




lnxd
Members
-
Joined
-
Last visited
Everything posted by lnxd
-
🤔 This is odd. Can you please force an update to the container to make sure you are on a version that handles sigterm, and then please share your diagnostics.zip when the container is unresponsive? Also, are you running the latest-root tag or latest? When it is unresponsive, do the logs not load via docker logs XMRig -f as well as the Unraid WebUI or just the WebUI? And does the first command output something and then not continue, or output nothing at all? Also, when you say a clean shut down do you mean of the container or does it hang your whole server during a shutdown? Because when you shut down, Unraid will try stopping the docker daemon, which tells docker to send sigterm to all running containers, and after about 10 seconds it will send sigkill to them. A couple of things to try: docker exec -ti XMRig apt-get install -y htop && htop When it is frozen, can you please run docker stop ----time=60 XMRig, see if it takes the full minute to stop. If it does, this means sigterm is failing. This shouldn't happen, but your diagnostics.zip could explain why it does.
-
I think @trig229 is having trouble with a Sapphire RX 6800 XT 16 GB Nitro+ from their logs. Yes I did! And I tried to get it working again today, but still no luck. But it's okay, I don't need to use it with linux anymore. I got it to use with tuya-convert, but I ended up using an Arduino Uno to flash the chips directly anyway. At least it works with my Windows VM so it's not a complete waste 🤷♂️.
-
Thanks for the info @Steace! Awesome option for people more interested in squeezing that bit more out of their hash rate. The lower minimum payout + lower transaction fees are definitely useful when mining XMR. Anyone who's interested in changing; best time to do it is right after a payout, as the profits aren't transferable from pool to pool.
-
No problem! And you're welcome 😁 If you're on the current template it explains too by the way, although it's a bit long so I don't blame you for missing it (or you're on the old template). In case anyone else comes across this while searching:
-
The HDMI dummy will still make it fluctuate 😅 I have one too, and when connected it bounces up and down +-5w. If you're just using it for Windows, check out VirtIO Guest Tools if you haven't already, it's an install package on the VirtIO Drivers ISO. Yup it'd be bound at the moment if you're using it in a VM. It could be better for Plex yeah, but if you're using Quick Sync to transcode h265 content the Intel might be marginally more efficient from hardware HEVC decoding support so could go either way too 😂 If most of your content is h264 or AV1 the Nvidia card will probably be better. If I was you, I'd definitely test it out and see how you go. Just keep in mind that while you can probably 1-click OC your card in Windows, you'll have to tune your OC manually using PhoenixMiner arguments if you want to OC for mining. And I don't know if that will work with Nvidia cards for my container. It does for AMD cards. Not to say I wouldn't love to have an Nvidia card, it's just that horrid shortage haha. EDIT: I just saw your update, sorry! Yeah I think for ages T-Rex Miner was the only one on there, then I made this, I think NfsminerOC was under development at the same time cos it showed up very soon after, and then I put XMRig on there as well. I also have a working container for Lolminer, and it's not a lot of work to change PhoenixMiner out for any GPU miner really. But I don't want to fill up CA with so many alternatives; just the best 😁
-
Thanks for fielding that question for me. For some reason, even though I have it set to email me every time there's a new post, it doesn't Also thanks letting me know about the procedure with Nvidia too, I have no way to test my work as I only have AMD cards. Do the overclock arguments from PhoenixMiner work for your 1070, or do you get errors? If this was XMRig, I'd say you're looking at a ~10% increase in hash power. But the performance of this container in theory should be around the same as running PhoenixMiner from a VM as long as there are no other bottlenecks (ie. pinning the CPU incorrectly). You might save a couple of watts from not having a display connected to your GPU anyway. The only way to know for sure would be test it (easy), or research the performance impacts of using a GPU via VFIO passthrough (basically voodoo). The main reason I made this container vs. mining from an NHOS VM in the first place was stability with AMD cards; it's not affected by the vfl / vendor-reset issue. And then coincidentally it just turned out it's super convenient if you want to use the same GPU with multiple docker containers either simultaneously or separately. Which makes it arguably more convenient for Nvidia as well if you're more interested in using your GPU for Plex transcoding or one of the awesome gaming containers on CA for eg. rather than GPU intensive VM workloads. So maybe a question that's just as valid is whether you prefer to have your card bound to VFIO or not 😅
-
Those logs line up with what @gfjardim said above, and I think they're spot on. If I was you I'd let the preclear finish and then confirm that the SMART data is valid after that. Definitely keep an eye on the current temperature data afterwards and make sure it updates as expected, as that is one of the more frequently updated SMART data points, and one that the system likely relies on. You can monitor it for a while before you add it to your array of course, but I think your drive is fine.
