




darrenyorston
Members
-
Joined
-
Last visited
Everything posted by darrenyorston
-
Its obviously a straight forward process to do periodic backups to a Synology NAS from unraid. Keeping two Synology devices in sync over the internet is built into Synology NAS so that isnt a problem. I was hoping someone might have containerised Synology's Cloud Station app which would allow unraid to sync files directly to a remote site.
-
I had looked at a few of those. I was looking to avoid using cloud services for obvious reasons, which necessitates a local solution, either an OTS NAS, a home brew NAS or a PC. I was against a PC, particularly for the remote site as I want something which would be unobtrusive and require no interaction from people at the host location. Hence why I was thinking of a OTS NAS like the Synology. I know I could have two Synology NAS, one remote and a second in the same physical location as my main server but as I already have a local backup this would be a duplication. I was wondering whether there was a docker container which allowed for the mirroring function used by Synology. Essentially that I could connect a remote NAS to the docker container for the data sync.
-
I thought the libvrt log would show that the VM has crashed. So I am presuming the problem is occuring before the error/s can be logged.
-
Not as yet, no. At the moment I see no errors in the VM logs. I do however see errors in the Libvirt Log: 2021-10-21 08:37:19.994+0000: 10790: warning : qemuDomainObjTaint:6075 : Domain id=3 name='Manjaro' uuid=93250046-5efe-9082-9009-bc183f6d4f6c is tainted: high-privileges 2021-10-21 08:37:19.994+0000: 10790: warning : qemuDomainObjTaint:6075 : Domain id=3 name='Manjaro' uuid=93250046-5efe-9082-9009-bc183f6d4f6c is tainted: host-cpu 2021-10-21 08:40:40.443+0000: 10788: warning : qemuDomainObjTaint:6075 : Domain id=4 name='Arch' uuid=fb5a38b0-6857-abb5-caba-1df6b23360a2 is tainted: high-privileges 2021-10-21 08:40:40.443+0000: 10788: warning : qemuDomainObjTaint:6075 : Domain id=4 name='Arch' uuid=fb5a38b0-6857-abb5-caba-1df6b23360a2 is tainted: host-cpu This was the log for the Manjaro VM when it crashed. Nothing draws my attention. I had to do a forced shutdown as the VM was frozen. ErrorWarningSystemArrayLogin -uuid 93250046-5efe-9082-9009-bc183f6d4f6c \ -display none \ -no-user-config \ -nodefaults \ -chardev socket,id=charmonitor,fd=31,server,nowait \ -mon chardev=charmonitor,id=monitor,mode=control \ -rtc base=utc,driftfix=slew \ -global kvm-pit.lost_tick_policy=delay \ -no-hpet \ -no-shutdown \ -boot strict=on \ -device pcie-root-port,port=0x8,chassis=1,id=pci.1,bus=pcie.0,multifunction=on,addr=0x1 \ -device pcie-root-port,port=0x9,chassis=2,id=pci.2,bus=pcie.0,addr=0x1.0x1 \ -device pcie-root-port,port=0xa,chassis=3,id=pci.3,bus=pcie.0,addr=0x1.0x2 \ -device pcie-root-port,port=0xb,chassis=4,id=pci.4,bus=pcie.0,addr=0x1.0x3 \ -device pcie-root-port,port=0xc,chassis=5,id=pci.5,bus=pcie.0,addr=0x1.0x4 \ -device pcie-root-port,port=0xd,chassis=6,id=pci.6,bus=pcie.0,addr=0x1.0x5 \ -device pcie-root-port,port=0xe,chassis=7,id=pci.7,bus=pcie.0,addr=0x1.0x6 \ -device ich9-usb-ehci1,id=usb,bus=pcie.0,addr=0x7.0x7 \ -device ich9-usb-uhci1,masterbus=usb.0,firstport=0,bus=pcie.0,multifunction=on,addr=0x7 \ -device ich9-usb-uhci2,masterbus=usb.0,firstport=2,bus=pcie.0,addr=0x7.0x1 \ -device ich9-usb-uhci3,masterbus=usb.0,firstport=4,bus=pcie.0,addr=0x7.0x2 \ -device virtio-serial-pci,id=virtio-serial0,bus=pci.2,addr=0x0 \ -blockdev '{"driver":"file","filename":"/mnt/user/domains/Manjaro/vdisk1.img","node-name":"libvirt-1-storage","cache":{"direct":false,"no-flush":false},"auto-read-only":true,"discard":"unmap"}' \ -blockdev '{"node-name":"libvirt-1-format","read-only":false,"cache":{"direct":false,"no-flush":false},"driver":"raw","file":"libvirt-1-storage"}' \ -device virtio-blk-pci,bus=pci.3,addr=0x0,drive=libvirt-1-format,id=virtio-disk2,bootindex=1,write-cache=on \ -netdev tap,fd=33,id=hostnet0 \ -device virtio-net,netdev=hostnet0,id=net0,mac=52:54:00:db:9c:d8,bus=pci.1,addr=0x0 \ -chardev pty,id=charserial0 \ -device isa-serial,chardev=charserial0,id=serial0 \ -chardev socket,id=charchannel0,fd=34,server,nowait \ -device virtserialport,bus=virtio-serial0.0,nr=1,chardev=charchannel0,id=channel0,name=org.qemu.guest_agent.0 \ -device vfio-pci,host=0000:44:00.0,id=hostdev0,bus=pci.4,addr=0x0,romfile=/mnt/user/isos/vbios/GTX1080.rom \ -device vfio-pci,host=0000:44:00.1,id=hostdev1,bus=pci.5,addr=0x0 \ -device vfio-pci,host=0000:45:00.3,id=hostdev2,bus=pci.6,addr=0x0 \ -sandbox on,obsolete=deny,elevateprivileges=deny,spawn=deny,resourcecontrol=deny \ -msg timestamp=on 2021-10-21 08:47:16.522+0000: Domain id=6 is tainted: high-privileges 2021-10-21 08:47:16.522+0000: Domain id=6 is tainted: host-cpu char device redirected to /dev/pts/0 (label charserial0) 2021-10-21T08:52:46.745914Z qemu-system-x86_64: terminating on signal 15 from pid 10785 (/usr/sbin/libvirtd) 2021-10-21 08:52:48.146+0000: shutting down, reason=destroyed
-
Ive started using the S3 Sleep plugin to shutdown my server at night. It works fine with WOL however every time the system restarts it commences a Parity-Check as a result of an unclean shutdown. Ive seen a number of posts from users with similar issues however none have a solution. Anyone else have this issue and found a solution?
-
Hello. I have this problem also. Did you find a resolution?
-
Id like to get TPLink Energy Monitoring running on unraid. There are standalone containers around as well as ones using influxDB and Prometheus. Anything workable on unraid that people have seen? I tried installing one from DockerHub but it has a port conflict with Grafana and I dont know how to change the containers port allocation.
-
I am having an issue with VMs freezing randomly. I dont see any problems in the log for the VM and its not causing an issue with the host machine. The VMs are completely unresponsiveness and require the VM to be forced shutdown and restarted. Are there any places other than the VM log where I can look for problems?
-
Hello all. Im trying to set up the container to work with ProtonVPN. There are a lot of config options in the container template; I dont know which are required or not. Im wanting to use the container as a proxy for certain browsers on some of my devices. I was hoping that I could use my local PiHole for DNS/Adblocking if at all possible. Anyone able to share a sanitised version of their config?Hello all. Im trying to set up the container to work with ProtonVPN. There are a lot of config options in the container template; I dont know which are required or not. Im wanting to use the container as a proxy for certain browsers on some of my devices. I was hoping that I could use my local PiHole for DNS/Adblocking if at all possible. Anyone able to share a sanitised version of their config?
-
I am looking to expand my backup approach. Currently I am backing up important materials to a separate, but local, storage system. I am interested in adding in some remote storage. I was recently watching a Network Chuck video where he was showing how he had files in sync between two remote locations with Synology NAS. I was wondering if it is possible to do the same thing but from Unraid to an OTS NAS like the Synology. Obviously do the main backup on site due to the size of the data involved, then move the devices to their remote locations. Anyone done this? Or seen someone doing this?
-
ahh ok. ill give that a go. thanks.
