




Jorgen
Members
-
Joined
-
Last visited
Everything posted by Jorgen
-
Sounds like your routing Sonarr et al through the DelugeVPN container network? In that case, you should NOT use the proxy settings in Sonarr. It's one or the other, not both. You should also add the SABnzbd ports to VPN_OUTPUT_PORTS environment variable. Because Sonarr running INSIDE the DelugeVPN container network, needs to be allowed to talk OUT to the SAB ports running outside the DelugeVPN network. This is explained in Q27 here https://github.com/binhex/documentation/blob/master/docker/faq/vpn.md Of course, if you are not routing the apps through the DelugeVPN network this is not applicable.
-
Sonarr is supposed to remove the torrent from Deluge after it reaches the defined ratio, but I never got that to work either. AutoRemovePlus plugin is the way to go in my opinion. The most likely reason the egg isn't accepted for you is that the Python version in this container was recently updated to 3.9. If you have the 3.8 egg in the plugin folder already, simple rename it to 3.9 (see below) and restart the container: AutoRemovePlus-2.0.0-py3.9.egg If you don't have it, download the 3.8 version from here: https://forum.deluge-torrent.org/viewtopic.php?f=9&t=55733 Put the egg into the plugin folder, rename it to 3.9 and restart container.
-
Thanks, hardcoding "/watch" made it work again, of course. Just for my understanding though, am I misinterpreting the table on the hooks page? I'm using post_watch_folder_processing.sh

-
Hi Djoss, I've been running this container for a looooong time without any problems, using the automatic watch folder workflow and a post_watch_folder_processing script to stop the container after processing if the watch folder is empty. Sometime during the last few months (maybe longer) the script has stopped working as intended, with this in the log: [autovideoconverter] Conversion ended successfully. [autovideoconverter] Removed /watch/moviename.mkv'. [autovideoconverter] Watch folder '/watch' processing terminated. [autovideoconverter] Executing post watch folder processing hook... post-watch folder processing: Watch folder = /watch/BDMV watch folder not empty, won't shut down [autovideoconverter] Post watch folder processing hook exited with 0 [autovideoconverter] Change detected in watch folder '/watch'. [autovideoconverter] Processing watch folder '/watch'... [autovideoconverter] Watch folder '/watch' processing terminated. Here's the script: #!/bin/sh # # This is an example of a post watch folder processing hook. This script is # always invoked with /bin/sh (shebang ignored). # # The argument of the script is the path to the watch folder. # WATCH_FOLDER=$1 echo "post-watch folder processing: Watch folder = $WATCH_FOLDER" if [ -d "/$WATCH_FOLDER" ] && [ -z "$(ls -A "$WATCH_FOLDER")" ] then echo "watch folder empty, shutting down" killall -sigterm ghb else echo "watch folder not empty, won't shut down" fi I don't understand where /watch/BDMV is coming from? Are you able to shed some light on this for me, please? Has the argument value changed recently? Is Handbrake adding a temporary BDMV folder during processing? Or have I added another watch folder somehow without realising? In the container settings, the watch folder is set to /mnt/user/Media/Handbrake_hotfolder/watch/ Thanks in advance Jorgen Edit: I only have one watch folder defined in the container settings, and no optical drives passed through. Full run command: root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker create --name='HandBrake' --net='bridge' -e TZ="Australia/Sydney" -e HOST_OS="Unraid" -e 'AUTOMATED_CONVERSION_PRESET'='My Presets/Mathias_MKV_720p30_v2' -e 'AUTOMATED_CONVERSION_FORMAT'='mkv' -e 'AUTOMATED_CONVERSION_KEEP_SOURCE'='0' -e 'AUTOMATED_CONVERSION_OUTPUT_SUBDIR'='' -e 'AUTOMATED_CONVERSION_OUTPUT_DIR'='/output' -e 'AUTOMATED_CONVERSION_NON_VIDEO_FILE_ACTION'='ignore' -e 'DISPLAY_WIDTH'='1280' -e 'DISPLAY_HEIGHT'='768' -e 'USER_ID'='99' -e 'GROUP_ID'='100' -e 'APP_NICENESS'='15' -e 'UMASK'='000' -e 'X11VNC_EXTRA_OPTS'='' -e 'AUTOMATED_CONVERSION_SOURCE_STABLE_TIME'='5' -e 'AUTOMATED_CONVERSION_SOURCE_MIN_DURATION'='10' -e 'SECURE_CONNECTION'='0' -e 'AUTOMATED_CONVERSION_CHECK_INTERVAL'='5' -e 'AUTOMATED_CONVERSION_MAX_WATCH_FOLDERS'='5' -e 'AUTOMATED_CONVERSION_NO_GUI_PROGRESS'='0' -e 'AUTOMATED_CONVERSION_NON_VIDEO_FILE_EXTENSIONS'='jpg jpeg bmp png gif txt nfo' -e 'AUTOMATED_CONVERSION_HANDBRAKE_CUSTOM_ARGS'='' -e 'AUTOMATED_CONVERSION_INSTALL_PKGS'='' -e 'AUTOMATED_CONVERSION_VIDEO_FILE_EXTENSIONS'='' -e 'AUTOMATED_CONVERSION_OVERWRITE_OUTPUT'='0' -p '7803:5800/tcp' -p '7903:5900/tcp' -v '/mnt/user/Media':'/storage':'ro' -v '/mnt/user0/Media/Handbrake_hotfolder/output/':'/output':'rw' -v '/mnt/user/Media/Handbrake_hotfolder/watch/':'/watch':'rw' -v '/mnt/cache/appdata/HandBrake':'/config':'rw' --device='/dev/dri' --cap-add=SYS_NICE --log-opt max-size=50m --log-opt max-file=1 'jlesage/handbrake'
-
ok, there was a bug in the container updates yesterday in regards to wireguard. Try forcing an update now and see if it fixes it, binhex pushed a fix a few hours ago.
-
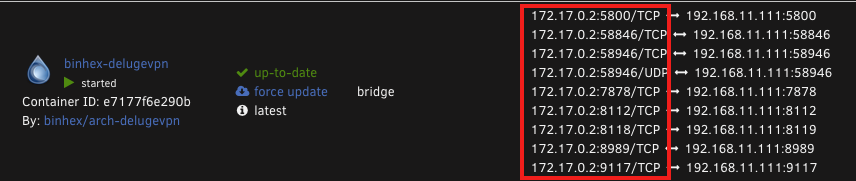
In Jackett proxy config you should use the 172.17.x.x IP of the DelugeVPN container. I think this also assumes that both Jackett and DelugeVPN containers are using the same docker network, which is bridge by default:

-
No terminal command required, it's shown on the docker page in unraid: One thing to keep in mind if you go down this route (pun intended) is that the docker IP is dynamcially assigned and could change on restart of containers or the unraid server. If things always start in the same order it probably won't, but just be aware of it if things suddenly stops working again.
-
Ah, interesting. Could you share a screenshot of the Jacket proxy settings? Is that a 172.x.x.x IP?
-
Sorry mate, I re-read you initial post and I think I misunderstood your setup. I thought you were binding the *arr apps to the delugeVPN network, but you are actually just using the proxy, right? In that case I pointed you in the wrong direction and can't really help as I don't know how NzbGetVPN works.
-
Well, it does work for Sonarr and Radarr, I think Binhex assumed Jackett would work the same, but it's obviously a special case from all the posts here. I don't know what to do about it either, apart from moving Jackett into the VPN network, maybe Binhex can weigh in at some point to clarify if there are other options. Edit: wgstarks has the solution, see posts below
-
That looks exactly like my setup which works. The only thing I can think of is there might be invisible characters or spaces in the Extra Parameters. Remove the orphaned image, reinstall Jackett from previous apps in CA and edit the Extra Parameters field by typing in the "--net..." line manually instead of copy/paste. After it's downloaded and unpacked, copy the full run command and paste it here if the container still fails to start. Which version of unraid are you on?
