




FrozenGamer
Members
-
Joined
-
Last visited
Everything posted by FrozenGamer
-
Thanks!!!!.. this solved this problem. I had another problem pop up and the server would crash due to delays - so i had to restart server several times "src\steamnetworkingsockets\clientlib\steamnetworkingsockets_lowlevel.cpp (901) : Assertion Failed: GetBestRoute2 failed with result 50 for address '38.10.34.53:0' src\steamnetworkingsockets\clientlib\steamnetworkingsockets_lowlevel.cpp (901) : Assertion Failed: GetBestRoute2 failed with result 50 for address '38.10.34.53:0'" This was solved by adding a line - see the following info i cut and pasted from google which solved it and has been working good - I had zero problems a few years ago when i did v rising server. - There may be better fixes than what i did but i am putting it up in case someone else has same problem. "I finally fixed mine! I can now log into my V Rising server (Docker container using container station) I fixed it by adding '"LanMode": true' to my ServerHostSettings.json This is absolutely counter intuitive because it's not a LAN only server but I can now direct connect to the server which is on the same network as my PC using either its local or WAN IP address and selecting the LAN Server checkbox for either IP. IMPORTANT: External users still have to check the LAN Server box when connecting via direct connection option (I don't list my server). Again counter intuitive. All roads lead to this being caused by something on the Steam side with some routing changes as I had made no changes to my server before it stopped working"
-
I have used a number of game servers successfully - including v - rising which i am trying to setup again.. As far as i can tell it is working - i can connect on my network but my friends cannot connect directly. I am listing a lot of info.. please let me know if there is anything else i should post. Here is my docker run command. docker run -d --name='V-Rising' --net='bridge' --pids-limit 2048 -e TZ="America/Anchorage" -e HOST_OS="Unraid" -e HOST_HOSTNAME="Tower" -e HOST_CONTAINERNAME="V-Rising" -e 'GAME_ID'='1829350' -e 'VALIDATE'='' -e 'SERVER_NAME'='Ketchikan_Rising' -e 'WORLD_NAME'='Free_World' -e 'GAME_PARAMS'='' -e 'ENABLE_BEPINEX'='' -e 'USERNAME'='' -e 'PASSWRD'='' -e 'UID'='99' -e 'GID'='100' -e 'CA_TS_FALLBACK_DIR'='/serverdata/steamcmd' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.icon='' -p '9876-9877:9876-9877/udp' -v '/mnt/user/appdata/steamcmd':'/serverdata/steamcmd':'rw' -v '/mnt/user/appdata/vrising':'/serverdata/serverfiles':'rw' --restart=unless-stopped 'ghcr.io/ich777/steamcmd:vrising' 018e023525547b5298775e7d4032a891755c765878d27842a559186bf0ae8af2 I deleted the folder in appdata deleted the app and reinstalled I added ports to my unifi firewall - forwarded 9876- 9877 UDP specifically to the internal IP address of server I use Tailscale but i dont think that should cause a problem? i don't have it enabled in my docker. I checked the game ServerhostSettings and UDP ports match "Name": "V Rising Server", "Description": "", "Port": 9876, "QueryPort": 9877, "MaxConnectedUsers": 40, "MaxConnectedAdmins": 4, "ServerFps": 30, "SaveName": "world1", "Password": "changed", "Secure": true, "ListOnSteam": true, "ListOnEOS": false, "AutoSaveCount": 20, "AutoSaveInterval": 120, "CompressSaveFiles": true, "GameSettingsPreset": "", "GameDifficultyPreset": "", "AdminOnlyDebugEvents": true, "DisableDebugEvents": false, "API": { "Enabled": false }, "Rcon": { "Enabled": false, "Port": 25575, "Password": "" My audiobookshelf is working fine but that is tcp port forwarding. Here are the port forwarding and firewall rules in my unifi network settings Allow Port Forward V Rising Unraid Firewall Allow UDP External Any Internal 192.168.1.154 9876-9877 V Rising Unraid Port Forwarding Translate UDP - Any - Any
-
Edit- solved but posted anyhow.. in case someone else can benefit.. i updated to latest stable version of unraid 7.1.4 - i am not sure but pretty sure this is what broke my deluge-vpn. I can't roll back for a few days until parity check finishes. I can connect via web ui, but no longer through the deluge thin client. Also it has broken my privoxy which i use to connect to vpn on chrome using proxy by patterns. -FOUND SOLUTION.... disconnected tailscale on my windows 11 machine and it all works fine.. - so i will try and figure out to have tailscale and privoxy/deluge client work in harmony next.