-
Thanks mate. I hear what you are saying. But how do you actually install a duplicate container of the same type as one already installed? Whenever I try it opens the config for my existing container. I presume you do it by some means other than using the community applications tab? Or do you open the application values for the container in community applications, append something to distinguish a new container which, as a result, creates a duplicate container?
-
ok, thanks. Why not just do backups of your database? Seems like your adding complexity for little reason.
-
Thanks mate. Ive read over the previous posts in the thread and I wouldn't say its clear. You say not to use the same DB for both sites, which is understandable, and to create a new MariaDB. Do you mean a new database within MariaDB or an entirely new MariaDB container? ie I will have two MariaDB containers running, one with the databases for all my others containers (authelia/nextcloud/photprism/wordpress) and another that solely contains a database for the second wordpress site?
-
Hello. I have Wordpress set up and running on my server with it being published to the web using nginxproxymanager. Its great and works perfectly. I am now trying to work out how to host a second site. I have created a second database in mariadb but how do i install a second wordpress container?
-
Im having difficulty getting Cloudflare, NGINX and any Docker container working. I have working Docker containers that I want to proxy. nextcloud being one. I have the Cloudfare DNS docker container functioning and the appropriate A record for my domain name is showing on Cloudflare. I have created a CNAME for nextcloud targeted to my domain. I have forwarded ports 80 and 443 in my router to NGINX's ports (1880 and 18443) When I create and select a host in NGINX I am presented with an Error 522 page. According to the error Cloudflare say "The initial connection between Cloudflare's network and the origin web server timed out. As a result, the web page can not be displayed." Anyone have an idea where I go about addressing the problem?
-
I'm having a problem launching creating new VMs. . I attempted to install ArcoLinux using the default Arch template. Calamares installer runs fine and the O/S installs. After shutting down the VM, removing the ISO and rebooting the VM I am getting the following message: Starting version 248.3-2-arch /dev/vda2: clean, 464203/3260416 files, 4273307/13029719 blocks The cursor flashes however the VM never progresses beyond this point. If I reboot the same message appears. The log for the VM is: -rtc base=utc,driftfix=slew \ -global kvm-pit.lost_tick_policy=delay \ -no-hpet \ -no-shutdown \ -boot strict=on \ -device pcie-root-port,port=0x8,chassis=1,id=pci.1,bus=pcie.0,multifunction=on,addr=0x1 \ -device pcie-root-port,port=0x9,chassis=2,id=pci.2,bus=pcie.0,addr=0x1.0x1 \ -device pcie-root-port,port=0xa,chassis=3,id=pci.3,bus=pcie.0,addr=0x1.0x2 \ -device pcie-root-port,port=0xb,chassis=4,id=pci.4,bus=pcie.0,addr=0x1.0x3 \ -device pcie-root-port,port=0xc,chassis=5,id=pci.5,bus=pcie.0,addr=0x1.0x4 \ -device pcie-root-port,port=0xd,chassis=6,id=pci.6,bus=pcie.0,addr=0x1.0x5 \ -device pcie-root-port,port=0xe,chassis=7,id=pci.7,bus=pcie.0,addr=0x1.0x6 \ -device pcie-root-port,port=0xf,chassis=8,id=pci.8,bus=pcie.0,addr=0x1.0x7 \ -device pcie-root-port,port=0x10,chassis=9,id=pci.9,bus=pcie.0,multifunction=on,addr=0x2 \ -device pcie-root-port,port=0x11,chassis=10,id=pci.10,bus=pcie.0,addr=0x2.0x1 \ -device ich9-usb-ehci1,id=usb,bus=pcie.0,addr=0x7.0x7 \ -device