

Stubbs
-
Posts
207 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Stubbs
-
There is some degree of truth to it.
-
Don't worry, I misunderstood what you meant when you said console.
-
Wait what? The Unraid built-in terminal wouldn't work without a GPU? I find that hard to believe. Why couldn't it just use a virtual GPU like VNC? I mean it uses that by default for VMs.
-
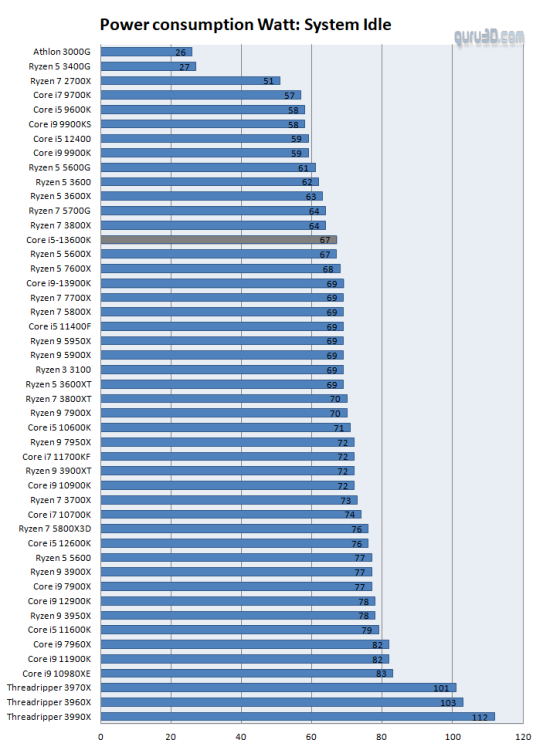
For an Unraid Server, does it makes more sense to buy a Ryzen CPU or APU? From what I understand, the regular CPUs are a bit more powerful (mainly in terms of L3 cache) and support ECC. But I heard APUs have lower idle power consumption thanks to monolithic design. Also maybe the iGPU could be used for something? I still don't know how to use it on Unraid, or if it can be used at all. I don't run a dGPU in my server, so if Vega Graphics on a G-series APU could be utilized, I'd love to know.
-
Does anyone know how to get an AMD iGPU working properly in Unraid? I have a Ryzen 2400G, and I would like to use the integreated GPU for hardware-accelerated transcoding, or maybe even the GPU for a VM. I have found limited information on getting this working.
-
Can someone tell me how I'm supposed to disable this annoying error? Usually it's meant to be infrequent and occurs maybe once a day. Now I'm seeing it all the time, constantly. From what I understand, it's a bug with Crucial SSDs and not actually a real problem. The real problem is the stupid error messages they keep producing. For the record, I attached an extended SMART test. tower-smart-20221127-0005.zip
-
Can it be smaller? What if I wanted to replace a 10TB drive with an 8TB drive?
-
Also, does the replacement drive have to be the exact same size as the failed drive? Or can it be any size above the used space?
-
I made probably my biggest, most costly mistake recently. I was upgrading my case to cool my drives better, but when re-connecting the HDD power connectors, I got my modular cables mixed up (they look exactly the same) and I ended up using cables from a Thermaltake 600W Gold PSU when my server uses a Seasonic 550W Gold PSU. Initially, the server wouldn't even power on (the fans would flicker once but that's it). I eventually figured out the cables were the problem, and I've since been told what I did was extremely dangerous for my hard drives and could easily brick one. Sure enough, one of them did brick, but the rest are fine. My question is, with the presumably irregular voltage they were taking in, will that likely have any long-term effects on the drives? Are they now more likely to fail in the future or have some kind of data loss? The still seem to be functioning normally now and I haven't noticed any data loss.
-
I currently have 30TB of storage and it shows in my array page. But my Rootshare on Windows shows 27.2TB. Does anyone know what might be causing this? I recently removed a 3TB drive from my array using this method: Could that have something to do with it?

-
Is it possible for a molex connector to not deliver enough power to an HDD? I recently upgraded my server from 3TB WD Reds to 10TB Seagate Ironwolfs, and the Ironwolfs kept returning errors in my server. Sometimes I'd get the parity sync working, but it would work at about 800kbps which would've taken about a year to finish. I fixed it by taking the Seagates out of the Hotswap Bay and into the case's internal 3.5" bay, and connecting them directly to both the motherboard (SATA) and the PSU (SATA Power connector). My Hotswap Bay has two SATA power connectors, and one of them is powered by a Molex connector (because that's all I could fit). Could a Molex cause a power bottleneck for higher capacity drives?