-
If this pre-clear is still in progress, can you please share your smart data from Main > Drive Name > Download next to Download SMART Report? Alternatively this is also in diagnostics.zip. You should be able to see the smart data on this screen too. As long as the smart data is visible there (and not wildly inaccurate) it's not an issue with your drive. ie.
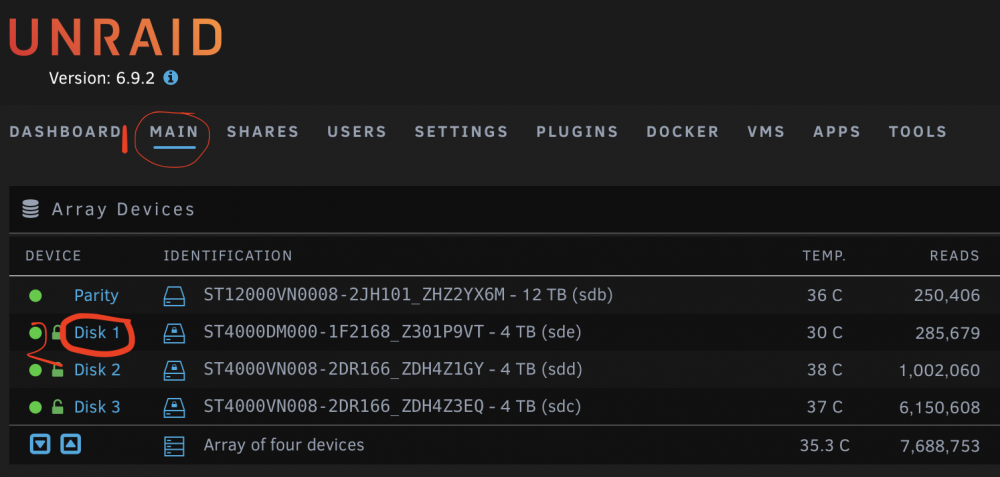
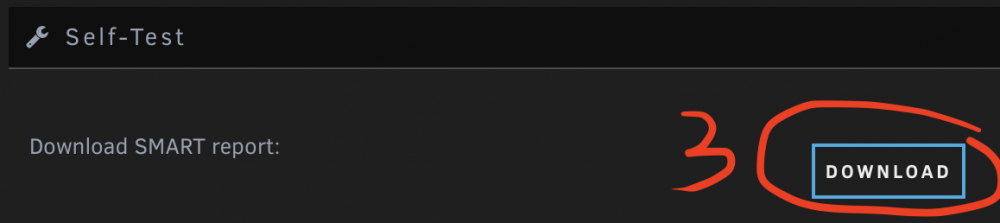
-
Hey @Steace, Haha all good, I usually edit my own reply rather than replying again if I am the most recent to reply to a thread. But that time I posted because it was an announcement. You did nothing wrong, I’m just talking to myself 😅 Thanks for letting me know! I've given it a value as default and added to the description that it should be removed unless you want to use GPU passthrough. That way people won't have the same trouble as you did. And leaving the default value there will do nothing unless you install GPU drivers in the container by filling out the other variables. The container should work just fine on 6.8.3, except if you try to use it with AMD GPU passthrough. That will install the drivers and everything, but the container won't see any AMD cards because the amdgpu module it relies on was introduced in 6.9.0.