ich9-usb-uhci1,masterbus=usb.0,firstport=0,bus=pcie.0,multifunction=on,addr=0x7 \ -device ich9-usb-uhci2,masterbus=usb.0,firstport=2,bus=pcie.0,addr=0x7.0x1 \ -device ich9-usb-uhci3,masterbus=usb.0,firstport=4,bus=pcie.0,addr=0x7.0x2 \ -device virtio-serial-pci,id=virtio-serial0,bus=pci.2,addr=0x0 \ -blockdev '{"driver":"file","filename":"/mnt/user/domains/ArcoLinux/vdisk1.img","node-name":"libvirt-1-storage","cache":{"direct":false,"no-flush":false},"auto-read-only":true,"discard":"unmap"}' \ -blockdev '{"node-name":"libvirt-1-format","read-only":false,"cache":{"direct":false,"no-flush":false},"driver":"raw","file":"libvirt-1-storage"}' \ -device virtio-blk-pci,bus=pci.3,addr=0x0,drive=libvirt-1-format,id=virtio-disk2,bootindex=1,write-cache=on \ -netdev tap,fd=33,id=hostnet0 \ -device virtio-net,netdev=hostnet0,id=net0,mac=52:54:00:5f:4f:38,bus=pci.1,addr=0x0 \ -chardev pty,id=charserial0 \ -device isa-serial,chardev=charserial0,id=serial0 \ -chardev socket,id=charchannel0,fd=34,server,nowait \ -device virtserialport,bus=virtio-serial0.0,nr=1,chardev=charchannel0,id=channel0,name=org.qemu.guest_agent.0 \ -device vfio-pci,host=0000:43:00.0,id=hostdev0,bus=pci.4,addr=0x0,romfile=/mnt/user/isos/vbios/GTX1080.rom \ -device vfio-pci,host=0000:43:00.1,id=hostdev1,bus=pci.5,addr=0x0 \ -device vfio-pci,host=0000:46:00.0,id=hostdev2,bus=pci.6,addr=0x0 \ -device vfio-pci,host=0000:47:00.0,id=hostdev3,bus=pci.7,addr=0x0 \ -device vfio-pci,host=0000:48:00.0,id=hostdev4,bus=pci.8,addr=0x0 \ -device vfio-pci,host=0000:49:00.0,id=hostdev5,bus=pci.9,addr=0x0 \ -sandbox on,obsolete=deny,elevateprivileges=deny,spawn=deny,resourcecontrol=deny \ -msg timestamp=on 2021-08-01 05:20:16.609+0000: Domain id=3 is tainted: high-privileges 2021-08-01 05:20:16.609+0000: Domain id=3 is tainted: host-cpu char device redirected to /dev/pts/0 (label charserial0) I've not had a problem running VMs with GPU pass through before. I've tried an install of the same O/S but used VNC instead of passing through the GPU. After install the O/S boots fine and operates through VNC. I'm presuming its some issue with the VP pass through. Ive tried two GPUs and get the same problem. One of the GPU I have used with GPU pass through previously. Any advice?
-
Thanks. I had opened console within the container. It worked once I opened in root. I couldn't end up getting it running. Bit to much beyond me unfortunately.
-
Hello I am following these instructions. When I input the cat /dev line I get the following message "tr: range-endpoints of 'O-9' are in reverse collating sequence order". I have looked in the homeserver.yaml document and these is no line beginning "enable_registration.." Also when edit the bind address to 0.0.0.0 I am still not able to access the container.
-
So I think, think, I may have identified the issue. I was checking the VPN certs and I noticed I have two "binhex-delugevpn" folders in my app data. One has a "." after it. It doesnt have any OpenVPN details. I copied the same Open VPN files into it as is in the similarly named container and now it works. As a result I checked the container details and whilst the container name is "binhex-delugevpn" its AppData Config Path is "/mnt/user/appdata/binhex-delugevpn." I changed the path to "/mnt/user/appdata/binhex-delugevpn", dropped the "." and now Sonarr and Radarr work with Proxy enabled. I have deleted the appdata folder with the "." at the end of the folder name. Is there a way for me to check that Sonarr, Radayy, and Lidarr are actually utilising the VPN? I regularly "iknowwhatyoudownloaded" but is there a more specific way?