-
I updated unraid from 7.0 to 7.0.1 and maybe this caused a problem with privoxy working (unreachable from my windows machine that i browse on) . I didn't change anything in the container etc but since then i can't reach it from chrome/foxyproxy on another machine. - if i recall i should also be able to type in my unraid server local address 192.168.1.154:8118 and reach it that way as well? Here is my docker config command - and i am setting my foxyproxy to connect to 192.168.1.154 http 8118 docker run -d --name='binhex-qbittorrentvpn' --net='bridge' --pids-limit 2048 --privileged=true -e TZ="America/Anchorage" -e HOST_OS="Unraid" -e HOST_HOSTNAME="Tower" -e HOST_CONTAINERNAME="binhex-qbittorrentvpn" -e 'VPN_ENABLED'='yes' -e 'VPN_USER'='xxxxxxx' -e 'VPN_PASS'='xxxxxxxxx' -e 'VPN_PROV'='pia' -e 'VPN_CLIENT'='openvpn' -e 'VPN_OPTIONS'='' -e 'STRICT_PORT_FORWARD'='yes' -e 'ENABLE_PRIVOXY'='yes' -e 'WEBUI_PORT'='8080' -e 'LAN_NETWORK'='192.168.1.0/24' -e 'NAME_SERVERS'='209.222.18.222,84.200.69.80,37.235.1.174,1.1.1.1,209.222.18.218,37.235.1.177,84.200.70.40,1.0.0.1' -e 'ADDITIONAL_PORTS'='' -e 'DEBUG'='false' -e 'UMASK'='000' -e 'PUID'='99' -e 'PGID'='100' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='http://[IP]:[PORT:8080]/' -l net.unraid.docker.icon='https://raw.githubusercontent.com/binhex/docker-templates/master/binhex/images/qbittorrent-icon.png' -p '6881:6881/tcp' -p '6881:6881/udp' -p '8080:8080/tcp' -p '8118:8118/tcp' -v '/mnt/user/Torrents':'/data':'rw' -v '/mnt/user/appdata/binhex-qbittorrentvpn':'/config':'rw' --sysctl="net.ipv4.conf.all.src_valid_mark=1" 'binhex/arch-qbittorrentvpn' in addition it appears that privoxy is up and running on the logs for qbittorrent vpn and that i am connecting to torrents with my PIA address properly (as far as i can tell) - Here is the log 2025-03-27 08:33:14,812 DEBG 'start-script' stdout output: [info] vietnam.privacy.network [info] taiwan.privacy.network [info] sg.privacy.network [info] sweden.privacy.network [info] gt-guatemala-pf.privacy.network [info] panama.privacy.network [info] de-germany-so.privacy.network [info] swiss.privacy.network [info] egypt.privacy.network [info] aus-melbourne.privacy.network [info] ec-ecuador-pf.privacy.network [info] santiago.privacy.network [info] aus-perth.privacy.network [info] tr.privacy.network 2025-03-27 08:33:17,487 DEBG 'start-script' stdout output: [info] Successfully assigned and bound incoming port '34218' 2025-03-27 08:33:32,586 DEBG 'watchdog-script' stdout output: [info] qBittorrent listening interface IP 0.0.0.0 and VPN provider IP 10.2.110.98 different, marking for reconfigure 2025-03-27 08:33:32,591 DEBG 'watchdog-script' stdout output: [info] qBittorrent not running 2025-03-27 08:33:32,596 DEBG 'watchdog-script' stdout output: [info] Privoxy not running 2025-03-27 08:33:32,596 DEBG 'watchdog-script' stdout output: [info] qBittorrent incoming port 6881 and VPN incoming port 34218 different, marking for reconfigure 2025-03-27 08:33:32,597 DEBG 'watchdog-script' stdout output: [info] qBittorrent config file already exists, skipping copy [info] Removing session lock file (if it exists)... 