




CrunchyToast
Members
-
Joined
-
Last visited
-
Looks like issues are still ongoing. The only hardware that is the same are the physical disks in the array. Everything else (including the cache and USB boot drives) have been replaced. Still nothing in the logs either. Now what seems to be happening is everything stops responding (shares, docker, vms and most of the web interface). If I go to my server IP, I can still login, however, only the header loads with navigation links. The rest of the page is blank. I can navigate to other pages, but nothing ever loads beyond the header. If I try to connect via SSH, it responds super slow. If I issue a reboot command, the system begins the shutdown process, but stops and just hangs. I have to manually power cycle the system. When it powers back on, it will boot to the CLI login screen, but the web GUI and all other services are unreachable. It takes about 2 or 3 power cycles to get things going again. After swapping out all the hardware, I got 14 days of uptime prior to the crash. Now it's happened twice in the last 48 hours. What could possibly be going on here?
-
Looks like it’s time to rebuild. I’ve swapped things around and the system keeps crashing. Thanks for your help.
-
Update: Got another crash at about 8AM this morning. Reformatted the Cache pool. One of the disks has a CRC error count. About to check the cabling and see if anything changes. Attached is the syslog for today. syslog.rtf
-
Oddly enough, after that last reboot, there hasn't been any error in the syslog. I'm going to leave it online for a bit and see what happens. If I get another crash, I'll reformat the cache pool and update. Thanks!
-
My syslog has appeared to fill up pretty quickly. Tons of BTRFS errors now, but no crash since removing the trim plugin. Rebooting due to this message and seeing what happens. Jun 24 05:43:32 Vault kernel: Fixing recursive fault but reboot is needed! Just a snippet of the attached syslog Jun 24 06:40:43 Vault kernel: item 170 key (216726 108 823296) itemoff 6748 itemsize 53 Jun 24 06:40:43 Vault kernel: extent data disk bytenr 177476538368 nr 8192 Jun 24 06:40:43 Vault kernel: extent data offset 0 nr 8192 ram 8192 Jun 24 06:40:43 Vault kernel: BTRFS error (device sdg1): block=176288710656 write time tree block corruption detected Jun 24 06:40:43 Vault kernel: BTRFS: error (device sdg1) in btrfs_commit_transaction:2377: errno=-5 IO failure (Error while writing out transaction) Jun 24 06:40:43 Vault kernel: BTRFS info (device sdg1): forced readonly Jun 24 06:40:43 Vault kernel: BTRFS warning (device sdg1): Skipping commit of aborted transaction. Jun 24 06:40:43 Vault kernel: BTRFS: error (device sdg1) in cleanup_transaction:1942: errno=-5 IO failure Jun 24 06:41:01 Vault kernel: blk_update_request: I/O error, dev loop2, sector 6787184 op 0x1:(WRITE) flags 0x100000 phys_seg 1 prio class 0 Jun 24 06:41:01 Vault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 1, rd 0, flush 0, corrupt 0, gen 0 Jun 24 06:41:01 Vault kernel: blk_update_request: I/O error, dev loop2, sector 21056496 op 0x1:(WRITE) flags 0x100000 phys_seg 1 prio class 0 Jun 24 06:41:01 Vault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 2, rd 0, flush 0, corrupt 0, gen 0 Jun 24 06:41:05 Vault kernel: blk_update_request: I/O error, dev loop2, sector 19397120 op 0x1:(WRITE) flags 0x5800 phys_seg 118 prio class 0 Jun 24 06:41:05 Vault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 3, rd 0, flush 0, corrupt 0, gen 0 Jun 24 06:41:05 Vault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 4, rd 0, flush 0, corrupt 0, gen 0 Jun 24 06:41:05 Vault kernel: blk_update_request: I/O error, dev loop2, sector 19398144 op 0x1:(WRITE) flags 0x1800 phys_seg 68 prio class 0 Jun 24 06:41:05 Vault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 5, rd 0, flush 