-
Im not sure if this will answer your question. I have your delugevpn, lidarr, radarr, sonarr, and sabnzbd containers installed. I utilised Spaceinvader1's YT guide to set them up. Deluge has my VPN enabled (PIA). Privoxy is also enabled though I have not set any browser or PC set to utilise it. Sonarr, Radarr, and Lidarr all have SAB set as the Download Client. All three had the same SAB config. I made sure all three were the same. They have all been working fine. Lidarr still is, Sonarr and Radarr are running. I can access the UI on all. Lidarr still downloads fine. The others dont. I attempted to fix the issue by deleting the Sab download client in Radarr's config. I have since attempted to re-add it assuming it may be corrupted in some way.Upon clicking "Test" I am shown the following screen. To me this seems to indicate a problem with the hosts IP address. I have tried localhost as the address however receive the same error. I have attached a picture of the Lidarr confg showing the test is successful. Also attached Sonarr proxy settings as requested. Edit: So i noted Lidarr wasnt usign a Proxy, hence im assuming why its downloading. Turning off Proxy in Sonarr/Radarr and it works, test successful. With Proxy enabled I receive the error message. So it seems to me there is a problem with the Proxy path, as it works (including downloading) when Proxy is set to off. I have not edited my delugevpn container. When Radarr/Sonarr connect to SABnzb does it go through my VPN, as specified in deluge? Could this be why the test fails locally?
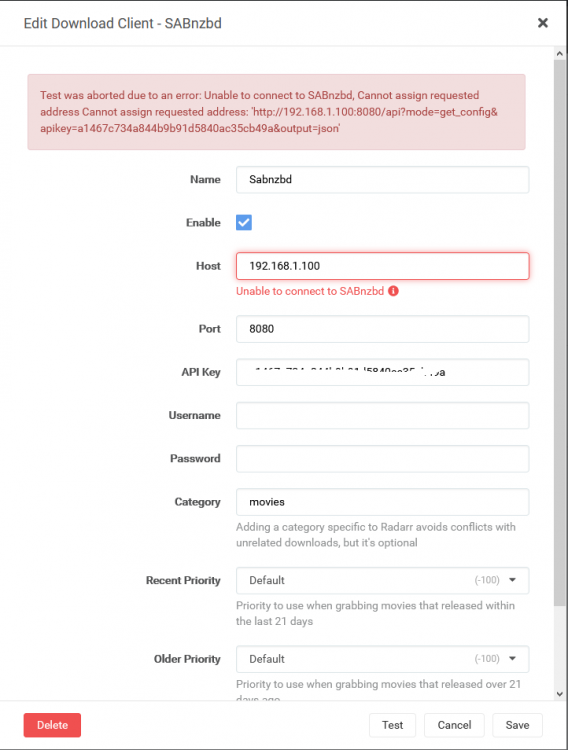
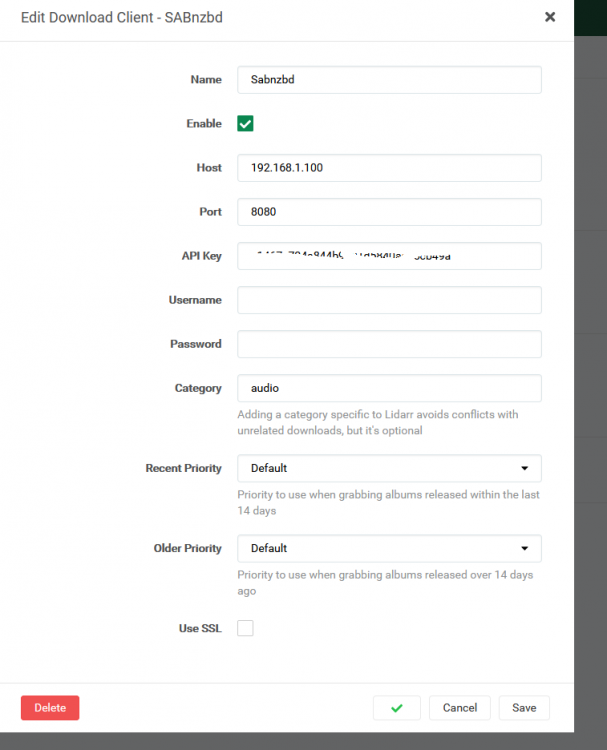
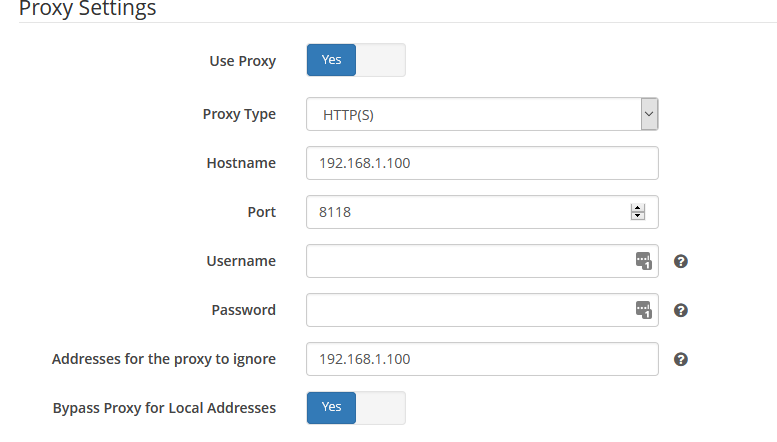
-
Im running your delugevpn container with privoxy enabled. There doesnt appear to be any issue for Lidarr downloading via your SAB container. I just tested it and its all working fine. Just Sonarr and Radarr reporting the error. So at the moment all I have changed is the Sonarr Settings/General/Proxy Settings field to ignore my server address. Im still getting the message "Test was aborted due to an error: Unable to connect to SABnzbd, please check your settings".
