




robobub
Members
-
Joined
-
Last visited
Everything posted by robobub
-
Thanks for your help, I will definitely try that out when I get home. I was hoping to leave the AC off during the day and only boot up the server at night for backups on my trip, but this unclean shutdown definitely makes it difficult. Here's ps aux/top/pstree/lsof/zpool status outputs. $ zpool list no pools available ps_aux.txt pstree.txt top.txt lsof2.txt
-
But as with the /mnt/user error, /mnt/cache_zfs is already unmounted, as you can see from the outputs from findmnt ,lsof /mnt/cache*, and find /mnt/. zpool status shows no pools are available anymore. Docker and VM services were successfully shut down at this point of array stopping, and nothing was showing up in htop/top, but I did try disabling them and starting/stopping the array and the same issue occurs. I just left for a weekend trip so I'll be holding off on trying safe mode. Though in theory I could try it with Wireguard/Tailscale being part of the core unRAID and you can change the default grub boot option. I'm sure it's some weird plugin/configuration, but I mean everything except tmpfs is unmounted, and I can halt with no data loss, it's just for some reason unRAID won't shut down and marks it as an unclean shutdown. htop/top/ps doesn't show anything obvious in terms of plugins or processes (is that output in diagnostics?).
-
UPDATE: in this version change inotifywait becomes a crucial part of the shutdown process. Previously I had some rare issues with that process preventing shutdown from a different plugin and had it killed on a shutdown script, which caused the shutdown process to stop and never recover. I recently upgraded to 6.12.15 from 6.12.10 to try to fix some zfs issues (migrating from my own zfs management to unRAID's) and now it refuses to stop the array causing unclean shutdown/reboots. I had run into this message plenty of times before in the past due to other issues, but to my surprise, all the disks and zfs are actually already unmounted. From the timestamps it looks like from stop array request to unmounting the last disk is around 2 minutes. Then unRAID just sits there with this message in the GUI. Attached diagnostics and some of my own attempts and investigating. How can I figure out why it is unhappy? EDIT: ps/top/lsof outputs here $ findmnt TARGET SOURCE FSTYPE OPTIONS / rootfs rootfs rw,size=16391148k,nr_inodes=4097787,inode64 ├─/proc proc proc rw,relatime ├─/sys sysfs sysfs rw,relatime │ ├─/sys/fs/fuse/connections fusectl fusectl rw,relatime │ └─/sys/fs/cgroup cgroup2 cgroup2 rw,nosuid,nodev,noexec,relatime ├─/run tmpfs tmpfs rw,nosuid,nodev,noexec,relatime,size=131072k,mode=755,inode64 │ └─/run/docker/netns/default nsfs[net:[4026531840]] nsfs rw ├─/boot /dev/sda1 vfat rw,noatime,nodiratime,fmask=0177,dmask=0077,codepage=437,iocharset=iso8859-1,shortname=mixed,flush,errors=remount-ro ├─/lib /dev/loop0 squashfs ro,relatime,errors=continue │ └─/lib overlay overlay rw,relatime,lowerdir=/lib,upperdir=/var/local/overlay/lib,workdir=/var/local/overlay-work/lib ├─/usr /dev/loop1 squashfs ro,relatime,errors=continue │ └─/usr overlay overlay rw,relatime,lowerdir=/usr,upperdir=/var/local/overlay/usr,workdir=/var/local/overlay-work/usr ├─/dev devtmpfs devtmpfs rw,relatime,size=8192k,nr_inodes=4097787,mode=755,inode64 │ ├─/dev/pts devpts devpts