




DaveDoesStuff
Members
-
Joined
-
Last visited
Everything posted by DaveDoesStuff
-
Thank you kind sir! Will check it out asap. I actually did find a backup of the backups...its about 9 months old but better then starting over just in case I can't fix it.
-
Since updating on the 11/07 I've been unable to successfully start this container. Also got an update notification today but still no joy All the recent logs generated on startup since 11/07 are basically the same. Is there any hope for salvaging it? I just check my config backups for the controller and it seems they stopped working and I didn't notice
-
Been back to running all of my dockers (same ones I had running while getting the crashes) for 7 days now and zero crashes or unclean shutdowns. No further system changes from my side, only things that would have changed are docker versions and plugin versions. Must have been something in there causing it. Whatever it was it seems resolved now by itself. Weird.
-
Interesting development, I have a new RAM kit ready to go but decided to turn everything except Plex server and Omada controller off while waiting to install it to see if it helped. Haven't had a crash in close to 48 hours, then this morning I re-enabled Urbackup and watched the container logs as it started. I observed it having issues with being unable to find a BTRFS filesystem OR a ZFS dataset. In my case I have an XFS encrypted array and a ZFS cache...so possible this is causing some issues. Decided to run a manual full image backup and started getting segfaults: Correction, the segfaults occurred before the manual backup started. Whether this is actually to do with the crashes remains to be seen. Right now the backup is still running and unraid appears fine. Also my previous backups do not align with the times of the crashes. I know segfaults like that can sometimes come down to XMP profiles but my RAM is running stock. Again could be dodgy RAM but I would have expected a crash tbh. I'm now wondering in this XFS pool versus ZFS cache setup is causing issues with my dockers (running on cache in folder mode) in general though, I'm considering moving docker.img back to a BTRFS image on the ZFS cache pool as opposed to the current folder setup. Will update the thread with more info as I find it in the hopes it helps someone else.

-
I've been considering that and dreading the Mrs screaming at me that the recipe apps and plex are down while she is in between our 11 month olds naps Decided to order another RAM kit when I saw Amazon could get it to me next day (here in Ireland that is very rare) without breaking my bank account too badly. If that doesn't help then I will fall back on safe mode for a few days. Thanks for taking a look, sometimes it just helps to know I haven't gone totally mad
-
Fresh crash, again nothing in syslog. If I look back at the last 4 crashes they were all 18 hours apart give or take a few minutes, gone through all my scheduled tasks and there is nothing I can see that would go off every 18 hours from boot...weird...but could be a total coincidence. ibstorage-diagnostics-20240312-1436.zip
