




stefan.tomko
Members
-
Joined
-
Last visited
Everything posted by stefan.tomko
-
OK, I figured this out. Perhaps it will help someone too. So my setup is - I run several instances of Nextcloud. Before using AIO, I used classic multi-docker install and never had such issues. It started when I switched to AIO. I am using Nginx Proxy Manager. My problem was that with default AIO setup, your nextcloud runs on port 11000 on the IP of your unraid server - this is where you have to forward your traffic to using reverse proxy (NPM in my case). My NPM is running on br0 and I typically assign specific IPs to docker. Whenever I would connect to either nextcloud instance, it would stutter, become unresponsive. Like - I would get to login pace, log in, but after that, it would not be responsive for few minutes. I figured, after reading other posts on NC forum, it has something to do with networking within unraid - perhaps that I am using br0 for my NPM, connecting to Nextcloud AIO... (I am using ipvlan for dockers, if that is of interest). To get this working - here is what I needed to do: 1) In NPM properties - enable advanced view and in "Post arguments" put this: ; docker network connect nextcloud-aio Nginx-Proxy-Manager-Official This will assing NPM also network adapter from internal nextcloud aio network through which all NC dockers communicate 2) Modify your proxy host so that instead of an IP and port 11000, it connects to docker name. Example: your.cloud.domain points to http://nextcloud-aio-apache:11000 That resolved connection issues for one of my servers (NC). However I have another unraid server, running different cloud instance, and I needed to figure out a way to pass connection to second NPM. I did not want to dedicate other external port for 2nd instance. Therefore since all my https is forwarded to primary NPM, that is the place where to distinguish connections based on domain accessed. To make this work: 1) Edit proxy host - configure for example your.second.domain to connect to https://ip_of_second_NPM:443 (assign proper SSL certificates) 2) In that proxy host, navigate to advanced settings and put this there: proxy_set_header Host your.second.domain; proxy_ssl_name your.second.domain; proxy_ssl_server_name on; 3) In secondary NPM, create proxy host that will actually connect to apache of your second instance. Follow same instructions as in first part of this post - assign internal interface to NPM and point connection to docker name instead of IP. That should do it. Now both your.cloud.domain as well as your.second.domain are firstly sent to primary NPM. From there, your.cloud.domain connects to apache docker running on that server, while your.second.domain is sent over to another NPM instance and configured there to connect to apache docker on internal nextcloud network. No more connectivity issues for me.
-
Thanks to other forum topic on NC forum where someone pointed out the issue is with the way how NPM connects, i managed to resolve it on my host, by attaching internal docker network from nextcloud to NPM and referring connection to docker container name instead of ip on bridged network. However I still face an issue since I host 2 NC instances behind my reverse proxy. While one is pointed to internal docker network, other NC instance is hosted on different machine in network where I need to access it via br. Any ideas on where the issue is, or how to overcome it, without needing to specify other port on wan and forward that over to 2nd npm instance?
-
There are no logs with or around the timestamp when that issue occurs.
-
I came here looking for help. I have Nextcloud AIO installed on 2 different servers. Pretty basic setup, nothing fancy. Before switching to AIO, I used regular docker install and was pretty satisfied, except trying to put multiple things together (+collabora, etc.) and AIO just made more sense. However my issue is - I set it up just fine, all works. But often, when I browse into NC (to upload/download/edit some files via web mostly), NC would just stutter - requests eventually ends with 504 Timeout error. That lasts for couple of minutes (3-5?) and then all comes back to life. Almost like there is some bottleneck or something that NC just can't digest and stutters. I tried checking obvious things - found nothing specific in apache logs, master container logs or NC logs at all. I am using Nginx proxy manager - if that matters. I know this is not much to start with, but I am hoping that someone encountered something similar and would be able to advise. Edit: for instance just now (3:21 PM) - i have deleted 3 files and tried to upload one, it just spins. If I refresh the page - i get 504 error Logs in apache/nextcloud/mastercontainer are only from the time of start, nothing recent. 3:26 PM and it is back working. Similar hiccup happened on other instance the other day where I just logged in, and that kicked it down.

-
If you navigate to where you edit your VM - top right, there is possibility to show XML view. Once you toggle it, it shows XML configuration. You should be able to just copy paste it, so when you need to recreate it, you can just paste it there. Truth is, unless you are doing something fancy, you really need to pick up just where your VM disk is (usually /mnt/user/domains/xxx), perhaps core assignment, network card type and perhaps MAC address (if you rely on DHCP)
-
When I faced libvirt issues, I could not start VM services at all. For me, it worked by deleting the libvirt.img (on settings - VM tab, once you stop VM service, there should be button to delete libvirt). It will be recreated upon VM service start. You can backup VM XML, since after libvirt deletition, VMs will be gone. But this is just VM definition, virtual disks are still there, you just need to create VM again, assign old disk, RAM, etc.