rw,relatime,gid=5,mode=620,ptmxmode=000 │ └─/dev/shm tmpfs tmpfs rw,relatime,inode64 ├─/hugetlbfs hugetlbfs hugetlbfs rw,relatime,pagesize=2M ├─/var/log tmpfs tmpfs rw,relatime,size=131072k,mode=755,inode64 └─/mnt rootfs[/mnt] rootfs rw,size=16391148k,nr_inodes=4097787,inode64 ├─/mnt/disks tmpfs tmpfs rw,relatime,size=1024k,inode64 ├─/mnt/remotes tmpfs tmpfs rw,relatime,size=1024k,inode64 ├─/mnt/addons tmpfs tmpfs rw,relatime,size=1024k,inode64 └─/mnt/rootshare tmpfs tmpfs rw,relatime,size=1024k,inode64 $ tail /var/log/syslog Jul 10 13:04:09 t1001 root: cannot unmount '/mnt/cache_zfs': pool or dataset is busy Jul 10 13:04:25 t1001 emhttpd: shcmd (160): umount /mnt/user Jul 10 13:04:25 t1001 root: umount: /mnt/user: target is busy. Jul 10 13:04:25 t1001 emhttpd: shcmd (160): exit status: 32 Jul 10 13:04:25 t1001 emhttpd: shcmd (161): rmdir /mnt/user Jul 10 13:04:25 t1001 root: rmdir: failed to remove '/mnt/user': Device or resource busy Jul 10 13:04:25 t1001 emhttpd: shcmd (161): exit status: 1 Jul 10 13:04:25 t1001 emhttpd: shcmd (163): rm -f /boot/config/plugins/dynamix/mover.cron Jul 10 13:04:25 t1001 emhttpd: shcmd (164): /usr/local/sbin/update_cron Jul 10 13:04:25 t1001 emhttpd: Retry unmounting user share(s)... Jul 10 13:04:27 t1001 kernel: script (5153): drop_caches: 3 $ ## the error messages above actually successfully completed at some later time, see dmesg tail below $ umount /mnt/user umount: /mnt/user: no mount point specified. $ rmdir /mnt/user rmdir: failed to remove '/mnt/user': No such file or directory $ zpool list no pools available $ date Thu Jul 10 13:25:23 EDT 2025 $ dmesg -T | tail [Thu Jul 10 13:04:02 2025] veth8f0ab61: renamed from eth0 [Thu Jul 10 13:04:02 2025] br-e769d98838f0: port 1(veth4e25d88) entered disabled state [Thu Jul 10 13:04:02 2025] device veth4e25d88 left promiscuous mode [Thu Jul 10 13:04:02 2025] br-e769d98838f0: port 1(veth4e25d88) entered disabled state [Thu Jul 10 13:04:27 2025] script (5153): drop_caches: 3 [Thu Jul 10 13:04:40 2025] BTRFS info (device dm-0): last unmount of filesystem 3b2ddebb-0f7c-470e-b80b-746480624f45 [Thu Jul 10 13:04:40 2025] BTRFS info (device dm-1): last unmount of filesystem 781ec874-cba1-4e0b-9de6-6724ea81035c [Thu Jul 10 13:04:41 2025] BTRFS info (device dm-2): last unmount of filesystem ab612068-00dd-4727-9c67-44b97ca3b95a [Thu Jul 10 13:04:41 2025] BTRFS info (device dm-3): last unmount of filesystem 71712954-1765-4aa6-84dc-1ee9efeb66e8 [Thu Jul 10 13:04:42 2025] XFS (dm-4): Unmounting Filesystem $ lsof /mnt/user* /mnt/disk* /mnt/cache* lsof: status error on /mnt/user*: No such file or directory $ lsof /mnt/disk* /mnt/cache* $ find /mnt/ /mnt/ /mnt/cache_zfs /mnt/rootshare /mnt/addons /mnt/remotes /mnt/disks Thought it might be open luks devices, but after this it is still on that message $ dmsetup ls --target crypt md1p1 (254, 0) md2p1 (254, 1) md3p1 (254, 2) md4p1 (254, 3) nvme0n1p1 (254, 4) sdb1 (254, 5) sdc1 (254, 6) sdd1 (254, 7) $ for d in /dev/mapper/*; do [[ "$(basename "$d")" != "control" ]] && cryptsetup luksClose "$(basename "$d")"; done $ dmsetup ls --target crypt No devices foundt1001-diagnostics-20250710-1320.zip
-
Any reason why we just don't keep referring to the obfuscated chattr while running the script? Might as well remove the small chance that ransomware tries to do chattr -i while the script is running? Or what scenario am I missing?