2025-03-27 08:33:32,637 DEBG 'watchdog-script' stdout output: [info] Attempting to start qBittorrent... 2025-03-27 08:33:32,642 DEBG 'watchdog-script' stdout output: [info] qBittorrent process started 2025-03-27 08:33:32,642 DEBG 'watchdog-script' stdout output: [info] Waiting for qBittorrent process to start listening on port 8080... 2025-03-27 08:33:33,555 DEBG 'watchdog-script' stdout output: [info] qBittorrent process listening on port 8080 2025-03-27 08:33:33,992 DEBG 'watchdog-script' stdout output: [info] Attempting to start Privoxy... 2025-03-27 08:33:34,998 DEBG 'watchdog-script' stdout output: [info] Privoxy process started [info] Waiting for Privoxy process to start listening on port 8118... 2025-03-27 08:33:35,009 DEBG 'watchdog-script' stdout output: [info] Privoxy process listening on port 8118
-
https://slickdeals.net/f/18184354-seagate-expansion-26tb-external-usb-3-0-desktop-hard-drive-with-rescue-data-recovery-services-299-99?v=1&page=5&src=frontpage&prop=&attrsrc= I have 5 coming, i will likely keep them- how is use case for unraid? i mainly write once and leave stuff on the server running 24x7 - other than parity checks i don't know that it would be that active, however starts and stops could affect life? anyhow what are your thoughts on these?
-
edit: Good news.. I figured it out.. just edited library in the webui and added the proper directory structure then deleted old library folder: I installed it.. It worked localnetwork.. But wouldn't connect from outside the network.. eventually i deleted the docker.. ran appdata cleanup, and reinstalled.. on the 2nd install i changed 1 thing.. i put the audiobook in docker template directory one directory up in the folder structure, in case i wanted to add other directories such as podcasts or other audiobook libraries.. Now it won't see any of the folder structures. Also it appears that maybe it kept some of the previous data from first install? Or i messed up the data folder path? Here is a line from the scanlog - t,"message":"Library Item \"/audiobooks/Adrian Tchaikovsky/The Children of Time Novels/2023 - Children of Memory [The Children of Time Novels 3]\" (inode: 648799860241192423) is missing","levelName":"WARN","level":3} attaching screenshot of config
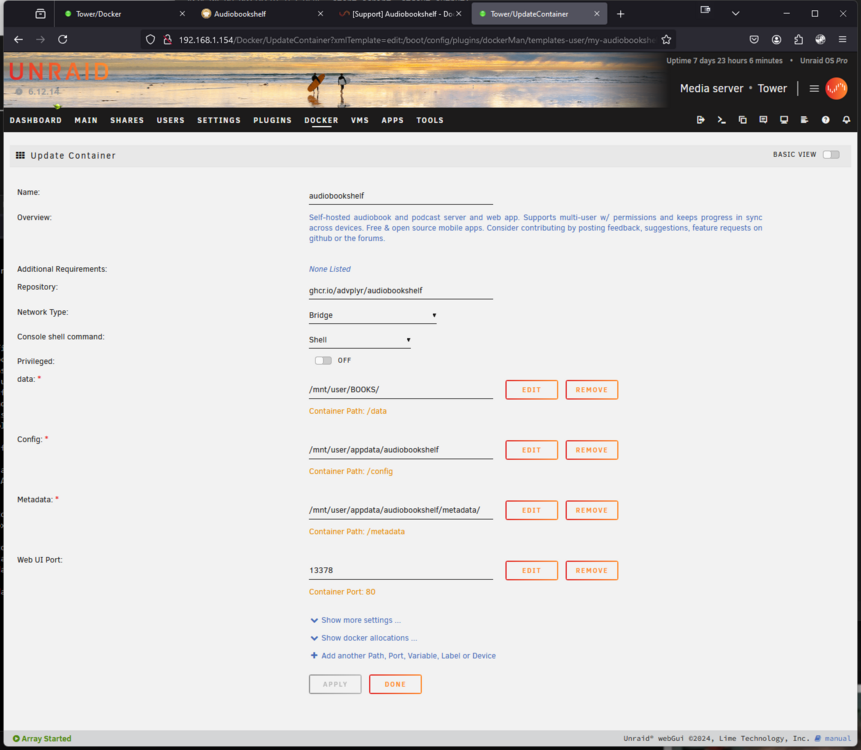
-
I am heading out for one more remote job, so i created new wireguard connections, which has broken the check all updates on docker, stays on checking.. However i did have an update that was available before i enabled wireguard and that update shows up when i load the docker page still. I rebooted the server and tried a different browser.. the single update persisted and i was able to update it.. I cannot however check for updates and it stays forever spinning on "checking." I will do a few disabling of wireguards and see if that solves it (it didn't seem to before) .. the problem eventually just went away.. so maybe it did..
