

Stubbs
-
Posts
207 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Stubbs
-
Actually I'm not even sure it's an issue with my firewall. I just turned everything off and I still got that error in the log. What gives?
-
I recently configured a firewall and added a bunch of blocklists. Unfortunately one of the side effects was blocking all my containers from fetching updates in the docker tab. Every container's version is listed as "Unavailable" and there's an error in my log: Jan 18 19:21:56 Unraidserver nginx: 2022/01/18 19:21:56 [error] 5536#5536: *1645538 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 192.168.5.5, server: , request: "POST /plugins/dynamix.docker.manager/include/DockerUpdate.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock", host: "192.168.5.5", referrer: "http://192.168.5.5/Docker/" This doesn't really wtell me what I should be whitelisting though. I'd rather not whitelist the MAC address of my Unraid server, which effectively removes the firewall protection.
-
[Support] [Depreciated] FlippinTurt PiHole DoT-DoH
Stubbs replied to FlippinTurt's topic in Docker Containers
Why isn't this container downloading adlists? Whenever I add them, they just remain greyed out. It worked when I first installed the container, but now they simple don't get downloaded or updated.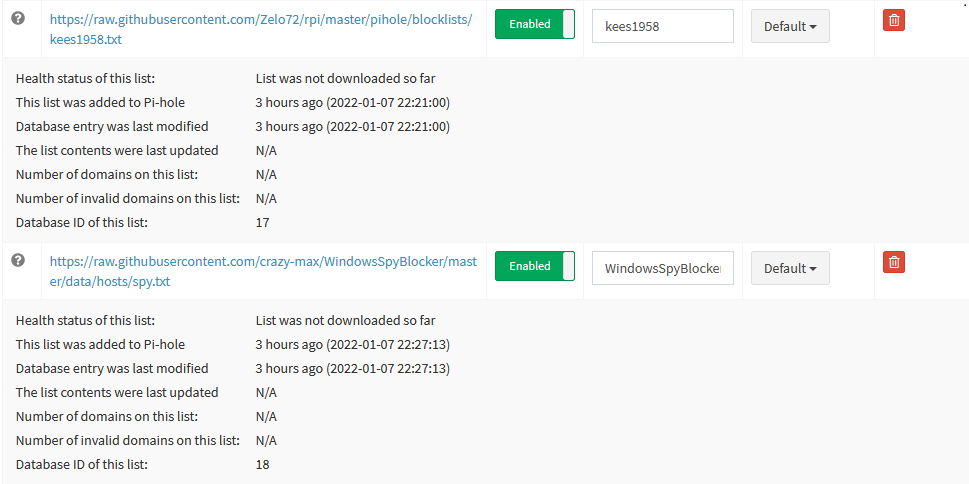
-
Oh right, I was misunderstanding something. I thought it had to be launched with specific commands. When I follow the DigitalOcean guide, I get an error when trying to flush privileges: ERROR 1146 (42S02): Table 'mysql.db' doesn't exist and when I try to run ALTER USER: ERROR 1290 (HY000): The MariaDB server is running with the --skip-grant-tables option so it cannot execute this statement
-
How? I know how to access the terminal from the Unraid WebUI, but not sure how to enter the docker specifically.
-
Is there a way to reset the credentials of the root user? The password I have set in the docker configuration isn't working, so I must have tried to change it at some point in the last 2 & a half years. The dockerhub page says once you install the container with a root password, changing it in the docker config will do nothing, and that you have to use mysqladmin. The problem is, I don't have a working password. My Nextcloud container depends on the database I created. Would it be possible to reset the root password without wiping any data?
-
Is this possible? If I were self-hosting multiple websites with docker containers and Nginx(Swag), would it be possible to route through my OpenVPN configuration? And if so, how should I go about doing it? Basically, when exposing my self-hosted domains to the public, I don't want my IP address to be exposed.
-
How do I change the warning levels? I don't see why I should be getting constant warnings just because I'm at 70%.
-
[SUPPORT] SmartPhoneLover - Aurora Files (Afterlogic)
Stubbs replied to SmartPhoneLover's topic in Docker Containers
The admin panel does not work. I logged in as the admin on the regular page which opened an admin panel, but I couldn't find a setting to configure a mail provider. Also, installing this container did not create an appdata directory. -
The latest update broke this container. Had to downgrade back to 2.5.219
-
Can you update the OwnCast container to v0.0.10? It released yesterday. Cheers.
-
They are not showing up on the log anymore, but the rebuild speed varies from 29 MB/s to 3 MB/s. I've been changing the cables around multiple times, and re-inserted the drives into the hotswap bay. I think it's working fine now, and I'm starting to suspect there's a big problem with one of my previous SATA cables. I actually had a really difficult time unplugging one from the motherboard.