-
I think you just encountered the issue I did with temperature pause/resume. From the comments, it looks like the logic also applies to pause/resume from mover action. I made a pull request here. Making these changes in /usr/local/bin/parity.check seem to be working for my case, though I did not check the second case yet. TESTING logs before the change for context
-
So it turns out the issue I stated earlier (RAM that went bad) was actually something else: a bad SATA cable or PSU after some more googling. Since replacing RAM and verifying on memtest, some writes were submitted that were ignored and the sata link has to be reset and thus actually fits this scenario more precisely than just bad RAM. However, there is indeed a problem by not having the checksumming and parity integrated together, as apandey's intuition suggested, at least when set up for copy-on-write filesystem (which is the default for BTRFS). There is still a solution I used to recover without a full rebuild, but it's advanced. Some more details: While I was able to recover the particular file that had this corruption (which manifested as "Input/Output Error", parity is still out of sync. Why? Not from the recovery process, it was already out of sync. The emulated drive did not have those BTRFS checksum errors when accessing the file, and the array's stats showed 0 in the write column for all drives when recovering (and a bunch of similar reads even though only the emulated device was mounted, which shows emulation was working). But the physical drive did have those BTRFS checksum errors. The problem: updating/deleting the file on a copy-on-write filesystem does not modify the corrupted sectors. As I mentioned earlier, while parity had the correct bits and correctly wrote the file, parity was out of sync because the physical drive had incorrect bits. When updating or deleting the file, BTRFS by default will place the new data in a new sector if it was not created with the chattr attribute to disable COW. That means the physical sectors that were used to hold the data, while now unreferenced by the BTRFS filesystem, still hold data that is out of sync with the parity. So if one needed to restore from those sectors on one of the other hard drives, it will be incorrect. Eventually BTRF will reclaim that space, which could be sped up via balance or defrag, but that's not really acceptable. The solutions is to tell unRAID to parity sync specific sectors. You can do this with dd or other advanced low-level tools after looking up the physical locations associated with the file by inspecting the BTRFS filesystem metadata. But I'll just strongly recommend against it unless you know what you are doing. I was able to get it working with dd, btrfs-progs, and help from #btrfs on irc. Some snippets of the errors. When trying to access a particular file, "Input/Output Error" is received. I did the steps that I outlined and After re-mounting with the disk, a parity check has shown no sync errors so far. Steps (WARNING, you will lose data unless you know what you are doing and how to navigate low level filesystem metadata) stop array (optional) backup /boot/config select "no device" for disk with error start array in maintenance mode mount device with `-o ro,loop,norecovery` Copy file in question to somewhere not on the disk/array. I put it on my `/tmp` ram but /boot or an unassigned device can also work stop array Tools -> New Config, preserve all configurations (some settings like shutdown timeout are reset, can also restore /boot/config) start array with "Parity is valid" write 0's for the sectors with sync errors For btrfs, you have to look up the logical offsets for each extent associated with the file, and zero the those extents for the size of those extents (optional) start a parity check, there should be no corrections, but you can uncheck write corrections to see if you messed something up. There is some irony in performing this step, as it will cause essentially the same wear/workload as rebuilding, at least for HDDs where reading/writing are likely similar in wear
-
I am playing around with a USB enclosure. I knew this enclosure didn't report serial numbers or SMART correctly and in the device page it was no surprise to essentially see an empty list under device attributes. But I can download the report manually under Self-Test and query with smartctl. Then days later, I see some notifications in the WebGUI and emails emails about SMART changes for the fields it's told to monitor: It even updates the GUI to report an error that I need to acknowledge, with a tooltip showing the specific data that changed, but clicking on attributes again still shows the blank table above. So clearly unRAID is actually parsing the SMART data and handling changes, but it just doesn't show up under the table. I tried all the different options under SMART controller type. Also it appears the SN does show up under device -> identity, it's just not reportedly normally I suppose. The model is ORICO 4 Bay Hard Drive Enclosure WS400U3 B0813KKWFJ B08D994JVT with a Jmicron JMB394 and JMS567 I actually spent a bit of time writing scripts that would query the smart data with smartctl, recording diffs, ignoring fields like Power Cycle Count, but seems that wasn't really necessary.
