




DanW
Members
-
Joined
-
Last visited
Everything posted by DanW
-
I had to hard reset my server and it booted without any issues, now its doing a parity check 🙄 I dont understand why this suddenly happened and completely locked up the GUI.
-
If it's a new flash drive, it should not be blacklisted, assuming it has a unique GUID. What if the flash drive is not broken and unraid has just corrupted itself? When you reinstall unraid onto the old flash drive to repair the unraid corruption should the license still work?
-
I have the same issue, it's basically locked me out of my server. Really annoying having to deal with this.
-
I ended up using mysql:5.7 as the repo.
-
Hey, any ideas how to get mysql_native_password working with this docker? I've tried adding these separately & together to post arguments and the docker just reboot loops. --mysql_native_password=ON --default_authentication_plugin=mysql_native_password Also tried adding the variable to the docker. MYSQL_AUTHENTICATION_PLUGIN mysql_native_password That cnf file that I could just edit sure would be useful right now 😂 EDIT: The owner hasn't been online in 6 months... looks like we aren't getting any support here.
-
I gave the server a reboot and ran a memtest, it passed. The CPU usage looks a lot healthier after rebooting. I hope I'm not going to need to reboot unraid weekly to prevent this issue.
-
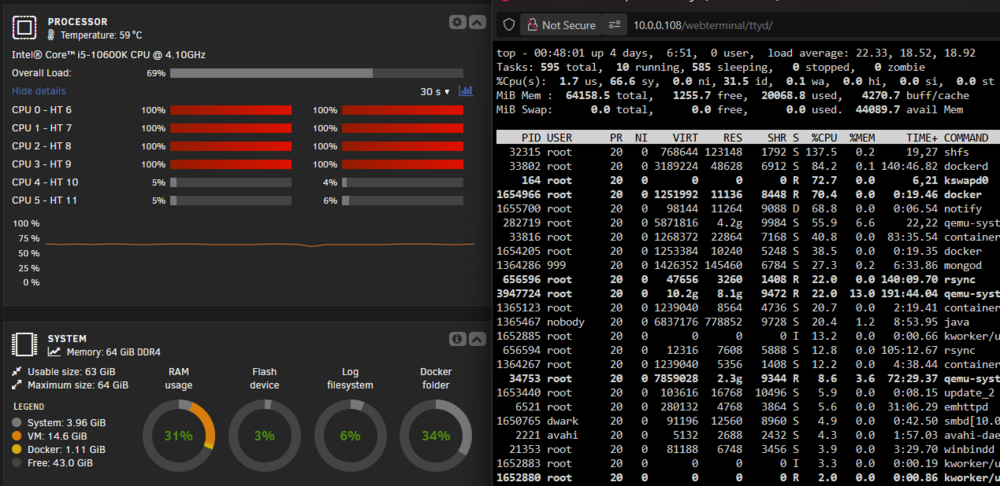
Still not sure what is hitting the cpu so hard. I've double checked the CPU pinning to make sure all dockers are pinned correctly to free up CPU 0 & 1. It's taking minutes to load and check these details so its pretty painful. I stopped my unifi network docker (I have a feeling just stopping any docker would have ben fine) and the cpu usage is no longer stuck at 100%, everything is responsive again. The CPU usage still seems to be spiking unusally high on all (non-isolated) cores though and I have a feeling over time it will return to 100% again. I noticed that loading into plex spikes all cores to 100% and shfs shows high cpu usage in the terminal.
-
I turned off folder caching and it had no impact. I looked to my dockers and stopped my unifi network docker and the CPU usage went back to normal. I realised I hadn't set up pinning on that docker, so that's configured now. I'm going to continue to monitor but anything CPU intensive is destroying unraid, ive never noticed this before.
