_SPEEDRESULTS_DIR" "$LOCAL_TMP_TESTFILE_DIR" > /dev/null 2>&1 BLACKLIST="$LOCAL_TMP"'blacklist_api_ips' API_IPS="$LOCAL_TMP"'api_ips' touch "$BLACKLIST" "$API_IPS" } # hosts file backup hosts_backup () { if [ -f "$HOSTS_FILE" ]; then HOSTS_FILE_BACKUP="$HOSTS_FILE"'.backup' if [ -f "$HOSTS_FILE_BACKUP" ]; then msg "Hosts backup file found. Restoring it." 'INFO' if ! cp "$HOSTS_FILE_BACKUP" "$HOSTS_FILE"; then return 1; fi else msg "Hosts backup file not found. Backing it up." 'WARNING' if ! cp "$HOSTS_FILE" "$HOSTS_FILE_BACKUP"; then return 1; fi fi return 0; else msg "The hosts file at $HOSTS_FILE does not exist." 'ERROR' return 1; fi } # takes a command as arg ($1) check_command () { if command -v "$1" > /dev/null 2>&1; then return 0; else return 1; fi } # add/parse bad IPs to/from a permanent blacklist blacklisted_ips () { API_IPS_PROGRESS="$LOCAL_TMP"'api-ips-progress' mv "$API_IPS_FRESH" "$API_IPS_PROGRESS" if [ -f "$PERMANENT_BLACKLIST" ]; then msg "Found permanent blacklist. Parsing it." 'INFO' while IFS= read -r line; do if validate_ipv4 "$line"; then # grep with inverted match grep -v "$line" "$API_IPS_PROGRESS" > "$API_IPS" 2>/dev/null mv "$API_IPS" "$API_IPS_PROGRESS" fi done < "$PERMANENT_BLACKLIST" else msg "Did not find a permanent blacklist at $PERMANENT_BLACKLIST. Creating a new one." 'WARNING' mkdir -p "$PERMANENT_BLACKLIST_DIR" 2>/dev/null touch "$PERMANENT_BLACKLIST" 2>/dev/null fi mv "$API_IPS_PROGRESS" "$API_IPS" } # ip checker that tests Google endpoints for download speed. # takes an IP addr ($1) and its name ($2) as args. ip_checker () { IP="$1" NAME="$2" HOST="$IP $NAME" RCLONE_LOG="$LOCAL_TMP"'rclone.log' echo "$HOST" | tee -a "$HOSTS_FILE" > /dev/null 2>&1 msg "Please wait. Downloading the test file from $IP... " 'INFO' # rclone download command if check_command "rclone"; then if [ -n "$CONFIG" ]; then rclone copy --config "$CONFIG" --log-file "$RCLONE_LOG" -v "${TEST_FILE}" "$LOCAL_TMP_TESTFILE_DIR" else rclone copy --log-file "$RCLONE_LOG" -v "${TEST_FILE}" "$LOCAL_TMP_TESTFILE_DIR" fi else msg "Rclone is not installed or is not reachable in this user's \$PATH." 'ERROR' end 'Cannot continue. Fix the rclone issue and try again.' 1 fi # parse log file if [ -f "$RCLONE_LOG" ]; then if grep -qi "failed" "$RCLONE_LOG"; then msg "Unable to connect with $IP." 'WARNING' else msg "Parsing connection with $IP." 'INFO' # only whitelist MiB/s connections if grep -qi "MiB/s" "$RCLONE_LOG"; then SPEED=$(grep "MiB/s" "$RCLONE_LOG" | cut -d, -f3 | cut -c 2- | cut -c -5 | tail -1) # use speed criterion to decide whether to whilelist or not SPEED_INT="$(echo "$SPEED" | cut -f 1 -d '.')" if [ "$SPEED_INT" -gt "${SPEED_CRITERION:-$DEFAULT_SPEED_CRITERION}" ]; then # good endpoint msg "$SPEED MiB/s. Above criterion endpoint. Whitelisting IP '$IP'." 'INFO' echo "$IP" | tee -a "$LOCAL_TMP_SPEEDRESULTS_DIR$SPEED" > /dev/null else # below criterion endpoint msg "$SPEED MiB/s. Below criterion endpoint. Blacklisting IP '$IP'." 'INFO' echo "$IP" | tee -a "$BLACKLIST" > /dev/null fi elif grep -qi "KiB/s" "$RCLONE_LOG"; then SPEED=$(grep "KiB/s" "$RCLONE_LOG" | cut -d, -f3 | cut -c 2- | cut -c -5 | tail -1) msg "$SPEED KiB/s. Abnormal endpoint. Blacklisting IP '$IP'." 