-
To expand on this, pointing directly to /mnt/cache instead of /mnt/user, it will skip the unraid shfs layer which incurs some CPU cost. It depends on the access pattern, but my theory is it is a fixed cost per request, e.g. many small requests, perhaps certain database queries, incur greater cost. One advanced way you can try to get a handle on this is checking for a lot of cpu usage of the shfs from the dockers accessing cache. You can check the cpu usage using `htop` or the glances docker app and look for shfs. All normal array access is through here though, so lots of access to the array (instead of cache) can result in high shfs usage. To see what is being requested through the shfs layer, you can run `lsof -c shfs` and see if the usage is more cache or array.
-
Well certainly sounds like a bug as this is not what occurs for multiple small files selected (as opposed to a folder) I've attached a log file of this scenario, let me know if you need any more information for this scenario or if I am doing something incorrectly Thanks! unbalance.log
-
At this point it's clear you aren't reading what I write. I told you exactly how you will know, checksums, which are built into btrfs. Let me change my language then, if the btrfs filesystem says the emulated drive from parity is good, then it's good, not "highly likely"— the only reason I used that terminology is to be mathematically precise. File integrity plugin will also get you to essentially the same place in a less real-time fashion with more steps. If you read all those same bits and the checksum comes out the same, then for all effective purposes (an essentially impossible random hash collision), it is good. There is no guessing here, please read up on cryptographic functions. As for "to an extent" that was more of a commentary on knowing "how off" your physical filesystem is. You can't really know how much of the block (or file in the plugin's case) but well, it's not really important how damaged your physical filesystem is if your emulated parity drive with checksums is good. Yes, integrating in those pieces together like zfs has advantages, particularly in terms of usability, automation, and ease, but all the information is still there. We're not going in circles, I've been explaining the same scenario since my first comment. I'm more than willing to continue to educate you on this as long as you want to respond. I've already laid out a practical implementation that works, given the other comments here stating when data is and is not written from the unraid side. You don't have to use these utilities to safeguard your data or streamline the restoration process if you don't want to.
-
Indeed, we still have a communication breakdown. I'll try to clarify again. No, you are covering a different case than the scenario I laid out. In your scenario, the parity is synchronized with the corrupted filesystem. It is numerically valid, but it does not satisfy my condition 2: that the parity has the correct bits, as in uncorrupted. I explicitly did not say whether or not the parity is invalid in this scenario, because it depends on the point of reference. In this scenario, it is synchronized with the uncorrupted filesystem, and out of sync with the physical corrupted filesystem. In my original comment's scenario, restoring from backup incurs a cost that is not desirable: remaining offsite backup that didn't fail is annoying to access: on a tape drive, in a different geographic location, on the cloud with expensive restore costs, etc. There are various scenarios where a write can be successful on one disk and not on another. The one I had thought up was that the connection with an externally connected SAS drive could be disrupted while the connection with the parity drive is intact. And then my actual scenario with RAM corruption, any particular computation could be corrupted, and the parity computation is separate from writing the block metadata or data itself. You could also have sata bus or CRC errors due to a bad cable. I did state these conditions up front for my scenario, if this was your big issue you could've brought this up in the beginning. I made no claims about the likelihood of this scenario, in fact in my first comment I stated it's probably rare. It doesn't mean rare cases should be ignored. The filesystem I mentioned already, btrfs, checksums both the data and metadata of every write. So yes, you can with a very high likelihood know if your parity is "correct" by emulating it, and also to know, to an extent, how "off" your physical filesystem is. And you'll get similar results with the file integrity plugin and other filesystems: once you notice your checksums are off with your physical disk, you can mount the emulated disk and see if the checksum is correct. This, of course, requires that you haven't done a parity check that writes corrections to parity, something that is explicitly recommended avoiding by those that use that plugin. There are plenty of advantages of unraid over zfs for my and other's use cases, why would I move to zfs if I can get some protection by adding additional layers on top of unraid's parity?
