kimocal
Members
-
Joined
-
Last visited
Everything posted by kimocal
-
Have you been able to get the IPMI working yet?
-
Fan control is the next thing I need to work on. I was able to get the fan speeds to get reported finally.
-
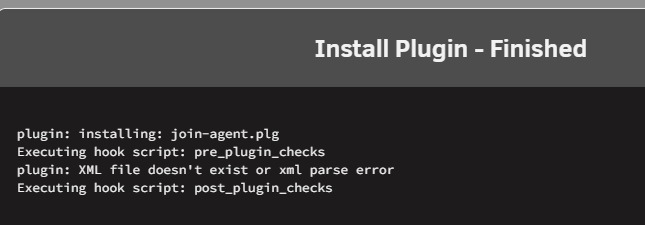
I recently upgraded rom 6.12 to 7.2. The Join notification agent is no longer listed under Settings --> Notification Settings --> Notification Agents. I had found a related post elsewhere on the forums here. Officially posting to the Bug Reports. Diagnostics attached. megamind-diagnostics-20251106-1013.zipCreated and moved all 3 files to the appropriate locations. Tried doing the Install Plugin and was getting an error saying the XML does not exist or xml parse error: I then rebooted unraid and the plugin disappeared from the /boot/config/plugins/ folder. Re-copied join-agent.plg to the plugins folder. Tried to re-install the plugin and get the same error as above. I even tried copying the XML to /usr/local/emhttp/plugins/dynamix/agents/Join.xml Nothing appears to exist at /var/log/notify_Join No worries on trying to get this to work. I've transitioned over to Telegram to centralize and organize my unraid and related notifications better. If you want me to keep testing though I can. Thanks for trying to help.
 I have the Asus Pro WS Z890-ACE SE running 7.2.0 and I don't see any errors like that in my my syslog. I only see these: Nov 5 19:21:47 Megamind root: error log : /var/log/graphql-api.log Nov 5 19:22:09 Megamind kernel: ACPI BIOS Error (bug): Failure creating named object [\_SB.PC00.RP01.PXSX._DSM.USRG], AE_ALREADY_EXISTS (20240827/dsfield-184) As a side note how are you liking the w880? That was one was my second choice but wanted the 10G NIC.It was located under the Settings --> Notifications like all the other modes. Where would I find the JOIN xml? Doing a quick search of my flash backup I did find this bash script, join.sh. Copy and pasted below as it's pretty basic. I've removed my API key. #!/bin/bash ########## API_KEY="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" TITLE="$SUBJECT" MESSAGE="$DESCRIPTION" ########## TITLE=$(echo -e "$TITLE") MESSAGE=$(echo -e "$MESSAGE") curl -s -k -G \ -d "apikey=$API_KEY" \ --data-urlencode "title=$TITLE" \ --data-urlencode "text=$MESSAGE" \ -d "deviceId=group.all" \ https://joinjoaomgcd.appspot.com/_ah/api/messaging/v1/sendPush 2>&1 Join.shI too am missing the JOIN notification agent I had previously on 6.12. I upgraded to 7.2.Did you merge these systems? Im about to do the same.Oh nice. Have fun with itWhat repo are you using? I am using this one as I have a Tesla P4. Post a pic of your container config to compare.
I have the Asus Pro WS Z890-ACE SE running 7.2.0 and I don't see any errors like that in my my syslog. I only see these: Nov 5 19:21:47 Megamind root: error log : /var/log/graphql-api.log Nov 5 19:22:09 Megamind kernel: ACPI BIOS Error (bug): Failure creating named object [\_SB.PC00.RP01.PXSX._DSM.USRG], AE_ALREADY_EXISTS (20240827/dsfield-184) As a side note how are you liking the w880? That was one was my second choice but wanted the 10G NIC.It was located under the Settings --> Notifications like all the other modes. Where would I find the JOIN xml? Doing a quick search of my flash backup I did find this bash script, join.sh. Copy and pasted below as it's pretty basic. I've removed my API key. #!/bin/bash ########## API_KEY="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" TITLE="$SUBJECT" MESSAGE="$DESCRIPTION" ########## TITLE=$(echo -e "$TITLE") MESSAGE=$(echo -e "$MESSAGE") curl -s -k -G \ -d "apikey=$API_KEY" \ --data-urlencode "title=$TITLE" \ --data-urlencode "text=$MESSAGE" \ -d "deviceId=group.all" \ https://joinjoaomgcd.appspot.com/_ah/api/messaging/v1/sendPush 2>&1 Join.shI too am missing the JOIN notification agent I had previously on 6.12. I upgraded to 7.2.Did you merge these systems? Im about to do the same.Oh nice. Have fun with itWhat repo are you using? I am using this one as I have a Tesla P4. Post a pic of your container config to compare.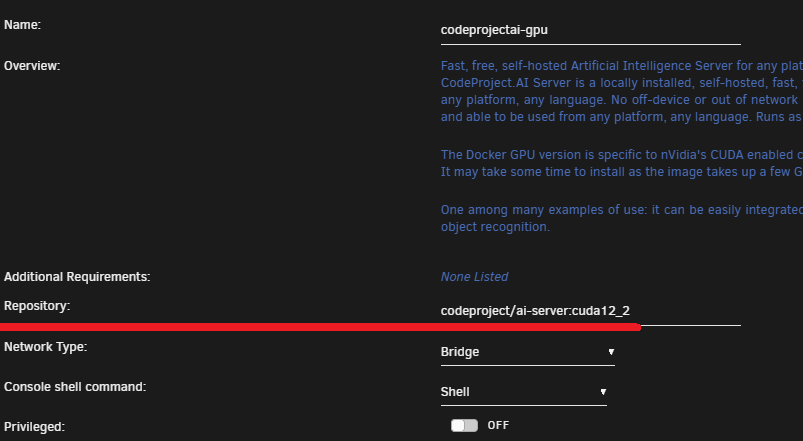 Access your CP AI IP and Port Then click the appropriate INSTALL for the module you want. Be patient as it takes time.
