




b0m541
Members
-
Joined
-
Last visited
Everything posted by b0m541
-
hello folks, I am successfully using privoxy in this container. microsocks starts, but when I put it in as SOCKS 4 or 5 in my browser (Port 9118) I get: Unable to connect. When connecting with netcat I can see that the port is open. I tmakes no difference whether I put a socks admin user and password or not. So something breaks in microsocks, but I don't knwo where it puts its logs. Anyone can help with troubleshooting/fixing this?
-
I tried to install resolvconf in the container, but that does not help. Some process keeps /etc/resolv.conf locked/writable, so resolvconf cannot update the content of /etc/resolv.conf. Something with the scripts in this container is definitely broken. Using a fixed DNS server as in --dns 8.8.8.8 is a work-around, and it would be better if the problem got fixed. I may take a look at the scripts this weekend but don't hold your breath.
-
I can see that the VPN server send the VPN provider's DNS server address, but it not being put in /etc/resolv.conf (putting it there would actually be default behaviour of openvpn). How would I enable this container to do that? Using the --dns option wants the /etc/openvpn_up/down scripts that are not coming with the container. However, in /etc/openvpn there is a script that can be called as up and down in vpn.ovpn and it is executed with proper parameters when the tunnel is established /etc/openvpn/update-resolv-conf tun0 1500 1585 vpn-dns-ip 255.255.0.0 init To set the nameserver in /etc/resolv.conf the script relies on /sbin/resolvconf, and this binary is unfortunately not coming in the container. This explains why using the DNS of the VPN provider does not work. Would you be willing to update your image accordingly to fix this problem?
-
in /etc/resolv.conf I can see my name server, that would constitute a DNS leak. it is not working anyway, as the routes are not yet set for a local network. I do not wish to use m own dns when the tunnel is established. it should use the VPN provider's DNS. how?
-
nope, he always packages an app with vpn, thats not what I need. routing through the container network is the right approach. There is one other container OpenVPN-AIO-Client-Torless by testdasi. Still trying this one and not getting dns to work. Using IPs for the vpn endpoint I get a tunnel, but DNS doesn't work. How to I make it use the VPN's DNS server?
-
good look without dns
-
will try this, but the idea of using a dns name there is that there are actually several IPs for the tunnel endpoint
-
no, cannot work for me, see above. my firewall enforces that in my network only my nameservers are used.
-
Thank you for the quick response. I did install from scratch. That did not work out of the box, so I created the variables I previously used. I will create the ports when the container actually works and created a connection. I installed now again from scratch and it complains that it cannot resolve the vpn endpoint dns name. Let me see, this is why I removed the --dns, because that server is -of course- blocked by my firewall, as every other external dns server. From a security perspective one wants to use the local ns while openvpn establishes the tunnel, and afterwards the ns of the tunnel provider. is that possible with this container? When I use my own local ns with --dns the container does establish the tunnel but dns resolution does not work. troubleshooting is hampered by crucial tools not being installed in openvpn-client (eg nslookup, ping, tcpdump). So I used a second container that is connected via the openvpn-client network. its actually difficult to do anything when dns is not working..