-
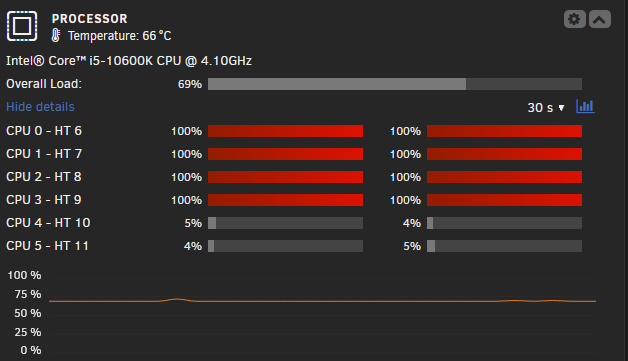
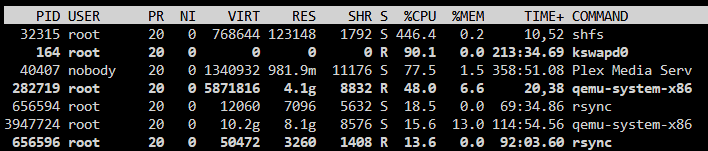
Happened to be sat on the main tab when the issue started again. shfs is using a lot of cpu, apparently it can be related to the folder caching plugin which I was messing around with yesterday. High CPU usage can happen during TRIM too and I was scheduling TRIM weekly, I get this issue with unraid weekly usually... I have a lot of SSDs / Nvmes, I wonder if its related. The CPU load is so high that it is making unraid & the array completely unusable.
-
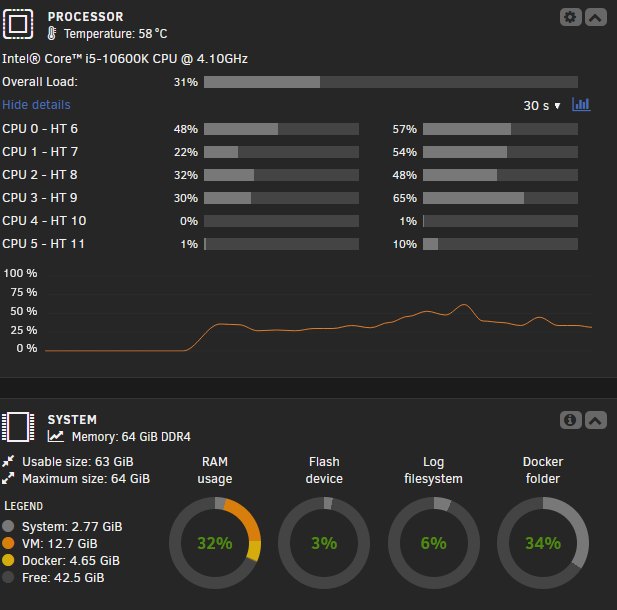
It's been stable over the weekend. I fired up a Linux VM along side a couple of other running VMs which all use unassigned drives and the stability lasted about 10 minutes. I use CPU isolation so the VMs use CPUs not in use by Unraid. Web UI became completely unresponsive, even with the changes suggested, and running dockers e.g. plex seem to be running but couldn't access the array to load content, same old story. Apr 21 11:16:44 DansUnRaidNAS webgui: Successful login user root from 10.0.0.23 Apr 21 11:17:21 DansUnRaidNAS kernel: br0: port 5(vnet3) entered blocking state Apr 21 11:17:21 DansUnRaidNAS kernel: br0: port 5(vnet3) entered disabled state Apr 21 11:17:21 DansUnRaidNAS kernel: vnet3: entered allmulticast mode Apr 21 11:17:21 DansUnRaidNAS kernel: vnet3: entered promiscuous mode Apr 21 11:17:21 DansUnRaidNAS kernel: br0: port 5(vnet3) entered blocking state Apr 21 11:17:21 DansUnRaidNAS kernel: br0: port 5(vnet3) entered forwarding state Apr 21 11:24:46 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3531765 exited on signal 9 (SIGKILL) after 53.001782 seconds from start Apr 21 11:24:47 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3531813 exited on signal 9 (SIGKILL) after 53.616490 seconds from start Apr 21 11:25:09 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3531799 exited on signal 9 (SIGKILL) after 75.097587 seconds from start Apr 21 11:25:10 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3531814 exited on signal 9 (SIGKILL) after 76.592013 seconds from start Apr 21 11:25:32 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3531815 exited on signal 9 (SIGKILL) after 96.189549 seconds from start Apr 21 11:26:37 DansUnRaidNAS monitor_nchan: Stop running nchan processes Apr 21 11:27:42 DansUnRaidNAS winbindd[21357]: [2025/04/21 11:27:42.291011, 0, traceid=52448] ../../source3/winbindd/winbindd_samr.c:71(open_internal_samr_conn) Apr 21 11:27:42 DansUnRaidNAS winbindd[21357]: open_internal_samr_conn: Could not connect to samr pipe: NT_STATUS_CONNECTION_DISCONNECTED Apr 21 11:28:08 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3534534 exited on signal 9 (SIGKILL) after 199.553446 seconds from start Apr 21 11:28:09 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3535068 exited on signal 9 (SIGKILL) after 178.435411 seconds from start Apr 21 11:28:11 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3535319 exited on signal 9 (SIGKILL) after 157.769059 seconds from start Apr 21 11:28:20 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3537213 exited on signal 9 (SIGKILL) after 12.379554 seconds from start Apr 21 11:28:22 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3537217 exited on signal 9 (SIGKILL) after 12.415261 seconds from start Apr 21 11:28:24 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3537224 exited on signal 9 (SIGKILL) after 13.247641 seconds from start Apr 21 11:28:32 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3537276 exited on signal 9 (SIGKILL) after 11.700707 seconds from start Apr 21 11:28:34 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3537315 exited on signal 9 (SIGKILL) after 12.047144 seconds from start Apr 21 11:28:36 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3537362 