




Cessquill
Members
-
Joined
-
Last visited
Everything posted by Cessquill
-
I haven't tried restarting Plex yet as a family member was using it (wasn't transcoding for them either). I will try shortly, but Plex can see the card for me. Sorry if I that sounds crazy to you.
-
Hi - after updating the plugin, then updating Unraid to 7.2.5, waiting for a reboot notification then rebooting, Plex isn't hardware transcoding (tested forcing 1080 file to 720 in browser). Was working before and haven't changed anything other than updating. Could have missed something in the last few pages here as it's got a bit confusing. unraid1-diagnostics-20260503-1413.zip
-
All of your movie folders are available from the Root Folder dropdown (when I click it, I get "shorts", "4k" and others). The dropdown also lets you add a new root folder.
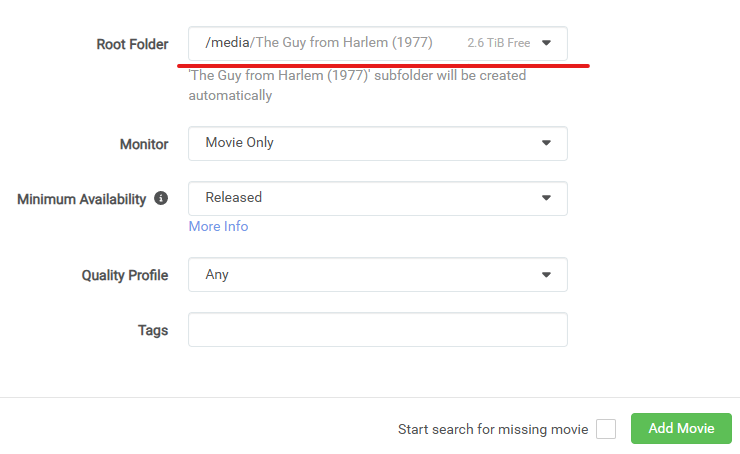
-
You say that your PSU is nearly new, but is it powerful enough? I was getting drop-outs after upgrading my GPU. Swapped for a higher power PSU and it's been rock-solid ever since - must have been tipping it over the edge. Turns out you can't just keep adding drives and cards and expect it to work 🙃
-
Good point, thank you. I've just checked - I've got a 920w power supply and it's powering 24 drives + parity + SSDs + GPU. If it was 920w new it could well be struggling. It's a SuperMicro chassis, so not a regular PSU. I've just seen I can get a 1U 1280W supply that fits and is still part of their quiet range, so that might be worth a try (used prices are worth the risk). EDIT: Used good condition 1200w supply - £24, just purchased. There's also 1400w, but they're still £250+
-
Command added to go file, BIOS confirmed to be up to date (2021), BIOS is up to date, above 4G Decoding enabled, but I do not have Resizable BAR Support available. Fingers crossed that buys a bit of time until a full system upgrade. I will look at the PSU too since I added an extra drive a few weeks ago - might have tipped it over the edge 🤔 Thank you for your help again.
-
I'll add the line to my go file (can I put it in a user script on array start?). I'll check the BIOS - pretty sure it's on the last update SuperMicro did but I'll check the settings. To be honest it's getting a little old and needs replacing, but that's a job for next year. The PSU should be up to it, but again, age... Thank you for your time
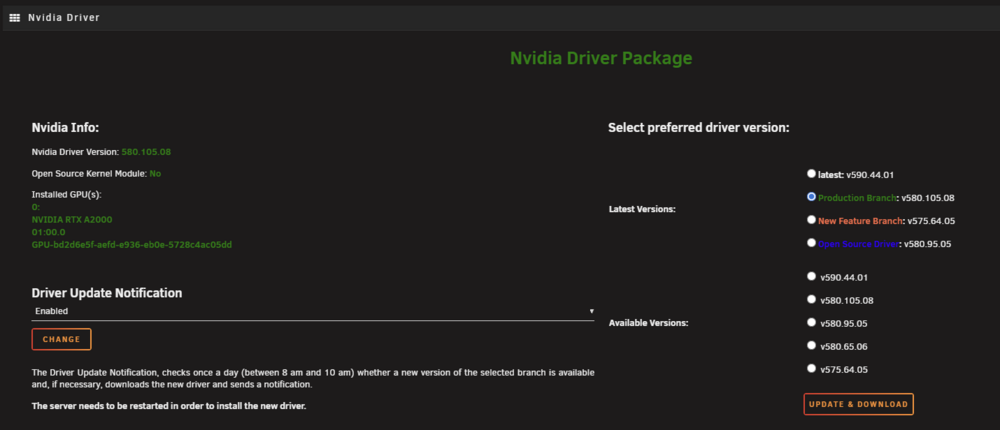
-
Hi - I've had a notification email a couple of times over the last few weeks saying... However, v580.105.08 is the version I have installed. Whenever this happens, my log has several of these lines listed... Dec 9 09:56:39 unRAID1 kernel: NVRM: GPU 0000:01:00.0: RmInitAdapter failed! (0x22:0x51:884) Dec 9 09:56:39 unRAID1 kernel: NVRM: GPU 0000:01:00.0: rm_init_adapter failed, device minor number 0 Dec 9 09:57:35 unRAID1 kernel: NVRM: GPU 0000:01:00.0: RmInitAdapter failed! (0x22:0x51:884) Dec 9 09:57:35 unRAID1 kernel: NVRM: GPU 0000:01:00.0: rm_init_adapter failed, device minor number 0 And shortly after, if I go to the Nvidia driver page I get no cards found. Appreciated the GPU stats plugin is separate, but on the dashboard no cards listed (Vendor command returned unparseable data). Sometimes it comes back, maybe bouncing on and off. I've rebooted and it's gone back to being stable for a while. This is an A2000 (after upgrading from 1050ti), not used in VM, latest version of Unraid. It's not catastrophic, but up until recently my machine's been pretty stable. Could easily be something I've left misconfigured though. Thanks! unraid1-diagnostics-20251209-0958.zip
-
You can sort of do it with custom filters... On the main Radarr page, click the "Filter" dropdown on the right and then "Custom Filters" Click "Add Custom Filter" Get it a Label/Title (eg, "Temp Movies") For the filter, you could do something like "Path", "contains", "/Temp Movie/" Add as many as you want (eg, "Path", "contains", "/Movies/") This way, the list you want will be available from the Filters dropdown. You could add more complicated filters to just list missing temp movies. I have my movies in different locations (e.g., shorts, features, standup, music), and then sub-grouped by quality (SD, HD, UHD). I hadn't thought about filtering them in Radarr - might add that to my rainy weekend list. It's not exactly like Plex, but it'll get the job done. Any more and I think you'd have to spin up more Radarr instances.
