




manolodf
Members
-
Joined
-
Last visited
-
Do you know if it would stay put if I would have allowed it to stay as eth0?
-
Just in case it helps I am attaching a new diagnostics few hours after the first one, with a name change even while not using the nic and remaining inactive. tower-diagnostics-20250412-2336.zip
-
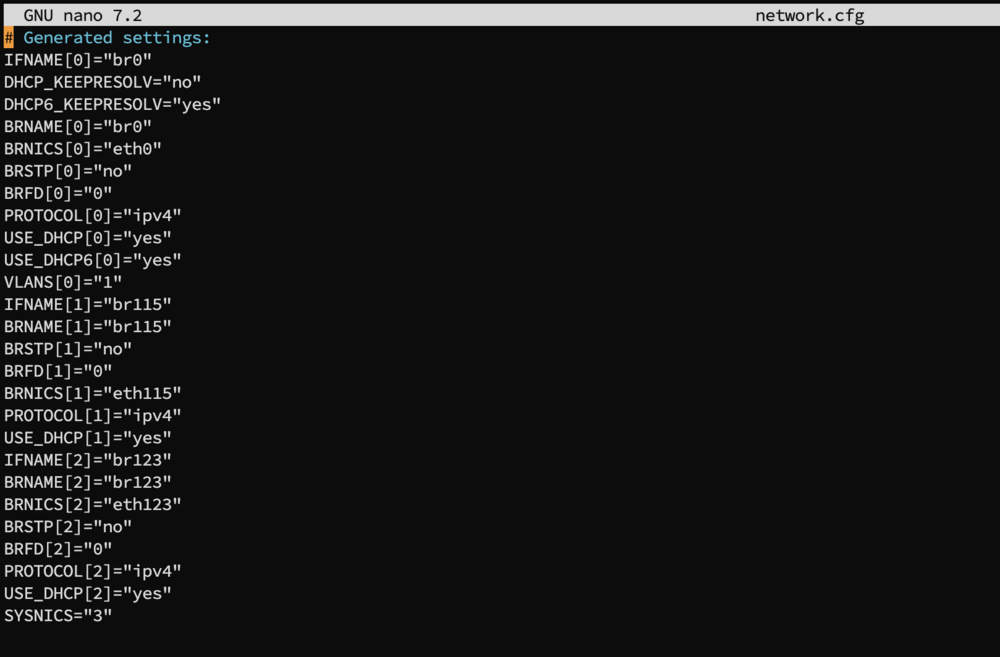
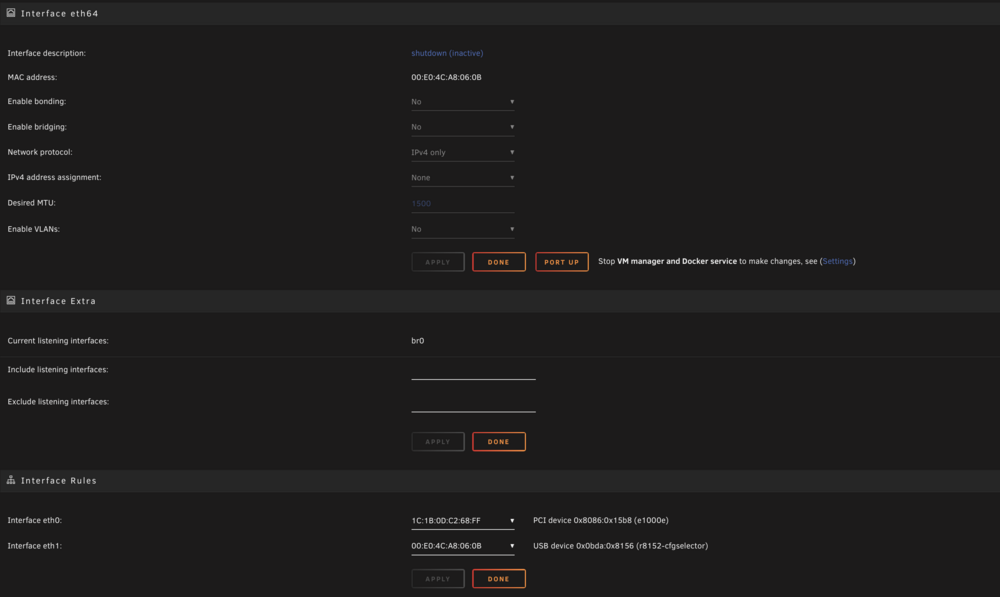
Hi Everyone, Today I added a 2.5G USB Nic Card. Upon first boot after adding the card, Unraid marked it as eth0, and my built in nic as eth1. Easy enough, I went to the Network Settings and set them up how I want them, in the reverse order, where the built in is eth0 and the new usb nic is eth1. I just want to say before I explain further I already removed the /boot/config/network.cfg and network-rules.cfg and rebooted, and the same issue persists. So after rebooting and setting the nics how I want them, my built-in nic is now eth0, awesome! But the new nic that I want to be eth1 so I can make br1, comes in as eth123, I found it strange but decided to just go with it. Created br123, had my VM use it, and it worked... briefly... then while still powered on, the nic changed to eth115, so I went ahead and re-created br115 and thought maybe it was a one time fluke. Well after working for a while, all of this within an hour it had changed to eth69, eth71 without a shutdown/reboot, while powered up and while VMs are actively using it. Then I did notice though not as quick after a few hours eth64 (with the nic now inactive since I had given up) I just want the nic to be eth1, so it can be perpetually br1 so I can pass it on to the VM, and whatever dockers I may wish to assign