-
How many cores/hyperthreads would you recommend to cpu pin for Satisfactory? amd 5900x 32gb ram.. would it even be needed in theory with several other dockers running. plex/torrent program and a few others.
-
Same issue - following.
-
Updated Diagnostics. Although server has been rebooted many times. @JorgeB any thoughts? tower-diagnostics-20241010-1443.zip
-
a little concerned about breaking something so i will wait for any other ideas before i go this route. I kind of recall doing it years ago and only having minor fixes needed.
-
I guess i should add that i was able to check plugins for updates and that worked without hanging up. Only place i have noticed a problem so far is in the docker management page.
-
OK. i have done so, and restarted docker service (but not full system reboot) - seems to still be stuck..
-
Clock appears to be correct.
-
Thanks.. i unplugged router for 30 and rebooted. still same issue happening. i currently have 1.1.1.1 and 1.0.0.1 as dns, will try changing that as well.
-
I also removed my vpn configs etc and then rebooted.. problem still exists
-
OK - did it on the unraid server and rebooted it and that isn't working. still stuck on checking and never finishes.
-
Done. I changed primarty to 9.9.9.9 and secondary to 1.1.1.1 in my router.. this didn't help. One thing that i did recently change is i setup vpn on ports 8444 and 8443 (did 2 of them to test etc) - i mapped both udp/tcp into unraid for that..
-
Thanks! As far as i can tell none of them are grabbing updates and it says "status: Image is up to date" on each one that i try. After a few days or a week, if this continues, i would assume that at least one of the dockers will be updated at some point. I wonder if anyone has solution to get it to successfully check for updates via the gui?
-
Also tried a few browsers. Never gets past "checking".. can i manually trigger updates in the mean time. even though i don't know they are available.. does a restart of the container trigger an update? EDIT - Could my recent enabling of wireguard (vpn) be part of the cause of this? even if it isn't "active"? see attached diagnostics. tower-diagnostics-20241007-1809.zip edit - solved it self.. works now.. not sure why.. i will setup wireguard again and see if that is what broke it and note it here if it stops working again. edit - update 10.20.24 - setup wireguard again and it stopped working again. - just turning active off (and not rebooting the server didn't help) As well as turning active off and autostart and rebooting server.. It seems to be going indefinitely stuck on checking.