0, corrupt 0, gen 0 Jun 24 06:41:05 Vault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 6, rd 0, flush 0, corrupt 0, gen 0 Jun 24 06:41:05 Vault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 7, rd 0, flush 0, corrupt 0, gen 0 Jun 24 06:41:05 Vault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 8, rd 0, flush 0, corrupt 0, gen 0 Jun 24 06:41:05 Vault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 9, rd 0, flush 0, corrupt 0, gen 0 Jun 24 06:41:05 Vault kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 10, rd 0, flush 0, corrupt 0, gen 0 Jun 24 06:41:05 Vault kernel: blk_update_request: I/O error, dev loop2, sector 19921408 op 0x1:(WRITE) flags 0x1800 phys_seg 118 prio class 0 Jun 24 06:41:05 Vault kernel: blk_update_request: I/O error, dev loop2, sector 19922432 op 0x1:(WRITE) flags 0x1800 phys_seg 68 prio class 0 Jun 24 06:41:05 Vault kernel: BTRFS: error (device loop2) in btrfs_commit_transaction:2377: errno=-5 IO failure (Error while writing out transaction) Jun 24 06:41:05 Vault kernel: BTRFS info (device loop2): forced readonly Jun 24 06:41:05 Vault kernel: BTRFS warning (device loop2): Skipping commit of aborted transaction. Jun 24 06:41:05 Vault kernel: BTRFS: error (device loop2) in cleanup_transaction:1942: errno=-5 IO failure Jun 24 06:41:32 Vault kernel: blk_update_request: I/O error, dev loop2, sector 17435296 op 0x1:(WRITE) flags 0x100000 phys_seg 3 prio class 0 Jun 24 06:41:32 Vault kernel: btrfs_dev_stat_print_on_error: 18 callbacks suppressed vault-syslog-20210624-2324.zip
-
Hey all - I've been trying to figure out why my server has been randomly crashing ever since a power outage last week. My UPS didn't stay online long enough for the server to power down gracefully. It's been super intermittent on when it happens. When it first occurred, it lost one of my cache drives. I was able to add it back and scan everything and there were no errors. I did have to run `xfs_repair` on a couple of drives in the array which fixed the error reported in the unRAID GUI. I started recording the syslog and the one below is the last one running when the server crashed this morning around 5AM. I only included the lines that were within an hour of the crash. Memtest passed as well. Note: I removed the trim plugin this morning as it isn't needed with BTRFS. It has been running for the last couple years without an issue. Jun 23 04:00:15 Vault root: /etc/libvirt: 920.7 MiB (965373952 bytes) trimmed on /dev/loop3 Jun 23 04:00:15 Vault root: /var/lib/docker: 42.2 GiB (45270634496 bytes) trimmed on /dev/loop2 Jun 23 04:00:15 Vault kernel: sd 7:0:1:0: [sdc] tag#5689 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 cmd_age=0s Jun 23 04:00:15 Vault kernel: sd 7:0:1:0: [sdc] tag#5689 Sense Key : 0x5 [current] Jun 23 04:00:15 Vault kernel: sd 7:0:1:0: [sdc] tag#5689 ASC=0x21 ASCQ=0x0 Jun 23 04:00:15 Vault kernel: sd 7:0:1:0: [sdc] tag#5689 CDB: opcode=0x42 42 00 00 00 00 00 00 00 18 00 Jun 23 04:00:15 Vault kernel: blk_update_request: critical target error, dev sdc, sector 973080532 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Jun 23 04:00:15 Vault kernel: BTRFS warning (device sdg1): failed to trim 1 device(s), last error -121 Jun 23 04:00:15 Vault sSMTP[5384]: Creating SSL connection to host Jun 23 04:00:15 Vault sSMTP[5384]: SSL connection using ECDHE-RSA-AES256-GCM-SHA384 Jun 23 04:00:17 Vault sSMTP[5384]: Sent mail for [email protected] (221 2.0.0 Bye) uid=0 username=root outbytes=461 Jun 23 04:40:04 Vault root: Fix Common Problems Version 2021.05.03 Attached is my diagnostics. unRAID version 6.9.2 Thanks for any info you may be able to share! vault-diagnostics-20210623-1311.zip
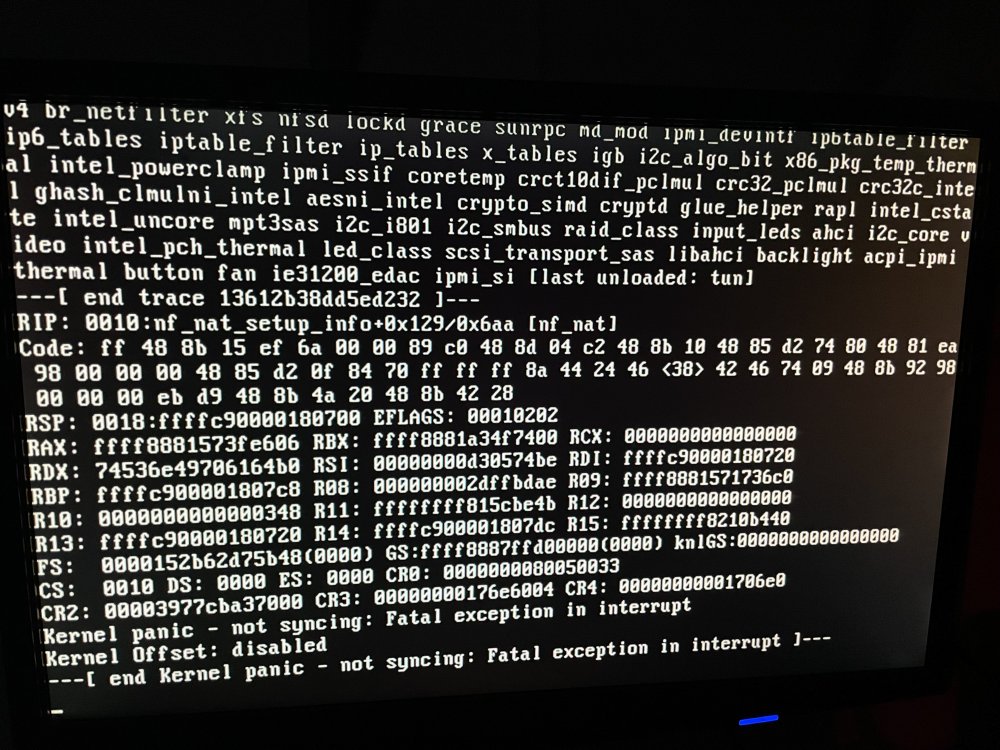
-