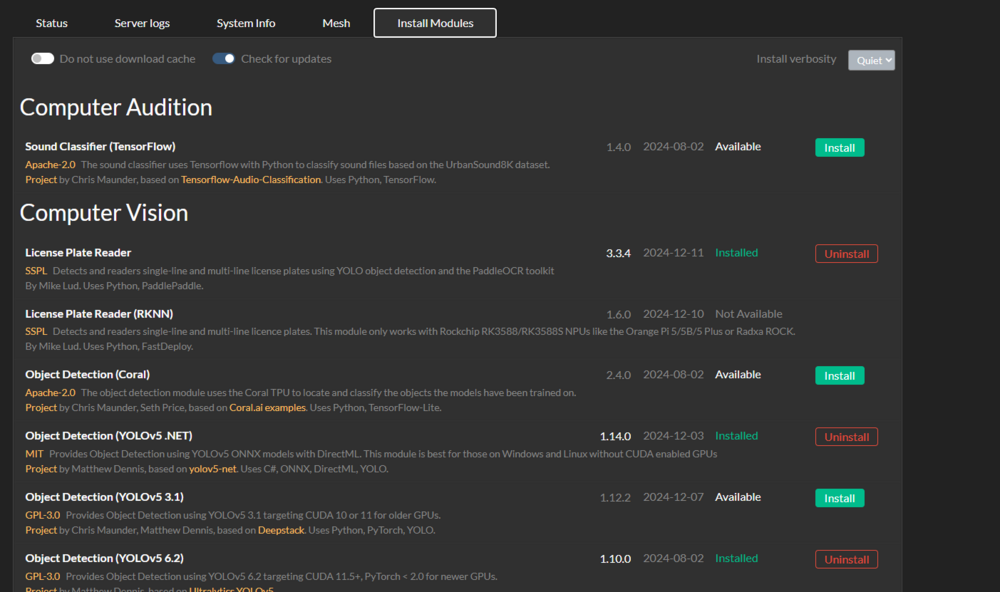
Access your CP AI IP and Port Then click the appropriate INSTALL for the module you want. Be patient as it takes time.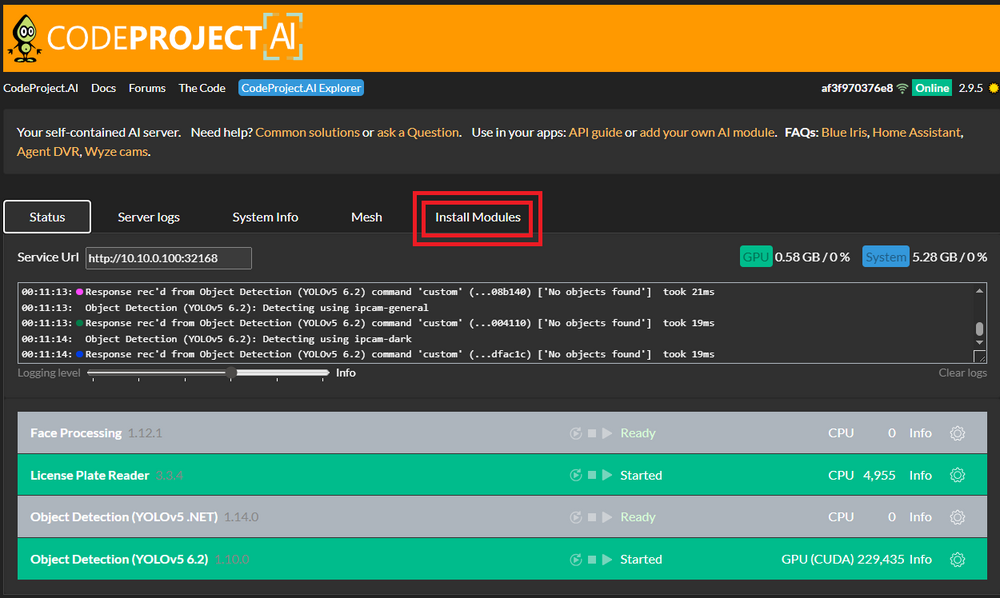
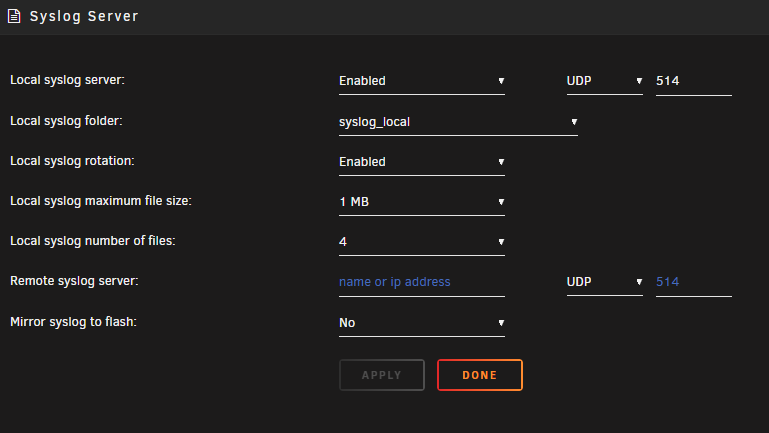
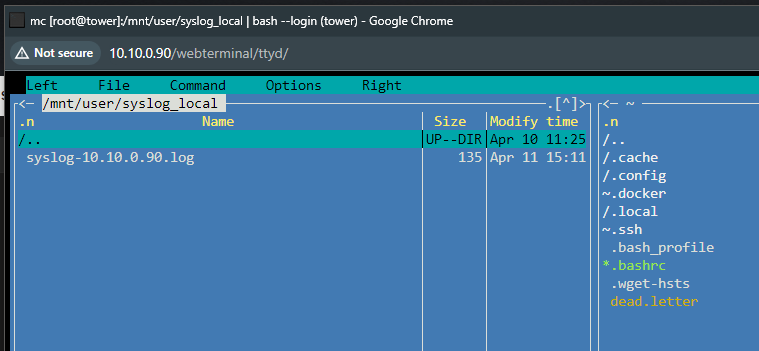
 No. The inference times of the LPR on CPU are pretty quick. YOLO uses the GPU. It's working at the moment as is so I haven't tinkered with it since. Currently on 2.6.5.I'm currently running this container with Repository: codeproject/ai-server:cuda12_2 I have a Tesla P4 installed. Object Detection (YOLOv5 6.2) 1.9.1 is running great with the GPU. Does anybody know how to or if the License Plate Reader module can use the GPU? Every time I try enabling GPU it reverts back to CPU. Also if I update YOLOv5 6.2 to 1.9.2 it seems to break GPU functionality.My wife and I are the only users for our nextcloud instance. We recently started having an issue where the connection will die and I will have to restart the container. Attached is my syslog I am getting from the syslog server. Any ideas based upon the syslog? Apr 11 15:11:14 tower rsyslogd: [origin software="rsyslogd" swVersion="8.2102.0" x-pid="23380" x-info="https://www.rsyslog.com"] start Apr 11 15:14:33 tower ool www[30194]: /usr/local/emhttp/plugins/dynamix/scripts/rsyslog_config Apr 11 15:14:35 tower rsyslogd: [origin software="rsyslogd" swVersion="8.2102.0" x-pid="30614" x-info="https://www.rsyslog.com"] start Apr 11 16:35:02 tower kernel: docker0: port 2(veth048550e) entered disabled state Apr 11 16:35:02 tower kernel: veth4f0e390: renamed from eth0 Apr 11 16:35:02 tower kernel: docker0: port 2(veth048550e) entered disabled state Apr 11 16:35:02 tower kernel: device veth048550e left promiscuous mode Apr 11 16:35:02 tower kernel: docker0: port 2(veth048550e) entered disabled state Apr 11 16:35:02 tower kernel: docker0: port 2(veth4583332) entered blocking state Apr 11 16:35:02 tower kernel: docker0: port 2(veth4583332) entered disabled state Apr 11 16:35:02 tower kernel: device veth4583332 entered