to that NIC. That was my goal to begin with, but I was defiinitely not expecting it to change names on me continuously. As one can see, the NICs are properly marked with the names they should have: /boot/config/network.cfg shows this, but I have even tried modifying to only have 2 devices and force the eth1 name, but it still ends up adding eth123, eth115 and so on. Even right now, after being at eth71, it went to eth64, its strange For now I have stopped fighting against it and using it, but I would love to have the nic usable and use it as eth1 with br1 to assign to the VM and dockers I wish. I hope this was enough information to diagnose the system. I have not reset my original network settings (static IP) yet after deleting the network.cfg file, but I will once I get everything stabilized. tower-diagnostics-20250412-1729.zip



-
Try forcing version 1.4.0 and see if it works for you, I believe I had the same issue when I updated the docker.
-
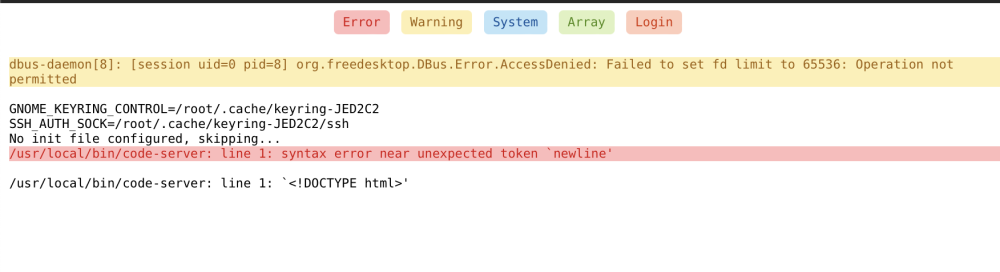
I am also getting this error after updating the docker: Update: I had to force version 1.4.0 for it to boot up. I tried 1.4.1 and also did not work, and Latest:1.4.3 as well did not work
-
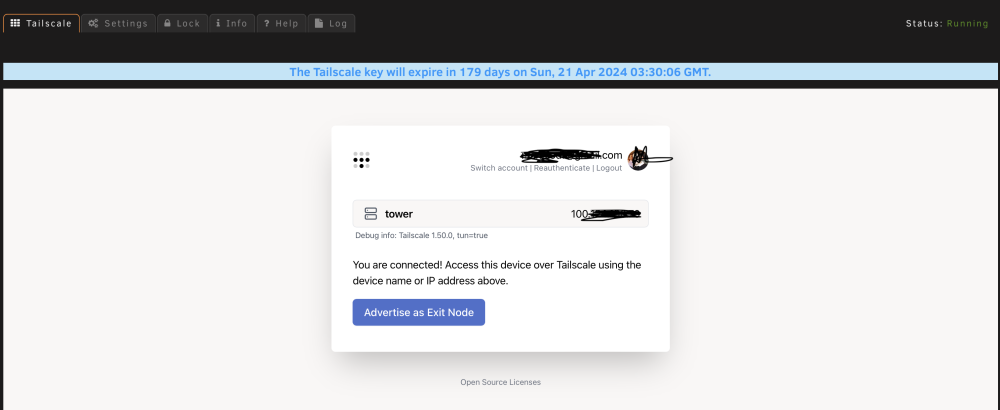
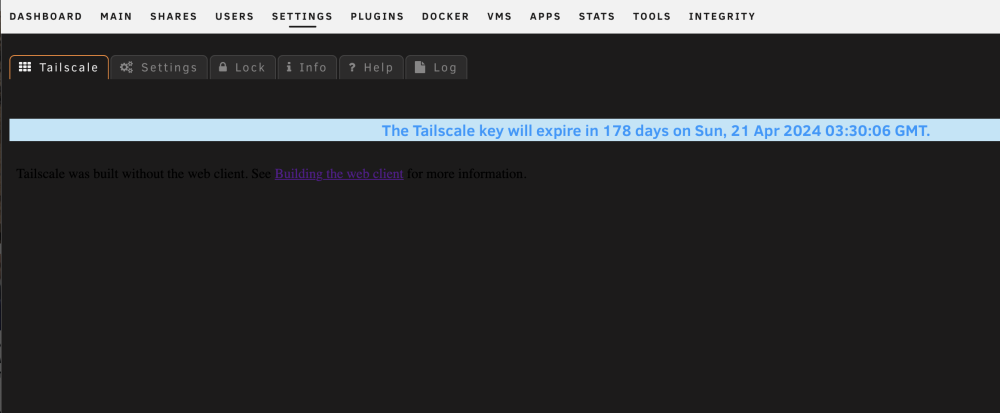
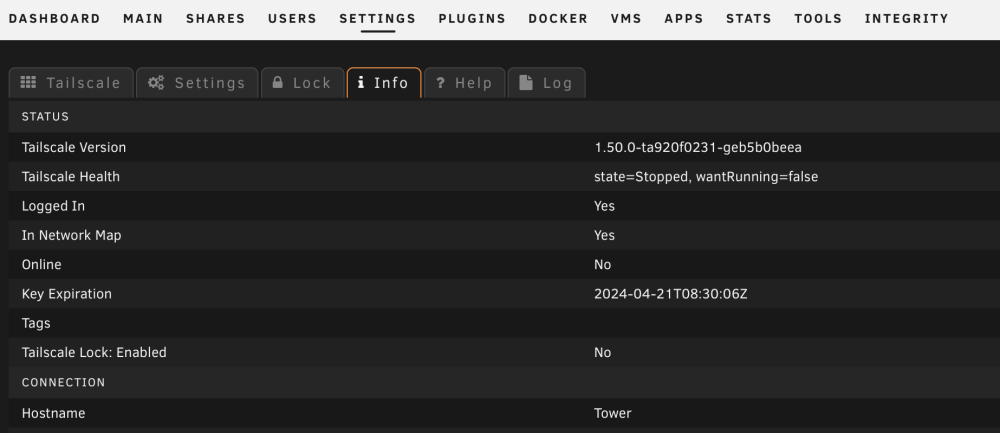
One other thing I notice is in Unraid GUI, when I go to plugin settings, sometimes I see the nice presentation that shows your IP, email, like this: yet sometimes, I would say after a while or most of the time it shows it like this, so one does not have that Advertise as Exit Node Button, or logoff button: Is that normal behavior? Not sure if I can pinpoint when that got triggered, because I even have tailscale down currently.