-
[SUPPORT] SmartPhoneLover - Rclone Browser (GUI for Rclone)
Stubbs replied to SmartPhoneLover's topic in Docker Containers
If I wanted this container and the Rclone Nacho GUI container to use the same rclone.conf file, what should I be doing? For the Rclone-Browser container, the path looks like this: /appdata/Rclone-Browser/xdg/config/rclone/rclone.conf For the Nacho-Rclone-Native-GUI container, the path is just /appdata/rclone/rclone.conf -
I want to power down my Disk 1 because it keeps running hot and I'm not upgrading my case for at least a month. The problem is it keeps making small reads every 7-8 seconds and I don't understand why. Even when nothing should be using it, it's still making reads. I assume it's maybe some kind of background check in a docker application, in which case, how can I tell which container is making these reads?
-
I'm inclined to post an issue here because it's a problem that occurs across every single docker container that enables audio streaming (Jellyfin, Navidrome, Gonic, Airsonic, all of them). I can stream video just fine. But when I try to stream a simple mp3 file, I get a message saying Playback Error This client isn't compatible with the media and the server isn't sending a compatible media format. In the Jellyfin logs, it says: [16:57:08] [ERR] [61] Jellyfin.Server.Middleware.ExceptionMiddleware: Error processing request: Could not find file '/music/Edwyn Collins - A Girl Like You.mp3'. URL GET /Audio/e2d30d0adc1e2d5c82d8247f7f4ec72f/universal. And a similar error is produced by all the other music streaming containers. I can tell you for a 100% fact that the folders are mapped correctly. They are showing up in Jellyfin/Navidrome just fine, they're just not playing on any device or browser. What is going on? Why is Unraid having such a hard time streaming audio?
-
[edit] Don't worry about it. Restarting the server fixed it, and I probably should've done that before freaking out with this thread. Can someone please help? I tried moving a file using the dynamic file manager plugin, it produced a weird error and as a result my entire user folder got purged. All the data still seems to my on the disks, but my server is currently completely non functional. Please help. tower-diagnostics-20221022-1054.zip
-
Not sure how I missed that. Thanks.
-
In Disk Settings, we have the option to change the "Default Spin Down Delay" to spin hard disks down after a set period of time. But this setting applies for all hard disks connected to the Unraid server. If I wanted this setting to only apply for two specific disks, what should I be doing? Would it require some kind of user script? Also, separate question, but is spinning down generally not encouraged? I see a lot of conflicting information on this subject. Some people say having disks in a spun-down state increases their lifespan, while others day it can degrade the disk quicker because the spin-up is the most likely action to physically break the drive.
-
The frustration continues. First, I tried connecting the Seagate to SATA_1. This was the port my cache drive was connected to. I connected the Seagate to it WITH the cache drive's cable. Same errors (1st FIS failed) (hard resetting link), along with 150KB/s parity rebuild. Diagnostics attached (sixth attempt). Then I reverted back to the exact same configuration where the parity build appeared to be working. Seagate connected to SATA_2 on the motherboard with its original cable, and I brought back the old orange SATA cable to connect the data drive to SATA_4. I powered the server back on, and it wouldn't even start the rebuild. The parity disk (seagate) was stuck in a disabled state. Stopped and started the array, and it was still disabled. Diagnostics attached (seventh) (disabled). Finally, I tried a different cable and a different port again, this time SATA_5. I powered the server back on, and initially it started rebuilding just fine at 90MB/s. But after about 30 seconds, the same errors shows up again. Oct 1 08:42:59 Tower kernel: ata9: softreset failed (1st FIS failed) Oct 1 08:43:05 Tower kernel: ata9: found unknown device (class 0) Oct 1 08:43:06 Tower kernel: ata9: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Oct 1 08:43:06 Tower kernel: ata9.00: configured for UDMA/133 Oct 1 08:43:06 Tower kernel: ata9.00: exception Emask 0x10 SAct 0x60000000 SErr 0x90202 action 0xe frozen Oct 1 08:43:06 Tower kernel: ata9.00: failed command: WRITE FPDMA QUEUED Oct 1 08:43:06 Tower kernel: ata9.00: cmd 61/c8:f0:c8:c5:14/00:00:00:00:00/40 tag 30 ncq dma 102400 out Oct 1 08:43:06 Tower kernel: res 40/00:e8:88:c0:14/00:00:00:00:00/40 Emask 0x10 (ATA bus error) Oct 1 08:43:06 Tower kernel: ata9.00: status: { DRDY } Oct 1 08:43:06 Tower kernel: ata9: hard resetting link And the parity build got slower and slower. 90MB/s to 30MB/s to 13MB/s and so on, so I cancelled it. Diagnostics attached (eighth attempt). (eighth)tower-diagnostics-20221001-0843.zip (seventh) (disabled) tower-diagnostics-20221001-0755.zip (sixth)tower-diagnostics-20221001-0732.zip
-
I agree, which is why I'm going to keep trying to get it working the next chance I get (I can't power it off right now). I'm hoping if I can get parity built, the storage drives will be less trouble. I have an HBA Card but I really don't want to install it yet. The only PCIe x16 slot is currently occupied by a NIC, which I use for a virtualized router. I'm really not keen on using a backup router without all my firewall stuff set up. This is the main reason I'm going to buy a new motherboard on black friday/cyber monday.