promiscuous mode Apr 11 16:35:02 tower kernel: docker0: port 2(veth4583332) entered blocking state Apr 11 16:35:02 tower kernel: docker0: port 2(veth4583332) entered forwarding state Apr 11 16:35:02 tower kernel: eth0: renamed from veth4daad3b Apr 11 16:35:02 tower kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth4583332: link becomes ready Apr 11 16:35:02 tower kernel: docker0: port 9(vethdcf57da) entered disabled state Apr 11 16:35:02 tower kernel: veth0389db9: renamed from eth0 Apr 11 16:35:03 tower kernel: docker0: port 9(vethdcf57da) entered disabled state Apr 11 16:35:03 tower kernel: device vethdcf57da left promiscuous mode Apr 11 16:35:03 tower kernel: docker0: port 9(vethdcf57da) entered disabled state Apr 11 16:35:03 tower kernel: docker0: port 9(vethd8cddd5) entered blocking state Apr 11 16:35:03 tower kernel: docker0: port 9(vethd8cddd5) entered disabled state Apr 11 16:35:03 tower kernel: device vethd8cddd5 entered promiscuous mode Apr 11 16:35:03 tower kernel: docker0: port 9(vethd8cddd5) entered blocking state Apr 11 16:35:03 tower kernel: docker0: port 9(vethd8cddd5) entered forwarding state Apr 11 16:35:03 tower kernel: eth0: renamed from veth976f3a7 Apr 11 16:35:03 tower kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vethd8cddd5: link becomes ready Apr 11 17:15:04 tower kernel: veth2e3f8cd: renamed from eth0 Apr 11 17:15:04 tower kernel: eth0: renamed from veth79ca70e**UPDATE** I forgot to add the IP of the sever in the remote part. It's working now. ____________________________________________________________________________ I am running unraid 6.12.3 on this server at the moment. Currently trying to troubleshoot a Nextcloud container of it needing a restart every once in a while. I set-up the local syslog server per the directions in this post with the following settings initially: I didn't see anything in the syslog_local share after 24 hours. I then changed the syslog server settings to this: I've been letting it run and I am still not seeing anything in the syslog_local share: Thoughts?
