




strike
Members
-
Joined
-
Last visited
Everything posted by strike
-
It's built-in to the OS now. There's a button in the top right of the webui. You can also click on button to the left for each share/disk and it will drop you into the file manager. I would post a screenshot, but on my phone right now.
-
Or if you really prefer cut and paste using the windows explorer you can enable disk shares in settings-global share settings (I think, on my phone right now). You then need to go to shares click on each disk and export then to smb, like you have done with your shares. Then you can browse to network in windows explorer and find your server there. Each disk and all your shares should pop right up. Cut and paste from disk to disk.
-
If you can't figure out unbalance, Midnight commander in the terminal is not as scary as it sounds. It's a filemanager with a simple gui. I prefer that over the built-in file manager in the webui. Just open the terminal, type mc and hit enter to try it. Navigate to /mnt using the mouse or arrow keys. Then all your disks should be visible. Open the disk you want to move from in the left pane, and the other in the right pane. You shift panes with tab. And on the bottom you can see which keys to press to copy/move etc. You can also use the menu. You can just select all the shares on the disk right away (insert on each share) then F6 to move. It might be other F keys for you. Or just use the menu and the mouse. The really important thing when moving manually with any method is to only move from disk to disk (you want this) or share to share. Never move from disk to share or vice versa.
-
Are you on unraid version 7.2+? If not it doesn't work. Or you can use the unbalance plugin. You can also move everything manually if you want. If you're familiar with midnight commander (mc) in the terminal you can use that. Or use the built-in file manager in the unraid webui.
-
There's nothing wrong with Nolans movies or your files. The issue you're experiencing is that you're trying to play a 7.1 audio track on a 2.1 speaker system. In a 7.1 speaker system, all the diaglog comes from the center channel and all the other channels play just sound effects, like explosiions etc. But you only have right and left channels + a subwoofer channel that plays the low frequencies. I don't know what you're using to play your movies, but you should go into your sound settings and look for "downmixing" or something similar. This will force the audio to play 2.0 stereo and solve your issue. Most tv's or media players have something like this. I would never re-encode 3000 movies to stereo... It's a waste of time and resources. And you might end up needing the 7.1 track someday.
-
So, assuming I have 3 snapshots and want to keep the most recent and delete the other two, leaving my VM in its current state. According to the documentation, both block commit and block pull will achieve the desired outcome, except that with pull, you continue using the independent overlay image instead of the original base image. So; 1: Commit the latest snap and delete the other two, which will permanently leave my VM in its current state. Leaving no snapshots left (assuming you checked delete). And continuing to use the base image (assuming you checked pivot). Here, I can leave pivot and delete unchecked if I want to continue capturing future changes, instead of doing a new snapshot after the commit. (?) 2: Pull the latest snap, and I can delete the other two and the base image if I want. Which will leave my VM in its current state, continuing to use the independent overlay image from now on, with no snapshots left. Am I understanding it correctly? Are there any scenarios you want to use one over the other? Assuming I just want to keep the VM in its current state and just get rid of earlier snapshots.
-
Everything worked out nicely :)
-
Aight, thanks. I'll try that when the backup of my second VM share is finished.
-
But if I do the block commit the snapshot will be deleted, doesn't the db get deleted too then? Or do I need the db if I just start with the base image after doing the block commit?
-
This is what I have in the db: { "02032025--generate": { "name": "02032025--generate", "parent": "Base", "state": "running", "desc": null, "memory": { "@attributes": { "snapshot": "external", "file": "\/mnt\/nvme\/VM disk share\/Windows 10\/memory02032025--generate.mem" } }, "creationtime": "1740933832", "method": "QEMU", "backing": { "hdc": [ "\/mnt\/nvme\/VM disk share\/Windows 10\/vdisk1.02032025--generateqcow2", "\/mnt\/nvme\/VM disk share\/Windows 10\/vdisk1.img" ], "rhdc": [ "\/mnt\/nvme\/VM disk share\/Windows 10\/vdisk1.img", "\/mnt\/nvme\/VM disk share\/Windows 10\/vdisk1.02032025--generateqcow2" ] }, "primarypath": "\/mnt\/nvme\/VM disk share\/Windows 10", "disks": [ { "@attributes": { "name": "hdc", "snapshot": "external", "type": "file" }, "driver": { "@attributes": { "type": "qcow2" } }, "source": { "@attributes": { "file": "\/mnt\/nvme\/VM disk share\/Windows 10\/vdisk1.02032025--generateqcow2" } } }, { "@attributes": { "name": "hdb", "snapshot": "no" } } ] }
-
Does the vm service need to be started for this? I have nothing in the libvirt directory. Do you have any idea why I got the error in my first post btw?
-
After some searches, I believe one option I could do is to block commit the changes from the snapshot to the base vdisk. My current state will then be transferred to the base image, if I understand correctly. Then just delete the snapshot, copy the vdisk back to the new share without spaces, and it should fire right back up? If I can just get the current state to the base image, I think I'm good, right?