-
Since approximately last week I've suddenly started getting crashes (reboots ok) with no discernible pattern. Originally I was on 6.12.5 when this issue started. Prior to this I've been going strong for over a year with no issues (that couldn't have been attributed to user error anyway ). After I noticed the issues (I hadn't looked at my alerts history for a while, because it recovered quickly and completely after each crash I can't be sure when it started) I updated to 6.12.8 but the crashes persisted. This morning I removed some old drives I had sitting in unassigned devices that has previously shown SMART errors and updated my motherboard bios to the latest version. No effect. No errors after running memtest overnight (so inconclusive) and RAM is set to default/stock in BIOS (learned this lesson a long time ago). I was watching plex with syslog open beside it for this latest crash and didn't see any warning times. There was nothing array intensive running, only real load was on my iGPU (Ryzen 5700G) doing transcoding in UNMANIC. Nothing else of note bar the usual "aars" etc... Diagnostics from after a graceful shutdown earlier today attached. Diagnostics from after the crash I had a few minutes ago also attached. I have syslogs from before and after the last crash available...but I'm concerned about posting any potentially sensitive data that might be contained in them 😕 In the pre crash log these are the only warnings/errors: Mar 11 12:25:31 iBstorage kernel: Warning: PCIe ACS overrides enabled; This may allow non-IOMMU protected peer-to-peer DMA Mar 11 12:25:31 iBstorage kernel: ACPI: Early table checksum verification disabled Mar 11 12:25:31 iBstorage kernel: floppy0: no floppy controllers found Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 5: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 5: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:25:31 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 12:26:41 iBstorage kernel: BTRFS info (device loop2): using crc32c (crc32c-intel) checksum algorithm Mar 11 12:36:16 iBstorage root: Fix Common Problems: Warning: Syslog mirrored to flash And the immediate entries before the crash don't have anything obvious: Mar 11 12:56:33 iBstorage kernel: Mar 11 12:58:21 iBstorage emhttpd: spinning down /dev/sdg Mar 11 13:19:48 iBstorage emhttpd: spinning down /dev/sdh Mar 11 13:28:26 iBstorage emhttpd: read SMART /dev/sdh Mar 11 13:43:27 iBstorage emhttpd: spinning down /dev/sdh Mar 11 14:12:23 iBstorage emhttpd: read SMART /dev/sdh Mar 11 14:13:01 iBstorage flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Mar 11 14:14:01 iBstorage flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Mar 11 14:27:22 iBstorage emhttpd: spinning down /dev/sdf Mar 11 14:29:34 iBstorage emhttpd: spinning down /dev/sdh Mar 11 14:50:15 