




Guido
Members
-
Joined
-
Last visited
Everything posted by Guido
-
Thank you. That document really helped out. I changed the folder rights before starting the installation and everything is running fine now.
-
If you are getting a DNS does not point to this server error you have issues resolving the domain you have entered. So either port forwarding is incorrect, or DNS is not configured correctly. Unfortunately that was as far as I got with this app... The created container nextcloud-aio-nextcloud is complaining that the AppData folder has moved since the installation (I'm sure I didn't as I didn't have it running in the first place.. So far it has been very frustrating to get this software to run, altough I would really like to get this running as I really like the idea of having all controlled from a master container and having all integrations configured correctly. Spacinvader has done some video's on Nextcloud on Unraid, but none of them include the redis integration to speed up the installation. I sure hope this will improve in the future. If you manage to get it running please let us know, maybe I can learn something from your experience.
-
That seems to be a beta version. Although it does have the latest binaries for Log4J, people should be aware that it's still in early access. And I'm glad you got things working again.
-
I have tried to build with Brett's sources and it just seems to work. At this point I have the container available at docker hub gjurriens/unraid-unifi-controller and I have just tried changing the container image in your template and that went without much trouble (the origional install got orphaned, but installing it again and setting the image to gjurriens/unraid-unifi-controller just brought it back up again with all my settings. @brettm357; just let me know how to get in contact (some form of chat or something alike) and we'll see how we can get it up and running again as we were used to. Also... could it be that your image is populair enough for Docker to not like to host it for free anymore? If that is the case... I'm working on getting some private docker container hosting going, if I get it running like I'm hoping to get it running that could also be a way out.
-
@brettm357Any updates? It was already quite some time ago that you commented on this. So far I didn't have an issue with it, but now with the Log4J vulnerability it is rather important to have this patched as soon as possible. If you can't get it working, is there any way we can help out? I can locally build the image using your setup, so your code by itself is working great. If you don't want the help, is it oke if I use your code to create a "new" docker image that will be receiving updates? I don't want to step on anyone's toes, but no updates is not really a great situation at the moment. I hope you won't be offended by my proposal.
-
Thank you, I did get Frigate running on the first try now. I have been looking through the issue's on the Frigate github, but couldn't find it. Thank you for helping out.
-
I had it running once... but after a reboot it didn't start again and I have the same error message in the log. I hope anyone has another idea, cause I would really like to get Frigate running again.
-
Did that just now, but it didn't help. Same message. And I did see it pulling the entire image again, so that's not the issue.
-
Yes, sure can.
-