No. The inference times of the LPR on CPU are pretty quick. YOLO uses the GPU. It's working at the moment as is so I haven't tinkered with it since. Currently on 2.6.5.I'm currently running this container with Repository: codeproject/ai-server:cuda12_2 I have a Tesla P4 installed. Object Detection (YOLOv5 6.2) 1.9.1 is running great with the GPU. Does anybody know how to or if the License Plate Reader module can use the GPU? Every time I try enabling GPU it reverts back to CPU. Also if I update YOLOv5 6.2 to 1.9.2 it seems to break GPU functionality.My wife and I are the only users for our nextcloud instance. We recently started having an issue where the connection will die and I will have to restart the container. Attached is my syslog I am getting from the syslog server. Any ideas based upon the syslog? Apr 11 15:11:14 tower rsyslogd: [origin software="rsyslogd" swVersion="8.2102.0" x-pid="23380" x-info="https://www.rsyslog.com"] start Apr 11 15:14:33 tower ool www[30194]: /usr/local/emhttp/plugins/dynamix/scripts/rsyslog_config Apr 11 15:14:35 tower rsyslogd: [origin software="rsyslogd" swVersion="8.2102.0" x-pid="30614" x-info="https://www.rsyslog.com"] start Apr 11 16:35:02 tower kernel: docker0: port 2(veth048550e) entered disabled state Apr 11 16:35:02 tower kernel: veth4f0e390: renamed from eth0 Apr 11 16:35:02 tower kernel: docker0: port 2(veth048550e) entered disabled state Apr 11 16:35:02 tower kernel: device veth048550e left promiscuous mode Apr 11 16:35:02 tower kernel: docker0: port 2(veth048550e) entered disabled state Apr 11 16:35:02 tower kernel: docker0: port 2(veth4583332) entered blocking state Apr 11 16:35:02 tower kernel: docker0: port 2(veth4583332) entered disabled state Apr 11 16:35:02 tower kernel: device veth4583332 entered promiscuous mode Apr 11 16:35:02 tower kernel: docker0: port 2(veth4583332) entered blocking state Apr 11 16:35:02 tower kernel: docker0: port 2(veth4583332) entered forwarding state Apr 11 16:35:02 tower kernel: eth0: renamed from veth4daad3b Apr 11 16:35:02 tower kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth4583332: link becomes ready Apr 11 16:35:02 tower kernel: docker0: port 9(vethdcf57da) entered disabled state Apr 11 16:35:02 tower kernel: veth0389db9: renamed from eth0 Apr 11 16:35:03 tower kernel: docker0: port 9(vethdcf57da) entered disabled state Apr 11 16:35:03 tower kernel: device vethdcf57da left promiscuous mode Apr 11 16:35:03 tower kernel: docker0: port 9(vethdcf57da) entered disabled state Apr 11 16:35:03 tower kernel: docker0: port 9(vethd8cddd5) entered blocking state Apr 11 16:35:03 tower kernel: docker0: port 9(vethd8cddd5) entered disabled state Apr 11 16:35:03 tower kernel: device vethd8cddd5 entered promiscuous mode Apr 11 16:35:03 tower kernel: docker0: port 9(vethd8cddd5) entered blocking state Apr 11 16:35:03 tower kernel: docker0: port 9(vethd8cddd5) entered forwarding state Apr 11 16:35:03 tower kernel: eth0: renamed from veth976f3a7 Apr 11 16:35:03 tower kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vethd8cddd5: link becomes ready Apr 11 17:15:04 tower kernel: veth2e3f8cd: renamed from eth0 Apr 11 17:15:04 tower kernel: eth0: renamed from veth79ca70e**UPDATE** I forgot to add the IP of the sever in the remote part. It's working now. ____________________________________________________________________________ I am running unraid 6.12.3 on this server at the moment. Currently trying to troubleshoot a Nextcloud container of it needing a restart every once in a while. I set-up the local syslog server per the directions in this post with the following settings initially: I didn't see anything in the syslog_local share after 24 hours. I then changed the syslog server settings to this: I've been letting it run and I am still not seeing anything in the syslog_local share: Thoughts?