iBstorage emhttpd: read SMART /dev/sdh Mar 11 18:00:02 iBstorage root: Starting Mover Mar 11 18:00:02 iBstorage root: Forcing turbo write on Mar 11 18:00:02 iBstorage root: ionice -c 2 -n 7 nice -n 0 /usr/local/emhttp/plugins/ca.mover.tuning/age_mover start 0 0 0 '' '' '' '' '' 65 '' '' 50 Mar 11 18:00:02 iBstorage kernel: mdcmd (38): set md_write_method 1 Mar 11 18:00:02 iBstorage kernel: Mar 11 18:00:02 iBstorage root: Restoring original turbo write mode Mar 11 18:00:02 iBstorage kernel: mdcmd (39): set md_write_method 1 Mar 11 18:00:02 iBstorage kernel: Mar 11 18:04:25 iBstorage emhttpd: read SMART /dev/sdc Mar 11 18:04:56 iBstorage emhttpd: read SMART /dev/sdf Mar 11 18:11:10 iBstorage emhttpd: read SMART /dev/sdg Mar 11 18:11:10 iBstorage emhttpd: read SMART /dev/sdi Mar 11 18:11:35 iBstorage kernel: mdcmd (40): set md_write_method 1 Mar 11 18:11:35 iBstorage kernel: Mar 11 18:27:11 iBstorage emhttpd: spinning down /dev/sdi Mar 11 18:27:58 iBstorage emhttpd: spinning down /dev/sdg Mar 11 18:28:05 iBstorage emhttpd: spinning down /dev/sdf Mar 11 18:31:35 iBstorage kernel: mdcmd (41): set md_write_method 0 Mar 11 18:31:35 iBstorage kernel: Mar 11 18:33:38 iBstorage emhttpd: spinning down /dev/sdc Mar 11 19:16:25 iBstorage emhttpd: spinning down /dev/sdh Mar 11 19:33:16 iBstorage emhttpd: read SMART /dev/sdf Mar 11 19:34:07 iBstorage flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Mar 11 19:39:28 iBstorage flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Mar 11 19:42:28 iBstorage flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Mar 11 19:59:18 iBstorage emhttpd: spinning down /dev/sdf Mar 11 20:03:34 iBstorage emhttpd: read SMART /dev/sdf Mar 11 20:04:28 iBstorage flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Mar 11 20:20:27 iBstorage emhttpd: spinning down /dev/sdf In the post crash log these are the only warnings/errors: Mar 11 20:23:54 iBstorage kernel: Warning: PCIe ACS overrides enabled; This may allow non-IOMMU protected peer-to-peer DMA Mar 11 20:23:54 iBstorage kernel: ACPI: Early table checksum verification disabled Mar 11 20:23:54 iBstorage kernel: floppy0: no floppy controllers found Mar 11 20:23:54 iBstorage rsyslogd: omfwd/udp: socket 5: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd: socket 5: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:23:54 iBstorage rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Mar 11 20:24:52 iBstorage root: Error response from daemon: network with name br0 already exists Mar 11 20:24:53 iBstorage kernel: BTRFS info (device loop2): using crc32c (crc32c-intel) checksum algorithm Mar 11 20:34:15 iBstorage root: Fix Common Problems: Warning: Syslog mirrored to flash I can't pinpoint anything useful in the above...but after staring at logs for so many hours this week I might just be blind to it. Hoping a fresh set of eyes might help. Any feedback/help/insight would be very welcome. postcrash-diagnostics-20240311-2029.zip precrash-diagnostics-20240311-1109.zip