-
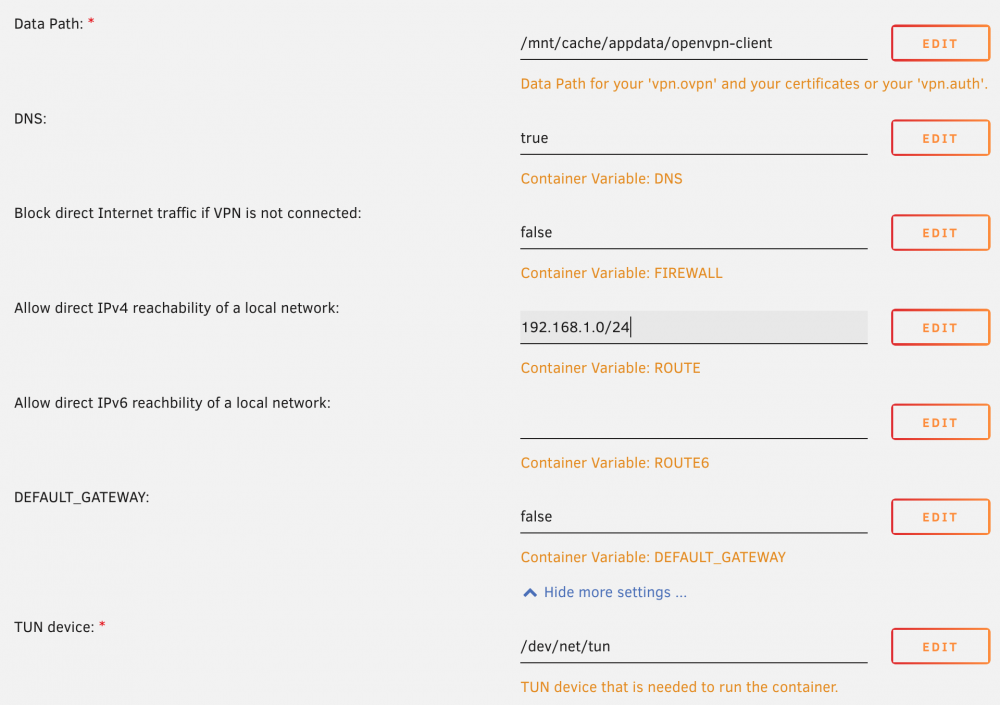
I switched from the russian OpenVPN-client container to ich777's OpenVPN-client and I get errors. I have /vnpn/vpnp.ovpn and /vpn/vpn.auth. Extra Parameters: --cap-add=NET_ADMIN --sysctl net.ipv6.conf.all.disable_ipv6=0 --log-opt max-size=50M I use the following variables: I get the following output: ---Checking for optional scripts--- ---No optional script found, continuing--- ---Taking ownership of data...--- ---Starting...--- The use of ROUTE or -r may no longer be needed, try it without! The use of ROUTE or -r may no longer be needed, try it without! The use of ROUTE or -r may no longer be needed, try it without! The use of ROUTE or -r may no longer be needed, try it without! The use of ROUTE or -r may no longer be needed, try it without! The use of ROUTE6 or -R may no longer be needed, try it without!! The use of ROUTE or -r may no longer be needed, try it without! Error: ipv4: FIB table does not exist. Dump terminated + exec sg vpn -c 'openvpn --cd /vpn --config /vpn/vpn.ovpn --script-security 2 --up /etc/openvpn/up.sh --down /etc/openvpn/down.sh --auth-user-pass /vpn/vpn.auth ' Options error: --up script fails with '/etc/openvpn/up.sh': No such file or directory (errno=2) Options error: Please correct this error. Use --help for more information. What is wrong?
-
The machine has 8 cores and was not Running full tilt in the situations when the sound was chopchopchop. So that explains why CPU shares did not help. The bad sound did not have anything to do with drives spining up. To be honest I have no idea what the root cause is. It does not sound like somethign is running out of buffers, then the music would just bause for a short time and then resume. The stream sounds like a helicopter is chopping it up with its blades, don't know how to better describe this. Maybe this is not related to performance? Still I am left wondering why assigning an isolated core to Mopidy makes it basically unusable? Any ideas about that?
-
I am experiencing chopped-up replay with Mopidy3 sometimes. Sometimes restarting the Mopidy3 container helps, sometimes it does not help to get clear playback. (Restarting Snapcast does not help.) The first thing I tried was to increase the --cpu-shares to 10240 for the Mopidy3 container and the Snapcast container. That did not help, so I rolled this change back. Next, I though, lets set 1 CPU aside for real-time applications, such as media servers (Mopidy, Snapcast, Plex, Owntone). So I isolated one CPU and pinned the media servers to this CPU. This actually led to bigger problems with Mopidy3, as the WebUI became unusable. Anything you do that actually influences the playing stream would not be executed, or much much later. What am I missing here? Why did my move not improve the performance of Mopidy3? Does it need to use several CPUs? What else can I try to improve the real-time performace of the media server containers? (So far never had Problems with Plex and Owntone, though.)
-
Hi there, I am running unRAID for quite some years, currently with 2 parity drives, 8 data drives (XFS), and 2 SSDs (each 500GB Samsung Evo 860). The Evo 860 SSDs run software RAID with BTRF and are used for the array write cache, appdata, VMs und docker. Recently I bought a Samsung Pro 980 1TB NVME without having a concrete plan for what I would use it in unRAID. What are you guys using an extra fast drive for, what are great use cases? - just use the NVME as a second cache drive? Is that actually possible that unRAID uses both, the BTRFS RAID of the Evo 860s and the Pro 980 with XFS for aching array writes? - should I separate the array cache from the system stuff (appdata, VMs, docker)? Which to put where? Do I want the software RAID for the array cache or for the system stuff? My imagination for what else to do with it in the unraid machine is currently limited, feel free to chime in!