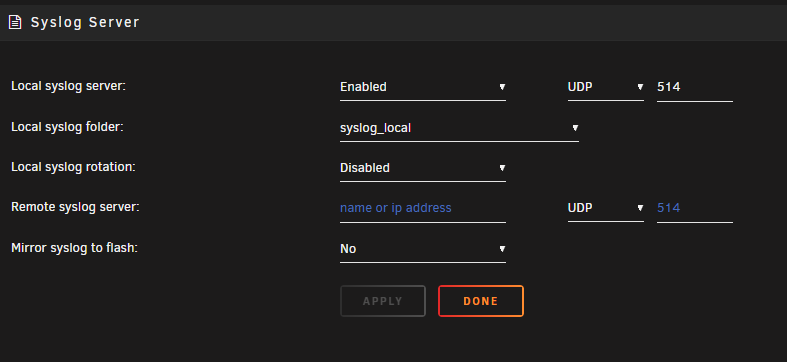
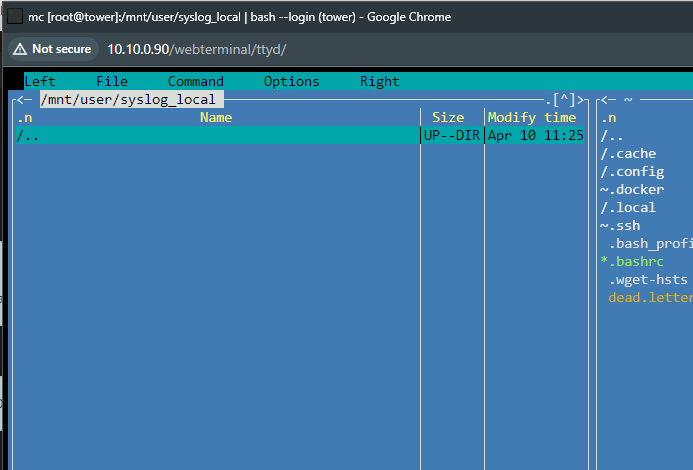
 **FIX** Force Update the containers to get the WebUI link again. I upgraded both of my 6.9.2 boxes to 6.12.1 and there are no WebUI links when accessing the docker containers: unRAID server #1 unRaid server #2 I can still access them when plugging in the correct IP:port Diagnostics attached. server01-diagnostics-20230621-1533.zip server02-diagnostics-20230621-1533.zip Tried multiple web browsers (Chrome, Firefox, Brave) and also cleared the cache on the browsers. No difference.Is anyone else's container not downloading? It was working fine a day ago for me. Edit #1 Appears that it can't connect to eweka: TLS handshake failed for news.eweka.nl I'm using PIA and OpenVPN. Edit #2 I swapped over to Wireguard to see if there is a difference. Getting the same error. I then tried changing the port to 119 and setting Encryption to No and it is able to connect. Setting CertCheck to No doesn't make a difference either with SSL enabled. Edit #3 So if using port 119 and wireguard is up it should be safe to run it that way? I am no longer encrypted, correct or does it still use PIA to mask the traffic if using 119? Another weird thing is that I restart NZBgetvpn after setting port 119, I can successfully connect to eweka, but then nothing downloads still. Edit #4 I tried using GrabIt on my Win box and was able to connect to eweka without any issue. Really at a loss now with NZBget 😕 Edit #5 I ran this command from the unraid terminal & container console: openssl s_client -showcerts -connect news.website:563 The terminal returns a cert but the container gets stuck on CONNECTED(00000003) Edit #6 It must eweka as I am able to use newsdemon without any issue on their ssl ports =P Edit#7 Last update for the time being. I disabled the VPN part of the container and eweka connects fine now over both SSL ports. Maybe PIA updated something recently that broke the ability to connect. I tried routing the nzbget container traffic through a binhex-privoxy container with PIA and same issues happens.I have a general best practices question. Are there any issues to consider when running multiple DBs in one MariaDB container? I originally setup MariaDB to be used with Nextcloud. I then created another DB to use with my HomeAssistant VM. Both have been working great. I'm about to add another DB for SuiteCRM to the same MariaDB docker instance. Is it best/better practice to have multiple MariaDB dockers for this scenario or should there not be any real issues doing this? There will only be 2 users with SuiteCRM. There are currently only 2 Nextcloud users too.I don't know why it won't work when placed in the AppData location but I downloaded the cert.pem file linked above and placed it in my "Downloads" folder. I then modified the settings in NZBGETVPN and it started downloading just now.