-
There she goes, there she goes again... Like clockwork almost exactly 15 days each time. Price of drives has shot up here too ibstorage-diagnostics-20230221-2004.zip
-
New diags attached. The parity2 drive has been moved to a SATA power cable on which it is the only drive, no splitters, straight to the PSU. Rebuild in progress. If it goes again I'll try getting a replacement disk, if that also fails then I'm considering getting an LSI SAS 9207-8i and new motherboard (to allow me to use it)...I think at that point all other options would be exhausted and it would have to be a bum onboard SATA. ibstorage-diagnostics-20230207-2308.zip
-
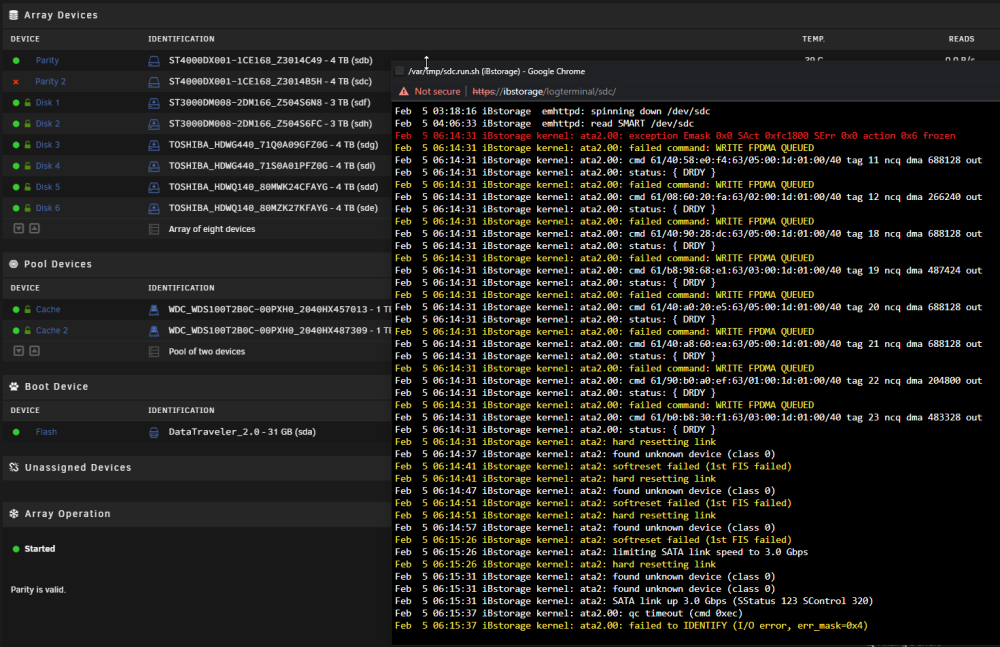
@trurlhappened again unfortunately: I'll try switching the SATA power cables around to see if a different drive goes offline. In the meantime I'll try and find some affordable drives to replace that one (at least as a test). ibstorage-diagnostics-20230205-1134.zip
-
Any update on this? 😅
-
After a power cycle without touching the hardware the drive was detected by the BIOS. But I went ahead and replaced the SATA cable anyway. Did the usual unassign drive, start in maintenance, array off, reassign and start rebuild. Which is currently still underway. All SATA cables are "loose" in that they have plenty of slack either end and are not bound to each other. Same for SATA power. Fingers crossed the cable replacement does it. Diagnostics attached. ibstorage-diagnostics-20230119-1916.zip
-
@trurl This has happened again unfortunately, diagnostics attached. No warning of SMART failures or any other issues...then suddenly bam, disk is disabled. Unfortunately I don't have a spare 4tb and a new one is over €150 with shipping to Ireland at the moment. Not ideal Not in a position to restart and rebuild at the moment to see if it resolves. EDIT: Forgot to mention that since the resolution I've had 2 full system lockups/crashes. Was unable to login to web/gui/cmd as all were completely dead. I've since started logging to a syslog location. Haven't had that happen again since tho so still no RCA. ibstorage-diagnostics-20230115-1727.zip
-
Appreciate the help! Just done this. Clean shutdown, power off. Everything is where it should be, case hasn't been opened since February and is in a heavy startech rack under our stairs. Literally no possible way anything can be disturbed. I unplugged everything connected to the problem drive and re-seated it all. No physical signs of issues with the drive, all ports look clean and straight/no damage. Also no signs of surge damage...etc... Array started up no problem, but the drive is still "disabled". Diags attached. EDIT: Noticed the disk reporting temperature so figured it was at last connected. Took the array offline and was able to run a short smart test and it passed with no errors. EDIT 2: I shutdown and rebooted again as the GUI became unresponsive. After bolting back up I followed the wiki instructions on re-adding