-
I had to leave the house so I couldn’t risk a tweak but I will continue when I get back. Do you recommend going for the exit node theory out the gate or try the toggles first? I planned on the exit node first, waiting then enabling on webgui if simply enabling did not cause the issue. Then after enabling, having an active session giving each one time to fail. If you have tips on the order I am all ears Sent from my iPhone using Tapatalk
-
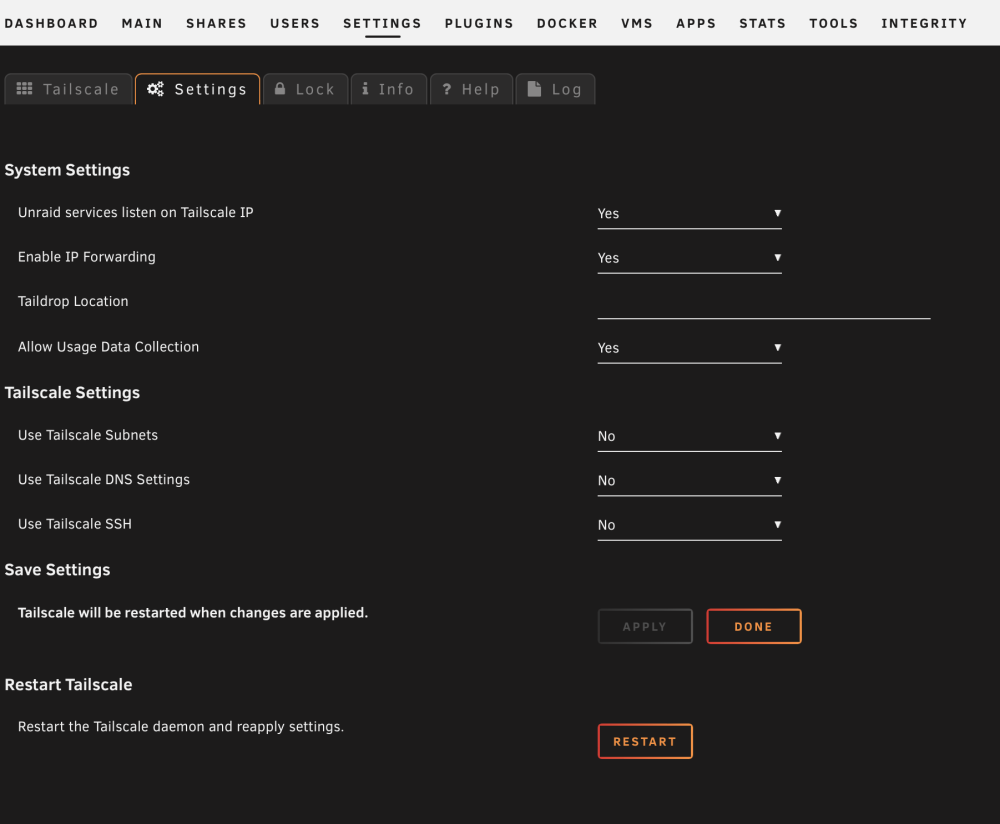
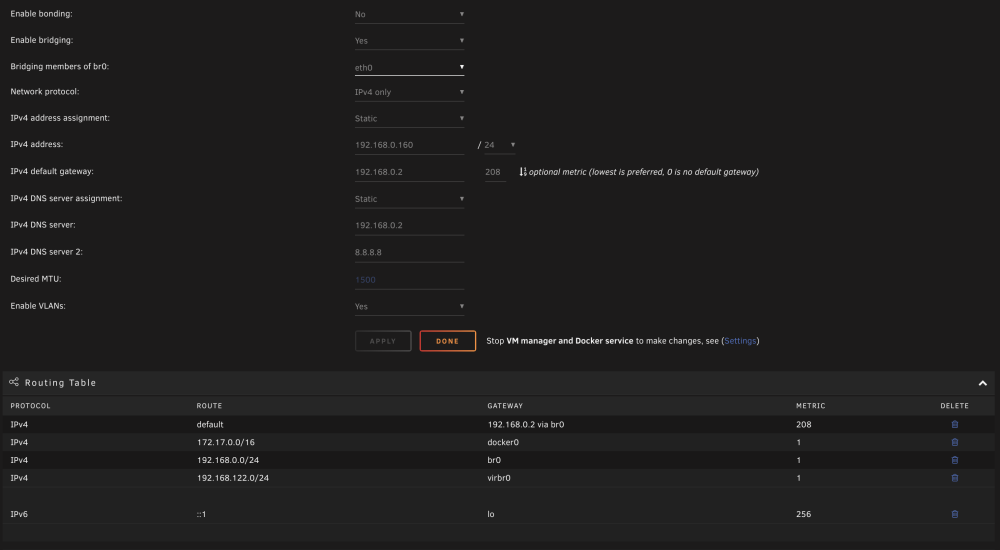
I am on Unraid 6.9.2 and began using the plugin, I followed the directions to advertise subnets (via Terminal ran: tailscale up --accept-routes --advertise-exit-node --advertise-routes=192.168.0.0/24,192.168.1.0/24) , and everything seemed to be working just fine. After leaving it alone and being satisfied with being able to access my local subnet (192.168.0.x) while remotely, and also being able to use my NAS as an exit node, I thought the job was done. What I was not expecting though is that few minutes later all of a sudden my unraid was without internet, i could not access any dockers GUI, access the Unraid GUI, and also my router seemed to not be seeing it online at all. I physically powered down the unraid, then I powered it back up thinking maybe it was an anomaly, sure enough it comes back up, my router sees my unraid, and few minutes later I am able to get into Unraid GUI, and the dockers and VMs come back up. This time a bit more nervous I just wait to see if everything is fine, and sure enough maybe 20 minutes later the same thing happens, the unraid loses all internet from the looks for