-
I switched to the Mopidy container (Mopidy v2). I tweaked to config so that Mopidy starts without error messages. I ran Mopidy local scan. In musicbox_webclient >Browse > Local media > Albums I can browse all local albums. In Iris > Browse > Local files > Albums I can also browse all albums. The problem: In Iris > Albums I have a notification "Loading X local albums" and nothing happens (I waited several hours). What's wrong there?
-
This is an excellent contribution, it helped me a lot. What a pity that the suggestions have not been implemented for the mopidy and mopidy3 template, so everyone has to go through the same valley of tears here.
-
The mopidy.config generated by Mopidy-3 does not contain [iris]. Does that mean that the Iris UI is missing in this container? Should we use the very old Mopidy container? Will there be an update to recent versions of Mopidy and Snapcast at some near point in time? I do not wish the library data to go into /var/lib/mopidy as this will size up the container image. I think it is better to put this in /config/data which is mapped to /mnt/user/appdata/mopidy/data. However, after setting data_dir = /config/data it seems that the db is not really properly rebuilt. The image comes with a pre-populated db for files that I do not have (WTF!). Does it not initialize and fill a new db if it does not find a db file?? This may be a bit too experimental (Do you really want everybody to know that you are German speaking and what you taste of music is?)
-
I would like to use Mopidy-3 with Snapcast. I set up both containers. Before I start configuring Mopidy properly I need Snapcast to run fine. The Snapcast container complains in the logs: [Notice] Settings file: "/root/.config/snapserver/server.json" [Err] Error reading config: [json.exception.parse_error.101] parse error at 1: syntax error - unexpected end of input; expected '[', '{', or a literal [Err] Failed to create client: Daemon not running[Info] PcmStream sampleFormat: 48000:16:2 [Info] metadata={ [Info] "STREAM": "Example" [Info] } [Info] onMetaChanged (Example) [Info] PipeStream mode: create [Info] Stream: {"fragment":"","host":"","path":"/data/snapfifo","query":{"buffer_ms":"20","codec":"flac","name":"Example","sampleformat":"48000:16:2"},"raw":"pipe:////data/snapfifo?buffer_ms=20&codec=flac&name=Example&sampleformat=48000:16:2","scheme":"pipe"} [Err] (PipeStream) Exception: end of file Also a question, the container does not map the ports 1704, 1705 and 1708. Is that right? Is the web UI provided on 1708? I can't see nothing on any port, probably because the daemon isnt running?
-
-
Today I had this problem when Bacula was automatically started again after the daily tasks (incl. Mover): 2022-04-30 05:00:03,712 WARN received SIGTERM indicating exit request 2022-04-30 05:00:03,724 INFO waiting for baculum to die 2022-04-30 05:00:03,725 INFO stopped: baculum (terminated by SIGTERM) ==> Checking DB... ==> Starting... ==> .......Storage Daemon... Starting Bacula Storage Daemon: bacula-sd ==> .......File Daemon... Starting Bacula File Daemon: bacula-fd ==> .......Bacula Director... Starting Bacula Director: bacula-dir ==> .......Bacula Web... 2022-04-30 07:07:46,348 INFO Set uid to user 0 succeeded 2022-04-30 07:07:46,383 INFO supervisord started with pid 1 2022-04-30 07:07:47,394 INFO spawned: 'baculum' with pid 149 2022-04-30 07:07:48,113 INFO exited: baculum (exit status 0; not expected) 2022-04-30 07:07:49,122 INFO spawned: 'baculum' with pid 152 2022-04-30 07:07:49,740 INFO exited: baculum (exit status 0; not expected) 2022-04-30 07:07:51,773 INFO spawned: 'baculum' with pid 155 2022-04-30 07:07:52,777 INFO success: baculum entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2022-04-30 07:07:53,132 INFO exited: baculum (exit status 0; expected) 2022-04-30 07:07:53,137 INFO spawned: 'baculum' with pid 158 2022-04-30 07:07:53,636 INFO exited: baculum (exit status 0; not expected) 2022-04-30 07:07:54,650 INFO spawned: 'baculum' with pid 161 2022-04-30 07:07:55,632 INFO exited: baculum (exit status 0; not expected) 2022-04-30 07:07:57,641 INFO spawned: 'baculum' with pid 164 2022-04-30 07:07:57,981 INFO exited: baculum (exit status 0; not expected) 2022-04-30 07:08:00,995 INFO spawned: 'baculum' with pid 167 2022-04-30 07:08:02,016 INFO success: baculum entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2022-04-30 07:08:02,291 INFO exited: baculum (exit status 0; expected) 2022-04-30 07:08:03,299 INFO spawned: 'baculum' with pid 170 2022-04-30 07:08:03,990 INFO exited: baculum (exit status 0; not expected) 2022-04-30 07:08:05,004 INFO spawned: 'baculum' with pid 173 2022-04-30 07:08:05,733 INFO exited: baculum (exit status 0; not expected) 2022-04-30 07:08:07,740 INFO spawned: 'baculum' with pid 176 2022-04-30 07:08:08,374 INFO exited: baculum (exit status 0; not expected) 2022-04-30 07:08:11,384 INFO spawned: 'baculum' with pid 179 2022-04-30 07:08:11,864 INFO exited: baculum (exit status 0; not expected) 2022-04-30 07:08:12,866 INFO gave up: baculum entered FATAL state, too many start retries too quickly The baculum web UI wouldn't work, but the backup tasks ran fine.