a disabled disk and was able to start a parity sync with no issues. However now one of my two intel nic interfaces can no longer be found by my pfSense VM. I've been trying to troubleshoot and noticed that the link lights for one of the ports (it's a dual nic card) is no longer lighting. I was able to resolve this by pausing the rebuild and doing a full power cycle again. Then when I started the array and resumes the sync, the link lights were working again and the VM recognised the second nic. Very strange behaviour though... Parity sync is in progress, ETA 8 hours. Will only run pfSense until then which should be safe for the sync since it only runs off the nvme cache pool. FINAL UPDATE: The sync completed, no issues since...I'm not super comfortable not knowing the cause of the original issue but will still mark this as resolved. ibstorage-diagnostics-20221206-1759.zip
-
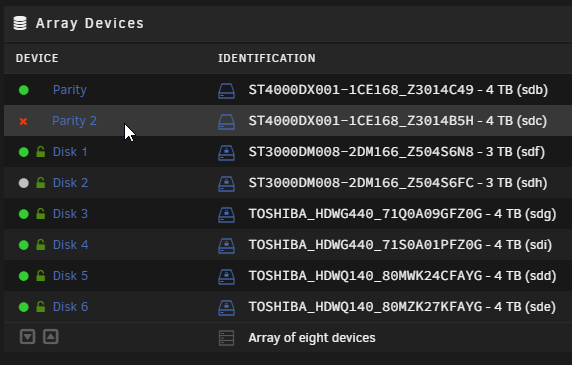
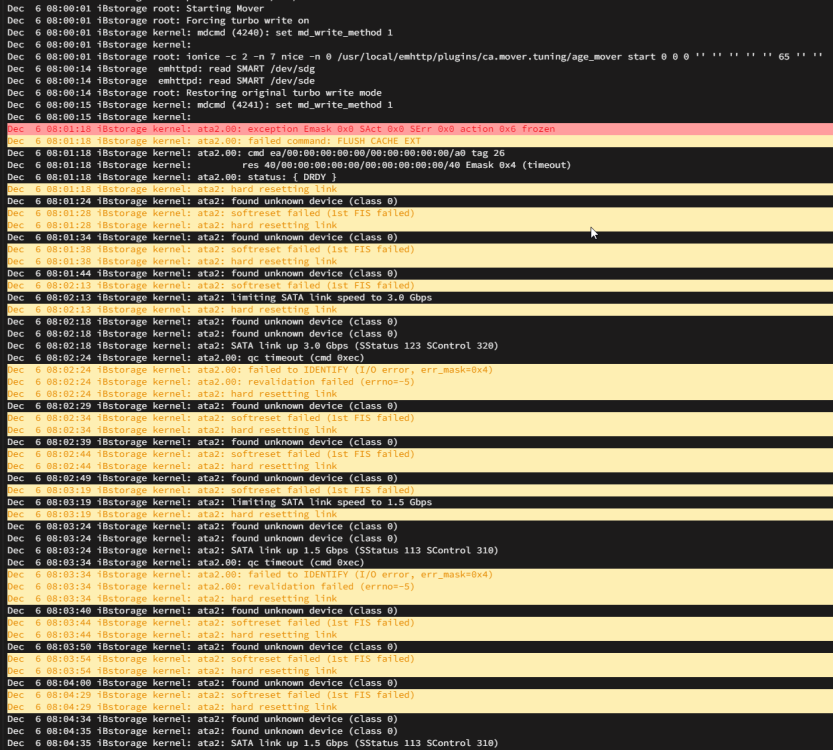
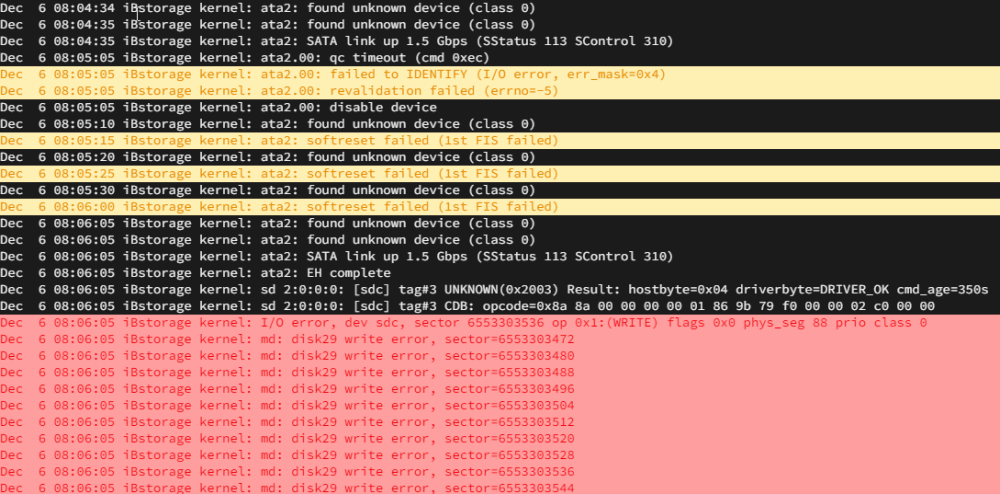
Hi all, This morning one of my 2 parity drives was disabled after several errors in the syslog as you can see below: It appears this happened shortly after the mover was triggered: Ultimately after warning for a bit it goes into full on write errors (1024 or so total before it disables the disk): Syslog is also being spammed with this, even after the drive was disabled: Server has been running for over 2 months since my upgrade to 6.11.0 without any issues bar the occasional plugin becoming depreciated and needing replacing. The only hint I had of something going bad was lastnight at approx 22:30 - 00:00 when I was having issues playing LoL/Watching Twitch and doing some torrenting. This is possibly relevant as I'm running pfSense inside a VM as my primary router, which is running straight off my cache (2x NVME). I've essentially concluded that the parity drive has gone bad and some of these symptoms are just a result/knock on effect of that...however the networking blip mentioned above (which again all runs off the cache, which is ONLY on my 2x 1TB NVMEs, and should have no presence on the array) has me slightly concerned I could be facing a more widespread issue. That being said neither cache device has any SMART errors or any other indicators of failure I can find (same goes for my other disks bar that disabled parity), so possibly I'm worrying over nothing. In any case before I go ordering overpriced replacement parity drives I figured getting some valued community opinions couldn't hurt Diagnostics attached. ibstorage-diagnostics-20221206-1256.zip

-
Thanks Jorge, I could be wrong with my sleep deprived memory but I think that was before I destroyed the pool...again I could be wrong though. No idea how that RAM is running at that speed. It SHOULD be set to 2133...had some blackouts here a while ago so possibly the bios settings default without me realising. I'll get that sorted this evening. Thank you for pointing it out!
-