-
Hey @horphi, this is quite difficult to set up but possible. Ravencoin uses the kawpow algorithm which is a GPU algorithm. To use XMRig you will need to go on the latest-root tag and re-install it from CA to get the new GPU options, and configure those. Then you will need to follow the instructions I'm giving for @tsakodim below but set the Coin variable to an unsupported option like x instead. Then you will need to add --algo kawpow to additional arguments and update the pool & wallet details per the Nanopool website. PS. there is a typo in your Additional Arguments: --random-1gb-pages should be --randomx-1gb-pages Hey @tsakodim, At the moment there is a hidden variable for COIN. The --algo option wasn't working with the container in 6.10.1 so I hardcoded COIN instead. If you set COIN it will default to the most optimised algorithm for mining that coin. It supports monero, arqma and dero. Like I said to @horphi above, if you set it to an unsupported option (like x) you can effectively disable it and use --algo in additional options instead. Example: Edit the container > click Add another Path, Port, Variable, Label or Device > Set Config Type to Variable > enter the following and press Add. Here are my logs starting to mine Ravencoin: Driver installation finished. Project: xmrig Author: lnxd Base: Ubuntu 20.04 Target: Unraid 6.9.0 - 6.9.2 Donation: lnxd-fee 1% Driver: 20.20 Running xmrig with the following flags: --url=rvn-au1.nanopool.org:12433 --coin=x --user=84e8UJvXHDGVfE5HZDQfhn3Kh3RGJKebz31G7D4H24TLPMe9x7bQLBw8iyBhNx9USXB8MhvhBe3DyVW1LcuVAf4jBiADNLw.Unraid --randomx-wrmsr=-1 --randomx-no-rdmsr --no-color --algo kawpow --tls --keepalive --opencl * ABOUT XMRig/6.10.0 gcc/9.3.0 * LIBS libuv/1.41.0 OpenSSL/1.1.1j hwloc/2.4.1 * HUGE PAGES supported * 1GB PAGES disabled * CPU Intel(R) Core(TM) i5-10500 CPU @ 3.10GHz (1) 64-bit AES L2:1.5 MB L3:12.0 MB 6C/12T NUMA:1 * MEMORY 29.8/31.1 GB (96%) DIMM_A1: 8 GB DDR4 @ 2400 MHz KHX3200C16D4/8GX DIMM_A2: 8 GB DDR4 @ 2400 MHz KHX3200C16D4/8GX DIMM_B1: 8 GB DDR4 @ 2400 MHz KHX3200C16D4/8GX DIMM_B2: 8 GB DDR4 @ 2400 MHz KHX3200C16D4/8GX * MOTHERBOARD ASUSTeK COMPUTER INC. - PRIME Z490-P * DONATE 1% * ASSEMBLY auto:intel * POOL #1 rvn-au1.nanopool.org:12433 algo kawpow * COMMANDS 'h' hashrate, 'p' pause, 'r' resume, 's' results, 'c' connection * ADL press e for health report * OPENCL #0 AMD Accelerated Parallel Processing/OpenCL 2.1 AMD-APP (3110.6) * OPENCL GPU #0 05:00.0 Radeon RX 580 Series (Ellesmere) 1200 MHz cu:36 mem:4048/8186 MB * CUDA disabled [2021-04-12 09:27:58.454] net use pool rvn-au1.nanopool.org:12433 TLSv1.2 139.99.156.30 [2021-04-12 09:27:58.454] net fingerprint (SHA-256): "c38886efdee542ebd99801b75c75d3498d97978bbcdec07c7271cb19729e014f" [2021-04-12 09:27:58.454] net new job from rvn-au1.nanopool.org:12433 diff 600M algo kawpow height 1707112 [2021-04-12 09:27:58.454] opencl use profile kawpow (1 thread) scratchpad 32 KB | # | GPU | BUS ID | INTENSITY | WSIZE | MEMORY | NAME | 0 | 0 | 05:00.0 | 9437184 | 256 | 2884 | Radeon RX 580 Series (Ellesmere) [2021-04-12 09:27:58.454] net use pool rvn-au1.nanopool.org:12433 TLSv1.2 139.99.156.30 [2021-04-12 09:27:58.454] net fingerprint (SHA-256): "c38886efdee542ebd99801b75c75d3498d97978bbcdec07c7271cb19729e014f" [2021-04-12 