'WARNING' echo "$IP" | tee -a "$BLACKLIST" > /dev/null else # assuming it's either KiB/s or MiB/s, else parses as error and do nothing msg "Could not parse connection with IP '$IP'." 'WARNING' fi fi # local cleanup of tmp file and log rm "$LOCAL_TMP_TESTFILE_DIR${REMOTE_TEST_FILE:-$DEFAULT_REMOTE_TEST_FILE}" > /dev/null 2>&1 rm "$RCLONE_LOG" > /dev/null 2>&1 fi # restore hosts file from backup cp "$HOSTS_FILE_BACKUP" "$HOSTS_FILE" > /dev/null 2>&1 } # returns the fastest IP from speedresults fastest_host () { LOCAL_TMP_SPEEDRESULTS_COUNT="$LOCAL_TMP"'speedresults_count' ls "$LOCAL_TMP_SPEEDRESULTS_DIR" > "$LOCAL_TMP_SPEEDRESULTS_COUNT" MAX=$(sort -nr "$LOCAL_TMP_SPEEDRESULTS_COUNT" | head -1) # same speed file can contain multiple IPs, so get whatever is at the top MACS=$(head -1 "$LOCAL_TMP_SPEEDRESULTS_DIR$MAX" 2>/dev/null) echo "$MACS" } # takes an address as arg ($1) validate_ipv4 () { # lack of match in grep should return an exit code other than 0 if echo "$1" | grep -oE "[[:digit:]]{1,3}.[[:digit:]]{1,3}.[[:digit:]]{1,3}.[[:digit:]]{1,3}" > /dev/null 2>&1; then return 0 else return 1 fi } # parse results and append only the best whitelisted IP to hosts append_best_whitelisted_ip () { BEST_IP=$(fastest_host) if validate_ipv4 "$BEST_IP"; then msg "The fastest IP is $BEST_IP. Putting into the hosts file." 'INFO' echo "$BEST_IP $API" | tee -a "$HOSTS_FILE" > /dev/null 2>&1 else msg "The selected '$BEST_IP' address is not a valid IP number." 'ERROR' end "Unable to find the best IP address. Original hosts file will be restored." 1 fi } # parse results and append all whitelisted IPs to hosts append_all_whitelisted_ips () { for file in "$LOCAL_TMP_SPEEDRESULTS_DIR"*; do if [ -f "$file" ]; then # same speed file can contain multiple IPs while IFS= read -r line; do WHITELISTED_IP="$line" if validate_ipv4 "$WHITELISTED_IP"; then msg "The whitelisted IP '$WHITELISTED_IP' will be added to the hosts file." 'INFO' echo "$WHITELISTED_IP $API" | tee -a "$HOSTS_FILE" > /dev/null 2>&1 else msg "The whitelisted IP '$WHITELISTED_IP' address is not a valid IP number. Skipping it." 'WARNING' fi done < "$file" else msg "Did not find any whitelisted IP at '$LOCAL_TMP_SPEEDRESULTS_DIR'." 'ERROR' end "Unable to find whitelisted IP addresses. Original hosts file will be restored." 1 fi done } ############ # main logic start trap "end 'Received a signal to stop' 1" INT HUP TERM # need root permission to write hosts if ! check_root; then end "User is not root but this script needs root permission. Run as root or append 'sudo'." 1; fi # prepare local files create_local_tmp if ! hosts_backup; then end "Unable to backup the hosts file. Check its path and continue." 1; fi # prepare remote file # TODO: (cgomesu) add function to allocate a dummy file in the remote # start running test if check_command "dig"; then # redirect dig output to tmp file to be parsed later API_IPS_FRESH="$LOCAL_TMP"'api-ips-fresh' dig +answer "$API" +short 1> "$API_IPS_FRESH" 2>/dev/null else msg "The command 'dig' is not installed or not reachable in this user's \$PATH." 