exited on signal 9 (SIGKILL) after 11.748763 seconds from start Apr 21 11:28:45 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3537449 exited on signal 9 (SIGKILL) after 12.438241 seconds from start Apr 21 11:28:47 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3537472 exited on signal 9 (SIGKILL) after 12.743702 seconds from start Apr 21 11:28:48 DansUnRaidNAS winbindd[21357]: [2025/04/21 11:28:48.029191, 0, traceid=52458] ../../source3/winbindd/winbindd_samr.c:71(open_internal_samr_conn) Apr 21 11:28:48 DansUnRaidNAS winbindd[21357]: open_internal_samr_conn: Could not connect to samr pipe: NT_STATUS_CONNECTION_DISCONNECTED Apr 21 11:28:49 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3537502 exited on signal 9 (SIGKILL) after 13.133407 seconds from start Apr 21 11:28:58 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3537755 exited on signal 9 (SIGKILL) after 12.444715 seconds from start Apr 21 11:28:59 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3537765 exited on signal 9 (SIGKILL) after 12.276622 seconds from start Apr 21 11:29:01 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3537771 exited on signal 9 (SIGKILL) after 12.248865 seconds from start Apr 21 11:29:11 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3537820 exited on signal 9 (SIGKILL) after 12.091068 seconds from start Apr 21 11:29:35 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3537818 exited on signal 9 (SIGKILL) after 31.924813 seconds from start Apr 21 11:29:46 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3538076 exited on signal 9 (SIGKILL) after 32.878311 seconds from start Apr 21 11:30:17 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3535055 exited on signal 9 (SIGKILL) after 307.699827 seconds from start Apr 21 11:30:56 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3538757 exited on signal 9 (SIGKILL) after 38.071488 seconds from start Apr 21 11:31:15 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3538080 exited on signal 9 (SIGKILL) after 121.705529 seconds from start Apr 21 11:31:32 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3537969 exited on signal 9 (SIGKILL) after 138.808158 seconds from start Apr 21 11:32:05 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3537832 exited on signal 9 (SIGKILL) after 183.883281 seconds from start Apr 21 11:32:21 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3538258 exited on signal 9 (SIGKILL) after 161.785909 seconds from start Apr 21 11:32:23 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3538298 exited on signal 9 (SIGKILL) after 156.739400 seconds from start Apr 21 11:32:30 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3540129 exited on signal 9 (SIGKILL) after 57.278373 seconds from start Apr 21 11:32:47 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3540757 exited on signal 9 (SIGKILL) after 15.263023 seconds from start Apr 21 11:33:18 DansUnRaidNAS kernel: br0: port 3(vnet1) entered disabled state Apr 21 11:33:18 DansUnRaidNAS kernel: vnet1 (unregistering): left allmulticast mode Apr 21 11:33:18 DansUnRaidNAS kernel: vnet1 (unregistering): left promiscuous mode Apr 21 11:33:18 DansUnRaidNAS kernel: br0: port 3(vnet1) entered disabled state Apr 21 11:33:18 DansUnRaidNAS php-fpm[8264]: [WARNING] [pool www] child 3540769 exited on signal 9 (SIGKILL) after 54.833446 seconds from start Apr 21 11:33:32 DansUnRaidNAS winbindd[21357]: [2025/04/21 11:33:32.516835, 0, traceid=52460] ../../source3/winbindd/winbindd_samr.c:71(open_internal_samr_conn) Apr 21 11:33:32 DansUnRaidNAS winbindd[21357]: open_internal_samr_conn: Could not connect to samr pipe: NT_STATUS_CONNECTION_DISCONNECTED I shut down another VM that I was connected to and unraid is back again. I don't understand why unraid is doing this, resource usage is not high...