09:27:58.454] net new job from rvn-au1.nanopool.org:12433 diff 600M algo kawpow height 1707112 [2021-04-12 09:27:58.454] opencl use profile kawpow (1 thread) scratchpad 32 KB | # | GPU | BUS ID | INTENSITY | WSIZE | MEMORY | NAME | 0 | 0 | 05:00.0 | 9437184 | 256 | 2884 | Radeon RX 580 Series (Ellesmere) [2021-04-12 09:27:58.540] opencl GPU #0 compiling... [2021-04-12 09:27:58.676] opencl GPU #0 compilation completed (135 ms) [2021-04-12 09:27:58.676] opencl READY threads 1/1 (222 ms) [2021-04-12 09:27:58.958] opencl KawPow program for period 569037 compiled (283ms) [2021-04-12 09:27:59.257] opencl KawPow program for period 569038 compiled (298ms) [2021-04-12 09:28:02.113] miner KawPow light cache for epoch 227 calculated (3149ms) [2021-04-12 09:28:02.113] miner KawPow light cache for epoch 227 calculated (3149ms) [2021-04-12 09:28:12.723] opencl KawPow DAG for epoch 227 calculated (10594ms) [2021-04-12 09:28:21.413] opencl accepted (1/0) diff 600M (297 ms) [2021-04-12 09:28:23.914] net new job from rvn-au1.nanopool.org:12433 diff 600M algo kawpow height 1707112 [2021-04-12 09:28:32.938] net new job from rvn-au1.nanopool.org:12433 diff 600M algo kawpow height 1707113
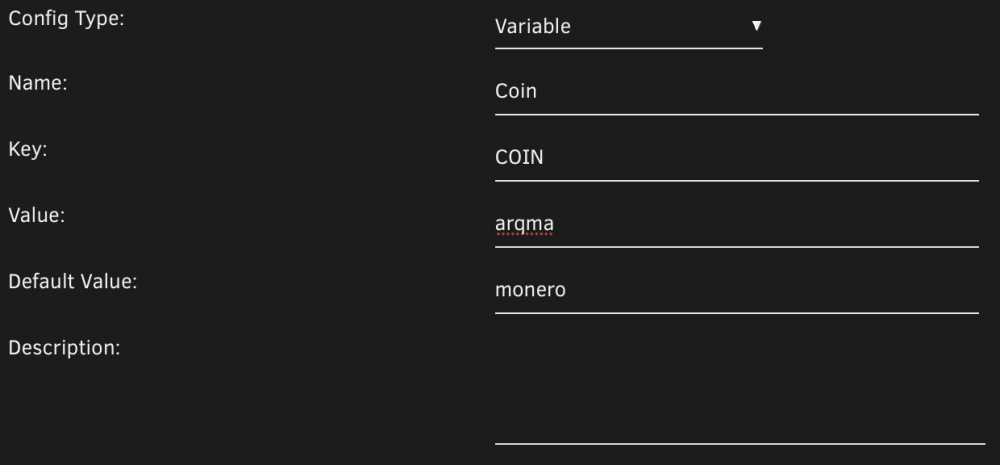
-
Due to overwhelming demand (3 people 😂), I've just released a new version works with both AMD and likely Nvidia GPUs as well. You'll need to re-add the container from CA and use the repository to lnxd/xmrig:latest-root to use the new features; it'll probably get picked up some time within the next 2 hours. I haven't got an Nvidia GPU to test it with so if someone gets it working with one, please let me know. But be patient, it takes around 10 mins to install Cuda for me before it gets to the mining stage, I'm gonna work on reducing that when I get a chance. It now includes XMRig 6.11.1 binaries made as part of the docker build process rather than separately, and it's 26mb smaller than before even with the optional CUDA library layer, probably because I got better at writing Dockerfiles? Not sure 😅 In case anyone is worried about bloat, the container doesn't contain the drivers by default. If you want to use them you need to select a version and it will install them. PS. Sorry, I hate to double post rather than just edit. But I thought people monitoring this thread might be interested to see without getting an annoying alert. Except @Steace
-
Thanks for the heads up @Squid! A very good call to do this after the recent wave of compromised servers with XMRig running. I'll update OP. And @jonathanm that recommendation made me laugh this morning, it was one of the first things I read when I woke up and it's very true 🤣 Hey @Steace! Yup you sure do. Otherwise it'll be a looooonngg time to payout. Just make sure you note their transaction fee when you're reducing the value. If you slip it into the worker field it should work, eg. Unraid/[email protected]. Then just let it mine for a while before trying to update the payout threshold on the Nanopool website.

-
Haha no worries! Just @trig229 is having trouble now. Sadly the drivers don't work, but I don't want to hijack this post 😅 I think this answer looks promising for my problem, I'll give it a shot when I get some time.