-
Ah, I see where the communication breakdown happened. I'll modify the first requirement to be: know a particular drive had a failure in particular files Yes, it's not by default in unraid that you get this, but there are tools that exist that give you this and would certainly to use them. In my case recently, it was btrfs (and it's fsck/associated tools) that alerted me to the specific files and folders with errors. It's also likely the file integrity plugin that I use would also have done so. I grabbed those files from backup. If I had known about the option I put forth in this thread, I would've at least investigated to see requirement 2 (know parity has the right bits) was satisfied by just mounting the emulated drive as true read-only and grabbing a checksum of the file. In my case, the issue ended up being bad RAM, so I would guess it's equally likely that the error was propagated both the parity and the drive vs just one of the two. I also did know that requirement 3 (the rest of the disk was good) was satisfied after extensive testing of the disk in another system and discovering the root cause.
-
Just thought I'd mention some unintuitive behavior for scatter: if I select multiple individual files, it attempts to place each one on a separate drive, even if there is enough space on a single drive. If there are more individual files than target drives selected, it claims there is not enough space in the target disks. E.g. I'm moving a several small log files (10 MB each), and my disks have several TB free. It will place the first log file on the first target disk, second on the next target disk, and then if there are more individual files than disks available, it will say "PLANNING: The following items will not be transferred, because there's not enough space in the target disks" I selected scatter because I want to move them from a specific full drive to other drives.
-
So then a single file restore with the steps I mentioned is actually currently possible then without any modifications. The required steps are to mount the disks with explicit options to do no writes: "ro,norecovery" with btrfs. xfs, reiserfs, and ext* also have similar options, and though there is some debate whether they actually work, creating a "ro,loop" device guarantees it with any block device. There is an additional layer if encrypted, so one would have to verify luks opening doesn't write any data either just in case. Thanks, this is definitely good to know and can potentially save days of rebuilding then under very specific scenarios.
-
Ok, then can you answer my original question? What data, if any, is written when just starting the array maintenance mode by itself? This is before any filesystems are interacted with. I did find an answer to the second half dealing with the filesystems, specifically btrfs: If it is mounted with the options "ro,norecovery" then indeed absolutely no data is written to the disk, and this step would not create a divergence between the physical disk and parity/emulated disk. So the remaining question is the preceeding steps.
-
Well, I guess thank you for indulging me as much as you two have so far. I'll just re-iterate from my original comment: The discussion I attempted to provoke was for an advanced use-case only. I thought it was clear from all the bold warnings in my original comment that it is not something I would suggest implementing without knowing more details of the how and when information gets written, of which apparently none of us here know.
-
You implied an answer to my question, but it wasn't explicit. I think you may have misunderstood my question based on adding an explanation on parity/emulation, so I'll restate it. My question is whether you can prevent writes to all disks by starting in maintenance mode and mounting as read-only, or if some amount of data is written on the emulated disk/parity through any of these steps. My understanding of parity/emulation hasn't changed since my original comment with your explanation, so if there is a specific detail I'm getting wrong, please point it out specifically. In my original comment, I acknowledge that anything that gets written when emulating would be dangerous and cause the physical disk and parity/emulated disk to go out of sync. Now if it is impossible to prevent writes currently when using maintenance mode and read-only mounting, my follow up question is if would it theoretically be possible (with OS level changes to unraid) to prevent those writes? I think it'd be advantageous to be able to inspect/modify the array without any writes to anything, as is the standard for dealing with issues on individual disks, even ignoring this specific scenario.
-
Well, all times leading up to an event, item 2 and 3 are generally true, and one specific event manually being instantiated can result. I did say it was a rare scenario and my reply was really just a thought experiment about what is possible with unraid. Interesting, well I am quite doubtful that the parity operation and emulation happens at a different stage whether the devices are encrypted or not, so perhaps the block devices themselves are likely hooked into it without mapping them. I suppose that makes sense, if you start in unencrypted maintenance mode and run a repair operation on device, any bit changes needs to be propagated to the parity. In this scenario I have manually selected the drive as "no device" and disabled it to get the emulation to run. The question is whether any writing of bits happens even though the partitions are mounted as read-only. When recovering a drive in general (outside of unraid), it's common practice to mount as read-only to avoid writing any data at all to the disk. Do you have any details on exactly what information is updated in this case in and outside of unraid? To clarify "restore that file outside of the parity protected array, e.g. cache or an unassigned device", the proposal is rebuilding the one corrupted file somewhere, then connecting back up the otherwise good drive and replacing the file alone. So avoiding the rebuilding of the full 20 TB and just whatever size the corrupted file is.