-
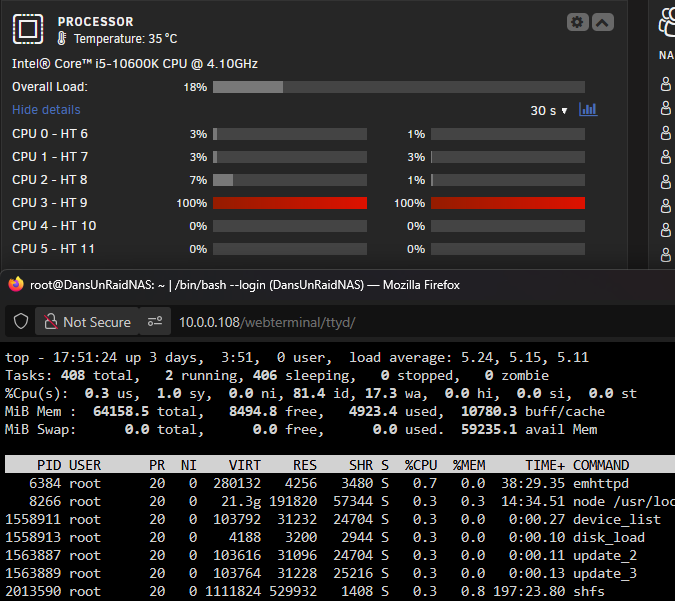
I'll go and hold the power button down. Thank you for checking in. No idea why those two cores are maxed out.
-
The array wont stop. Has been stuck for an hour... Not having a lot of joy. Something is maxing out two of the cores, not sure wtf is going on. Dockers & VMs aren't even running atm. I've tried to init a reboot or shutdown with no success either. Apr 17 14:20:13 DansUnRaidNAS unassigned.devices: Unmounting Remote SMB/NFS Share '//10.0.0.104/media'... Apr 17 14:20:13 DansUnRaidNAS unassigned.devices: Unmount cmd: /sbin/umount -t cifs -l '/mnt/remotes/QnapUnraid_media' 2>&1 Apr 17 14:22:34 DansUnRaidNAS nginx: 2025/04/17 14:22:34 [error] 15976#15976: *1132710 upstream timed out (110: Connection timed out) while reading upstream, client: 10.0.0.21, server: , request: "POST /update.htm HTTP/1.1", upstream: "http://unix:/var/run/emhttpd.socket:/update.htm", host: "10.0.0.108", referrer: "http://10.0.0.108/Main" Apr 17 14:28:43 DansUnRaidNAS shutdown[95945]: shutting down for system reboot Apr 17 14:28:59 DansUnRaidNAS shutdown[96715]: shutting down for system reboot Apr 17 14:31:39 DansUnRaidNAS shutdown[104472]: shutting down for system halt Apr 17 14:35:27 DansUnRaidNAS ool www[95743]: /usr/local/emhttp/plugins/dynamix/scripts/emcmd 'cmdStatus=Apply' Apr 17 14:36:48 DansUnRaidNAS monitor_nchan: Stop running nchan processes Apr 17 14:43:16 DansUnRaidNAS flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Apr 17 15:00:03 DansUnRaidNAS emhttpd: spinning down /dev/sdg Apr 17 15:05:02 DansUnRaidNAS emhttpd: read SMART /dev/sdg Apr 17 15:11:41 DansUnRaidNAS emhttpd: spinning down /dev/sdl Apr 17 15:11:43 DansUnRaidNAS emhttpd: spinning down /dev/sdm Apr 17 15:19:36 DansUnRaidNAS emhttpd: spinning down /dev/sdd Apr 17 15:19:36 DansUnRaidNAS emhttpd: spinning down /dev/sdt Apr 17 15:19:36 DansUnRaidNAS emhttpd: spinning