




johnny121b
Members
-
Joined
-
Last visited
Everything posted by johnny121b
-
Trying out 6.9.2, and my dashboard is SO unbalanced; left column FULL/TALL, right column....almost empty. Such segregation! TskTskTsk 1 - 2 - 3 1 - 2 1
-
I don't have an answer, but have a similar problem. I landed here while searching for an explanation RE: why my HTTP interface has slowed. I'm also seeing loads of 'docker0 port 1 ......entered blocking/forwarding/disabled state' messages in my log. My dockers seem to load/work correctly, but clicking on anything in the http interface- means a wait of about 60-seconds. DASHBOARD -> MAIN = wait 60 seconds......MAIN -> SHARES = wait 60-seconds.....you get the idea. Wondering if you stumbled upon a solution?
-
Go to: SETTINGS | NETWORK | List of IP addresses and networks that are allowed without auth Add the IP addresses you wish to have UNauthenticated access (to work when PLEX servers are down) Example; 192.168.1/255.255.255.0 to allow anything in-house to access regardless of PLEX site condition....if your internal network is 192.168.1.xxx
-
+1 for the idea. .....even something so basic as the ability to RENAME files in the array, would be helpful. To help protect my server from ransomware, I keep my shares set to prevent even ME from easily changing the files. And I'm not a fan of Midnight Commander, especially with longer filenames.
-
+1 for the 'intermittently stops while unpacking' issue. For me, this is a longstanding problem- many months. I've gotten into the habit of deleting the download and later telling nzbget to 'download ramaining files' to return it to the queue. Still, it stinks knowing that I MUST check the docker at least once a day, or things will pile up. I REALLY hope something shakes-out on this situation soon, because I know I suck at configuring/understanding dockers. And I KNOW... that if I have to switch to another docker, I'm gonna have a devil of a time making it play nicely with binhex's sonarr. In case any info helps: I'm still running 6.3.5, but I DO keep my dockers up-to-date.
-
Your tone implies this is a relatively straighforward step, but the thought of a hiccup leaving me with 700,000+ files to delete, strewn across hundreds of folders....is pretty intimidating. Any suggestions to help ensure this doesn't happen? Or some syntax to leisurely recover, if it does?
-
I AM probably the biggest risk on my network, but it isn't realistic to expect everyone in my house to live in a bubble. I DO protect my data with backups, but restoring a large system would be a major task- a threat in-and-of-itself. I'm not going to go nuts trying to lock down tablets and laptops, forbid PLEX, cripple my system's usability, and generally quadruple my workload while annoying everyone in the house (including myself), all for a dubious gain. All-the-while, I have a server sitting there, 95% idle, that could be keeping a watchful eye on things, that isn't subject to the latest Windoze update, that isn't having things installed on it daily, that isn't surfing the internet, that has nothing more to do..... I don't begrudge Squid for his choice, but that does not make offloading diligence to an 8-year old or a housewife....a better one. At the moment, this doesn't even affect me. I'm stuck on 6.5.3 because of other issues. I just pursued the point because I wanted to see IF there was something I wasn't aware of....as hinted by one of Squid's comments above.
-
Mmmmm....yeah. That's not realistic....and not a better solution. Malware is by-definition, proactive. It's no longer enough to be suspicious of Nigerian Prince emails. Bad things can arrive via ads- that you don't even click on, via a webpage or popup....all without user interaction. You can do everything right...and still become a victim. Anyways...really sad to see it fall by the wayside after having its functionality torpedoed by UnRAID's advancement. Thanks for the work you did on it all-the-same.
-
Can you elaborate on "a more pro-active system"? While I was never a fan of the gigantic number of bait files, I certainly see advantage in relying on a system whose O/S is isolated from the rest of my network. Otherwise, my server's overall safety is determined by the least secure machine (and user) in my house.
-
At my age, my head doesn't wrap around abstraction as well as it once did. Hard to believe I could once write code in assembly. Adding to BinHex's response, here's a shot of an example show in Sonarr. If you're like me, you're overthinking the paths. Even now, i look at BinHex's reply, and I struggle with the logic in USING abstract paths- IF everything has to be the same anyways. I -SO- want to specify absolutes....complete absolutes...from every application. But times change, and we all have to adapt. I blurred out some details on the page, but I think you'll get the idea. (I was once scolded for including too much detail, but now I only record public domain shows.) The second shot, is the path configuration for NZBGet. Its paths are unchanged from the docker defaults. Not sure if this all helps, but hopefully it might.