Thank you for the reply. It is a 2xNVME pool...ended up doing this after a massive cache failure a year ago. I may re-examine it if this happens again. I switched from a docker img aronud the time 6.9.0 came out because I was getting excessive writes to the cache pool and it did indeed fix it. Some folders ended up on the array during lastnight/this mornings attempt to rescue shares from the cache pool (moved moved system to the array, well it moved 75% of it the rest was corrupted so badly it would put the pool in read mode when I tried to move them). I'm not actually going back to an image, I only wanted to try it to see if it was any different. I also had totaly nuked the docker directory before posting both via the gui and a good old rm -rf when the gui failed to do it. SOLUTION: On the plus side I have actually resolved this with the single worst tool everyone has in their toolbox. A system restart (the first one since formating the pool and nuking the docker directories). I have now been able to re-create the docker directory and get my apps back. Thanks for the help anyway. I will mark the subject as solved.
-
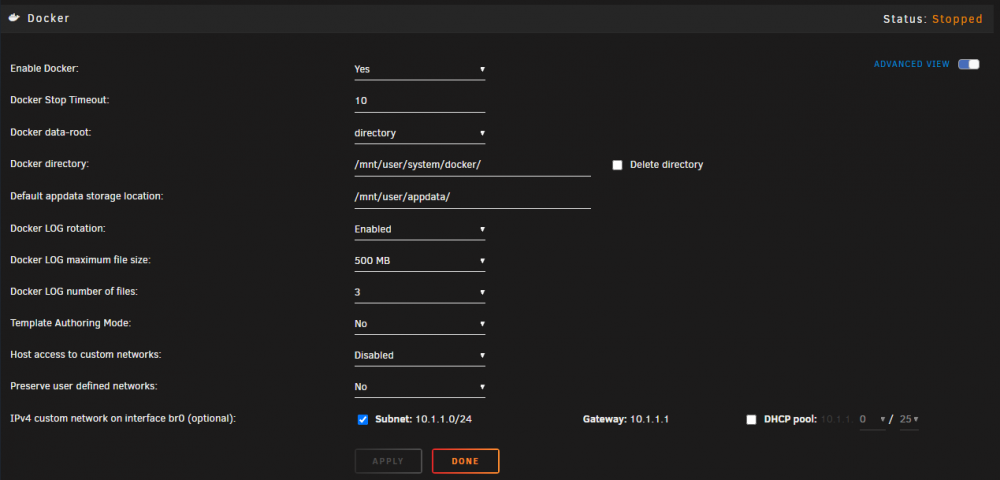
Hi all, Up all night with this one, any help would be appreciated. Basically I had a corrupted btrfs filesystem on my 2xNVME cache pool that revealed itself in the form of read only pool mode last night. Wrestled with that until 3am and decided to just say F it and format the pool (after getting as much as possible off). I also has an ASM1061 controller issue that was unaware of and I solved. But all things considered this appears to have been unrelated. Got the pool formatted and everything moved back onto the cache (system/appdata/domains) and have been able to get my VMs back up. However docker was having none of it, I was using it in "directory mode" and I knew not all files made it off the cache so I decided to delete the directory via the GUI and rebuild (Settings > Docker > Directory field > Delete checkbox) however upon attemping to start docker (I've tried directory mode and btrfs image mode) it just errors out as per the below...no combination of options (even if I manually delete the directory via terminal) fix it. Docker settings page: Directory mode error: Mar 5 10:28:02 iBstorage emhttpd: shcmd (63791): /usr/local/sbin/mount_image '/mnt/user/system/docker/' /var/lib/docker 20 Mar 5 10:28:02 iBstorage root: mount: /var/lib/docker: mount(2) system call failed: No such file or directory. Mar 5 10:28:02 iBstorage emhttpd: shcmd (63791): exit status: 32 BRTFS image error: Mar 5 10:31:22 iBstorage root: Checksum: crc32c Mar 5 10:31:22 iBstorage root: Number of devices: 1 Mar 5 10:31:22 iBstorage root: Devices: Mar 5 10:31:22 iBstorage root: ID SIZE PATH Mar 5 10:31:22 iBstorage root: 1 20.00GiB /mnt/cache/system/docker/docker.img Mar 5 10:31:22 iBstorage root: Mar 5 10:31:22 iBstorage kernel: BTRFS: device fsid dd9a73e4-509f-43d1-8455-685e0eb24740 devid 1 transid 5 /dev/loop3 