down /dev/sde Apr 17 15:19:36 DansUnRaidNAS emhttpd: spinning down /dev/sdb Apr 17 15:19:36 DansUnRaidNAS emhttpd: spinning down /dev/sdr Apr 17 15:19:36 DansUnRaidNAS emhttpd: spinning down /dev/sdf Apr 17 15:19:36 DansUnRaidNAS emhttpd: spinning down /dev/sdv Apr 17 15:19:36 DansUnRaidNAS emhttpd: spinning down /dev/sdc Apr 17 15:19:36 DansUnRaidNAS emhttpd: spinning down /dev/sds Apr 17 15:19:36 DansUnRaidNAS emhttpd: spinning down /dev/sdn Apr 17 15:19:36 DansUnRaidNAS emhttpd: spinning down /dev/sdo Apr 17 15:20:10 DansUnRaidNAS emhttpd: spinning down /dev/nvme1n1 Apr 17 15:20:10 DansUnRaidNAS emhttpd: sdspin /dev/nvme1n1 down: 25 Apr 17 15:20:12 DansUnRaidNAS emhttpd: spinning down /dev/sdh Apr 17 15:20:13 DansUnRaidNAS emhttpd: spinning down /dev/sdi Apr 17 15:20:14 DansUnRaidNAS emhttpd: spinning down /dev/sdj Apr 17 15:25:02 DansUnRaidNAS emhttpd: read SMART /dev/sdh Apr 17 15:25:02 DansUnRaidNAS emhttpd: read SMART /dev/sdi Apr 17 16:05:04 DansUnRaidNAS emhttpd: spinning down /dev/sdg Apr 17 16:10:02 DansUnRaidNAS emhttpd: read SMART /dev/sdg dansunraidnas-diagnostics-20250417-1622.zip

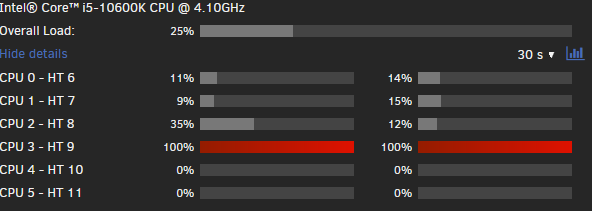
-
I stopped the plex docker and everything is back to normal. Need to investigate further.
-
The webui has slowed down a lot today, some tabs are taking minutes to load. I'll give safe mode a try soon. syslog-10.0.0.108.log
-
Unfortunatley still getting the issue, my dockers / vms / smb are losing access to the array but the web gui stays responsive now so I can see the array struggling. I have a backup task running over smb to another unraid nas and I can see the array speed crawl to under 1 MB/s. The plex docker keeps losing the array and struggles to find cotent then suddenly unraid recovers and its back to normal. Such a weird issue. syslog-10.0.0.108.log
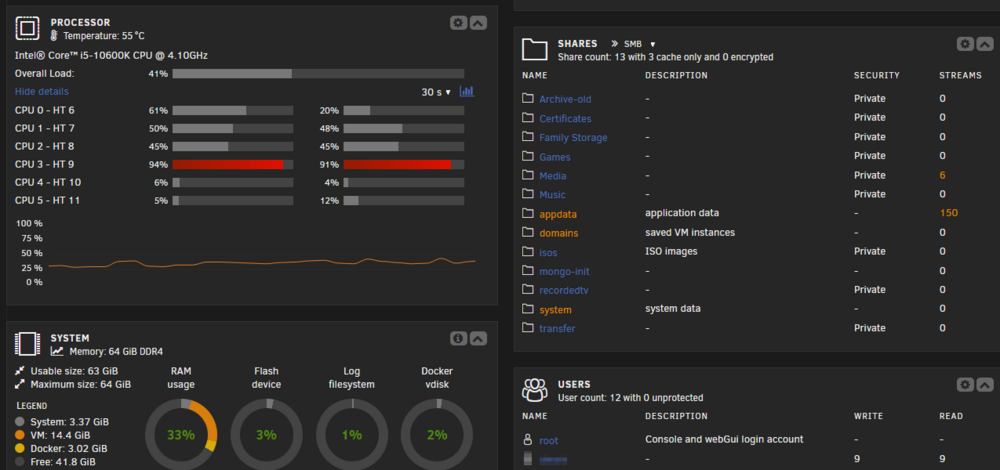
-
Ah ok, thank you for the response.