**FIX** Force Update the containers to get the WebUI link again. I upgraded both of my 6.9.2 boxes to 6.12.1 and there are no WebUI links when accessing the docker containers: unRAID server #1 unRaid server #2 I can still access them when plugging in the correct IP:port Diagnostics attached. server01-diagnostics-20230621-1533.zip server02-diagnostics-20230621-1533.zip Tried multiple web browsers (Chrome, Firefox, Brave) and also cleared the cache on the browsers. No difference.Is anyone else's container not downloading? It was working fine a day ago for me. Edit #1 Appears that it can't connect to eweka: TLS handshake failed for news.eweka.nl I'm using PIA and OpenVPN. Edit #2 I swapped over to Wireguard to see if there is a difference. Getting the same error. I then tried changing the port to 119 and setting Encryption to No and it is able to connect. Setting CertCheck to No doesn't make a difference either with SSL enabled. Edit #3 So if using port 119 and wireguard is up it should be safe to run it that way? I am no longer encrypted, correct or does it still use PIA to mask the traffic if using 119? Another weird thing is that I restart NZBgetvpn after setting port 119, I can successfully connect to eweka, but then nothing downloads still. Edit #4 I tried using GrabIt on my Win box and was able to connect to eweka without any issue. Really at a loss now with NZBget 😕 Edit #5 I ran this command from the unraid terminal & container console: openssl s_client -showcerts -connect news.website:563 The terminal returns a cert but the container gets stuck on CONNECTED(00000003) Edit #6 It must eweka as I am able to use newsdemon without any issue on their ssl ports =P Edit#7 Last update for the time being. I disabled the VPN part of the container and eweka connects fine now over both SSL ports. Maybe PIA updated something recently that broke the ability to connect. I tried routing the nzbget container traffic through a binhex-privoxy container with PIA and same issues happens.I have a general best practices question. Are there any issues to consider when running multiple DBs in one MariaDB container? I originally setup MariaDB to be used with Nextcloud. I then created another DB to use with my HomeAssistant VM. Both have been working great. I'm about to add another DB for SuiteCRM to the same MariaDB docker instance. Is it best/better practice to have multiple MariaDB dockers for this scenario or should there not be any real issues doing this? There will only be 2 users with SuiteCRM. There are currently only 2 Nextcloud users too.I don't know why it won't work when placed in the AppData location but I downloaded the cert.pem file linked above and placed it in my "Downloads" folder. I then modified the settings in NZBGETVPN and it started downloading just now.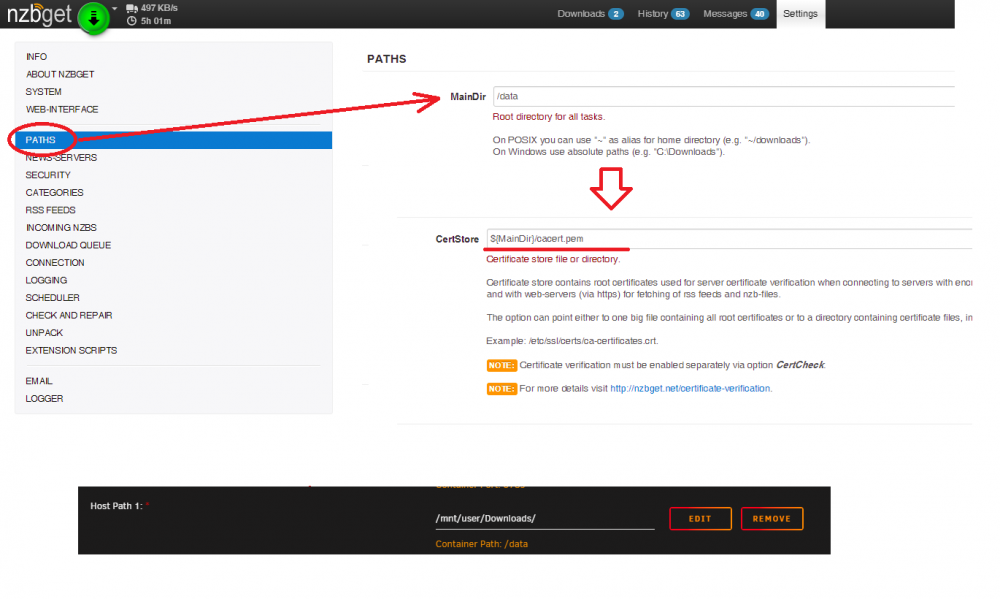 I don't know if it will work for this docker but for the jshridha/docker-nzbgetvpn version, I copied the cert.pem file from here and placed it in my "Downloads" folder. I then modified the settings in NZBGETVPN and it started downloading just now.
I don't know if it will work for this docker but for the jshridha/docker-nzbgetvpn version, I copied the cert.pem file from here and placed it in my "Downloads" folder. I then modified the settings in NZBGETVPN and it started downloading just now.