




neurocis
Members
-
Joined
-
Last visited
-
@SimonF Feature request: Would it be possible on the send dialogue, after clicking SEND to the right of an existing snapshot, to have an override that allows one to override to a full snap send instead of whatever is defaulted (I believe at original creation time). As the default selection is for snaps to be sent as incremental this would make seeding the initial snap much more intuitive IMO. Thanks!
-
Rolled back to 6.11.5 issues were so bad, server was up for over 6 months until update. hard freeze every other day, nothing in logs. Docker containers would not release resources consistently having to reboot for that as well. Not posting a diagnostics, sorry I have to have a running server.
-
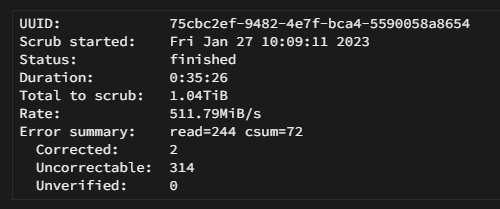
Succeeded on my one unraid box, failed on the other. digging deeper: Looks like I have some corruption to address & maybe some memory to test as it is a RAID 1. Tried to send on my other unraid, worked a charm, so alright then, not the plugin's fault there. Now have to figure out how configuring incremental sends would work as I am confused on automating that cycle with the way the dialogues are. I can get a full to send, and send manually, but incremental eludes me other than having to send the first (full) manually. i.e. How to automate the Full - Incr - Incr - Incr - Full - Incr -Incr - Incr --- cycle? Edit: Nevermind, I have to change my classical thinking. If I manually seed the last snap all will proceed well, it then just becomes a question of pruning the export target snaps. Thanks!
-
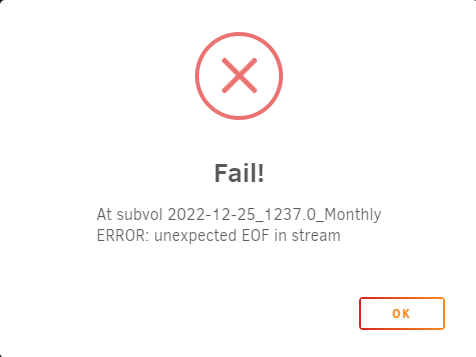
Hi, just checking in on Snapshot Send functionality and issue I had reported earlier. Let me know if I can assist in any way! Thanks!
-
Hi, thanks for this, after clearing the persistent store a couple times I am still having this crash: You may download the recommended models (about 10GB total), select a customized set, or completely skip this step. Download <r>ecommended models, <a>ll models, <c>ustomized list, or <s>kip this step? [r]: A problem occurred during initialization. The error was: "EOF when reading a line" Traceback (most recent call last): File "/InvokeAI/ldm/invoke/CLI.py", line 96, in main gen = Generate( File "/InvokeAI/ldm/generate.py", line 160, in __init__ mconfig = OmegaConf.load(conf) File "/venv/lib/python3.10/site-packages/omegaconf/omegaconf.py", line 189, in load with io.open(os.path.abspath(file_), "r", encoding="utf-8") as f: FileNotFoundError: [Errno 2] No such file or directory: '/userfiles/configs/models.yaml' During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/InvokeAI/scripts/configure_invokeai.py", line 780, in main errors.add(download_weights(opt)) File "/InvokeAI/scripts/configure_invokeai.py", line 597, in download_weights choice = user_wants_to_download_weights() File "/InvokeAI/scripts/configure_invokeai.py", line 127, in user_wants_to_download_weights choice = input('Download <r>ecommended models, <a>ll models, <c>ustomized list, or <s>kip this step? [r]: ') EOFError: EOF when reading a line I was able to resolve this by mkdir /userfiles/configs , rebuilding the container (error again - missing file) then, cp -r /invokeai/configs/stable-diffusion /userfiles/configs/. Appears there is an expectation that configs exists pre, ready for the models.yaml file and stable-diffusion prefs. Newb to this so more than likely this is a hack. Cheers! Ref: https://github.com/invoke-ai/InvokeAI/issues/1420
-
This worked for me: in /boot/config/ssh/sshd_conf added: HostKeyAlgorithms=ssh-rsa,[email protected] PubkeyAcceptedAlgorithms=+ssh-rsa,[email protected] Either reboot or "cp /boot/config/ssh/sshd_conf /etc/ssh/" and restart sshd. Ref: https://unix.stackexchange.com/questions/674582/how-to-enable-ssh-rsa-in-sshd-of-openssh-8-8 Edit: I also just noticed on my secondary system that in sshd_conf I had to enable PubkeyAuthentication as it was #commented : PubkeyAuthentication yes Edit+: Additionally, if you are desiring to sign in as an alternate user to root, do not forget to setup their home directory & shell in /boot/config/passwd and /etc/passwd
-
And here I don't have anything for you for Christmas! Is there a place I can buy you a coffee? Updated and pruning is now working. Cheers m8.
-
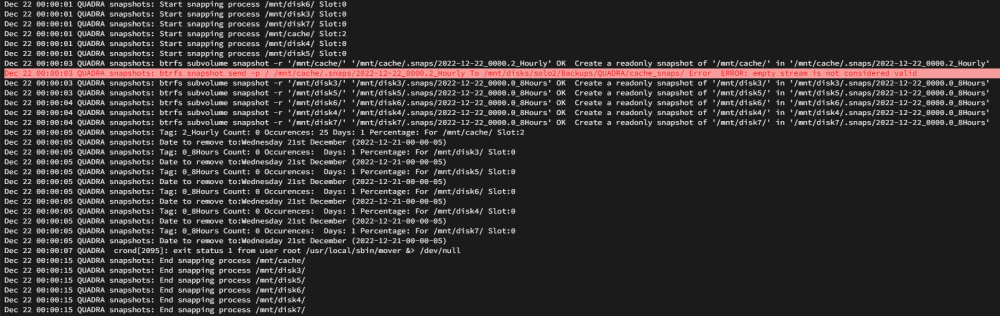
So yes, this is interesting: Send location is specified as the default: I will review the repo tonight probably, see what I can contribute. Thanks!