-
Looking back at other posts about Jackett and proxy, I think the easiest would be to not use it via proxy and instead bind it's network to the DelugeVPN container. See Q24 here: https://github.com/binhex/documentation/blob/master/docker/faq/vpn.md It will have its own quirks to work through though, read the other FAQ entries around network binding. Sent from my iPhone using Tapatalk
-
Yeah that looks like a successful start and all settings seems to be ok. Are you sure the LAN_NETWORK range is correct? If it is, maybe it's a problem on the web browser end, try disabling ad blockers, clear the cache and/or try accessing deluge from a private window or different browser?
-
There's a fix coming for this, see https://github.com/binhex/arch-delugevpn/issues/258 Although, if you want to run NzbGet through a VPN tunnel, an alternative is to use the normal binhex NzbGet container and bind it's network to the DelugeVPN container. See Q24 here: https://github.com/binhex/documentation/blob/master/docker/faq/vpn.md
-
Yes, you need to get Jackett working first. I don't use jacket via Proxy, so I'm just guessing here, but could you try using the IP of unraid, instead of "tower" for Proxy URL?
-
I'm seeing this too, have reported it to Binhex on github and will patiently wait for a new image build. Could you post new supervisord.log from the older version? Don't forget to redact user names and passwords first.
-
If you are using a proxy in the app settings of radarr/sonarr you can’t check from the container console wether they are using the VPN or not. The console works on a OS level in the container, and the OS is unaware of the proxy that the apps are using. I don’t know how to check that the app itself is actually using the VPN via the proxy, maybe someone else has a solution for that. Sent from my iPhone using Tapatalk
-
Glad you worked it out! It can be confusing with the two different methods of using the VPN tunnel, each one with its own quirks on how to set it up. Sent from my iPhone using Tapatalk
-
Wireguard is supported and has been for a while, but maybe I’m misunderstanding your question? Sent from my iPhone using Tapatalk
-
I ended up adding all of the download apps in the delugeVPN network, including NzbGet (the non-VPN version from binhex). I am seeing slower download speeds for nzbget this way, but at least it’s working and all apps can talk to each other again. Binhex is working on a secure solution to allow apps inside the VPN network to talk to apps outside it, so it might be possible to run NzbGet on the outside again in the future. Your only other option is to configure sonarr/radarr to talk to NzbGet on the internal docker ip, e.g. 172.x.x.x, but beware that the actual up is dynamic for each container and may change on restarts. Edit: yeah jackett is of no use for NZB’s, you need to set them up as separate indexers in radarr/sonarr. Which shouldn’t be a problem, both apps should talk to the internet freely over the VPN tunnel Edit2: sorry ignore the first bit of my reply, you’re using privoxy, not network binding. Sorry for the confusion.