scanned by udevd (9404) Mar 5 10:31:22 iBstorage kernel: BTRFS info (device loop3): enabling free space tree Mar 5 10:31:22 iBstorage kernel: BTRFS info (device loop3): using free space tree Mar 5 10:31:22 iBstorage kernel: BTRFS info (device loop3): has skinny extents Mar 5 10:31:22 iBstorage kernel: BTRFS info (device loop3): flagging fs with big metadata feature Mar 5 10:31:22 iBstorage kernel: BTRFS info (device loop3): enabling ssd optimizations Mar 5 10:31:22 iBstorage kernel: BTRFS info (device loop3): creating free space tree Mar 5 10:31:22 iBstorage kernel: BTRFS info (device loop3): setting compat-ro feature flag for FREE_SPACE_TREE (0x1) Mar 5 10:31:22 iBstorage kernel: BTRFS info (device loop3): setting compat-ro feature flag for FREE_SPACE_TREE_VALID (0x2) Mar 5 10:31:22 iBstorage kernel: BTRFS info (device loop3): checking UUID tree Mar 5 10:31:22 iBstorage root: mount: /var/lib/docker: mount(2) system call failed: No such file or directory. Mar 5 10:31:22 iBstorage root: mount error The docker page itself displays this error after it fails to start: Warning: stream_socket_client(): unable to connect to unix:///var/run/docker.sock (No such file or directory) in /usr/local/emhttp/plugins/dynamix.docker.manager/include/DockerClient.php on line 682 Couldn't create socket: [2] No such file or directory Warning: Invalid argument supplied for foreach() in /usr/local/emhttp/plugins/dynamix.docker.manager/include/DockerClient.php on line 866 And the dashboard page has this chap at the bottom, all clearly the same thing being screamed at me: Warning: stream_socket_client(): unable to connect to unix:///var/run/docker.sock (No such file or directory) in /usr/local/emhttp/plugins/dynamix.docker.manager/include/DockerClient.php on line 682 Couldn't create socket: [2] No such file or directory Diagnostics attached. I'd really appreciate any help possible on this...have had basically no sleep so I wouldn't be surprised if I'm doing something stupid. ibstorage-diagnostics-20220305-1046.zip
-
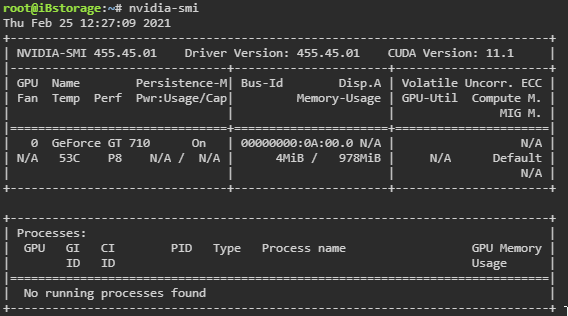
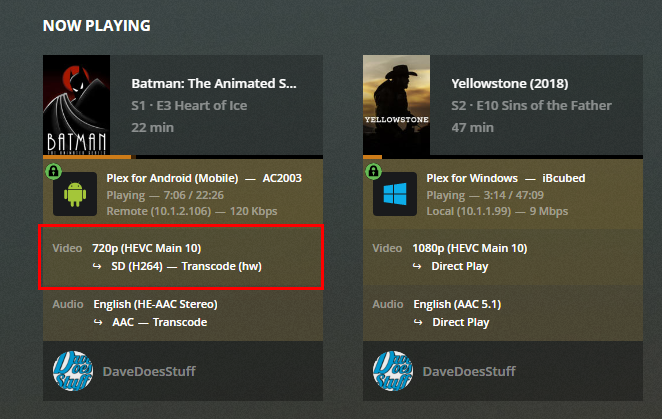
That's actually a really cool website, bookmarked. It never occured to me that the media, coupled with lack of 265 support was the problem...but it does make total sense thanks for the steer. I'll try a different format and lower the quality and report back! EDIT: So the HW transcoding kicks in when playing this second show and transcoding to h.264...but it seems to be using CPU not GPU...or am I misreading this? Hmm, does the source also have to be h.264 or could a GT710 transcode HVEC Main 10 to h.264 at all? I clearly need to improve my knowledge in this area
-