-
Did you delete it by checking this checkbox "Delete Image File" and hitting done? Because that is how I do it. On next disable/enable VM, file gets recreated again. By the way, I am still getting that. I run multiple unraid servers, and I am getting that on more of them. Basically when I disable VM service because I need to change something in settings, or when I reboot server for whatever reason, there is 50/50 chance that VMs won't work. Not sure what it really is related to, when I check libvirt logs, there are messages related to USB devices, how they could not be attached or something. But since I wasn't able to figure it out, I stopped bothering much. I just back up VM XML, and on next libvirt file creation, I just recreate VMs.
-
Coming here for help. I am trying to set up nextcloud-aio. I am using local DNS server (pihole) to resolve internal IP internally. I have added "--dns x.x.x.x" into extra parameters for mastercontainer, however this does not seem to be populating to other containers. As a result, apache container resolves my public IP, which is not working for me locally (can't do hairpin NAT, and I can't access my public IP from inside LAN). These sub containers don't allow to set DNS for each. So I am trying to find a way how to force it to use specific DNS server for name resolution.
-
Thanks. I managed to get it resolved, but your lead that USB is being passed to VM was valuable lead.
-
Thank you all for quick responses. I managed to find the issue - what was causing it, not the reason. It happened to me in the past when Unraid was not shut down cleanly, that my libvirt image would get corrupted. I tried backing it up daily in the past, but that did not help - when it got corrupted, regardless if I stopped VM, restored libvirt.img from backup, it just did not work. So instead i backed up xml for each VM (when you edit VM and switch to XML view, I copied the output). Seems something must have changed that caused device mappings to change. When I restored VM from XML, I had at least 2 USB devices listed that were "unknown". I did not attach any of them to VM in VM's settings, yet when I started VM restored from XML, it went nuts. So instead of doing that, I manually recreated all my VMs (I have some dependencies on various network cards, mac addresses, so it is bit of work). Anyhow, other things got messed up too (this is outside of this topic, but maybe someone finds it useful). I was using macvlan for docker despite few changes recently that actually recommended to change back to ipvlan. I did not have issues with macvlan, and i had several reboots recently and everything just worked. Today, after this "catastrophy", I figured that docker to docker access does not work anymore either despite having all settings set to allow that. I had to change to ipvlan and it started to work. Can't explain why all of sudden today, it stopped liking it. Also, all of my dockers were listed as stopped, and i could not start any of them (something like "container not found" error on start). I had to force update everyone (except for those using host/bridge access) (or would need to delete docker.img and reinstall all apps from previous apps) and then it could be started. Maybe server got a huge "kick" today and started disliking lot of things. But I managed to get if up and running. Again, thank you all.
-
there is nothing under /etc/libvirt I have not changed anything, just rebooted the server and this happened. Not aware of any USB mappings in vm itself. I guess I would need to remove libvirt image and try from scratch there.
-
OK this is strange, i have cleared all mappings from both patg and config. root@Tower:/tmp/usb_manager/config# ls remote_usbip.cfg usb_manager.cfg vm_mappings.cfg root@Tower:/tmp/usb_manager/config# more vm_mappings.cfg ******** vm_mappings.cfg: Not a text file ******** root@Tower:/tmp/usb_manager/config# root@Tower:/boot/config/plugins/usb_manager# ls packages/ remote_usbip.cfg usb_manager.cfg v2 vm_mappings.cfg vm_mappings.cfg.backup root@Tower:/boot/config/plugins/usb_manager# more vm_mappings.cfg ******** vm_mappings.cfg: Not a text file ******** root@Tower:/boot/config/plugins/usb_manager# As soon as i start array and VM gets started, unraid flash is passed to VM I can't go to VM settings to check it, as it does not show up after array start. Any ideas how to get out of this loop?

-
i am not sure I understand what you mean. Could you elaborate?
-
Is there a way to clear all mappings? I am having strange issue after I replaced one of array drives. When array is stopped and VM/Docker is not running, and I look at USB tab, all ports seem correct (eg. devices that are supposed to be passed to one VM are marked with that VM, and unraid flash drive is marked as unraid flash drive). But once I start VM service, unraid flash drive gets passed to the VM and I am done at that point, my only chance is to go and reboot and start over. I can't figure this out. I am getting typical "usb corrupted" message as soon as USB gets passed to the VM. edit: I tried renaming vm_mappings.cfg (or similar) under /boot/config/plugins and reinstalled USB manager plugin, then my historical mappings were gone, so I thought it would help, but as soon as I started VM service, 2 of my USB devices got mapped to VM automatically, unraid flash included.