-
I replaced the cables again and started rebuilding the parity drive. The speed went down to 2 MB/s at the start before going back up to 25 MB/s. I'm worried I'll be an old man before it fully rebuilds. I don't feel like touching it again because this has been an absolute nightmare for me all day. Jul 21 02:40:19 Tower kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth7db6519: link becomes ready Jul 21 02:40:19 Tower kernel: br-236e25b7e44c: port 3(veth7db6519) entered blocking state Jul 21 02:40:19 Tower kernel: br-236e25b7e44c: port 3(veth7db6519) entered forwarding state Jul 21 02:40:21 Tower avahi-daemon[4067]: Joining mDNS multicast group on interface veth7db6519.IPv6 with address fe80::ec19:f4ff:fe80:239c. Jul 21 02:40:21 Tower avahi-daemon[4067]: New relevant interface veth7db6519.IPv6 for mDNS. Jul 21 02:40:21 Tower avahi-daemon[4067]: Registering new address record for fe80::ec19:f4ff:fe80:239c on veth7db6519.*. Jul 21 02:40:39 Tower kernel: ata6.00: exception Emask 0x0 SAct 0x703000 SErr 0x0 action 0x0 Jul 21 02:40:39 Tower kernel: ata6.00: irq_stat 0x40000008 Jul 21 02:40:39 Tower kernel: ata6.00: failed command: WRITE FPDMA QUEUED Jul 21 02:40:39 Tower kernel: ata6.00: cmd 61/40:a0:a8:a4:7f/05:00:00:00:00/40 tag 20 ncq dma 688128 out Jul 21 02:40:39 Tower kernel: res 41/10:00:a8:a4:7f/00:00:00:00:00/40 Emask 0x481 (invalid argument) <F> Jul 21 02:40:39 Tower kernel: ata6.00: status: { DRDY ERR } Jul 21 02:40:39 Tower kernel: ata6.00: error: { IDNF } Jul 21 02:40:39 Tower kernel: ata6.00: configured for UDMA/133 Jul 21 02:40:39 Tower kernel: ata6: EH complete Jul 21 02:40:46 Tower kernel: ata6.00: exception Emask 0x0 SAct 0x7000000 SErr 0x0 action 0x0 Jul 21 02:40:46 Tower kernel: ata6.00: irq_stat 0x40000008 Jul 21 02:40:46 Tower kernel: ata6.00: failed command: WRITE FPDMA QUEUED Jul 21 02:40:46 Tower kernel: ata6.00: cmd 61/40:c0:a8:a4:7f/05:00:00:00:00/40 tag 24 ncq dma 688128 out Jul 21 02:40:46 Tower kernel: res 41/10:00:a8:a4:7f/00:00:00:00:00/40 Emask 0x481 (invalid argument) <F> Jul 21 02:40:46 Tower kernel: ata6.00: status: { DRDY ERR } Jul 21 02:40:46 Tower kernel: ata6.00: error: { IDNF } tower-diagnostics-20210721-0240.zip
-
Help tower-diagnostics-20210721-0215.zip
-
I just reconnected the previous(fast) cables, booted up, parity rebuild started, and sure enough, those old, nasty errors started appearing again, along with a lousy 6 MB/s rebuild speed (in contrast to the 50MB/s speed I had with the "slower" cables. Here is the log. My Array won't even turn off now, it's stuck on "Array Stopping•Retry unmounting disk share(s)...". I'm worried I will have to restart it again and pray no data will be lost. tower-diagnostics-20210721-0142.zip
-
Well, it appears to have started rebuilding without any issues so far. The problem is, I think I replaced the previous SATA cables with slower 3GB/S ones. I'm thinking that maybe I should do a quick swap back to the old ones, assuming they're not the problem. I don't want to spend a full 24 hours stressing my array.
-
This is what I did last time, which resulted in a 90% used up error log, and basically this: Trying again right now though. If it happens again, I'll upload the diagnostic.
-
Ok, my Disk 4 is back online and working, but my Parity Drive is still broken. Both of these drives are in my x3 HDD Hotswap Bay, which are powered by two power cables. They're extremely difficult to replace or re-insert in my set up so I couldn't do that. The middle HDD (disk 3) has not failed yet, but the Parity Drive in there still has problems. I replaced both SATA cables for the top and bottom bay (parity and disk 4). tower-diagnostics-20210721-0105.zip
-
My mistake. I was just looking at the top bar and neglected to look at the bottom of the posting area. Being stressed doesn't help... tower-diagnostics-20210721-0041.zip
-
-
https://files.catbox.moe/nsotzb.zip Alright, here it is. I also can't even boot my array anymore. My Parity HDD and Disk 4 are now showing up as unassigned devices that need to be formatted, and trying to format them results in "fail". I'm feeling sick...
-
I ran into a problem. I was encoding videos in the Handbrake container, then at the same time, ran into that highly obnoxious issue where the file permissions for certain folders reset to something I couldn't move, so I ran Safe New Permissions. This caused my Unraid server to freeze with all my CPU cores locked at 100%, and this wasn't ending so I had to shut down my server manually. When I restarted, I started getting these nasty errors. My parity drive wasn't working. I tried removing it from the array and readding it, it started a read check, but that just started returning a mountain of errors, and now my Disk 4 isn't working. I can't even copy-paste the log because it keeps filling up endlessly with errors. I'm scared all my data is starting to disappear now. Is there nothing that can be done?
-
Again, I'm not sure whether this is related to the Owncast software or the container, but when I try to set up external storage configured with Digital Ocean, I get the error: https://i.imgur.com/hYuOMnN.png Error: More than 1000 frames duplicated I could've sworn I got storage-based streaming working a few days ago, and it may have been before I updated the container to the latest version. I can't test it on the previous version because it's not listed on dockerhub. The stream basically looks like a slide show with a buffering circle. Also the stream portion uploaded to Digitalocean is split in 1.5mb increments, which clearly isn't right: https://i.imgur.com/FHWC0Iq.png It still works fine if I stream directly from my home server without using external storage, but I obviously don't want that because of my worse upload speed.
-
Thanks for the help anyway.
-
Hmm, that's so confusing. Maybe it's something to do with configuration. Here is mine with LibreWolf: On Waterfox, it outright doesn't work at all (all addons disabled): One of my viewers yesterday was a Waterfox user too and he said chat wasn't working. My Firefox was outdated though (because I don't use it) so maybe it works with that.