'ERROR' end "Install dig or make sure its executable is reachable, then try again." 1 fi if [ "$USE_PERMANENT_BLACKLIST" = 'true' ]; then # bad IPs are permanently blacklisted blacklisted_ips else # bad IPs are blacklisted on a per-run basis mv "$API_IPS_FRESH" "$API_IPS" fi while IFS= read -r line; do # checking each ip in API_IPS if validate_ipv4 "$line"; then ip_checker "$line" "$API"; fi done < "$API_IPS" # parse whitelisted IPs and edit hosts file accordingly if [ "$USE_ONLY_BEST_ENDPOINT" = 'true' ]; then append_best_whitelisted_ip else append_all_whitelisted_ips fi # end the script wo errors end "Reached EOF without errors" 0 4. Before running the script you need to ensure your /etc/hosts file is ‘clean’ so to say, as in it doesn't contain any references to www.googleapis.com An unclean hosts file to edit out the google host, use midnight commander or the config file editor plugin from CA mc #navigate to /etc/host #press F4 to edit #delete reference 'IP' www.googleapis.com #press F2 to save 5. Press ‘’’run in background’’ in user scripts and let the script do its work. your /etc/hosts file will now be updated to reflect the fastest server. 6. Set the script to run at an interval you feel comfortable with, probably daily will suffice as google may change their IPs and that would mean you would lose connection to the google drive servers. I’ve set mine to run at 6am daily, use crontab guru to set your own custom times or use the built in ones. https://crontab.guru 7. Once you have run script once we can enhance the testing to get more accurate results for the fastest google server. The reason you would want to do this is we are only initially testing downloading a 50MB file, and from user reports on rclone, this may not give the most accurate results, but it will allow the script to quickly identify the ‘bad’ google drive servers and add them to its -blacklist.api file for future reference so it doesnt test them. To enhance testing: -a)Using midnight commmander (mc) navigate to /root and delete ‘’dummythicc’’ by pressing F8 b) Using mc navigate to your ‘’/mnt/user/mount_rclone" user share and delete the /temp/ folder c) Run the below to create a 200MB file and re-upload it fallocate -l 200M dummythicc rclone copy dummythicc gdrive_vfs:/temp/ d) rerun the script from user plugins for more accurate results. Please let me know if i have missed anything or need help!


-
line 104 remove the /t and put a triple space in to represent tab, it should work correctly after that. hostsline="$macs $api"
-
Someone on the rclone forums has created a script to check your IPs to the google api and update your hosts file to the fastest one, unfortunately it doesnt yet work for Unraid due to differences in linux (and im not experienced enough to make it work) https://github.com/Nebarik/mediscripts-shared/blob/main/googleapis.sh
-
FYI anyone experiencing random slow speeds from google drive, there is starting to be many people report strange throttling behaviour. https://forum.rclone.org/t/rclone-mount-random-slow-speeds/31417/45
-
Thats interesting, if you run id root what comes up.