-
The folks on the Shinobi Discord server told me to try dashboard-v3 to solve my problem with recordings (just a copy of input stream) freezing several times for some seconds. Is there a version of this container with dashboard-v3? Or is there a chance it can be in the near future?
-
Looking for a better solution for the following problem: The JobDefs for DefaultJob is buried in really many resources, but it cannot be edited in Baculum. I had to edit JobDefs in the bacula-dir.conf to be able to get rid of the default resources (schedules, jobs, pools, storage) coming with the container. Is there a way to edit JobDefs in Baculum?
-
I get your point. Your aspiration with this is more ambitious than what I actually had in mind: I didn't think that UD is actually analyzing the collected information to pinpoint the actual problem. I was rather interested in the part that is easier to implement and makes it more comfy to people who are able to manually read/interpret and analyze some diagnostic tool output - which would be collected by UD only when the user pressed Unmount and the button was not set to "Mount" by UD. So a one-off situation when UD would collect and present the diag info and definitely not repeatedly or continually. But of course, as I respect and are grateful that you do all the work, mentioning this idea is all this is from my side. No expectations at all.
-
This is just an idea I just had when I wanted to unmount a USB disk and the unmount failed. In such a situation the user can look at the disk log or open a terminal and investigate manually. Some things the user would probably do is if there are any file handles open on the disk. I think it would be beneficial if UD would collect such diagnostic information on its own when an unmount fails (using tools such as lsof) and present it to the user. What do you think about this idea?
-
see the followig article: Solution proposal: One could increase the nfs options text field size limit approriately, or (preferred) allow to have several lines per export to completely remove the limit, i.e. allow for adding and editing several lines.
-
I am trying to export a given NFS share to a number of networks, basically 2 groups of networks, and each group has their own options. Here are the problems I ran into: (A) the text field used by the UI limits the number of characters that it can take. If I have to enumerate the options for each network, the whole thing does not fit into the text field. I see two approaches, but they do not work: (1) group the networks so that the options only need to defined once per network group - this seems only be supported for NIS groups, in the NFS export man page I did not find a way to somehow group networks and then define options per group Example: network1,network2(options1) network3,network4(options2) network5(options3) Note that the grouping by using comma separated networks is not supported by NFS (2) separate options into (a) global options that shall be applied to all networks in the list and (b) per-network options that deviate from the global options. The probleme here is that the unraid GUI already defines global options that you can see in /etc/exports: -async,no_subtree_check,fsid=123 Example: -globaloptions network1(options1) network2(options2) network3(options3) in /etc/exports it will then write: "sharename" -async,no_subtree_check,fsid=100 -globaloptions network1(options1) network2(options2) network3(options3) It seems that NFS will then ignore "-globaloptions" as there are already global options followed by a space character, so that you cannot append your own global options to them. Do you have some ideas how to overcome this limitation while not bypassing the GUI and doing some "hacks". I am looking for a way to express different options for a number of networks in a more compact way that still fits into the line limit of the GUI text field.

