




randalotto
Members
-
Joined
-
Last visited
Everything posted by randalotto
-
Thanks for taking a look! The two drives in question are on the last two plugs of a 1-to-4 SATA power splitter, so I'm going to replace that and see if it helps. (Thinking back, it seems like I heard a spin-up just before the still-online drive starting spitting errors and the extended SMART test failed on the offline drive, so that does seem to suggest a power issue.) What's the process to get things back online? I'll power down, replace the power cable, then ... will Unraid handle the rest once I boot back up?
-
I first got an error saying "Alert [TOWER] - Disk 3 in error state (disk dsbl)" The main screen of the GUI shows 2048 errors, and the drive has been disabled. I've tried running an extended SMART test several times, but each time it fails with the message, "Interrupted (host reset)". (And yes - I changed the spindown setting to "Never".) While I was trying to troubleshoot, I started getting errors on another drive. It currently reports 1447 errors. Both drives are connected through the same HBA card. I haven't confirmed whether they're using the same breakout cable, but several other drives would also be connected on the same cable(s) regardless. Before I restart / start poking around, I'd appreciate if anyone can help guide me to where I should be looking based on my diagnostics file. Thanks! tower-diagnostics-20240825-1927.zip
-
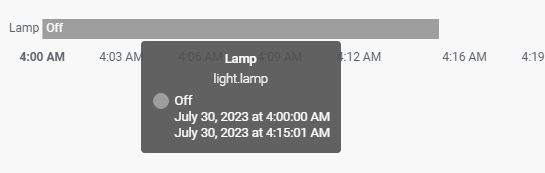
I've got a bit of a weird one- I've been having issues with Zigbee2MQTT not restarting after an update. In some cases, it will restart properly, but certain devices won't rejoin the network. In order to avoid the issue, I excluded Zigbee2MQTT and related apps (Home Assistant and MQTT) from auto updates and auto backups (and they are also set not to turn off during auto backups) My situation has improved, but I still sometimes find that it has stopped unexpectedly. For the latest crash, I realized it coincided not with the auto app update, but with the auto plugin update. (starting at 4:15:01, there's no data) Here's the log: Jul 30 04:12:37 Tower CA Backup/Restore: Backup / Restore Completed Jul 30 04:15:01 Tower Plugin Auto Update: Checking for available plugin updates Jul 30 04:15:02 Tower kernel: docker0: port 18(vethccf4ece) entered disabled state Jul 30 04:15:02 Tower kernel: veth24ef50b: renamed from eth0 Jul 30 04:15:02 Tower avahi-daemon[8703]: Interface vethccf4ece.IPv6 no longer relevant for mDNS. Jul 30 04:15:02 Tower avahi-daemon[8703]: Leaving mDNS multicast group on interface vethccf4ece.IPv6 with address fe80::9c9f:54ff:fe0f:5de. Jul 30 04:15:02 Tower kernel: docker0: port 18(vethccf4ece) entered disabled state Jul 30 04:15:02 Tower kernel: device vethccf4ece left promiscuous mode Jul 30 04:15:02 Tower kernel: docker0: port 18(vethccf4ece) entered disabled state Jul 30 04:15:02 Tower avahi-daemon[8703]: Withdrawing address record for fe80::9c9f:54ff:fe0f:5de on vethccf4ece. Jul 30 04:15:02 Tower kernel: docker0: port 18(veth7d3c02b) entered blocking state Jul 30 04:15:02 Tower kernel: docker0: port 18(veth7d3c02b) entered disabled state Jul 30 04:15:02 Tower kernel: device veth7d3c02b entered promiscuous mode Jul 30 04:15:02 Tower kernel: docker0: port 18(veth7d3c02b) entered blocking state Jul 30 04:15:02 Tower kernel: docker0: port 18(veth7d3c02b) entered forwarding state Jul 30 04:15:02 Tower kernel: eth0: renamed from vethabbc255 Jul 30 04:15:02 Tower kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth7d3c02b: link becomes ready Jul 30 04:15:04 Tower avahi-daemon[8703]: Joining mDNS multicast group on interface veth7d3c02b.IPv6 with address fe80::583c:b9ff:fe32:c699. Jul 30 04:15:04 Tower avahi-daemon[8703]: New relevant interface veth7d3c02b.IPv6 for mDNS. Jul 30 04:15:04 Tower avahi-daemon[8703]: Registering new address record for fe80::583c:b9ff:fe32:c699 on veth7d3c02b.