-
Unfortunately no. The 4th attempt was the first time the parity check actually started running, but it was at 300K/Bs and errors kept repeating in the log. I shut down the server, plugged the Seagate into SATA port 2 with it's original cable, powered the server on, and parity started building properly. I didn't save a diagnostics file because I thought the problem was gone. I cancelled the parity build and shut down the server again (the case was open and laying on the floor). The only other thing I did was swap out the SATA4 cableto a newer cable. This was connected to a data drive and was unrelated to the Seagate. (fifth) is the most recent diagnostics. Exact same cable and port for the Seagate when the parity build worked. For some reason it went back to this:
-
Alright, I gave it a try and got some mixed results. I updated the BIOS on my Asus B450M-A first because that was the simplest. Didn't fix it. There were also no firmware updates available for these disks. I proceeded to change some of the SATA cabling around. I swapped one of my internal drive's data cable with the Seagate's, and I think it was connected to SATA2 on the motherboard. The errors persisted but the parity check started. It just ran extremely slow (would've taken a year to build) and the log was full of errors so something was wrong. It looked like this: https://i.imgur.com/jTvI3JR.png Diagnostics attached attached(fourth attempt) So I shut down, tried a different cable setup. I plugged the Seagate into SATA2 using it's original cable (not the one I swapped in). Started a parity check and it worked; parity actually started building normally. But my server case was still open and not in its usual resting spot. So I cancelled the parity check, shut down the server, put the case cover back on and moved the server back into its original position. I powered back on, started the parity check and... back to really slow speeds, taking 300+ days to rebuild. Diagnostics attached(fifth attempt). I just don't understand. It went from working fine to not working. It's using the same cable, same port, but after one shutdown cycle, the parity build decided not to work anymore. (fifth)tower-diagnostics-20220930-1141.zip (fourth attempt)tower-diagnostics-20220930-1108.zip
-
Yes, both the two I tested. I attached diagnostics for both in the OP. [edit] Also my motherboard has six SATA ports: https://www.asus.com/au/motherboards-components/motherboards/prime/prime-b450m-a/ I connected them via my hotswap bay mounted to the front of the case. This bay has three SATA ports, and is powered by two SATA power connectors. I will try connecting the new drives to the motherboard the next opportunity I get. That being said, I find it a bit strange that the WD Red drives work perfectly fine in the bay, yet the Seagates do not. Could this have something to do with the WD Reds being 5400RPM, and the Seagates being 7200RPM? Because the hotswap bay (which includes a fan) is powered by only two SATA power cables. Could that introduce some kind of bottleneck if a drive with higher RPM was installed?
-
I already did. As stated in the OP, I put my old WD Red Parity back in the slot, and there were no errors. The parity build started, and worked just fine. I then cancelled the rebuild. I put the new Seagate back in that slot; exact same cables, exact same screws and everything. Same errors. I then tried putting the new Seagate in a different slot with different cables. Again, same errors. Then I connected the Seagate to my Windows 10 PC via a docking station/toaster. I formatted it with NTFS and it's working fine. The new Seagate drives seem to be working fine. For some reason Unraid doesn't want to build parity on them.
-
Upon reflection, I just realized I'm dumb, and forgot I don't need to do that at all while I'm rebuilding parity, lol.