-
Thank you! Should have been obvious to me, but I didn't know the new version was out yet 😅
-
Haha yeah it's super expensive here, I calculated that at a rate of $0.21AUD/kWh. I have flat rate electricity (included in my rent) so I can play around a bit, but it would have to cost someone less than $0.035AUD/kWh to be profitable with an RX 580. But hey, it's max 14c (57f) here today, and mining heats two rooms of my house 😂
-
Thanks for all the suggestions in your post! Super valuable information for people with Xeons. If I'm honest about GPU Mining Monero, the environmentalist inside me kicks in and says it's a waste of electricity 😅 My hash rate with my RX580 with XMRig/RandomX is around 900H/s which is around $2.56AUD/month at current rates, but the cost at 80w is around $12.85AUD/month worth of electricity. I might write up a tag for people who are left out (and are lucky to have free electricity). It just requires one extra XMRig build so that it works with Nvidia cards + adding the AMD drivers which I already have a base for.
-
Hey! I'm building a kernel that contains vendor-reset for @plis halp. Is it failing to build vendor-reset?: ---Copying Kernel Image to output folder--- ---Downloading gnif/vendor-reset from Github--- ---Source: https://github.com/gnif/vendor-reset --- Cloning into 'vendor-reset'... Already on 'master' Your branch is up to date with 'origin/master'. make -C /lib/modules/5.10.21-Unraid/build M=/usr/src/vendor-reset/vendor-reset modules make[1]: *** /lib/modules/5.10.21-Unraid/build: No such file or directory. Stop. make: *** [Makefile:8: build] Error 2 make -C /lib/modules/5.10.21-Unraid/build M=/usr/src/vendor-reset/vendor-reset INSTALL_MOD_PATH= modules_install make[1]: *** /lib/modules/5.10.21-Unraid/build: No such file or directory. Stop. make: *** [Makefile:11: install] Error 2 ---Generating bzmodules in output folder--- logs.txt
-
Haha no worries, as far as it looks, the card is resetting correctly. Did you notice if one core get stuck at 100% when this happens? Easiest way to see this is probably from Unraid dash, but you can see it via Task Manager or by running top as well. That'd be a sure sign the vBIOS you're using is causing problems, and you'd want to dump it yourself. I hate to be the link guy but I'm a little stumped, but I think you're on the right track already with the changes you made to your XML. I came across this comment for someone having the same issue with a 6800XT on Reddit that says: OP said they resolved it: I'm guessing you've tried this from your XML. Does setting a vendor ID with a valid format like 0x0438 make a difference?: <hyperv> <relaxed state='on'/> <vapic state='on'/> <spinlocks state='on' retries='8191'/> <vendor_id state='on' value='0x0438'/> </hyperv> <kvm> <hidden state='on'/> </kvm> Also this slightly less relevant but potentially very useful post on Level1techs could provide some possible solutions, ranging from confirming that your GPU is configured correctly in your BIOS to some potential XML tweaks. 😅 it'll work out-of-the-box in Windows, when I was trying to get it working in linux there were no compatible drivers.
-
Haha yeah sorry I was a bit tired when I asked, dumb question because it says it's an i3 in your logs. But yeah drop your caches and then restart the container:
-
No worries, and between 2-3gb sounds about right. It's like I said, the dash doesn't report allocated RAM just used RAM, whereas XMRig will report allocated RAM + used RAM. So if the dash shows around 15% before XMRig launches, and XMRig shows 72% when it launches (and is only sitting at around 300mb overhead), there's something unaccounted for that at least one of the above steps should solve. I'm thinking once you force your host to drop caches XMRig should have a fighting chance. As you noted the other day though, even with your huge pages set to 1gb, we're only talking a 1-3% increase in efficiency / hash rate. You said you have an Intel CPU and you limited it to 1 NUMA node. I'm guessing you have a Xeon/s then? If that's the case, your hash rate will likely benefit more from changing to the latest-root tag so that XMRig can see what hardware you really have and optimise things accordingly. XMRig reports how much RAM it's using a few lines down from what you shared in the logs, Eg.: 1gb Huge Pages Enabled with 1 NUMA node: randomx allocated 3072 MB (2080+256) huge pages 100% 3/3 +JIT (144 ms) 1gb Huge Pages Disabled with 1 NUMA node: randomx allocated 2336 MB (2080+256) huge pages 100% 1168/1168 +JIT (241 ms) The container will use what it says there + around 300mb.
