mathomas3
Members
-
Joined
-
Last visited
Everything posted by mathomas3
-
good thing you did... I have never had good luck with WD red/green/black drives or any SATA drive... I have around 10 of them that failed over the 3 years I used them... Since switching to SAS drives I have had 2 failures in 7 years... and they are used ones at that(currently 20 of them are spinning)
-
I have this exact same case and I maxed out the number of drives that you could place in it... I ended up going with a 1200 Watt Corsair PSU only difference being that I had a GPU in it... Mine might have been overkill though, but I am building a new system with it. 2x Epyc CPUs 6900xt GPU and water cooling... The cables that came with it were long enough
-
Hello, I am seeking some advise as to a backup solution. I would like to a tape based system if that would make any sense but from the prices that I have seen for hardware it kinda scares me. I have roughly 130tb of data that I would like to have an extra copy of should something go south on me and looking at the LTO specs I would like to stay with LTO7 or LTO8. Is anyone doing this here? What hardware are you using? How do you go about organizing you tapes? Thanks in advance, Mat
-
Someone done something like this before? Are there somethings I should consider per UnRaid and Epyc CPUs?
-
so you are building parity again... and wiping away the failed disk... sorry that's happening... by chance what WATTs is your PSU? A long time ago I had issue in a build and it wasnt till I went OVERKILL on one PSU 1200 watts for 10 hdds... that I didnt encounter issues again... Im about to use that PSU again on a new build(psu 10 years old now) hoping all works well... we will see
-
Google to the rescue
-
Hello all, I am considering a new build in an old case... I Define 7... I have already bought a dual AMD CPU epyc MOBO+CPU combo to include 256g RAM and a 6900GT(xt?) GPU... and I plan on water cooling the whole thing... a mix of parts that I already have My current server setup has 136tb Pool across 19 disks(2 parity), that I would like to mirror on this rig... I mostly have 8tb drives with a few 14tb drives(I can get more) This new build(OG server build) I would like to make this my main rig... Run Unraid (as a backup array for the main system) and to host a VM (where I would conduct my work from) via the 6900xt(play some games with my son) There is alot to consider here... Can this be done? is it wise? again I have not used Epyc CPUs before... nor have I tried using unraid for hardware passthough(vmware term) via unraid to a VM to a physical GPU... There are a number of unknowns... but I have a few weeks to figure this out while I wait for parts... and figure out(fit) hard line water cooling lines... What have I gotten myself into
-
I was able to apply the update by forcing it... seems like this issue isnt caused by the docker... hoping that others will read this and follow suit... im sure there are others
-
server level update? I am on the latest unraid version... the current status of this docker has been the same for 4-6 months now... I think ES was in the same status until recently... This docker has been finicky recently thus I didnt want to change things... now that I am 2 versions behind I am willing to make changes... also I have 100+ unfinished downloads... so...

-
at this point... I think its fair to say that the docker version is dead... I am now two version old vs the new release and docker still shows that there isnt an update... I suggest perhaps rolling a VM to replace the docker... I plan on doing this soon
-
At this low of a price... I would check local craigslist or marketplace... all your looking for is a case/mobo combo that has 3 sata connections on it... nearly anything that you can get your hands on will check that box... even a rasberrypi should be able to handle what you are looking to do (except for the VMs)... I would focus your search for an old workstation that has a xeon processor in it... with DDR4 ram if possible... a Full tower If you can also have a GPU included in the deal, that would be the best possible best of luck
-
ok... if you want to go small... there is a thermaltake case the 304? that houses 8hdds that could be built for around the same cost as this... I have that case now
-
3 hundred bucks on hardware that not expandable... PASS... Your money would be better spent on a 28 bay DAS and a 1u server...