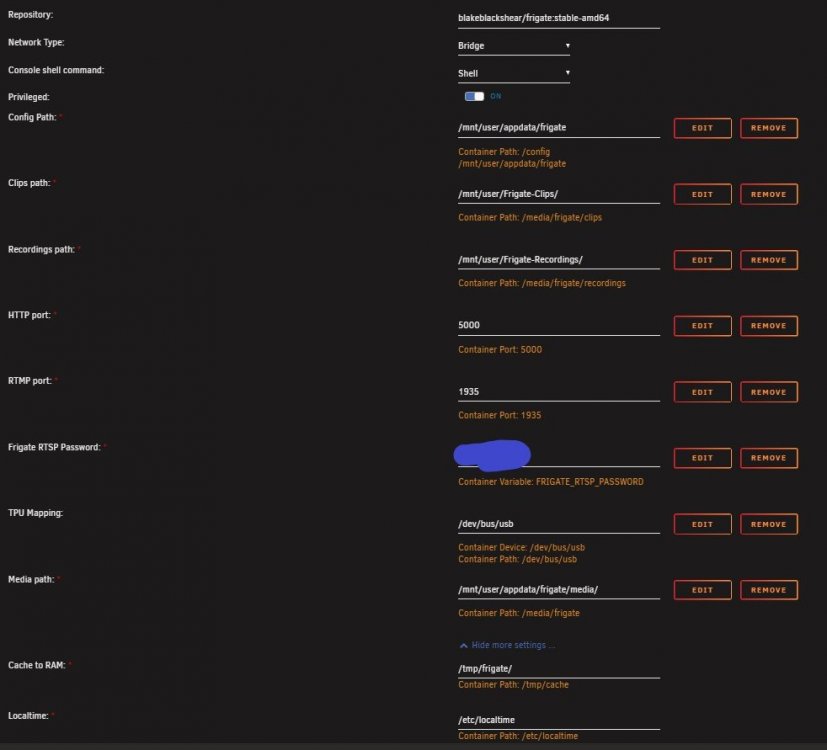
I have updated to the latest version, made sure my config is correct (at least, I can't find any faults in it). But when I start the container it stops again within a minute or so. The logs give me this: [s6-init] making user provided files available at /var/run/s6/etc...exited 0. [s6-init] ensuring user provided files have correct perms...exited 0. [fix-attrs.d] applying ownership & permissions fixes... [fix-attrs.d] done. [cont-init.d] executing container initialization scripts... [cont-init.d] done. [services.d] starting services [services.d] done. [s6-init] making user provided files available at /var/run/s6/etc...exited 0. [s6-init] ensuring user provided files have correct perms...exited 0. [fix-attrs.d] applying ownership & permissions fixes... [fix-attrs.d] done. [cont-init.d] executing container initialization scripts... [cont-init.d] done. [services.d] starting services [services.d] done. [2021-10-22 15:07:19] frigate.app INFO : Starting Frigate (0.9.2-25bb515) Starting migrations [2021-10-22 15:07:19] peewee_migrate INFO : Starting migrations There is nothing to migrate [2021-10-22 15:07:19] peewee_migrate INFO : There is nothing to migrate [Errno -2] Name or service not known [cmd] python3 exited 1 [cont-finish.d] executing container finish scripts... [cont-finish.d] done. [s6-finish] waiting for services. [s6-finish] sending all processes the TERM signal. [s6-finish] sending all processes the KILL signal and exiting. My Config is as follows: (removed credentials and stuff offcourse): mqtt: host: homeassistant.fqdn.local port: 1883 topic_prefix: blaat client_id: blaat user: blaat password: blaat stats_interval: 60 detectors: coral: type: edgetpu device: usb num_threads: 3 database: path: /media/frigate/frigate.db birdseye: enabled: True width: 640 height: 480 quality: 8 mode: motion ffmpeg: input_args: - -avoid_negative_ts - make_zero - -fflags - nobuffer - -flags - low_delay - -strict - experimental - -fflags - +genpts+discardcorrupt # - -rw_timeout # - "5000000" - -use_wallclock_as_timestamps - "1" detect: width: 1280 height: 720 fps: 5 enabled: True max_disappeared: 25 objects: track: - person motion: threshold: 25 contour_area: 100 delta_alpha: 0.2 frame_alpha: 0.2 frame_height: 180 record: enabled: False retain_days: 0 events: max_seconds: 300 pre_capture: 5 post_capture: 5 objects: - person required_zones: [] retain: default: 10 objects: person: 15 snapshots: enabled: true timestamp: false bounding_box: False crop: False height: 175 retain: default: 10 objects: person: 15 rtmp: enabled: False cameras: reolink-test: ffmpeg: inputs: # - path: rtsp://user:[email protected]:554/h265Preview_01_main # roles: # - record # - clips # - detect - path: rtsp://user:[email protected]:554//h264Preview_01_sub roles: - record - detect # - clips best_image_timeout: 60 Does anyone have an idea what's wrong?
-
I know, but I already have to much experience with flashdrives (different brands) dying on me (altough not related to Unraid).
-
@JorgeB; Thank you for the suggestion, I will surely look into that (need to find a place where I can host a syslog server best). Also... I have disabled some docker containers (machinaris-chives, machinaris-hddcoin and machinaris-nchain) and my server seems to be staying online longer at this point (the regular machinaris container is still running and that one doesn't seem to cause an issue).