-
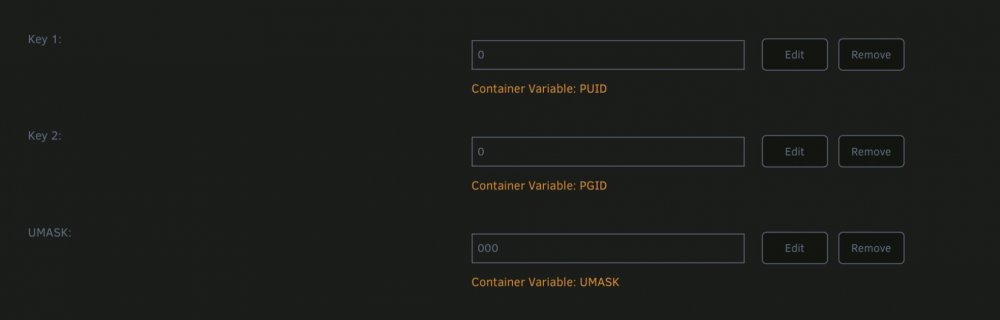
I’ve had been experiencing permission issues since upgrading to 6.10 as well and i think i finally fixed all the issues. RCLONE PERMISSION ISSUES: Fix 1: prior to mounting the rclone folder using user scripts, run ‘docker safe new permissions’ from settings for all your folders. Then mount the rclone folders using the script. I no longer recommend using the below information, using the docker safe new permissions should resolve most issues. Fix 2: if that doesnt fix your issues, in the mount script add the following BOLDED sections to the create rclone mount section of the script, or add them to the extra parameters section, this will mount rclone folders as user ROOT with a UMASK of 000. Alternatively you could mount it as USER:NOBODY with the uid:99 gid:100 DOCKER CONTAINER PERMISSIONS ISSUES FIX (SONARR/RADARR/PLEX) Fix 1: Change PUID and PGID to user ROOT 0:0 and add an environment variable for UMASK of 000 (NUCLEAR STRIKE OPTION) Fix 2: Maintain PUID and PGID to 99:100 as USER:NOBODY and using the user scripts plugin, update the permissions of the docker containers permissions using the following script, change the /mnt/ path directory to reflect your Docker path setup. Rerun for each containers path after changing it. #!/bin/bash for dir in "/mnt/cache/appdata/Sonarr/" do `echo $dir` `chmod -R ug+rw,ug+X,o-rwx $dir` chown -R nobody:users $dir done IMPORTANT PLEX UPDATE: After running docker safe new permissions, if you experience EAC3 or audio transcoder errors where the video never starts to play, it is because your CODECS folder and/or your mapped /transcode path does not have the correct permissions. To rectify this issue, stop your plex container, navigate to your plex appdata folder path and delete the CODECS folder. Then navigate to your mapped /transcode folder if you are using one and also delete that. Restart your plex container and plex will redownload your codecs and recreate your mapped transcode folder with the correct permissions.
-
Can i get a CORSAIR 1000D logo please . Here’s my custom build in one.


-
Yeah im not sure why this error has crept up, but i think it might have something to do with the patch notes from rc2 where it states This seems to have introduced a permissions issue for some people using rclone as there where no issues in rc1.
-
I tested 99/99, it did not work for me and the file permissions continued If you run in command line, you will see that Unraid uses 'USER NOBODY' on ID 98, and "USERGROUP NOBODY" on ID 99. At least for me it was I woke up early and updated my server to RC7 and now it works fine, before none of my dockers utilizing the gdrive folders would work and threw file permission errors in the log.
-
adding the below to you mount script should resolve the permissions issue if your updating to 6.10 RC7, i will test in approx 12 hours if this fixes the permissions issue with docker containers and plex. if you run the below from cli it should confirm what USER nobody is set too
-
@DZMM I @ you in this thread but for awareness of everyone else using RC, seems to be a permissions error with rc builds as LT updated how the permissions are managed from 6.9.2
-
Not to sure how to do this on Ubuntu, the easiest way would be to delete the container, and set it up as a new container with the correct config path.