things (I tried accessing it with hostname, my local IP, via tailscale IP, through tailscale, through local network, all to no avail) So now I am here asking for suggestions, help, or any tips of what could be causing it. Here are my settings: Those were the settings when the issues repeatedly took place. Since then I have just now turned off the exit node, and also set the top two to "No" t see if that changes anything. I also turned off the subnets for now on Tailscale webGUI just in case. Is there anything that stands out that I may ned to change? I have not twaked any of these in a long long time but here are my unraid Network Settings TIA for any help! Update1: With above modifications, turning off the listen on tailscale ip, and forward ip, as well as exit node disabled, and subnets disabled I have about 50min uptime, that is far more than after my reboot. I will try to make one modification per hour and see how I fare to see if I can pinpoint what is causing the crash/loss of internet issue. I also attached diagnostics. Update2: I have advertised subnets back without an issue so I am now able to access my dockers with the local IPs when I am on tailscale. So far the system has been stable. About an hour up. Remaining to test is the exit node, as well as the Tailscale IP and Forward IP settings. Those will come next, and I have a feeling it may be the exit node that was causing the system crash/offline issue. Tower-tailscale-diag-20231024-165630.zip
-
Awesome that got the timezone result! Maybe the ubuntu upgrade is what gave an error when doing "pip3 install requests" that used to work and had to change it. But definitely getting the desired timezone! Thanks!