-
Right. But the problem I have is that all USB mappings under USB seem OK. However as soon as I start VM service, flash drive gets passed to the VM. And once that happens, I am unable to enter docker/vm settings. My only chance then is to reboot the server and start again from scratch.
-
you are indeed right. I am using USB manager and for some reason, all devices are OK before i start they array (meaning my flash drive is marked as flash, cannot be passed on to VM). However as soon as I start the array, USB is passed to the VM. I tried removing USB manager plugin, but it keeps passing the flash drive regardless. Any ideas? I am not passing any USB to any device directly in the VM configuration.
-
Hello. I have been using Unraid reliably until one of my array drives failed. I have replaced it today but after start of unraid and starting the array, I got a message that my USB is corrupted. Files are readable on the USB, but when in unraid, I see nothing under /boot. So I have replaced USB drive temporarily, transferred license but I am still getting the same error. Basically when I reboot and array is stopped, all works, I can install license for new USB drive. However as soon as I start array, USB error pops up. With that, I cannot start docker (I assume it can't read proper config and if I configure it, point it to docker.img and apply, it is not saved). Similar goes for settings - VMs (it is blank after I start array). I am gonna try different USB too, but I feel like this is not USB issue. Any ideas? I tried switching USB port on server, but made no difference. Posting diagnostics as well. tower-diagnostics-20240430-1831.zip
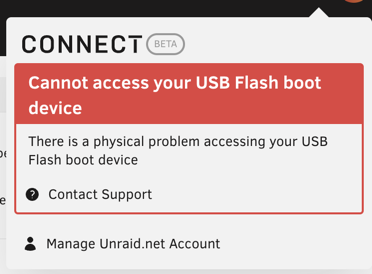
-
I am using "LAN to LAN access" and am routing local networks and peer networks on respective routers. Everything works between the networks. However, when i originate connections from unraid itself to remote side, it would always use wg0 IP of unraid server and not eth0 IP. This is causing me some headaches on the remote end. Can I somehow force unraid to use eth0 IP (or br0 in this case) and just use wg0 for tunnelled communication?
-
Seems like i found my issue - one of my cache drives in pool (Samsung 870 QVO) is having issues which results in very low and unstable read/write speeds. Initally I removed the pool and kept only Samsung as cache. Performance was ever worse. Then I changed cache drive to Apacer AS350 only, and it is flying now. It is still covered by warranty so I am going to submit it back to seller under warranty.
-
I am starting to suspecting my cache or something around it. I downloaded diskspeed - not to test disks, just to compare how long does it take to install it. On my other server, it takes 26 seconds. On this one here, 2:30 (2 minutes, 30 seconds). While downloading is comparably fast, it is extracting that takes long. Also, while it is ongoing, I am unable to open unraid in other tab - it just loads, like it is busy. I would rule out pc/cpu etc. as this has been replaced. But disks are the same.
-
I came here to seek for advice. I went through other threads on slow/sluggish performance, but I could not find anything useful. I was running Unraid on HP Proliant server with Sandisk USB flash drive, and it was slow especially when doing things such as downloading/updating dockers, where you would spend ages on the screen showing progress. Or when installing MariaDB for instance, initial run took like 5 minutes. Same with some other dockers (nextcloud). I recently moved to new server (Intel® Core™ i5-14500, 64GB of RAM, disks stayed the same, but I have replaced my flash drive) hoping for improvement, but there is no difference. I maintain few other servers that are "worse" specs-wise, so I know this is not common thing. I would appreciate any suggestion. tower-diagnostics-20240304-1456.zip
-
Is there anyone who is successfully using collabora code in a docker? I am on Nextcloud hub 6 (27.0.1) and latest Collabora Code docker. All my dockers are in br0, with IPs on the same subnet. I am using NGINX Proxy Manager. I have created proxy host for nextcloud.* that points to my nextcloud. I have created the same for office.* that points to https://IP_OF_COLLABORA:DOCKER port 9980 with websockets enabled, and even with some additional config I found on some sites: # static files location ^~ /browser { proxy_pass $forward_scheme://$server:$port; proxy_set_header Host $http_host; } # WOPI discovery URL location ^~ /hosting/discovery { proxy_pass $forward_scheme://$server:$port; proxy_set_header Host $http_host; } # main websocket location ~ ^/cool/(.*)/ws$ { proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_http_version 1.1; proxy_pass $forward_scheme://$server:$port; proxy_set_header Host $http_host; proxy_read_timeout 36000s; } # download, presentation and image upload location ~ ^/cool { proxy_pass $forward_scheme://$server:$port; proxy_set_header Host $http_host; } # Admin Console websocket location ^~ /cool/adminws { proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_http_version 1.1; proxy_pass $forward_scheme://$server:$port; proxy_set_header Host $http_host; proxy_read_timeout 36000s; } My dockers can talk to each other, and I pointed nextcloud to use https://office.* (without port, as port is handled by NPM) and nextcloud can connect to the collabora server. However when I create document and try to open it, it fails after maybe 10 seconds with: Honestly, I am not even sure which logs matter at this point. Here is latest what I see in collabora docker: wsd-00001-00047 2023-09-20 22:00:10.390097 +0200 [ docbroker_002 ] ERR loading document exception: WOPI::CheckFileInfo failed: | wsd/DocumentBroker.cpp:2610 wsd-00001-00047 2023-09-20 22:00:10.390111 +0200 [ docbroker_002 ] ERR Failed to add session to [https%3A%2F%2Fnextcloud.*%3A443%2Findex.php%2Fapps%2Frichdocuments%2Fwopi%2Ffiles%2F871848_instanceid] with URI [https://nextcloud.*/index.php/apps/richdocuments/wopi/files/871848_instanceid?access_token=Q8BemIu9osHPNyQCq3ikA4xFXTQKncL7&access_token_ttl=0&permission=edit]: WOPI::CheckFileInfo failed: | wsd/DocumentBroker.cpp:2572 wsd-00001-00047 2023-09-20 22:00:10.390120 +0200 [ docbroker_002 ] ERR Storage error while starting session on https%3A%2F%2Fnextcloud.*%3A443%2Findex.php%2Fapps%2Frichdocuments%2Fwopi%2Ffiles%2F871848_instanceid for socket #18. Terminating connection. Error: WOPI::CheckFileInfo failed: | wsd/COOLWSD.cpp:5052 wsd-00001-00047 2023-09-20 22:00:10.394410 +0200 [ docbroker_002 ] ERR #24: Read failed, have 0 buffered bytes (ECONNRESET: Connection reset by peer)| net/Socket.hpp:1122 wsd-00001-00047 2023-09-20 22:00:10.394428 +0200 [ docbroker_002 ] WRN #24: Unassociated Kit (46) disconnected unexpectedly| wsd/COOLWSD.cpp:3491 frk-00038-00038 2023-09-20 22:00:10.404696 +0200 [ forkit ] WRN The systemplate directory [/opt/cool/systemplate] is read-only, and at least [/opt/cool/systemplate//etc/hosts] is out-of-date. Will have to copy sysTemplate to jails. To restore optimal performance, make sure the files in [/opt/cool/systemplate/etc] are up-to-date.| common/JailUtil.cpp:524 sh: 1: /usr/bin/coolmount: Operation not permitted sh: 1: /usr/bin/coolmount: Operation not permitted sh: 1: /usr/bin/coolmount: Operation not permitted wsd-00001-00055 2023-09-20 22:00:10.563226 +0200 [ docbroker_003 ] WRN #29: Failed to verify the certificate of [nextcloud.*]| net/SslSocket.hpp:252 wsd-00001-00055 2023-09-20 22:00:10.563294 +0200 [ docbroker_003 ] ERR WOPI::CheckFileInfo failed for URI [https://nextcloud.*/index.php/apps/richdocuments/wopi/files/871848_instanceid?access_token=Q8BemIu9osHPNyQCq3ikA4xFXTQKncL7&access_token_ttl=0&permission=edit]: 0 (Unknown) . Headers: Body: []| wsd/Storage.cpp:708 wsd-00001-00055 2023-09-20 22:00:10.563320 +0200 [ docbroker_003 ] ERR loading document exception: WOPI::CheckFileInfo failed: | wsd/DocumentBroker.cpp:2610 wsd-00001-00055 2023-09-20 22:00:10.563327 +0200 [ docbroker_003 ] ERR Failed to add session to [https%3A%2F%2Fnextcloud.*%3A443%2Findex.php%2Fapps%2Frichdocuments%2Fwopi%2Ffiles%2F871848_instanceid] with URI [https://nextcloud.*/index.php/apps/richdocuments/wopi/files/871848_instanceid?access_token=Q8BemIu9osHPNyQCq3ikA4xFXTQKncL7&access_token_ttl=0&permission=edit]: WOPI::CheckFileInfo failed: | wsd/DocumentBroker.cpp:2572 wsd-00001-00055 2023-09-20 22:00:10.563333 +0200 [ docbroker_003 ] ERR Storage error while starting session on https%3A%2F%2Fnextcloud.*%3A443%2Findex.php%2Fapps%2Frichdocuments%2Fwopi%2Ffiles%2F871848_instanceid for socket #24. Terminating connection. Error: WOPI::CheckFileInfo failed: | wsd/COOLWSD.cpp:5052 wsd-00001-00055 2023-09-20 22:00:10.567161 +0200 [ docbroker_003 ] ERR #18: Read failed, have 0 buffered bytes (ECONNRESET: Connection reset by peer)| net/Socket.hpp:1122 wsd-00001-00055 2023-09-20 22:00:10.567170 +0200 [ docbroker_003 ] WRN #18: Unassociated Kit (54) disconnected unexpectedly| wsd/COOLWSD.cpp:3491 frk-00038-00038 2023-09-20 22:00:10.576432 +0200 [ forkit ] WRN The systemplate directory [/opt/cool/systemplate] is read-only, and at least [/opt/cool/systemplate//etc/hosts] is out-of-date. Will have to copy sysTemplate to jails. To restore optimal performance, make sure the files in [/opt/cool/systemplate/etc] are up-to-date.| common/JailUtil.cpp:524 sh: 1: /usr/bin/coolmount: Operation not permitted sh: 1: /usr/bin/coolmount: Operation not permitted sh: 1: /usr/bin/coolmount: Operation not permitted When I open developer console in Chrome, I am getting this: Can anyone advise? // edit I was able to resolve my issue. Spaceinvader's video pointed me in the right direction. I use pihole and internally, for nextcloud.* I resolve local IP of my reverse proxy. Same for collabora (office.*). In nextcloud's docker, I use extra parameter to use pihole proxy (by default, servers on my server segment don't get pihole proxy) and that allows nextcloud to resolve locally collabora's IP. Since Spaceinvader mentioned that both collabora and nextcloud need to be able to resolve each other, I tried to add the same extra parameter to collabora's docker. Otherwise, if collabora was to resolve it, it would resolve public IP. And voila - it works now.
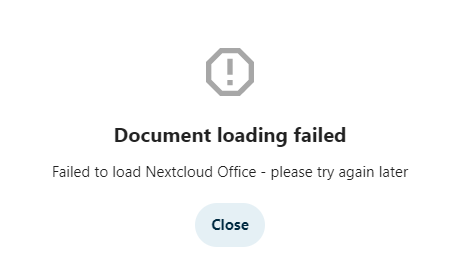
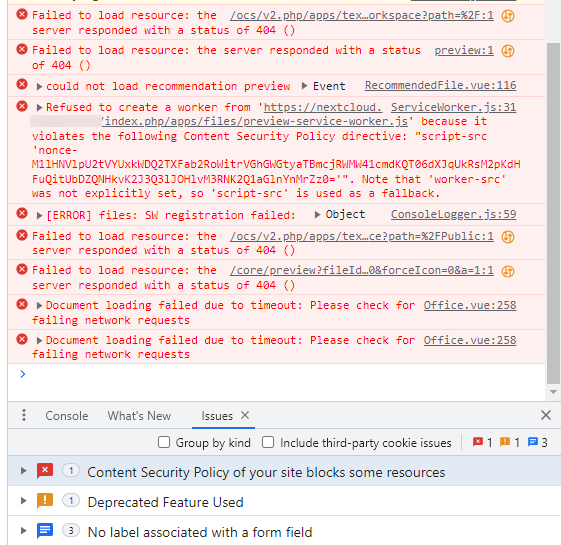
-
So this is still "an issue". From time to time (don't know why yet), when my server goes down unexpectedly, my libvirt image gets corrupted. I recreate it, but after that, I need to reinstall USB manager as devices no longer auto-attach after VM is started. Is there something that can be done about it?
-
Hello. I have had few occasions where libvirt.img got corrupted. Usually when power went out and Unraid did not manage to shut down cleanly. Last night I had power outage, this time it looks like it shut down cleanly. However I faced this issue again. Attached is my diagnoatics, appreciate if someone could advise what is going on. tower-zohor-diagnostics-20230829-1121.zip
-
Well, I did not uninstall it nor installed it. It has been the same server running from the same USB drive. If it gets created only with plugin install, it would be normal to not re-create it. But I was thinking - if it can't be recreated when plugin has something to auto-attach and it cannot do so, at least be notified that this is missing. I realize not many would have this issue like I did... but just in case.