-
Consider this a semi-continuation from my previous thread (https://forums.unraid.net/topic/128808-need-help-upgrading-my-hdds/#comment-1173836) But this is a separate problem. To summarize: I bought four new 10TB Seagate Ironwolf Hard Drives. This is to upgrade the storage of my current array, which is: three 3TB WD Reds(one parity), two 2TB WD Reds. As people on this forum instructed me, I started by replacing the WD Red 3TB Parity Drive with one of the Ironwolf 10TB drives. I shut my server down, removed the WD Red, installed the Seagate in it's place, and booted the server back up. I headed to the "Main" menu, confirmed there was no parity drive, and my Seagate was there under unassigned devices. I shut down the array, assigned the Seagate Ironwolf as a parity, started the array and... errors. Straight away, I ran diagnostics (see attachment: (first attempt)). It took a few minutes for the array to even boot up, but when it finally did, parity almost immediately started returning errors and a read-check was initiated. Before making this thread, I thought I'd do some extra tests. I powered down the server, took the Seagate Ironwolf out and replaced it with one of the other brand new Seagate Ironwolfs I bought. I powered the server back on, tried to build parity with the next Seagate, and it returned the same errors (see attachment: (second attempt)). Finally, I put my old WD Red 3TB parity drive back in. Once again, I triggered a parity rebuild and... it worked fine, parity started rebuilding without any errors. Can anyone explain to me what the problem is? Is it another case of hardware connectivity issues? Is it something to do with being a different brand of HDD?(I thought Unraid didn't care about this). Did I somehow buy two dud HDDs? Here's some logging snippets (not that it matters much): Sep 28 23:52:19 Tower avahi-daemon[9851]: Interface vethec6bd6e.IPv6 no longer relevant for mDNS. Sep 28 23:52:19 Tower avahi-daemon[9851]: Leaving mDNS multicast group on interface vethec6bd6e.IPv6 with address fe80::704d:adff:fe0f:2f34. Sep 28 23:52:19 Tower kernel: docker0: port 10(vethec6bd6e) entered disabled state Sep 28 23:52:19 Tower kernel: device vethec6bd6e left promiscuous mode Sep 28 23:52:19 Tower kernel: docker0: port 10(vethec6bd6e) entered disabled state Sep 28 23:52:19 Tower avahi-daemon[9851]: Withdrawing address record for fe80::704d:adff:fe0f:2f34 on vethec6bd6e. Sep 28 23:52:20 Tower kernel: ata6: found unknown device (class 0) Sep 28 23:52:25 Tower kernel: ata6: softreset failed (1st FIS failed) Sep 28 23:52:25 Tower kernel: ata6: hard resetting link Sep 28 23:52:30 Tower kernel: ata6: found unknown device (class 0) Sep 28 23:52:30 Tower kernel: ata6: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Sep 28 23:52:31 Tower kernel: ata6.00: configured for UDMA/133 Sep 28 23:52:31 Tower kernel: sd 6:0:0:0: [sdh] tag#3 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=16s Sep 28 23:52:31 Tower kernel: sd 6:0:0:0: [sdh] tag#3 Sense Key : 0x5 [current] Sep 28 23:52:31 Tower kernel: sd 6:0:0:0: [sdh] tag#3 ASC=0x21 ASCQ=0x4 Sep 28 23:52:31 Tower kernel: sd 6:0:0:0: [sdh] tag#3 CDB: opcode=0x88 88 00 00 00 00 00 00 00 00 10 00 00 00 08 00 00 Sep 28 23:52:31 Tower kernel: I/O error, dev sdh, sector 16 op 0x0:(READ) flags 0x80700 phys_seg 1 prio class 0 Sep 28 23:52:31 Tower kernel: sd 6:0:0:0: [sdh] tag#7 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=16s Sep 28 23:52:31 Tower kernel: sd 6:0:0:0: [sdh] tag#7 Sense Key : 0x5 [current] Sep 28 23:52:31 Tower kernel: sd 6:0:0:0: [sdh] tag#7 ASC=0x21 ASCQ=0x4 Sep 28 23:52:31 Tower kernel: sd 6:0:0:0: [sdh] tag#7 CDB: opcode=0x88 88 00 00 00 00 00 00 00 01 08 00 00 00 f8 00 00 Sep 28 23:52:31 Tower kernel: I/O error, dev sdh, sector 264 op 0x0:(READ) flags 0x80700 phys_seg 2 prio class 0 Sep 28 23:52:31 Tower kernel: ata6: EH complete Sep 28 23:52:32 Tower kernel: ata6.00: exception Emask 0x50 SAct 0x400 SErr 0xb0802 action 0xe frozen Sep 28 23:52:32 Tower kernel: ata6.00: irq_stat 0x00400000, PHY RDY changed Sep 28 23:52:32 Tower kernel: ata6: SError: { RecovComm HostInt PHYRdyChg PHYInt 10B8B } Sep 