-
So I did a workaround for now. Since the webui didn't let me recreate the share with spaces, I just made a new top-level folder from cli, stopped the vm service and copied the data from the new, renamed share to the new, old name share. After restarting the array, the VM booted right back up to where I left it. But I would still like to know how I can use my share without spaces and make the VM boot. I forgot to change the vdisk location back to the path with spaces before I started the VM, but the VM booted anyway, now with the path to the share without spaces in the vdisk settings. So there is a conflict here somewhere, and now I'm afraid to delete the share with spaces again in case it won't boot back up again. While I wait for some guidence I'll take the opportunity to back up the share to the array since I haven't done that in a long time. I would like to create another snapshot too, but with this path mess, I'm not sure it would do any good or even make things worse.

-
Are you sure it's restoring to the same location? If you backup is indeed before you ran the new permission tool all you need is to restore it and install the containers again and you should be good. But if you want to start from scratch that's up to you.
-
So the appdata backup plugin is failing to restore the data then. Have you looked at the log in the appdata backup plugin, what does it say? You can try to delete the whole appdata folder and try the restore again. If you can't delete the appdata folder you can do it from command line with midnight commander. Open a terminal and type mc and hit enter. navigate with mouse or arrow keys to /mnt/user/ and wherever your appdata folder is. Then delete the folder, see at the bottom of the window which key to press, mine is F8. If it fails to restore the data again you may need to manually unpack all the tar files to your new appdata folder. Once all the data is back continue to my first post about stopping the service and deleting the docker img. But you need to get all the data back first before you install the containers again.
-
And you ran the new permission tool today or before the 19th? If you go to your appdata backup and open one of the tar files, is the data there?
-
When was the backup from, and how did you restore it?
-
What do you mean? You didn't restore from a backup, or you don't have a backup of your appdata?
-
First, restore your appdata from backup. Then stop the docker service and delete the docker.img file and start the service again. It will recreate the img file. Now go to apps->previous apps and install all your containers from there.
-
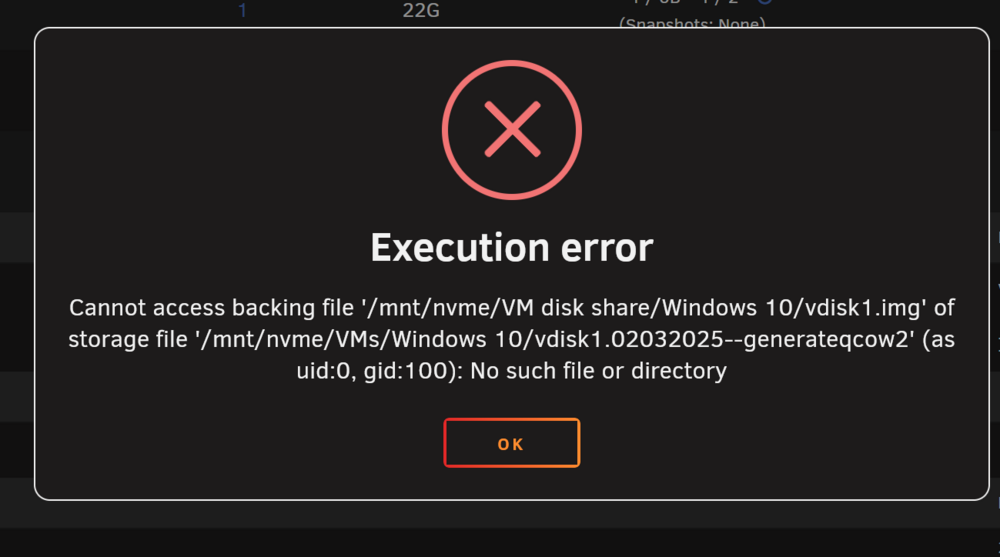
So I went to the shares tab and saw that some of my shares had "illegal characters", apparently spaces in the share name aren't allowed anymore. So I renamed them, one of them was my VM share. And now when I'm trying to start the VM i get this: I see that the first path has my old share name, but I can't figure out how to change it. I've looked at the source path in the xml view, and it has the correct path. If I change the vdisk location to just vdisk1.img it starts, but that restores the vm from before I took a snapshot it looks like. I've also rebooted to check if that would fix it, but no dice. I would like to fix the path so I can just start the VM and come back to where I was. The snapshot is old, so last option is to restore to that. Does Anyone have a clue how I could fix this? tower-diagnostics-20251222-0045.zip
-
Sorry for the wait, I of course got an unrelated problem after I rebooted I'm still trying to fix. But it appears you're right, hw transoding is still working after removing the plugin. So I can't answer why it wasn't working before I installed the plugin last time, but as long as it works :)
-
I hear you, but I'm not entirely convinced. Just for fun, I'll uninstall it and try it on my containers; it takes just 10 seconds to test. I'm not using the iGPU for VMs anyway, so one less plugin (if I clearly don't need it) is only a plus. Back in few seconds :)
-
Do you actually use an iGPU for your containers, or is that just your assumption? I've tried it, and it doesn't work without it, at least it didn't back when I installed it, and the same happened to the OP. So clearly something in the plugin is needed.
-
I had only one question, and you didn't answer it at all..
-
I wasn't talking about the Arc GPU, but the iGPU. How do you explain that it's not working without the SR-IOV plugin then? It's been a few years since I installed it, but I remember it not working without it. And the same happened to the OP just now.