-
Take my advise with a grain of salt... but... I lean the the KISS mentality... Keep It Simple Stupid... While with enough time and effort im sure that you could make your setup work... having a single box do too many things is ill advised... IMO... buying an old workstation with enough SATA connectors/slots and load unraid on it... maybe 50 bucks shipped
-
FYI... there are many people here that would like to help... but given the old version of unraid that you are currently using... I suggest making a backup of your current setup and update the version that you have to current and try booting again... using a current version helps troubleshooting these things
-
good advice here
-
without taking a good look at all the the hardware that you are using... You have tons of free space on your array... I would suggest that you move data to as few disks that you can... your array could live on 3 disks... and build parity... Also... check your SATA connectors... ensure that you have good connections... I currently have 23hhds running on a DAS that has 750 WATT PSU... your PSU should be enough for this setup, thus I dont think the PSU is at fault... are you using a RAID controller in this system?
-
Hello all, Current hardware - Dell r430 - HP DAS 24 bay with 2 HBA?s(two controller cards) I recently updated my server from an old HP ddr3 1u to a dell r430 chassis and while we were trouble shooting the system, it was suggested that I break the multipath(server-hba-hba-server) loops due to UnRaid not supporting this setup... I removed the cable connecting the two HBAs together but kept the server connected to both controllers thus breaking the loop... Since that time, none of the HDDs will spin down devoid of what time it is... I suspect that I will need to remove one of the cables to the Controllers but I would ask that someone confirm that this might be the cause of the HHD spinning 24h... Also I have 3 SSDs that are in the DAS that I would like to move into the r430 chassis... with the HP they were not recognized correctly, thus breaking the cache and app pools... What would be the best steps to attempt this? I suspect that the raid controller on the r430 will be a big reason as to if I can do this... the chassis RAID controller is a LSI MegaRAID SAS-3 3008 Thank you for considering these questions and have a good week/day
-
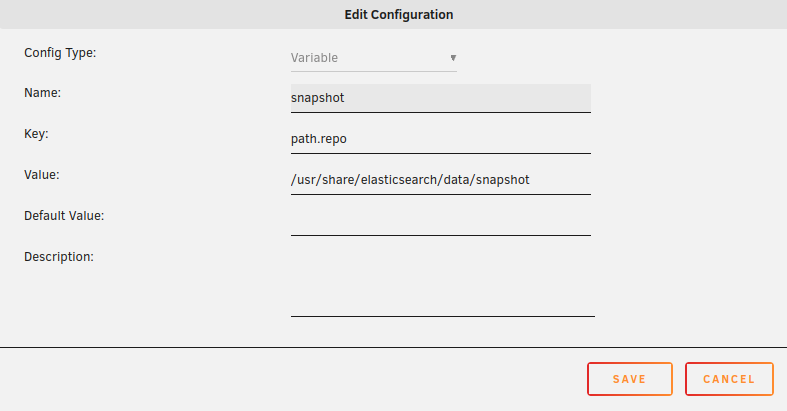
for anyone everyone else... there is a new ES setting that needs to be manually done... here it is
-
I am unable to view logs... I reinstalled the docker as a fresh install... and watched the logs... The last thing that I saw was that it was confirming access to ES and then right after that there are two new lines that flash and the log window closes... and after the docker is stopped... I can not view the logs even after it's stopped... I browsed to the appdata path and there is a single file there... db.sqlite3 file... feels like there should be more files/data there after a fresh install... Feels like this docker is half of what it should be... like it was taken down...I did the force refresh on the main tube archive docker... that was the one that said and update was "not available" which is odd I did change the repo on the redisjson container and that didnt help anything... thus I tried the force update on the main dockerI tried to mimic the advice here... and blew up my entire setup... when I checked for updates for this docker it said there was "not available" in my panic... I forced an update... and blew up the whole thing... it wont start and on a fresh install it dies right away... suggestions?The plugin changes how the Main page displays the Unassigned page... My Dummy Hat was earned today... Thank you dlandonI was looking around a little bit more and noticed that on the Dashboard I have 2 unassigned disks... but the Main page still shows them as MIA... hmmm