-
I tried to set up a docker for Humanitz but had no joy. Can you just run any game in this docker or does it need configuring specifically for the game? docker run -d --name='HumanitZ' --net='bridge' --cpuset-cpus='1,7' --pids-limit 2048 -e TZ="Europe/London" -e HOST_OS="Unraid" -e HOST_HOSTNAME="UnraidNAS" -e HOST_CONTAINERNAME="HumanitZ" -e 'GAME_ID'='2728330 -beta linuxbranch' -e 'GAME_PARAMS'='-log -servername Test' -e 'VALIDATE'='' -e 'UID'='99' -e 'GID'='100' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.icon='https://i.imgur.com/L4k2cG6.png' -p '7777:7777/udp' -p '27015:27015/udp' -p '7777:7777/tcp' -p '27015:27015/tcp' -v '/mnt/user/appdata/steamcmd':'/serverdata/steamcmd':'rw' -v '/mnt/user/appdata/humanitz':'/serverdata/serverfiles':'rw' 'ich777/steamcmd' 27a60c484e336ba940b157daa4b533de6ace6b0f422bd049ad9dc77d4eb06c98 The command finished successfully! The docker crashes after downloading the server files and calling start-server.sh
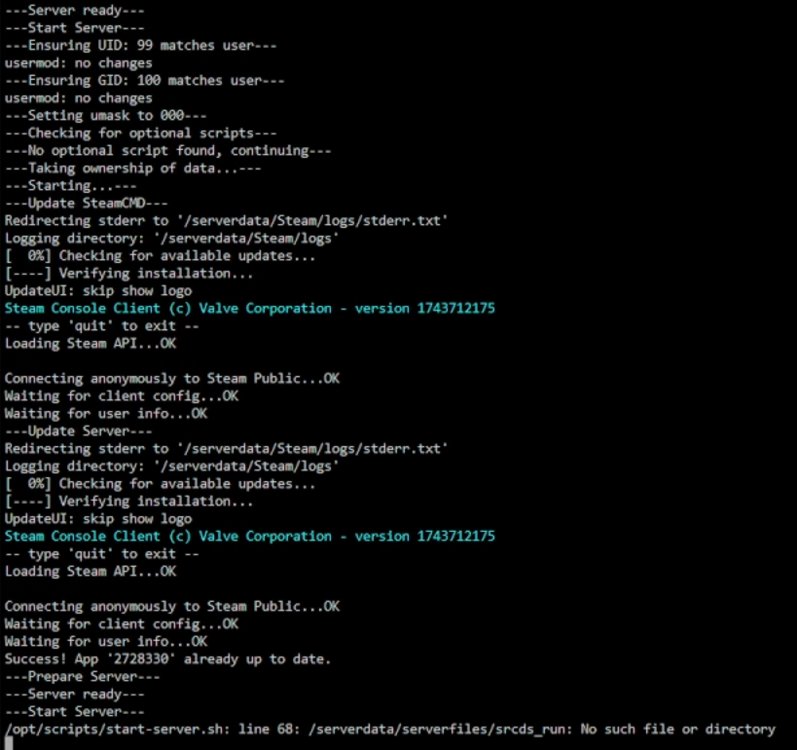
-
Thanks for the help so far Its a i5-10600K with two cores dedicated to the unraid and there is about 50GB RAM free, it has plenty of juice. I doubt the server is running slow unless the flash is being hammered. The issue only seems to happen when I am running large file transfers over SMB. I'll max out the file descriptors and create the ram drive for the flash and see how it goes.