-
I see, learn something new everyday. This container is based on arch which seems to support firewalld, but that’s obviously up to binhex what to use. From all the effort he’s put into the iptables I’d hazard a guess that he’s not keen to change it anytime soon. Sent from my iPhone using Tapatalk
-
Just out of curiosity, what do you think it should use instead of iptables? They seem well suited to the task at hand of stopping any data leaking outside the VPN tunnel? Sent from my iPhone using Tapatalk
-
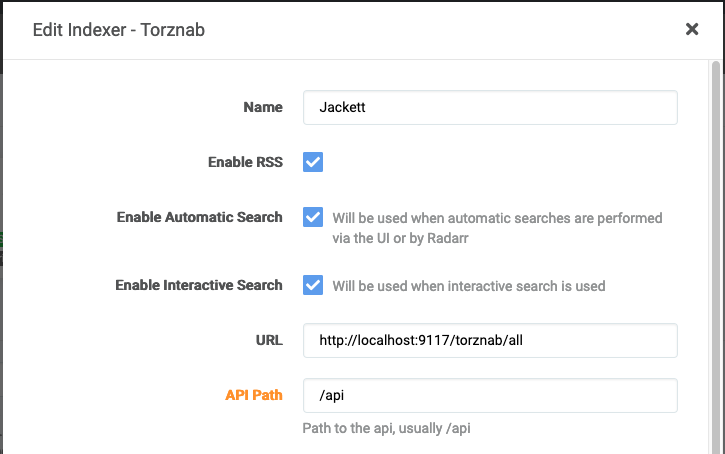
This doesn't answer your question directly, but in Sonarr/Radarr you can also set them up to use all your configured indexers in jacket, see example from Radarr below. That way you only have to set up one indexer, once, in sonarr/radarr. If you add new indexers to jackett, they will be automatically included by the other apps. Doesn't work if you need different indexers for the different apps though...
-
I have the same problem, where everything works as expected (after adding ADDITIONAL PORTS and adjusting application settings to use localhost) except being able to connect to bridge containers from any of the container with network binding to delugeVPN. Jackett, Radarr and Sonarr are all bound to the DelugeVPN network. Proxy/Privoxy is not used by any application. NzbGet is using the normal bridge network. I can access all application UIs and the VPN tunnel is up. Each application can communicate with the internet. In Sonarr and Radarr: I can connect to all configured indexers, both Jackett (localhost) and nzbgeek directly (public dns name) I can connect to delugeVPN as a download client (using localhost) I CAN NOT connect to NzbGet as a download client using <unraidIP>:6790. Connection times out. I CAN connect to NzbGet using it's docker bridge IP (172.x.x.x:6790) It's my understanding that the docker bridge IP is dynamic and may change on container restart, so I don't really want to use that. @binhex it seems like the new iptable tightening is preventing delugeVPN (and other containers sharing it's network) from communicating with containers running on bridge network on the same host? Here's a curl output from the DelugeVPN console to the same NzbGet container using unraid host IP (192.168.11.111) and docker network IP (172.17.0.3) sh-5.1# curl -v 192.168.11.111:6789 * Trying 192.168.11.111:6789... * connect to 192.168.11.111 port 6789 failed: Connection timed out * Failed to connect to 192.168.11.111 port 6789: Connection timed out * Closing connection 0 curl: (28) Failed to connect to 192.168.11.111 port 6789: Connection timed out sh-5.1# curl -v 172.17.0.3:6789 * Trying 172.17.0.3:6789... * Connected to 172.17.0.3 (172.17.0.3) port 6789 (#0) > GET / HTTP/1.1 > Host: 172.17.0.3:6789 > User-Agent: curl/7.75.0 > Accept: */* > * Mark bundle as not supporting multiuse < HTTP/1.1 401 Unauthorized < WWW-Authenticate: Basic realm="NZBGet" < Connection: close < Content-Type: text/plain < Content-Length: 0 < Server: nzbget-21.0 < * Closing connection 0 sh-5.1# Edit: retested after resetting nzbget port numbers back to defaults. Raised issue on github: https://github.com/binhex/arch-delugevpn/issues/258
-
No. You can use privoxy from any other docker or computer on your network by simply configuring the proxy settings of the application/computer to point to the privoxy address:port. For example, you would do this under settings in the Radarr Web UI. Or in Firefox proxy setting on you normal PC. But for dockers running on you unraid server, like radarr/sonarr/lidarr, there is an alternative way. You can make the other docker use the same network as deluge, by adding the net=container... into the extra parameters. It has some benefits in that you are guaranteed that all docker application traffic goes via the VPN. When using privoxy, only http traffic is routed via the VPN, and only if the application itself has implemented the proxy function properly. But doing it the net=container way, you shouldn't also use the proxy function in the application itself. So one or the other, depending on your use case and needs, but not both.