*. Jul 30 04:15:04 Tower Plugin Auto Update: fix.common.problems.plg version 2023.07.29 does not meet age requirements to update - 1 days old Jul 30 04:15:04 Tower Plugin Auto Update: unassigned.devices.plg version 2023.07.28 does not meet age requirements to update - 2 days old Jul 30 04:15:04 Tower Plugin Auto Update: Checking for language updates Jul 30 04:15:04 Tower Plugin Auto Update: Community Applications Plugin Auto Update finished Jul 30 04:15:09 Tower kernel: docker0: port 18(veth7d3c02b) entered disabled state Jul 30 04:15:09 Tower kernel: vethabbc255: renamed from eth0 Jul 30 04:15:09 Tower avahi-daemon[8703]: Interface veth7d3c02b.IPv6 no longer relevant for mDNS. Jul 30 04:15:09 Tower avahi-daemon[8703]: Leaving mDNS multicast group on interface veth7d3c02b.IPv6 with address fe80::583c:b9ff:fe32:c699. Jul 30 04:15:09 Tower kernel: docker0: port 18(veth7d3c02b) entered disabled state Jul 30 04:15:09 Tower kernel: device veth7d3c02b left promiscuous mode Jul 30 04:15:09 Tower kernel: docker0: port 18(veth7d3c02b) entered disabled state Jul 30 04:15:09 Tower avahi-daemon[8703]: Withdrawing address record for fe80::583c:b9ff:fe32:c699 on veth7d3c02b. Jul 30 04:30:01 Tower root: Fix Common Problems Version 2023.07.16 Any idea what could cause that?
-
This is driving me nuts. According to a reddit thread I found, it's a bug in guacamole: https://issues.apache.org/jira/browse/GUACAMOLE-1717 I have no clue how to make that fix on my own, though.
-
Assuming one uses this script to back up Plex data, how does one restore that data at a later time?
-
You are my hero. Couldn't get my new system (with identical hardware) to boot. Disabling fast boot alone didn't work. Additionally changing the folder name to just "EFI" did. Thank you!
-
I recently had an issue with my cache drive that caused my docker image to become corrupted. I deleted the image, created a new one, re-installed my apps, and restored appdata from CA Backup. With fairly minor troubleshooting (mostly to recreate a custom network and deal with issues in docker templates that didn't automatically repopulate), everything is working again. Amazing! There's just one exception: Plex refuses to start. Here's the error message I'm getting: Why would the database be corrupted if I'm restoring from a perfectly good backup from only ~4 days ago? Edit: while I'd still like to know the answer to the above, I was able to get Plex back up and running using Plex's own database backup by following this: https://support.plex.tv/articles/202485658-restore-a-database-backed-up-via-scheduled-tasks/
-
Deluge is also suddenly broken for me and I'm getting the same error.
-
So I'm still having this issue. When I scan a document, paperless sees the document and adds it to the queue, and then ... nothing happens. Once I restart the docker, it correctly consumes the document with no additional intervention.
-
I'm having the exact same issue. Here are the log entries from today: [2021-04-01 11:22:35,086] [INFO] [paperless.management.consumer] Adding /usr/src/paperless/src/../consume/scan04012021.pdf to the task queue. 11:22:35 [Q] INFO Enqueued 1 Then nothing happens.
-
So I set this up with remote access via reverse proxy. In order to achieve a reasonable level of security, I've also enabled 2FA using TOTP. Is there a way to remember devices so that I don't have to enter a code every time I log in from a device on my local network?
-
Why? Both containers are exhibiting the same behavior, which seems like a bug.
-
I'm having issues disabling DLNA and removing mapping to port 1900. My unraid server is running Plex and Jellyfin, both of which try to bind port 1900 for DLNA. The typical result is that Plex launches and maps the port, but that causes Jellyfin to fail to launch. I don't actually care about DLNA, so I've tried disabling it in the Plex and Jellyfin interfaces and removing the port mapping from both containers. However, every single time one of the dockers updates, the port 1900 binding reappears. Is there any way to prevent this from happening? [posted the same question in the Jellyfin thread]
-
I'm having issues disabling DLNA and removing mapping to port 1900. My unraid server is running Plex and Jellyfin, both of which try to bind port 1900 for DLNA. The typical result is that Plex launches and maps the port, but that causes Jellyfin to fail to launch. I don't actually care about DLNA, so I've tried disabling it in the Plex and Jellyfin interfaces and removing the port mapping from both containers. However, every single time one of the dockers updates, the port 1900 binding reappears. Is there any way to prevent this from happening? [posted the same question in the Plex thread]