-
(Satisfactory) So.. Maybe i missed this in the thread.. I kept getting encryption missing error on trying to connect.. The answer was to use server manager to connect.. Not to just join ip address.. Then you go through the process of creating server etc as directed.. Now it seems to work. https://steamcommunity.com/app/526870/discussions/1/4845399560304886641/
-
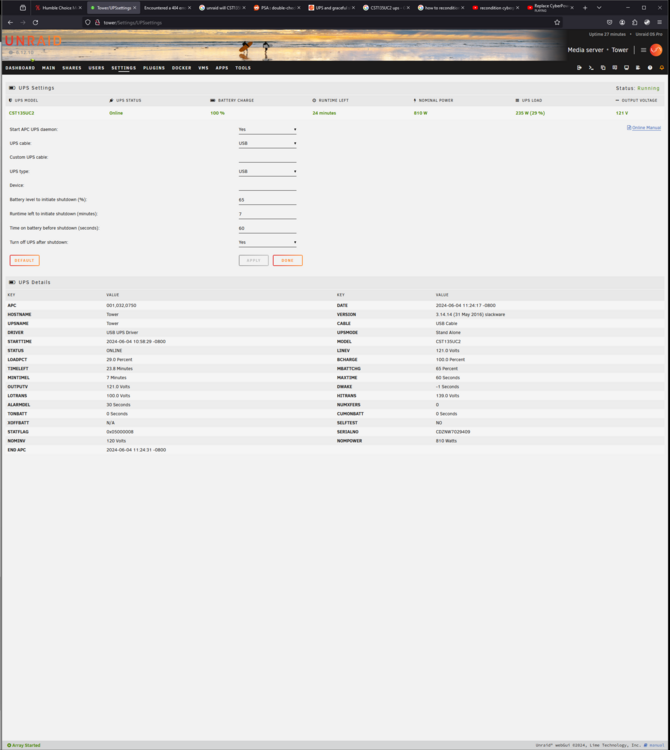
Can anyone let me know if these settings look good? I am going to unplug test it now.
-
I have determined this is a 6 year old ups, did the simple unplug of wall to see how long it would run with just the 2 hard drive caddies and the ups shut off in 10 or so seconds, replaced it with a new ups (99 dollar CST135UC2 cyberpower from costco) and unplugged drive caddies only, says 23 minutes with that load.. So now that i know the ups isn't working right, i am hoping the new one will shut itself down after power down of unraid (but the 2 drive caddies cannot be shut off that i know of.) I had read that the old similar cyberpower ups was not cable of shutting itself off afterwards.. I assume this maybe degraded the ups? or just the 6 years of use? Looking into how to recondition the batteries, but i assume i should just buy a few more from costco and not worry about it, maybe even a separate one for the caddies (32 drives) and the box amd 5900x without a graphics card) Thanks everyone for all the assistance.. unraid is pretty amazing and the support in the forums is above and beyond. Edit- partial answers to my own questions.. unplug worked fine and shut down the desktop with unraid.. It also triggered the auto shutdown of the UPS which set to shut down in 59 minutes.. This will not work with 32 drives connnected to it.. Looking into how to change that shutdown time with https://www.cyberpowersystems.com/product/software/power-panel-business/powerpanel-business-windows/
-
I can't promise it is not a hardware issue (as in memory etc), I really dont think it is.. but it may be a ups issue?
-
Power went out or flickered again sometime while i was gone and server was off again.. I am starting to wonder if the power supply itself isn't able to keep the load of the entire server and 32 drives without powering down.. I say this because i use a similar costco UPS on my desktop and i have been coming home to see computer powered off a few times and ups down.. (not unraid server) this has never happened on unraid server as far as i know its been power outtages. I think desktop is lower power load, i just eliminated the ups from desktop.. If i was to choose to do a test by unplugging my unraid server ups from wall and seeing if it supports the load, i assume it would be best to do so when the server array was down and drives spinning still? So as not to damage file integrity? Any other ideas on how to test etc.