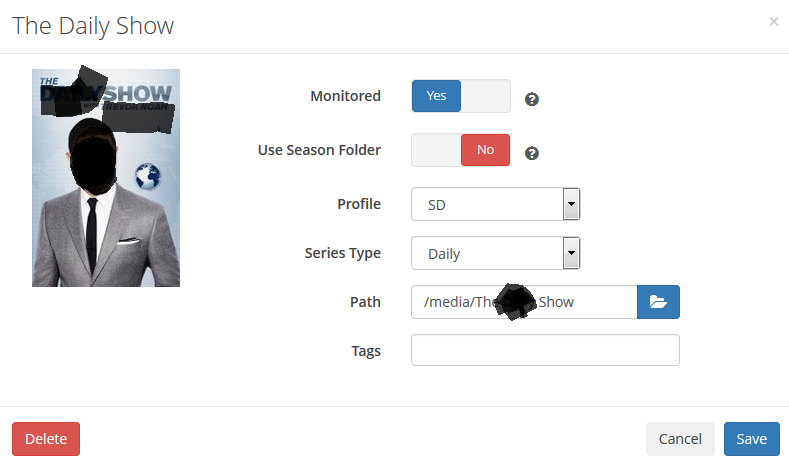

-
I'll take some screenshots later today. I'm about to head to work. I understand your frustration. The added layer of abstraction when dealing with dockers absolutely drove me crazy.. so-much-so, that when I finally got it running, I squirreled away screenshots of everything- because despite the fact that I had it running, I still didn't fully UNDERSTAND why it worked..so I knew I couldn't fix it when it broke. (unfortunately for you, I'm not sure where those screenshots are at-the-moment, because it's been so long ago.) What are you working with besides PLEX? NZBGet/Sabnzbd/? Sonarr/Sickbeard/?
-
My movies are largely in a single folder in my 'movie' share. Some of the more important titles merit their own subdirectory (for special features mostly), but 99% of them are tossed into the movie share. My TV shows are in my 'tv' share, but each series [does] have its own subdirectory. I don't do season folders. For me, that just added too much to the path length in the occasional series. (Windows doesn't handle path lengths over 255-characters) When PLEX does its scanning, it doesn't care whether the movie is in \movie or in \movie\Raiders of the Lost Ark.
-
I don't know if I'm a good example to follow. Someone may-well pop up and tell me I have something incorrectly configured, BUT the setup shown, works smoothly for my docker trio- PLEX, Sonarr & NZBGet under 6.35. The trick (for me) was to use dockers from the same author- makes life much simpler.
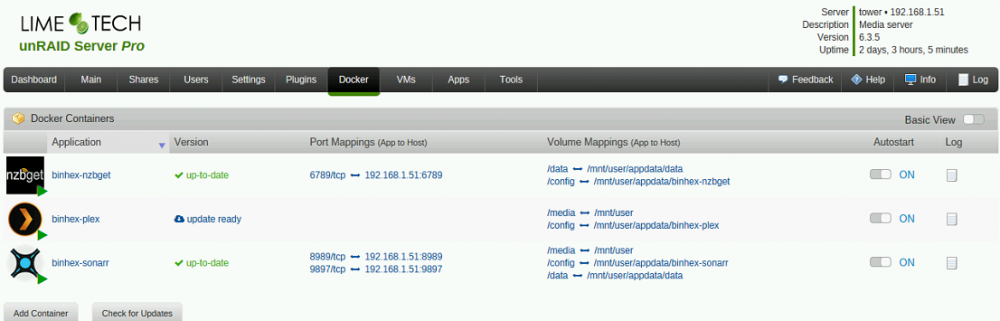
-
I've never had problems with SanDisk or Lexar sticks. As some have hinted at, mechanical damage is a significant consideration long-term. I use only sticks with minimal protrusion- a 0.25" drive will probably be protected by the normal recesses of your machine, while a 2" long stick just begs to be broken off by the accidental bump, a drop, or a cable snag.
-
When updating PLEX, is it best to Update the docker or Update PLEX from within the WebUI ??
-
"There was an unexpected error loading the dashboard" This is how it's starting up today- It HAD been loading correctly, so it's obviously taken a step backwards. My situation: New install. Public PLEX version. Binhex docker on Unraid 6.35 system. System doesn't seem to be updating the libraries as episodes are added, though it did spend a few days doing nothing but scanning/updating the libraries...just no sign of episodes added to my server in the last few days. Search function sporadically works. Seldom loads the seasons once you select a series. Nothing looks wrong or presents any sort of outward appearance of malfunction- but PLEX just seems brain-dead. I've stopped and restarted the docker. Really need some direction- I know almost nothing about dockers. UPDATE 10/31: Eventual resolution: I deleted and reinstalled the docker. I'm guessing the container became filled with logs, but I didn't know how to tell.
-
IS the wiki up-to-date?
-
Yup, I know. And it's precisely all the 'working thru issues' that made me decide to ask the question. I'd rather know now, than find-out on release day. Don't wanna become a victim of my own enthusiasm.
-
Are there any caveats for upgrading from 5.06 to 6.1? (I wasn't comfortable upgrading to a version ending in [glow=red,2,300].0[/glow] .....but I will be taking the plunge in upgrading to 6[glow=red,2,300].1[/glow]) Or are the 6.0 instructions still valid as-is? (My plan: store my existing flash drive and format/use a secondary (also-licensed) flash drive, copying over only the relevant config settings per the wiki instructions)