Firstly, great plugin/work! Unfortunately I'm having some issues getting plex transcoding to work on my GT710. The very first time I installed the plugin and set everything up it worked fine until my next system restart. Since then every combo of troubleshooting steps I've tried failed to get it to ever work again. I'm running binhex-plexpass with a lifetime plex pass. Rest of the info is in the screenshots, I've tried to include any/everything I've seen in the other posts in this thread that seems to be of help. Sorry if I've overdone it It should be noted I have no errors in the systemlog or the container log for plex. None whatsoever. EDIT: For clarity I'm doing the PCI override because I have a dual intel nic for a dedicated pfSense VM, so it's not really optional.

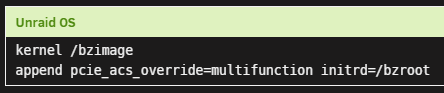
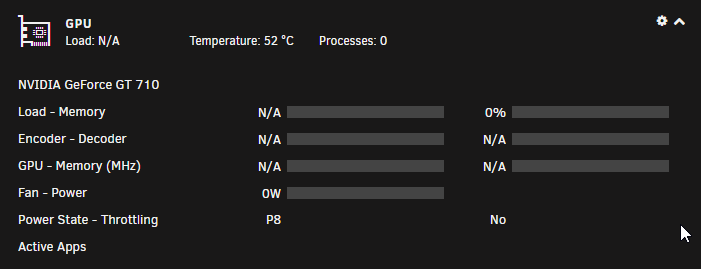
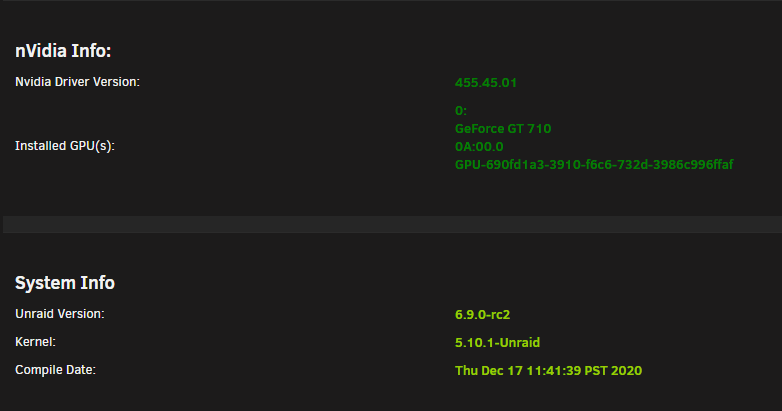
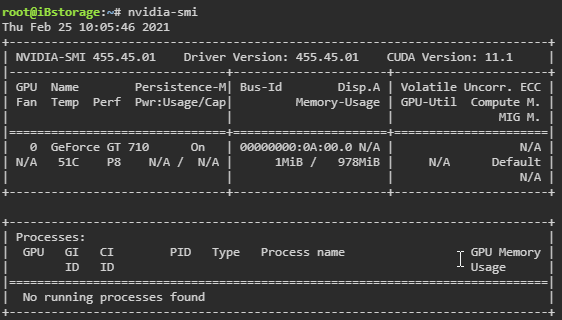

-
Hi team, Upgraded to 6.9.0-rc2 last night after I was forced to look into some issues with a parity drive (unrelated) and decided I was sick of the warnings about the mover tuning plugin being incompatible with stable branch (I'm easily annoyed). I rely on booting unRaid in GUI mode since I run a pfSense VM and 2 dedicated NICs as my home router via unRaid...and obviously this means if the array is down there is no webUI...hence my need for a working GUI mode on boot. After upgrading however all I get after going through the boot sequence is a black screen with a blinking cursor in the top left instead of the GUI. I've tried various ways of troubleshooting this myself such as: Enabling CSM Enabling CSM but allowing UEFI only/first Disabling CSM and forcing UEFI only Reseating my GT 710 BIOS defaults and re doing my settings one at a time GUI safe mode (issue persists/no change) I can boot in normal OS mode (cli) no problem, I was able to work around my pfSense going down by plugging a laptop directly into the unRaid NIC (pfSense NICs are on a seperate card) on the mobo and accessing the webUI but this isn't a practical/long term solution. Interesting to note that while the "system profiler" tool does not seem to detected the GT 710 that it appears as an option for GPU if I go into the create VM wizard (currently no VM is using the GT 710 so there shouldn't be anything "claiming it" and it has not been isolated in anyway). ibstorage-diagnostics-20210215-1138.zip
-
Thanks for the analysis and workaround, I appreciate that you provided it even tho its a UD issue.
-
Yep, absolutely fine.
-
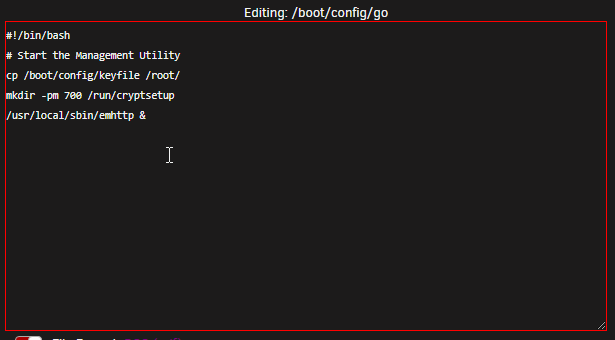
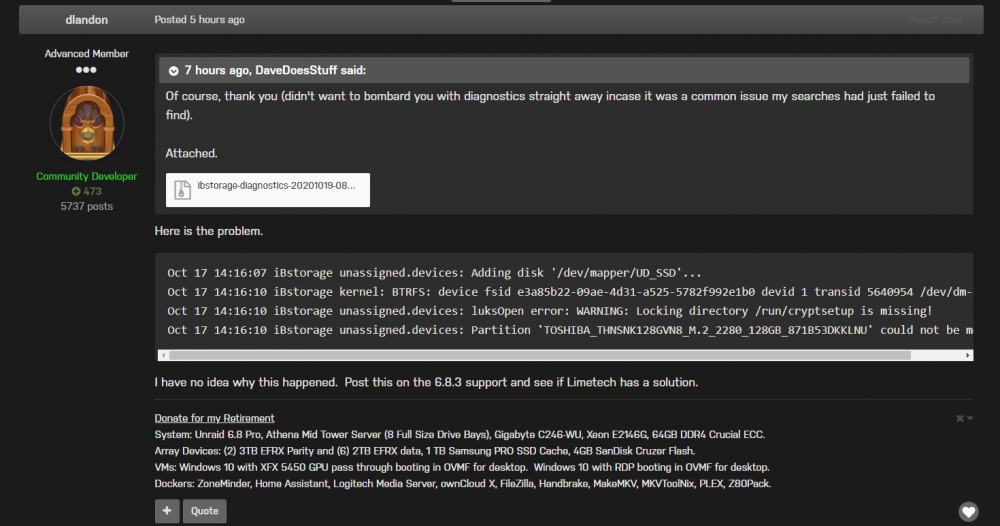
Curious what you make of this @doron, I've been having an issue whereby my UD NVME drive won't auto mount on system startup after a reboot. I posted over in the UD thread and supplied my diagnostics and dlandon suggested the issue below is my problem. Seems a bit coincidental right? What do you think? Possible sidefffect of the sript or unrelated and a 6.8.3 issue? (dlandon didn't know I'd run a script to replace my keys)
-
Of course, thank you (didn't want to bombard you with diagnostics straight away incase it was a common issue my searches had just failed to find). Attached. ibstorage-diagnostics-20201019-0854.zip
