-
I followed the link you provided. I removed the Extra Parameters field. Q25 does not apply as I can view the UI. Q26 does apply. I have added my unRAID server to the Ignored Addresses field of Sonar's Settings/General Proxy. Error continues. As to Q27; where am I adding the VPN_OUTPUT_PORTS to? Am i adding a variable from the Sonarr docker template config page? This page?
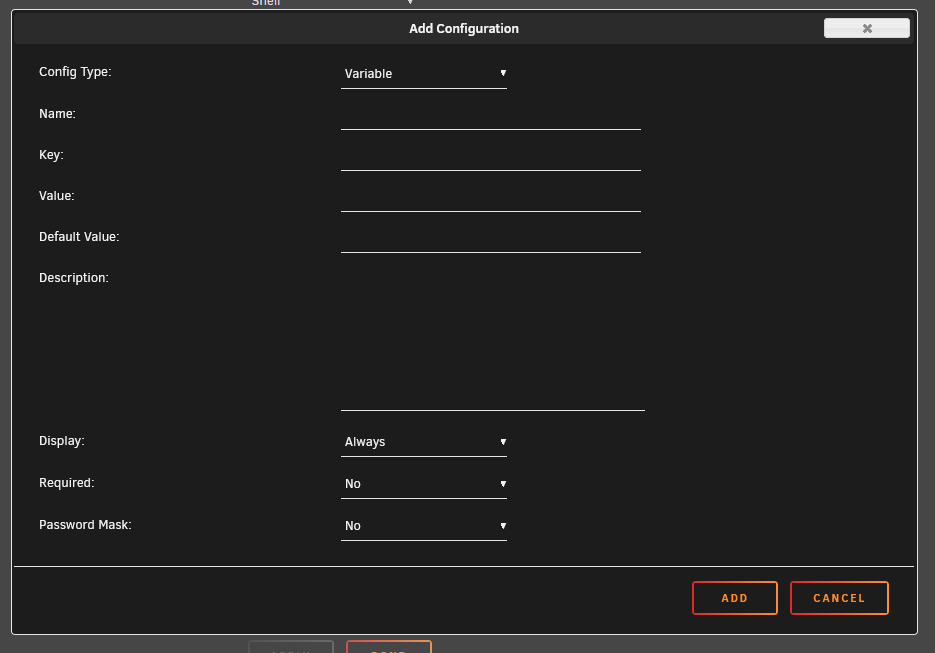
-
I forced the update on the containers of yours that Im running. Sonarr and Radarr still dont work, though Lidarr does. I have added the line --sysctl="net.ipv4.conf.all.src_valid_mark=1" to Sonarr's Extra Parameters field but the Sonarr container has now dissappeared from the list on the Docker tab. I have reinstalled the container but still get the same message. I edited the Settings-General-Proxy Settings of Sonarr's config to ignore my server (192.168.1.100). Still getting the same message.
-
I tried unchecking "Enable HTTPS" however it does not work. It says the change will require a restart. However, when it restarts HTTPS remains enabled.