28 23:52:32 Tower kernel: ata6.00: failed command: READ FPDMA QUEUED Sep 28 23:52:32 Tower kernel: ata6.00: cmd 60/08:50:40:20:00/00:00:00:00:00/40 tag 10 ncq dma 4096 in Sep 28 23:52:32 Tower kernel: res 40/00:50:40:20:00/00:00:00:00:00/40 Emask 0x50 (ATA bus error) Sep 28 23:52:32 Tower kernel: ata6.00: status: { DRDY } Sep 28 23:52:32 Tower kernel: ata6: hard resetting link Sep 28 23:52:32 Tower kernel: ata6: SATA link down (SStatus 0 SControl 300) Sep 28 23:52:33 Tower kernel: ata6: hard resetting link Sep 28 23:52:39 Tower kernel: ata6: found unknown device (class 0) Sep 28 23:52:43 Tower kernel: ata6: softreset failed (1st FIS failed) Sep 28 23:52:43 Tower kernel: ata6: hard resetting link Sep 28 23:52:49 Tower kernel: ata6: found unknown device (class 0) Sep 28 23:52:49 Tower kernel: ata6: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Sep 28 23:52:49 Tower kernel: ata6.00: configured for UDMA/133 Sep 28 23:52:49 Tower kernel: sd 6:0:0:0: [sdh] tag#10 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=17s Sep 28 23:52:49 Tower kernel: sd 6:0:0:0: [sdh] tag#10 Sense Key : 0x5 [current] Sep 28 23:52:49 Tower kernel: sd 6:0:0:0: [sdh] tag#10 ASC=0x21 ASCQ=0x4 Sep 28 23:52:49 Tower kernel: sd 6:0:0:0: [sdh] tag#10 CDB: opcode=0x88 88 00 00 00 00 00 00 00 20 40 00 00 00 08 00 00 Sep 28 23:52:49 Tower kernel: I/O error, dev sdh, sector 8256 op 0x0:(READ) flags 0x80700 phys_seg 1 prio class 0 Sep 28 23:52:49 Tower kernel: ata6: EH complete Sep 28 23:52:49 Tower emhttpd: error: hotplug_devices, 1730: No such file or directory (2): Error: tagged device ST10000VN000-3AK101_WWY036M2 was (sde) is now (sdh) Sep 28 23:52:49 Tower emhttpd: read SMART /dev/sdh Sep 28 23:52:49 Tower kernel: emhttpd[5074]: segfault at 674 ip 0000000000413f90 sp 00007ffcc22ab490 error 4 in emhttpd[403000+1d000] Sep 29 00:29:47 Tower kernel: SVM: TSC scaling supported Sep 29 00:29:47 Tower kernel: kvm: Nested Virtualization enabled Sep 29 00:29:47 Tower kernel: SVM: kvm: Nested Paging enabled Sep 29 00:29:47 Tower kernel: SEV supported: 16 ASIDs Sep 29 00:29:47 Tower kernel: SEV-ES supported: 4294967295 ASIDs Sep 29 00:29:47 Tower kernel: SVM: Virtual VMLOAD VMSAVE supported Sep 29 00:29:47 Tower kernel: SVM: Virtual GIF supported Sep 29 00:29:47 Tower kernel: SVM: LBR virtualization supported Sep 29 00:29:47 Tower kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth9d6e238: link becomes ready Sep 29 00:29:47 Tower kernel: docker0: port 9(veth9d6e238) entered blocking state Sep 29 00:29:47 Tower kernel: docker0: port 9(veth9d6e238) entered forwarding state Sep 29 00:29:47 Tower kernel: tun: Universal TUN/TAP device driver, 1.6 Sep 29 00:29:47 Tower kernel: mdcmd (36): check Sep 29 00:29:47 Tower kernel: md: recovery thread: recon P ... Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=0 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=8 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=16 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=24 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=32 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=40 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=48 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=56 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=64 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=72 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=80 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=88 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=96 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=104 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=112 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=120 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=128 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=136 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=144 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=152 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=160 Sep 29 00:29:47 Tower kernel: md: disk0 write error, sector=168 (second attempt)tower-diagnostics-20220928-2354.zip (first attempt)tower-diagnostics-20220929-0030.zip