-
Hey @JorgeB here is the syslog, the server has been stable for 7 days and I was using it last night just like normal - running some backup SMB transfers to my other unraid NAS. My web GUI is unresponsive this morning and the dockers are... limping. Its like the cache pool & array are running on a 56k modem, everything is pinging and seems to attempt to load in like normal but times out / errors, sometimes they load but its at a snails pace. I have a VM running on the frozen unraid NAS using an unassigned nvme and its running fine, I am able to connect in and use the VM like normal. This VM has a task to transfer files to a share via powershell and I can see that the task has froze because the network drives are not accessible. Looks like the trouble started with these lines. Apr 14 06:17:55 DansUnRaidNAS winbindd[2284]: [2025/04/14 06:17:55.419350, 0, traceid=67911] ../../source3/winbindd/winbindd_samr.c:111(open_internal_lsa_conn) Apr 14 06:17:55 DansUnRaidNAS winbindd[2284]: open_internal_lsa_conn: Could not connect to lsarpc pipe: NT_STATUS_IO_TIMEOUT Apr 14 06:18:28 DansUnRaidNAS winbindd[2284]: [2025/04/14 06:18:27.223844, 0, traceid=67913] ../../source3/winbindd/winbindd_samr.c:71(open_internal_samr_conn) Apr 14 06:18:28 DansUnRaidNAS winbindd[2284]: open_internal_samr_conn: Could not connect to samr pipe: NT_STATUS_IO_TIMEOUT Samba playing up? syslog-10.0.0.108.log
-
I upgraded from 6.12.* to 7.0.1 and it has been unstable on my main NAS hosting plex etc. with random unraid freezes, espcially related to the GUI and dockers. The system was rock solid stable before. My second NAS that does almost nothing has been fine on 7.0.1. Still trying to get to the bottom of my issues but I'd advise caution to anyone else. There appears to be people having similar issues on the forum.
-
It got stuck and I powered off the nas manually. It didn't generate anything. dansunraidnas-diagnostics-20250406-2159.zip
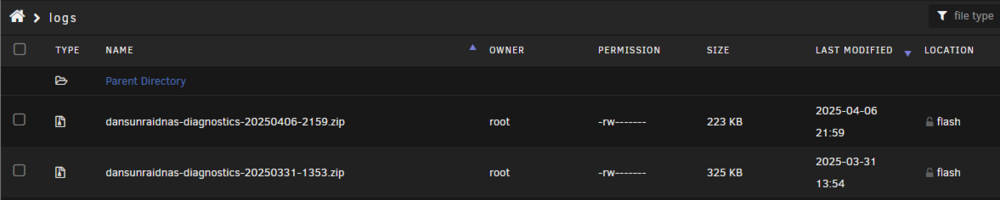
-
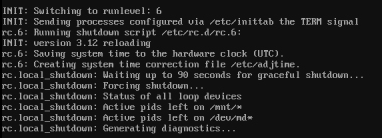
I've presed ctrl+alt+del and it's started a graceful shutdown. Been stuck like this for a while now.
-
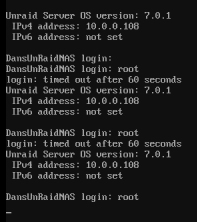
Hey @JorgeB, tightening the ram usage has helped but the server is still locking up, not as often though. I haven't seen the issue in days. I can't even login because the password prompt doesnt appear. The server has two cores assigned now and there should be 16-32GB ram free. The dockers e.g. plex, unifi seem like they're running, the ip/ports are working, i can access their local web pages but they dont load content. VMs are accessible too, I was able to RDP in to a VM but the performance was majorly impacted, it was unusable. No idea what to do here.
 Hey Jorge, Thanks for the response 🙂 I'll run the server a bit leaner with the ram to see if it makes a difference. I do use CPU pinning pretty religiously to make sure unraid always has 0 to itself, I can look at tweaking this include 1 too. I've doubled the fuse File Descriptors.
Hey Jorge, Thanks for the response 🙂 I'll run the server a bit leaner with the ram to see if it makes a difference. I do use CPU pinning pretty religiously to make sure unraid always has 0 to itself, I can look at tweaking this include 1 too. I've doubled the fuse File Descriptors.