-
I tried adding the TZ Variable within unraid and applied, and same result, still showing UTC time for me when running python script.

-
I wanted to see if you could help me get my local Unraid Time within code-server, or to set a time. I tried mapping /etc/localtime and that did not seem to work, and the timedatectl did not seem to work also. Is there an argument or parameter I can pass through to assign my timezone so that when testing a python script within code-server it has my correct timezone instead of UTC?
-
Not sure if you have seen the Linuxserver version of code-server. I think that is what the other user was referring to in terms of a password on a splash screen. I just switched to yours because it’s frankly better since I can run all extensions but the password protection would be a bonus Sent from my iPhone using Tapatalk
-
I think he meant when pulling up the GUI to enter a password of some sort like some of the the Open-VSCode ones do. What is the passkey for in the config by the way, I did think that was for some sort of GUI Passcode to be able to access?
-
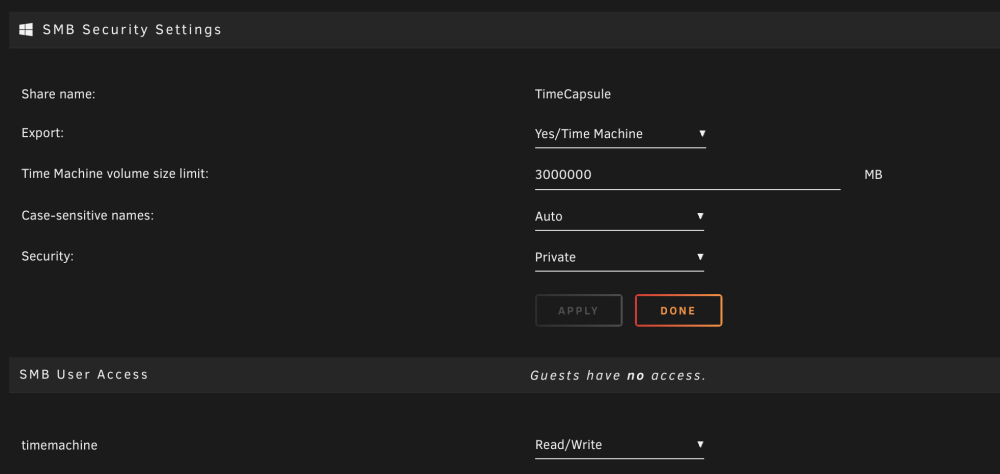
So a bit of an update. I downgraded from 6.10.3 (That broke time machine backups) back to 6.9.2 and my Time Machine went back to working flawlessly on my unraid as it had for about 10 years prior without any need for any docker. I decided to wait a while, so after several months I decided to give 6.11.5 a shot to see if the issues were perhaps resolved. I upgraded yesterday and again the time machine issues came back just like when I upgraded to 6.10.3. I do not want to miss out on new features of Unraid, nor be on an older version for various reasons, but Time Machine backups are super important to me as all my mac devices back up to it as they have since the early years of Unraid.
-
So after downgrading to 6.9.2 from 6.10.3 (Time Machine backups stopped working for me after upgrading to 6.10.3) and having my Time Machine backups work again for a few months I decided to try 6.11.5, and once again the issues arise. I can connect to the share manually in my mac but the time machine cannot connect to disk when running. This exact same behavior happened last time, and when I downgraded to 6.9.2 it started working without any issue again. I have created new users without any change, I have not created a new share as I have had this share for over a decade working just fine, and worked in 6.9.x, while downgrading is an option I do not want to lose on some of the features of unraid going forward, but my time machine backups are very important to me.