Yes, it works just fine for me. What issue are you running into? I wouldn't really say one is better than the other, but for a faster response and quicker record trigger, use FTP. I was manually modifying the config via the /super config gui. There was an issue with the config getting reset back to default somehow, so I just created the conf.json file in Shinobi's app data folder and haven't had an issue since. You can manually create the conf.json file. The container will use it instead. Just make sure it's the full config as it won't even look at the other one anymore.
-
For those of you seeing high CPU usage on Shinobi when using the built-in motion detection, most IP cameras have FTP or Email alerts built in along with motion detection. I'm using Reolink RLC-410-5MP cameras. Check out the following links to on how to use your camera's built in detection rather than Shinobi's. When I was using the motion detector in Shinobi, I was seeing anywhere between 40%-80% CPU usage on 8 cameras. When I switched over to using my camera's built in motion detection, I drop to around 7%-10% max with 8 cameras going. The FTP trigger will give you the fastest motion response. https://hub.shinobi.video/articles/view/Qdu39Dp8zDqWIA0 https://hub.shinobi.video/articles/view/LyCI3yQsUTouSAJ
-
It doesn't look like roles are working for a local user. Requests won't auto approve and it isn't stopping them from requesting other items (music,tv). Anything special I need to do or check? Thanks.
-
I did dig around this. When using same as src it would only do the most immediate folder, not multiple directories. Either way, it's working for me.
-
This seems to be working so far. I had to create a custom script for Radarr and Sonarr separately. Move or Episode is downloaded and imported Custom script copies file to the /watch directory File is encoded After encoding, file is moved to the /output directory then copied to overwrite the original file An issue I had was trying to make sure the files were dropped into the correct directory after encoding. Sonarr adds an extra directory that Radarr doesn't have. Wanting to use the container's available functions without adding new packages, I had to come up with a way to identify that extra directory. Here's the variable I created and finally settled on: DEPTHCOUNT=$(find "$CONVERTED_FILE" -type f | grep -o / | wc -l) Seems pretty functional so far. I get to watch videos asap and they still get encoded.
-
I didn't think of that right off the bat. Next problem I would have is once Radarr imports the video file, it renames it. Any idea the best path to overwrite the renamed file? I know I would have to retrieve the new name, but I can't think of how... I think I'd have to create a post process script in Radarr to have it write the new name to a file then this processing script can read the file and overwrite it.
-
I've been using SpaceInvader's method of converting and importing, but I run into a couple issues. If conversion takes too long Radarr or Sonarr stop looking for the file and I have to import manually. Plus I have to wait a while to watch it unless I convert it later. I was hoping to find a solution where I could allow Radarr or Sonarr to import the movie, copy to a temp directory then overwrite the original. In my case, transcoding a movie takes longer than watching one. I will inquire on that post. Thank you.
-
Hello, a couple quick questions here: Is it possible to ignore already existing files in the /watch directory? Is it possible to grab a file, have it converted then put back in the same location as the source file? I received an error of "already exists" when trying this. My goal would be to just convert new files and just leave the existing ones. Thanks.
-
Hey all - I see this is still in Beta. Is this running pretty smoothly right now? I was looking into Spaceinvader's solution, but if this works, I'll do this prior to changing all configuration. Thanks!