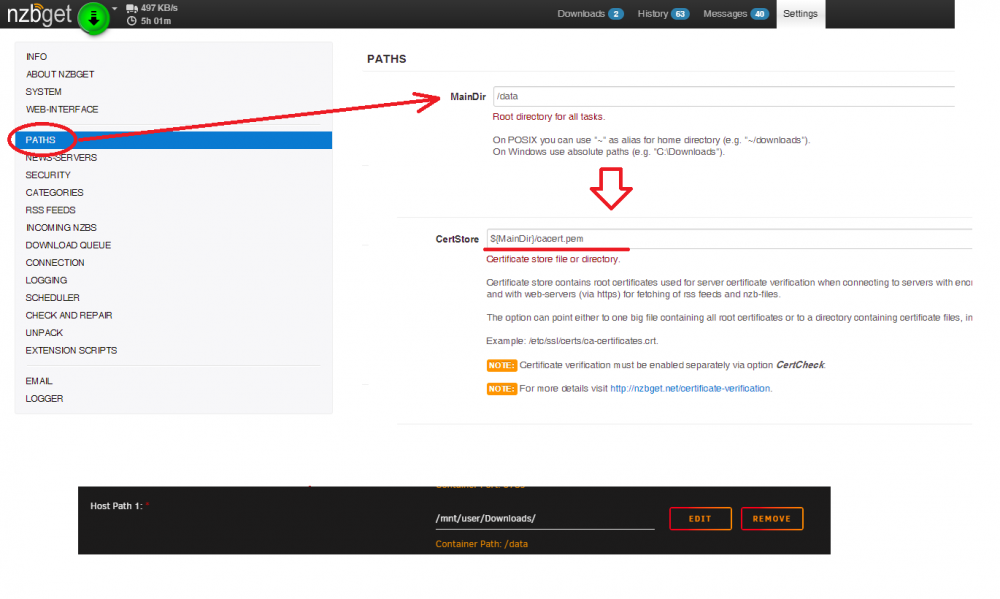 This fixed the recently connection issues I've been having too with the PIA VPN in nzbgetvpn.Thanks @uberchuckie It's up and running. I pointed to my Maria DB docker so not sure if that's what fixed it. I was able to add my Ubiquiti ER-X device for it to monitor, as all I'm really interested in is tracking my monthly data usage thru my ISP. Beyond that I haven't had much time to tinker with it though.I too am having the issue of the default login/password not working. I've stopped the container, deleted the contents of the appdata folder, and restarted. I've also deleted the container image and reinstalled it. Sometimes when accessing the webinterface it gives this error: DB Error 2002: No such file or directory A common item I've seen in the logs is this error: [0;35m o [1;37mMySQL [0m ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION And then after it's been running for a while it seems to repeat this MariaDB entry: Starting MariaDB... 200731 10:43:51 mysqld_safe Logging to '/config/databases/ea65e1ef1086.err'. 200731 10:43:51 mysqld_safe Starting mariadbd daemon with databases from /config/databases Database exists. Starting MariaDB... 200731 10:43:52 mysqld_safe Logging to '/config/databases/ea65e1ef1086.err'. 200731 10:43:52 mysqld_safe Starting mariadbd daemon with databases from /config/databases Database exists. Starting MariaDB... 200731 10:43:53 mysqld_safe Logging to '/config/databases/ea65e1ef1086.err'. 200731 10:43:53 mysqld_safe Starting mariadbd daemon with databases from /config/databases Database exists. Starting MariaDB... 200731 10:43:54 mysqld_safe Logging to '/config/databases/ea65e1ef1086.err'. 200731 10:43:54 mysqld_safe Starting mariadbd daemon with databases from /config/databases Database exists. Starting MariaDB... 200731 10:43:55 mysqld_safe Logging to '/config/databases/ea65e1ef1086.err'. 200731 10:43:55 mysqld_safe Starting mariadbd daemon with databases from /config/databases Attached is a C&P of the Observium log. I've also tried running the container as Privileged. I'm running unRAID 6.8.3. **EDIT** I also haven't touch the config.php in the Observium appdata folder. Are we able to point to an existing MariaDB container? **EDIT #2** Somehow got it working. I edited the config.php to point to my MariaDB Container used by other containers. // Database config --- This MUST be configured $config['db_extension'] = 'mysqli'; $config['db_host'] = '10.0.0.90:3306'; $config['db_user'] = 'observium'; $config['db_pass'] = 'xxxxxxxxxxxxxxxxxx'; //<--- SAME PASSWORD GENERATED IN OBSERVIUM LOGS $config['db_name'] = 'observium'; // Base directory #$config['install_dir'] = "/opt/observium"; // Default community list to use when adding/discovering $config['snmp']['community'] = array("public"); // Authentication Model $config['auth_mechanism'] = "mysql"; // default, other options: ldap, http-auth, please see documentation for config help // Enable alerter // $config['poller-wrapper']['alerter'] = TRUE; //$config['web_show_disabled'] = FALSE; // Show or not disabled devices on major pages. // Set up a default alerter (email to a single address) //$config['email']['default'] = "user@your-domain"; //$config['email']['from'] = "Observium <observium@your-domain>"; //$config['email']['default_only'] = TRUE; // End config.php I also edited with the Observium docker container settings by enabling Privileged, deleted the files except the edited config.php and lo and behold it's working now. No idea what the problem was. Observium_LOG_07312020.txt
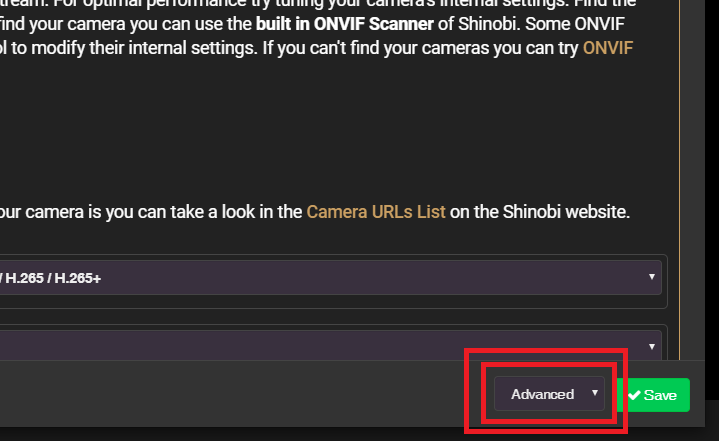
