




manofcolombia
Members
-
Joined
-
Last visited
-
@Axel8rate Did you ever get anywhere with this? I recently upgraded to 7.3.1 from 7.1 and also have had a p2000 that was doing hw transcode no problem for the last several years. After the upgrade, the container still sees the device no problem but refuses to use it. I am also lifetime plex member and have had this server going for many years. Jellyfin and frigate has the same p2000 passed through and both of those are working without issue, including transcoding the same media files.
-
I've been consolidating 2 arrays into 1 by mounting the 2nd arrays drives as unassigned drives and then rcloning the data into the array. This starts off pretty good and I get ~200MB/s writes when using 16 transfers concurrently. These are all large media files so not a ton of itty bitty things happening. After about 10-15 minutes, the same transfer (sometimes on the same files depending on size) will drop to 30-50MB/s. The destination of the copy is all going to 1 drive on the array because of high-water, but it still started off fine at ~200MB/s and it just progressively gets slower till it stabilizes at 30-50MB/s. The destination of the copy is not going to any cache pool so its not like its filling cache and then switching to array. I also noticed this with my parity checks. At the beginning of the parity check, its flying at ~200+MB/s and then by the end the average is ~50MB/s and its taken ~3 days. I thought maybe it was drive bay or HBA cable, but I swapped drive bays today and still seeing the same behavior. Cache is already being used for vms and docker so its not like there are competing writes from those. stylophora-diagnostics-20240108-1422.zip
-
Thanks for the confirmation to set my mind at ease!
-
Hey @ich777 I was pointed in your direction for this question: I'm currently still running 6.8.2 with the old linuxserver nvidia build. I'm looking to finally upgrade to meet the latest stable unraid, however, in the past, I've always reverted back to the vanilla build before upgrading. The old plugin no longer works/supported so I am curious if you would suggest trying to get my hands on a vanilla build of 6.8.2 before attempting to upgrade to 6.11 and/or any other gotchas you might think of regarding my current situation? Thanks
-
Needless to say, its been quite a long time since I've upgraded unraid... I am curious if anyone has done such a big jump in versions or if it is suggested to upgrade in smaller steps. The thing I am most worried about is that I am still running an old nvidia build from @linuxserver.io and I can no longer revert back to the stock image (easily?) to do a more vanilla upgrade.
-
All good man. Stuff happens. Thanks for taking a look. I confirmed that the lastest build is working as it used to and the db and related files is now being written out to my volume mount. Thanks
-
@Stark any luck? Container restarted again and all its config is gone again
-
Within the last 2 weeks, I started having issues with the hosts/schedules being wiped after restarting/updating the container. The only log that seemed interesting is this: 2019-03-03 15:03:13.506 - INFO - [DavosApplication] - No active profile set, falling back to default profiles: default Assuming that the config isn't being saved to persistent location so it goes back to a default state. I removed the image and all appdata to start over and found that the container does appear to write its persistent data to /config (mapping) anymore. Based on the last log message I have written to volume mapping, this started on 2/10
-
Since upgrading to 6.6.6, I see this log message every day around the same time: Jan 8 06:00:13 stylophora sSMTP[4074]: Creating SSL connection to host Jan 8 06:00:13 stylophora sSMTP[4074]: SSL connection using ECDHE-RSA-CHACHA20-POLY1305 Jan 8 06:00:13 stylophora sSMTP[4074]: Authorization failed (535 5.7.8 https://support.google.com/mail/?p=BadCredentials g25sm28692448qki.29 - gsmtp) I had never previously setup email notifications for anything so I went and took a look at the notifications page in settings and found that email notifications are all unchecked, however, the default gmail smtp server info is there and with no way to disable it. There is no option to disable this in "preset service" and if you choose custom service and blank out all the options, it will not let you save the form. Hitting reset will revert to default gmail preset. Expected outcome - like the rest of the notification services, being able to disable the notification types: stylophora-diagnostics-20190108-1911.zip
-
Running into this and I believe it is causing some movies to be constantly missing, even though they are local to the box where radarr lives: Import failed, path does not exist or is not accessible by Radarr: /home/hd3/manofcolombia/torrents/data/The.Butterfly.Effect.2004.DC.1080p.BluRay.H264.AAC-RARBG My workflow goes like this: Ombi -> radarr -> deluge on seedbox -> filebot on seedbox renames and moves to movies folder on seedbox -> davos sftp seedbox movie folder to on prem movie folder -> Plex scans and imports. The above file path is the file path is the path for deluge downloads on the seedbox so I assume deluge is sending back the path. How do I go about handling this without leaving a ton of data on the seedbox, and without being able to mount the seedbox path into the radarr container on prem.
-
Yea that hasn't happened before. May have been a one off kind of deal.
-
Still dies at some point after heavy use. But there are no more timeouts in the logs. stylophora-diagnostics-20190102-0651.zip
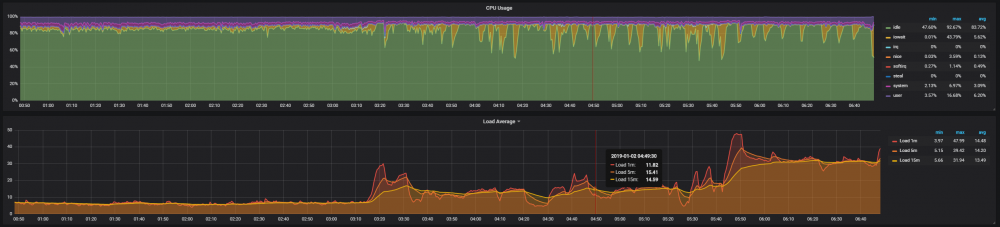
-
Just got it happening a couple of times since I tested. But it was literally just happening. Here are the fresh diagnostics The worst thing is, I start getting crazy cpu_io_wait, assuming because plex container expects the path to be there but the path isn't happy. So what I end up having to do is: 1. stop plex - because it normally won't remount if its still running and it'll give me a blank error reason 2. Unmount the share which works sometimes on the first try but can take 30-45+ seconds for the plugin to say its actually unmounted - also sometimes does not work on the first try 2a. Start plex if I don't feel like dealing with #3 and back to normal 3. Mount the NFS share again, very rarely works on the first try 4. Start plex once the share is mounted successfully again stylophora-diagnostics-20181231-1834.zip
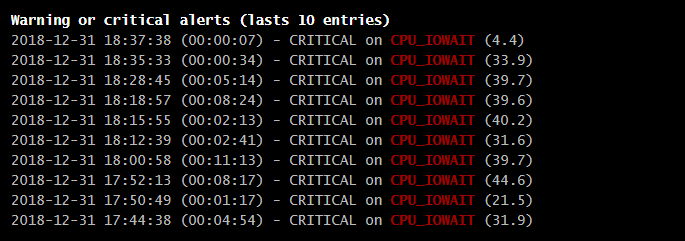

-
Testing it now. Set the share up as a separate library so the setup should be identical now.
-
Try this then. It should be in there. I see the logs of it not responding. stylophora-diagnostics-20181230-1314.zip