-
Thanks @trig229, when did you last have this problem? I'm assuming you've restarted since then, right? You said you can still restart the array afterwards? The data explaining the problem isn't in this diagnostics.zip. If you're willing to, I might ask you to: Start the VM with both the VGA controller and the audio device passed through: 0c:00.0 VGA compatible controller [0300]: Advanced Micro Devices, Inc. [AMD/ATI] Navi 21 [Radeon RX 6800/6800 XT / 6900 XT] [1002:73bf] (rev c1) Subsystem: Sapphire Technology Limited Device [1da2:e438] Kernel driver in use: vfio-pci Kernel modules: amdgpu 0c:00.1 Audio device [0403]: Advanced Micro Devices, Inc. [AMD/ATI] Device [1002:ab28] Subsystem: Advanced Micro Devices, Inc. [AMD/ATI] Device [1002:ab28] Kernel driver in use: vfio-pci Stop it, and test that the VM won't start back up Grab a diagnostics.zip to post here (the issue also might be visible to you if you run the next command at this point. But I also want to see your XML files.) dmesg | grep vfio Stop the Array, and allow the system to go through a complete reboot so that you can use it again normally without the card stuck hanging There is a chance your issue might be vBIOS related too if @giganode thinks so; although honestly you should be able to get away with not using a vBIOS file, booting to the Windows login screen, then shutting down and starting back up again. Especially if the VM is using the Microsoft Basic Display Driver. The card should still be able to reset, but it sounds like it's failing to. Also if you ever get that Intel Corporation Wi-Fi 6 AX200 [8086:2723] working in a linux VM, hit me up 😅
-
@G Speed In addition to what @SPOautos mentioned, another likely cause is kernel caching. Might also be worth dropping your caches by running the following in terminal: echo "Before:" && free -h && sync; echo 3 > /proc/sys/vm/drop_caches && sleep 10 && echo "After:" && free -h There's a real chance you'd be fine starting XMRig with 1gb Large Pages soon after a reboot. But the Kernel caches regularly accessed things to RAM for the purposes of speed & efficiency. XMRig just asks for the RAM with a lower priority and its request gets denied. The command above forces the server to drop these caches, so XMRig has less competition when it tries to launch with 1gb Huge Pages. The kernel will then rebuild them as necessary. On any other OS this would cause a (probably unnoticeable on a modern PC) drop in performance in the short term, but keep in mind that on Unraid the Kernel is run from memory anyway so it shouldn't impact much at all. You'll also likely notice that free RAM visible from terminal (free -h) is different to free RAM visible on the Dashboard, the Dashboard seems to ignore cached data in RAM. I'm assuming this choice was made because the system will automatically drop it if you ask it to. Eg. if you try to use that RAM to start a VM it just takes that space in your memory, so it isn't useful information for most users. I'm going to make some updates to OP as well.
-
Woohoo! Hopefully it keeps going that way. I'm just happy to help, so any time 😁 You'll be better off with both changes anyway, one might have caused problems once you resolved the other so no harm, no foul.
-
😂 Inno3D's heyday was well before me, I only know about them from some LTT videos where they've reviewed "weird" cards. The thermals on that card must be insane, how do you manage the heat? The diagnostics.zip you provided doesn't seem to have the answer in it, having the server crash + needing to reboot means the logs are gone. All that's in there is the logs that show the system booting and data that otherwise suggests your server should be working fine. @jonp's answer should give you the information you need, I wish my "server" had IPMI. That or configuring a remote Syslog Server in Unraid WebUI > Settings > Syslog Server. But it looks like you've found yourself a possible solution.
-
No worries. Possibly, I wouldn't passthrough one without the other, because the driver might address the audio device expecting it to be there. You can passthrough multiple audio devices if you need to have onboard audio in the VM. While you're in there by the way, I'd dump it with both so that you have a second vBIOS to try if something goes wrong with the first. It's a pain set up, and ATIFlash is more trusted than GPU-Z for generating a mod-able (complete) vBIOS, where GPU-Z is the go-to for producing vBIOS for vfio passthrough.