This fixed the recently connection issues I've been having too with the PIA VPN in nzbgetvpn.Thanks @uberchuckie It's up and running. I pointed to my Maria DB docker so not sure if that's what fixed it. I was able to add my Ubiquiti ER-X device for it to monitor, as all I'm really interested in is tracking my monthly data usage thru my ISP. Beyond that I haven't had much time to tinker with it though.I too am having the issue of the default login/password not working. I've stopped the container, deleted the contents of the appdata folder, and restarted. I've also deleted the container image and reinstalled it. Sometimes when accessing the webinterface it gives this error: DB Error 2002: No such file or directory A common item I've seen in the logs is this error: [0;35m o [1;37mMySQL [0m ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION And then after it's been running for a while it seems to repeat this MariaDB entry: Starting MariaDB... 200731 10:43:51 mysqld_safe Logging to '/config/databases/ea65e1ef1086.err'. 200731 10:43:51 mysqld_safe Starting mariadbd daemon with databases from /config/databases Database exists. Starting MariaDB... 200731 10:43:52 mysqld_safe Logging to '/config/databases/ea65e1ef1086.err'. 200731 10:43:52 mysqld_safe Starting mariadbd daemon with databases from /config/databases Database exists. Starting MariaDB... 200731 10:43:53 mysqld_safe Logging to '/config/databases/ea65e1ef1086.err'. 200731 10:43:53 mysqld_safe Starting mariadbd daemon with databases from /config/databases Database exists. Starting MariaDB... 200731 10:43:54 mysqld_safe Logging to '/config/databases/ea65e1ef1086.err'. 200731 10:43:54 mysqld_safe Starting mariadbd daemon with databases from /config/databases Database exists. Starting MariaDB... 200731 10:43:55 mysqld_safe Logging to '/config/databases/ea65e1ef1086.err'. 200731 10:43:55 mysqld_safe Starting mariadbd daemon with databases from /config/databases Attached is a C&P of the Observium log. I've also tried running the container as Privileged. I'm running unRAID 6.8.3. **EDIT** I also haven't touch the config.php in the Observium appdata folder. Are we able to point to an existing MariaDB container? **EDIT #2** Somehow got it working. I edited the config.php to point to my MariaDB Container used by other containers. // Database config --- This MUST be configured $config['db_extension'] = 'mysqli'; $config['db_host'] = '10.0.0.90:3306'; $config['db_user'] = 'observium'; $config['db_pass'] = 'xxxxxxxxxxxxxxxxxx'; //<--- SAME PASSWORD GENERATED IN OBSERVIUM LOGS $config['db_name'] = 'observium'; // Base directory #$config['install_dir'] = "/opt/observium"; // Default community list to use when adding/discovering $config['snmp']['community'] = array("public"); // Authentication Model $config['auth_mechanism'] = "mysql"; // default, other options: ldap, http-auth, please see documentation for config help // Enable alerter // $config['poller-wrapper']['alerter'] = TRUE; //$config['web_show_disabled'] = FALSE; // Show or not disabled devices on major pages. // Set up a default alerter (email to a single address) //$config['email']['default'] = "user@your-domain"; //$config['email']['from'] = "Observium <observium@your-domain>"; //$config['email']['default_only'] = TRUE; // End config.php I also edited with the Observium docker container settings by enabling Privileged, deleted the files except the edited config.php and lo and behold it's working now. No idea what the problem was. Observium_LOG_07312020.txt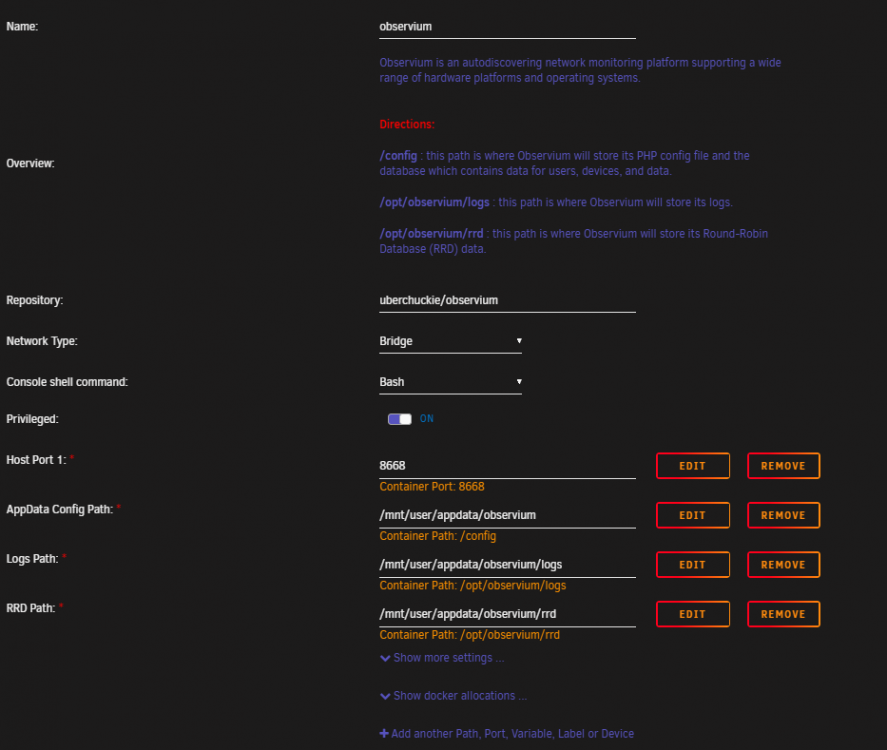 When editing a monitor/camera, be sure to turn on Advanced Settings:
When editing a monitor/camera, be sure to turn on Advanced Settings: