




WoRie
Members
-
Joined
-
Last visited
Everything posted by WoRie
-
So simply switching the tag from 2.3.2 to latest or 3.0.2 for the repository will not result in a working setup i guess? I'm just planning to upgrade my 7.4 cluster to 8 and thought about updating pbs as well, as i'm unsure whether the new pve version will work with the older pbs server
-
After some initial issues with the setup in the beginning, this has been running flawless so far. Thanks for the great work! Are there any plans to update the package to PBS 3?
-
Hi, after wasting a quarter of a year due to a broken GPU and subsequent issues due to this, I replaced the GPU (RTX 4090, water cooled) and was finally able to use the VM as intended. I passed through 32 of the 64 gigs of my RAM, and all but one core/HT core from my xeon CPU. Everything is running fine, even for several hours, even with breaks in between sessions for several hours. I can either connect completly local with an HDMI cable connected to the passedthrough GPU as if I weren't running everything through virtualization in Unraid, or through parsec. However, if I don't shut down the vm and leave it idling for longer periods, say over night for example, I come back to my system running all passed through CPU cores on 100% and the VM unresponsive. I then have to hard shutdown the vm through unraid (which works fine), my CPU usage drops back down to normal values. I can then reboot the VM and use it as before, no issues whatsoever. The event viewer in windows only shows an error, that windows was shut down unexpectedly the last time, but nothing else in the period where the crash would have occured. The most recent one was at 02:03 in the morning, where I was fast asleep. Any idea where I could start the trouble shooting? Diags are attached. wonas-diagnostics-20230824-0928.zip
-
Hi, I have 5 80mm Arctic 4 pin PWM fans installed, all connected to my MB. 2 of the 5 are connected in series but then to the mb, the last one in the screenshot is a smaller noctua fan. I set all low temp / high temp points for the disks and minimal PWM values. The values are being displayed in the bottom bar of Unraid. However, some show up as 0% duty cycle, while others correctly display the current level. I hit detect on each of the controllers again and adjusted all points, but the results are the same. Any idea what the problem is? Also, can I rename these fans somehow. It's hard to remember, which fan cools which part.

-
disk 5 had problems negotiating a link, even with new cables. Now after some up and down the array is up. disk 10 reports as being emulated and i only can perform a read check but no rebuild of disk 10... I think if i will be able to restore the array in full, i immediatly should move all files from these old disks, some from 2011 to the newer 18tb drives... Can I rebuild disk10 which currently appears empty in the array or should I wipe it and readd it? wonas-diagnostics-20230625-1811.zip
-
Here you go. Started the array in maintenance with new cables fresh out the box. wonas-diagnostics-20230625-1733.zip
-
Both disks completed the extend test without error. wonas-diagnostics-20230625-1128.zip
-
I changed disk10 to xfs and started the array. Disk10 shows as unsupported file system. I don't know about the read errors. When the hba became instable I saw reported write errors, than cleaned up after an reboot. wonas-diagnostics-20230623-2212.zip
-
Here are the new diagnostics. How would I go about rebuilding disk10 now, if (hopefully) everything is fine again? wonas-diagnostics-20230623-1834.zip
-
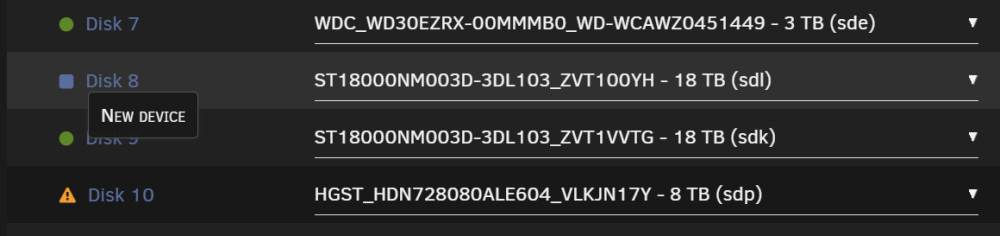
Yes, Disk8 suddendly showed up as dead. How can I force it back into the array? I believe parity should still be valid and the disks should be fine. The issue was the HBA. In my old case it was directly cooled through a case fan that was near it, in the new case this fan is missing and it was 30° C the last few days. I believe that was the culprit and the HBA died. I zip tied a small Noctua to the new HBA to be safe in the future
-
I know, thats why I'm a bit scared It's showing up as new. The data on it is still accessible when mounted through unassigned devices, but I cannot reintroduce it into the array like this. And I also can't check the filesystem, because if i assign both, I cannot start the array due to 2 missing/new disks with single parity.
-
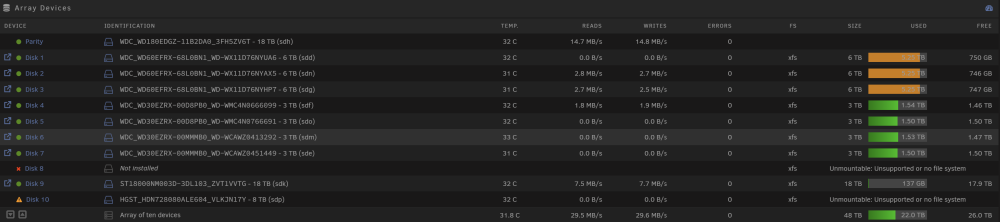
There you are. I've just installed a new HBA, it says Data Rebuild but the two discs affected by the outage show up as unmountable wonas-diagnostics-20230623-1637.zip
-
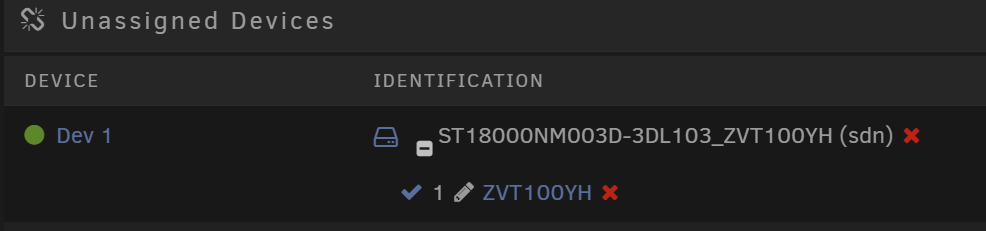
Hi JorgeB, so, i think I f*cked up... I pulled the HBA and repasted the heatspreader on the chip. The old thermal compound was completely dry, solid and oozed a solidified liquid that looked like treesap. After reassembling, i booted unraid and started the rebuild of disk 10 (as referred in the screenshot). During this, the connection broke down again. I believe the card is toast and dies when getting too warm (it's pretty warm here the last few days), even with new thermal compound and a directly attached fan. The issue now is, that the rebuild of disk 10 hasn't finished and disk 8 showed also suddenly as "disabled - content emulated." And this is where I made a mistake I think... I stopped the array, set the failed disk 8 to "disabled", started the array in maintenance, stopped it again and tried reassigning the disk to slot 8. But now it shows as a new device... I can power up the array only when i set disk 8 to unassigned, otherwise too many disks are missing / changed. I don't want to carry on with the rebuild of disk 10 with this shot HBA, a new one should arrive tomorrow. However, will I be able to fix this situation at all and what would be the best course of action? Will I be able to correctly reassign disk 8 after disk 10 has been rebuilt, or is the data on disk 8 gone and I have to add it as a new device? The partition is still there in unassigned devices and my array is only 30% full, so if I can save the files somehow, that would be great. The files are not irreplacable, but nevertheless would be a hassle to aquire again.
-
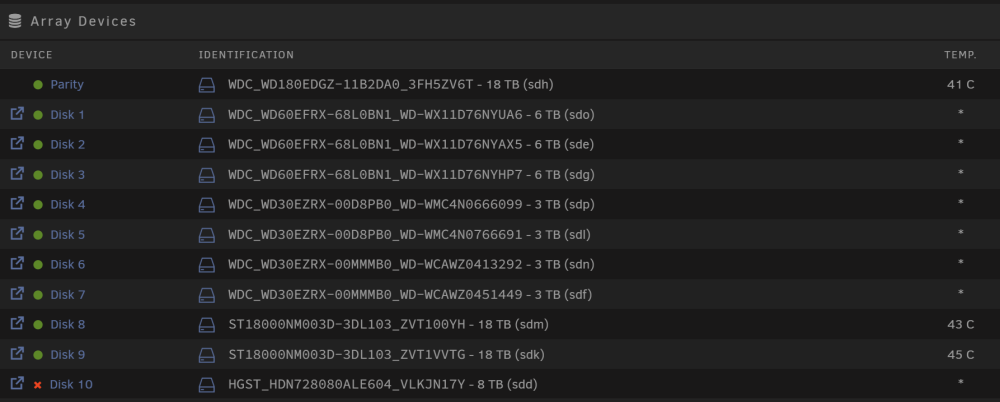
there you are. I've since disabled anything APSM related in the BIOS. But now again all disks are spun down and won't come up again. wonas-diagnostics-20230619-2019.zip
-
Hi I ran the 6.12 rc5 before updating to the final and I now encounter errors with my lsi 9300 hba. If everything is freshly booted and spun up, all is fine. However, when disks spin down, the gui still shows a green dot for the disks connected to the hba, while the ones connected to my mainboard sata controller have the correct grey dot. This wouldn't bother me, but the hba disks also suddenly report read errors after some time, which again are fixed after rebooting the host until the disks enter standby. Could this be due to power management of the pci e devices? Or is my hba on the way out?
-
I somehow can't save any settings. Whenever I change something and hit "apply" a new tab opens with update.php which is blank and nothing is being saved. Any ideas?
-
Out of the blue, the VM seized to work twice already. Adding the Virtio as primary, passed through as secondary let me boot again. And after shutting down the vm, removing the virtio and setting the passed through as primary, the vm works for some time and through some restarts until it breaks again. If I can provide any logs that could help, please let me know.
-
So, I just had to reset the GPU setup again. The VM wouldn't boot, switching to the virtio gpu and passedthrough as secondary let me boot into windows, with the NIC again switching to DHCP. Shutting down the vm, removing the virtio and switching to the passedthrough GPU works as well. But this is really not something that I would describe as "user friendly" or "rock solid".
-
Great to hear, that I'm not alone in this, even if there is no solution so far. Concerning your question: I passed through an RTX 4090, so the difference in framerate was noticable I've sinced narrowed down a process to fix the vm: - Set primary display as VNC, secondary as your GPU. Save the settings - Edit the vm config again, switch to xml mode and lookup the qxl string which denotes the VNC virtual gpu. Make sure that the bus used is 0x00 and not something else. If it is something else, change it to 0x00 and save. If a message comes up that the slot is already in use, change the corresponding value until you can save and exit. - Upon booting the VM, you should have video out through VNC - Inside windows, it is as if the hardware subsys detects all hardware anew (again pertaining to my guess, that the hardware setup changes somehow in between). After everything is done, the GPU should again show up in device manager (along the qxl gpu, which you can throw out afterwards) And at least for me, afterwards everything worked as it should. Something else I tried was to delete the VM (but not the disks) and create a new one, referencing the original disk. Then I was also able to change the machine type to i440fx. So far, this also worked. We'll see how long until suddenly everything breaks again. I don't know if a future unraid version with a newer kernel would work better, since in kernel 5.19 or 6.x, hardware passthrough should be more stable (at least that is what I read in the proxmox changelog).
-
So, to update on this: - "The guest has not initilalized the display (yet)" error went away, after I reset my bios to defaults and disabled Reziable BAR. Afterwards everything worked, even without VFIO binding, syslinux parameter and without multifunction. I could reinstall the VM, add the graphics and even played some games yesterday. Even after cold booting my unraid box with the vm, it still worked fine afterwards. However, I just booted my unraid box again, booted the VM and had normal video output. So everything fine and same as yesterday. I forgot to passthrough my mouse and keyboard to the vm, so I shut it down through unraid, changed the VM settings and added the mouse and keyboard. And now everything is fubar again The VM won't boot at all, mouse/keyboard present or not. Cold reboot of the box also didn't help. Changing the machine type from q35 v7.1 down to 7.0 lets the VM boot, but again with a new NIC, therefore a new IP and no passed through GPU. Going back to v7.1 and the vm won't boot at all. So it is, as if the whole hardware subsystem gets messed up. I don't understand why the NIC doesn't persist. It's virtio, but with the same MAC adress in all instances. Therefore windows should normally assign the same IP config inside the VM. But to windows, it's as if I installed a new NIC. Therefore I guess, that the hardware config is not persistent somehow and in the process, passthrough seizes to work. Do you have any further ideas, where I could look? If I setup the win 11 vm with i440fx, I can't proceed through setup because the requirements for win 11 are not met.