-
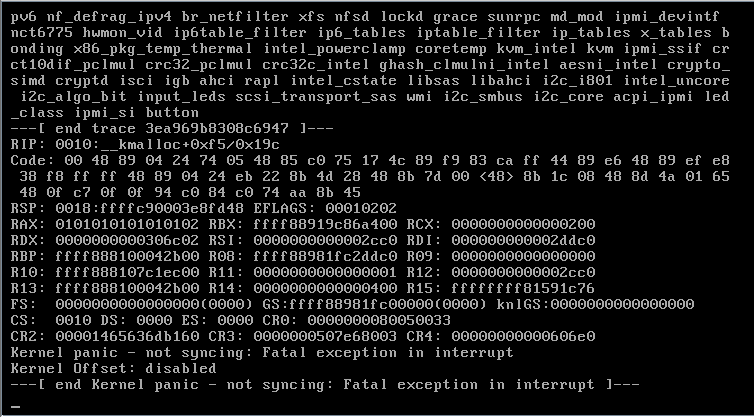
Unfortunately it didn't help altough I think it took quite a while longer before going into kernel panic. I have taken a screenshot of the kernel error (thank you IPMI). And I have also run new diagnostics. If anyone has another thing I can try, please let me know. srv-fs01-diagnostics-20211015-1512.zip
-
Thank you. I have change the custom network type to ipvlan. I will monitor the server and report back here.
-
I'm currently experiencing random kernel panics (at least, that is what the ILO remote console is showing me). I have no idea on how to troubleshoot this issue as I'm not that familiar with Linux. Just to be sure I have attached the diagnostics for my server, hopefully it will bring some clarity. Oh, I'm running the 6.10 RC1 because of the solution for the stale file issue's.. Thank you all for your time. Guido srv-fs01-diagnostics-20211013-1031.zip
-
Same here unfortunately... ** edit ** Found how to get it working. You need to upgrade to rc1 first and then load the plugin. It will then update to the internal rc2 test branch.
-
@MajorTomG Is it possible that your router would try to connect to the DNS using the WAN connection on your router? You could try running another DNS server (pihole or something like that) and point your router to that and see if it will resolve... If it will not resolve either, than I think your router will use the WAN port for DNS lookups. In that case you can setup LanCache to use your router as source DNS and point your systems to the LanCache IP. Maybe it's possible to change it in the DNS settings of your router so it will hand out the LanCache IP as the DNS server to you DHCP clients.
-
This is done by creating a 2nd or 3rd or whatever Pool Device (it's a new function in the beta versions). Therefore I have a main raid set and an ohter raid set in the pool device (in my case a 4 disk btrf raid 1 set) and the main set is a 3 disk raid 5 (xfs)
-
I have and it doesn't as far as I can see... I need a raid set, and with the Unassigned Devices plugin I can only share a single drive... Or if it is possible to set a few drives in a raid mode, I haven't found out how... a pointer in the right direction would be nice in that case.
-
It is on a new raid set that will only be available as a "cache". It is set to cache only. I need it to be like this cause I didn't want it to be part of the main raid setup.
-
When I try to use Veeam as a backup target using NFS, I always have to reboot my Veeam Backup server before starting the job or I will have errors about stale file handles in the Veeam logs and the job failes. The options provided on the forum with the tunables didn't work. The best possible solution would be to implement a newer version of NFS (4.x) so we can finally get rid of all these old time errors for multiple users. I'm running beta25 at the moment (latest at the time of posting)
-
I'm going to have a look at Ganesha-NFS later this week. I hope I can get the docker container running on it's own IP address.. that has been an issue for me so far.. maybe because I have a virtual Unraid server (ESXi based with 2x LSI cards on passthrough). Oh, and I have the same issue with the stale file handles (in the Veeam Backup Job logs: NFS status code: 70).
-
I hope the dev will implement NFS4.x soon... I was hoping to setup Unraid as a Veeam Backup Repository, but I have issue's with it on both SMB and NFS. NFS requires me to reboot my proxy before running a backup just to get a connection to the NFS. If I don't I get a message saying I don't have write access to the location. Already checked the rights on the share, and tried with NFS share as public and unfortunately it didn't work out.
-
Hello all, I'm having issue's running lancache... I cannot seem to get any connection to the lancache container. My UnRaid server is running on 192.168.102.200. I have given lancache a dedicated IP (192.168.102.202) in my LAN range (192.168.102.0/23), but connecting isn't possible. Network type is set to Custom: br0 If I ping the IP from a random system on my network I never receive a reply, but when checking with arp -a I do see the mac address beloning to the container (checked with ifconfig from within the container). Is there anything I should check (firewall on the unraid server or something like that)? I didn't configure any firewall rules myself (if there is a firewall on Unraid as I don't see anything about it in the menu. Thank you for your time.