-
Nothing is mounted by default when starting in maintenance mode but the drives and emulated drives are created and mapped to /dev/mapper/mdX. You can then mount (read-only or even read-write, which does update parity) and get access to emulated files. Though as I mentioned I'm not sure if some bits get written in this process that invalidate the drive that is disconnected and being emulated. In this scenario, the concerns about rebuilding to the same drive are in terms of time and stress, not messing with the original disk or data.
-
Yes of course, I mentioned that in my comment with its potential disadvantage: So with drives of 20+ TB it can take quite a while, yielding degraded performance during the rebuild and stressing out the other drives. Though certainly better than getting to an annoying to access backup.
-
Sure, one should always have backups, since (un)raid is not a backup. But say your onsite backups failed and the remaining offsite backup that didn't fail is annoying to access: on a tape drive, in a different geographic location, on the cloud with expensive restore costs, etc. Requirements for this scenario: know a particular drive had a failure in only one file know that parity had the correct bits know the rest of that drive is okay. Maybe this could happen if you had some drive that was externally connected (e.g. SAS) which was disrupted when making a modification to one particular file with no other activity on that drive. An very rare scenario which use case shouldn't officially be supported, but an interesting thought experiment: In theory, wouldn't it be possible to emulate the drive that is known to have a file error and restore that file? There is a method to rebuild a drive onto itself, but as far as I know that will rewrite every bit on that drive and thus can take quite awhile. One potentially dangerous method in an attempt to achieve that result today: stop the array, mark the disk with the known error as "no drive", start the array in maintenance mode, mount the emulated drive as read only, and restore that file outside of the parity protected array, e.g. cache or an unassigned device. If starting the array in maintenance mode and mounting an emulated drive prevents any bits from being written to any drive, then you could then start the array after re-assigning the disk. Though since it'll likely mark your disk as a new drive, you'd have to make a new config and say parity is valid. To be clear, this probably a poor assumption, as I don't know all that much about filesystem details. Some bookkeeping information very well could be written somewhere before the read-only partitions are even mounted, and possibly mounting as read-only still writes to a log somewhere depending on the filesystem.
-
I'm restoring my array and lost my docker order. I have all my templates, I'm curious where the old docker startup order is stored. I still have my old /system/docker folder and /boot configurations. I do see an unraid-autostart file but that is of course only the ones that I have set to autostart, not the ones where I start with other scripts, where I setup the order in a specific way for shutting down automatically.
-
After realizing I might actually have dataloss from some mishaps with parity, I've started down this path and ran into issues, added to the first post. EDIT: Solved through making a temporary array where I could start an ubuntu docker and compile it. The binary then runs on the base slackware outside of docker just fine.
-
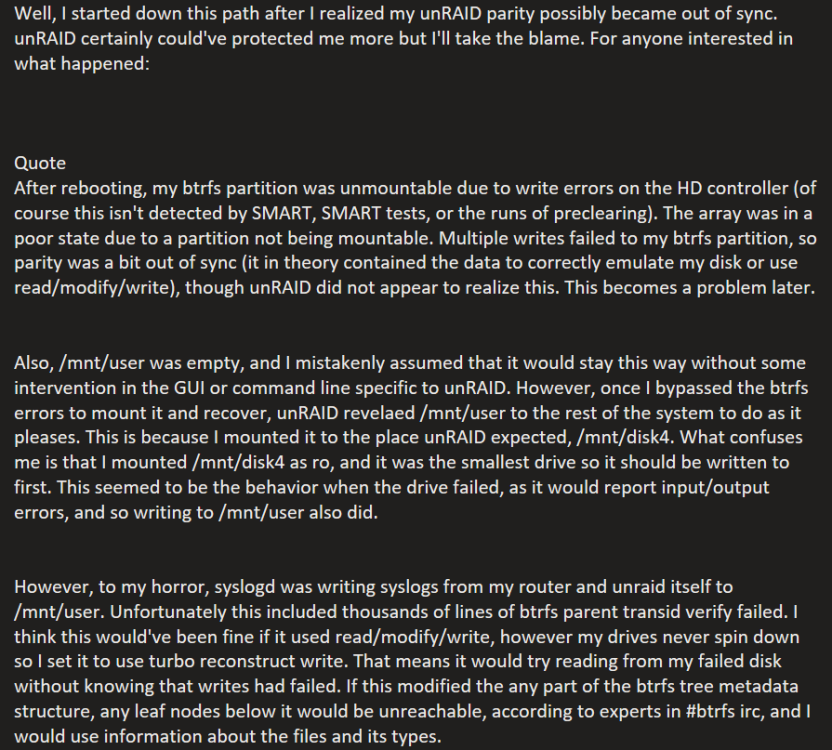
I have a drive with btrfs that is corrupted. I want to use btrfs restore but my drive had many files with compression set to zstd, as it is supported by the kernel. But the version of btrfs-progs installed on 6.11.5 does not have the zstd flag enabled, and thus errors when trying to restore files with zstd compression. I looked into compiling but with the dev tools plugin being depreciated, it seems like a bit of a hassle. Well, I started down this path after I realized my unRAID parity possibly became out of sync. unRAID certainly could've protected me more but I'll take the blame. For anyone interested in what happened: When trying to build btrfs-progs myself, I ran into several issues and am currently stuck on a couple issues. After going through and installing missing dependencies from https://packages.slackware.com/, I was able to get configure getting decently far. However: openat() function doesn't exist I did check fcntl.h and it certainly looks like openat is defined, just whether or not there is a separate openat64 depending on #defines, though it's been a while since I programmed backtrace and some issue with documentation generation, both can be fixed with flags blkid, uuid packages not found, not on slackware.com stopped commenting out checks at this point
-
Apparently it's a not uncommon issue with SSDs that slow down reading old files due to flash cell voltage for files that are over 3 months old. Discussion links on this issue at the end. Anybody have ideas about how to find SSDs that don't have this issue? Or SSDs that do have it? Advertisement terms, SLC vs MLC, some info in datasheets somewhere? Even some relatively new SSDs with 3 GB read/write speeds have this issue. I run my unraid off of 1 GbE so I don't care for speeds above 200 MB/s. Or any reviewers that do a long term review that look at this? I suppose it's not a common use case as many games get updated. Only thing I've found so far is that Samsung is the only manufacturer that deals with this, either through higher quality chips or at least in the 840 drives, firmware that likely refreshes old data occasionally at the cost of wear. It seems like some drives from WD, Corsair, and Teamgroup have this issue. While the 840's and the Corsair model dropped like a rock after ~3 months, WD model looks to appear to slow down gradually from 4 months to a year and maintain decent speeds. I also discovered this effects parts of files, e.g. for files that are constantly appended to, the early files remain intact and are slow. I have long running duplicati backups running with sqlite databases where this occurs. I always wondered why speeds got slower and slower, and it turns out the beginning blocks of the file are read incredibly slow. The most obvious use case was running an old VM in unRAID that I only spin up for specific use cases. Any old docker commits on images probably also have this issue but perhaps less noticeable if the layers get completely updated. Reading material: https://www.overclock.net/threads/read-speeds-dropping-dramatically-on-older-files-benchmarks-needed-to-confirm-affected-ssds.1512915/ https://linustechtips.com/topic/1275489-western-digital-ssds-experiencing-read-performance-degradation/ https://www.reddit.com/r/techsupport/comments/n438uo/wd_blue_ssd_exceptionally_slow/ https://www.overclock.net/threads/corsair-mp510-980gb-slooooooooow-with-older-files-like-7-10mb-s-read-speed-slow.1801829/ https://www.overclock.net/threads/read-speeds-dropping-dramatically-on-older-files-benchmarks-needed-to-confirm-affected-ssds.1512915/page-45#post-28976970 https://www.reddit.com/r/techsupport/comments/10bgcv0/ssd_read_speeds_slow_except_for_new_files/