-
Ok, now it's somehow even worse... As stated, I added the entry in syslinux, I bound the GPU to VFIO (and rebooted of course), I added the "multifunction='on' part to the xml file and hit update and I even extracted the vbios (150kb in size, so should be valid) from the card. Extracting the vbios with Spaceinvaderones script was only possible when the card was not bound to VFIO btw. But now, as soon as I add the card to the vm, either as primary or as secondary, the VNC console will just show "The guest has not initialized the display (yet)" and as far as I can tell, the VM won't boot. No IP is being assigned. Do I need to mess with unsafe interrupts and ACS overrides? I already tried both settings and each individually, sadly to no avail. There is a new GPU in the mail, but it is the same chipset, although a different vendor.
-
Hi @ghost82 thanks for the swift response! I've now added the parameter to syslinux, I also set my boot vga to the internal one resulting in the following log entries (00:02.0 being the iGPU, 01:00.0 being the nvidia GPU, and 05:00.0 being the BMC/IPMI GPU) root@WoNas:~# dmesg | grep vgaarb [ 0.798180] pci 0000:00:02.0: vgaarb: setting as boot VGA device [ 0.798180] pci 0000:00:02.0: vgaarb: bridge control possible [ 0.798180] pci 0000:00:02.0: vgaarb: VGA device added: decodes=io+mem,owns=io+mem,locks=none [ 0.798180] pci 0000:01:00.0: vgaarb: bridge control possible [ 0.798180] pci 0000:01:00.0: vgaarb: VGA device added: decodes=io+mem,owns=none,locks=none [ 0.798180] pci 0000:05:00.0: vgaarb: setting as boot VGA device (overriding previous) [ 0.798180] pci 0000:05:00.0: vgaarb: bridge control possible [ 0.798180] pci 0000:05:00.0: vgaarb: VGA device added: decodes=io+mem,owns=io+mem,locks=none [ 0.798180] vgaarb: loaded [ 36.494784] vfio-pci 0000:01:00.0: vgaarb: changed VGA decodes: olddecodes=io+mem,decodes=io+mem:owns=none [ 37.046855] i915 0000:00:02.0: vgaarb: changed VGA decodes: olddecodes=io+mem,decodes=none:owns=io+mem [ 37.046859] vfio-pci 0000:01:00.0: vgaarb: changed VGA decodes: olddecodes=io+mem,decodes=io+mem:owns=none With this, do I still need to add a vbios? I've also added the "multifunction='on'" The VM will still not boot. I'll try to reinstall it again, dump the bios and then see, if these settings did the trick. Thanks again for your help!
-
Hi, I've set up (multiple times now) a win 11 gaming vm, and passed through an Nvidia GPU. During initial setup, everything works fine, even through restarts of the VM or host. However, after shutting down unraid completly and starting up afterwards, I have the following issues - The VM won't come up at all. The logs show no issues, the status "started" but I can't connect or see any display output. The (installed) guest agent reports no IP - After some forced reboots, the guest agent suddenly reports a new IP (while being set to static inside VM). Upon RDPing, a new network is detected inside the vm, the IP being again assigned by DHCP. Also, the GPU is missing from the VM completly. Everything else seems to work fine. Any ideas, what is happening here? I've already set up this same VM 3 times. Today upon booting up my NAS again, everything is broken again. As far as I can tell, the logs show no issues. wonas-diagnostics-20230208-1056.zip
-
I've bought it on steam when I got my steamdeck and also own it on XBOX.
-
I had no other options selected for launch options adding "--launcher-skip" to the launch options will start the game with my nvidia gpu being used. However, the REDLauncher is not working. I've tried several different proton versions to no avail. I really need the launcher, since I play on XBOX and my Steamdeck. Without the launcher, there is no cloud saving. Witcher 3 uses the same system and I wanted to play this next. For the time being, I can passthrough the GPU to a Windows VM and make it work, but not tying my GPU to one single VM would be preferred. Maybe @Josh.5 has another idea what to do about that stupid launcher app?