-
That is the version of the web client. To get the server version, scroll down the left on the same settings area and under your server name, go to Settings, General. It should say something like "Version 1.42.1.10060", but I'm guessing a docker update will be available soon enough.
-
Even better, thank you! I hadn't kept up to date with graphics cards and was searching for something recent, doesn't require external power, and the A2000 kept cropping up.
-
Quick Q: Would a 6GB RTX A2000 be a suitable upgrade for my 1050ti? I know it's said we've still got a fair amount of time before the 1000 series drivers are unsupported, but I figure this might buy me a few more years with the setup I have (plus I could do with something to crunch through Tdarr processes). I'm running 23 data + parity, 3xSSD and a temp spinner in an SC846 case and don't think there's that much headroom on the PSU, and I can't currently afford to replace the mobo, RAM, CPU, etc. Used ones seem to be fairly reasonable.
-
Thanks for the head's up - I appreciate the card's getting on, but it's perfectly good enough for my transcoding at the moment. This might tip things into a full system upgrade as everything else is starting to age.
-
Sorry to hijack, but didn't know this - are you saying my trusty 1050 won't be supported soon? Roughly how long have I got until I need to find a quiet and efficient replacement?
-
Yeah, the "echo" line after is is what's telling you it's renaming, but since the actual command doing the work was commented out you were effectively doing a dry run. The echo command could say pretty much anything, so feel free to change it to echo "renamed $file, transferred money into bank account 😀
-
Remove the # at the start - you've effectively remmed / commented out this line, so the actual renaming is skipped
-
Is there any way to turn off "you might be interested in" at the end of notification emails? I tend to scroll through before reading replies in full and the extra stuff is far longer than the notification.
-
Notification emails seem to be cluttered with extra stuff as well. I know it's change, and I generally don't like change, so I'll wait it out. I am struggling with the font though.
-
You're not the only one. I've had the same, and keeping an eye on these topics.As far as I'm aware, yes. I follow the steps in this thread for each new Ironwolf (although I haven't changed drives for a while) I wouldn't, no. One of the key selling points to me is the ability to spin down drives when there's no activity. Just follow the steps in the first post - you could do all eight at once if you prep your commands in a text editor beforehand.As an update to using OCC commands. I recommended using the occweb app, but it appears to be broken on the latest version (I get an Internal Server Error). I've raised an issue on github for it. For running OCC commands from the Unraid console, I get the same error as you when using the above command, but the following works for me... docker exec Nextcloud php occ db:add-missing-indices Just replace the text after occ with the command that the admin console wants you to run. (also posting it here to remind myself, as I always forget)I'm out of ideas I'm afraid. If Plex can see those shares but not the folders inside them then something's wrong - hopefully one of the other people on here can assist.So if you click on the browse icon where you set the mount up, are the files/folders there?
 Are you saying that when you are in Plex setting up the photos library, when you go to add a folder, /photosp and /photospri are not listed as root folders to select?
Are you saying that when you are in Plex setting up the photos library, when you go to add a folder, /photosp and /photospri are not listed as root folders to select?