-
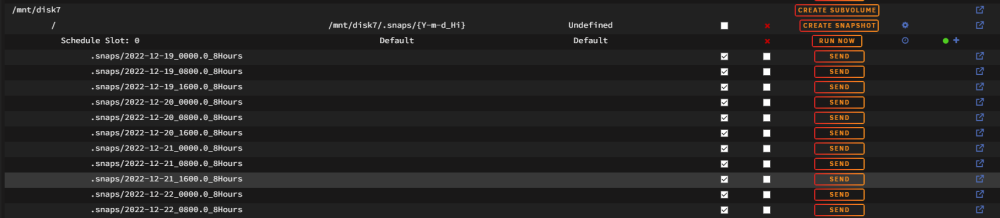
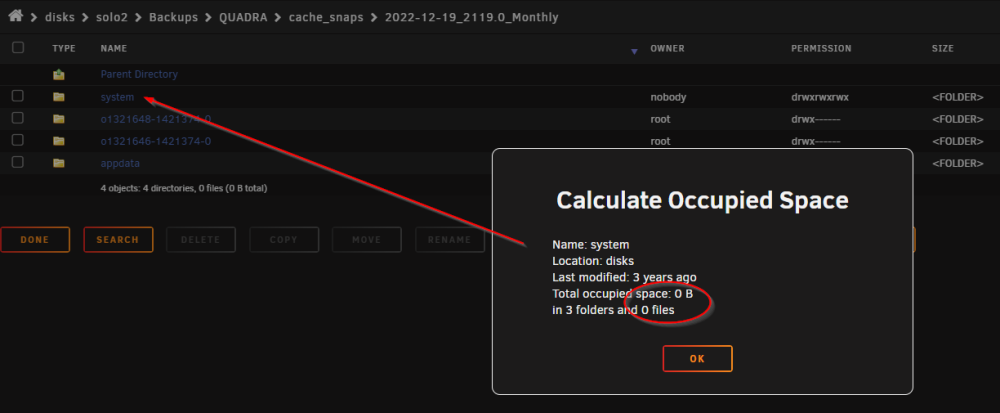
Hi @SimonF, Is there a GitHUB repo for this plugin if one wanted to contribute? Also my snapshots do not seem to be pruning by the retention settings for me, is there a known issue there? let me know what details I can provide. Lastly, I am sure I am misunderstanding but I am having issues sending snapshots as well, so far just local from Cache root to a spinny disk. I get the subfolder but the contents are all wonky. Once again let me know what details I can provide. Folders, but no data in the sent subvolume, it is like an incremental but options are set for full. Cheers!


-
Just had need to reboot and it/array mounted fine.
-
OK, found following thread: Sounds very familiar. Unfortunately these drives have been in use in this array configuration for at least a year and I have snapshot tasks that run against them which is why they are btrfs. Guess reboots are manual intervention until ( if this ) ever gets resolved. Bummer. EDIT: Actually about 3 months ago I edited the array to have 8 disks and moved disk 7 into slot 8 to more accurately reflect my physical layout and rebuilt the array parity, leaving slot 7 empty for future. FYI.
-
Scrub complete, no errors, cleared counters: root@QUAZAR:~# btrfs scrub status /mnt/cache/ UUID: 9e26bfb5-cb8e-4261-afed-937a83aa6106 Scrub started: Sun Jun 26 23:12:38 2022 Status: running Duration: 0:00:20 Time left: 0:05:26 ETA: Sun Jun 26 23:18:29 2022 Total to scrub: 227.32GiB Bytes scrubbed: 13.11GiB (5.77%) Rate: 671.50MiB/s Error summary: no errors found root@QUAZAR:~# btrfs dev stat -z /mnt/cache/ [/dev/sdg1].write_io_errs 0 [/dev/sdg1].read_io_errs 0 [/dev/sdg1].flush_io_errs 0 [/dev/sdg1].corruption_errs 0 [/dev/sdg1].generation_errs 0 [/dev/sdk1].write_io_errs 0 [/dev/sdk1].read_io_errs 0 [/dev/sdk1].flush_io_errs 0 [/dev/sdk1].corruption_errs 0 [/dev/sdk1].generation_errs 0 Stopped docker, unmounted /mnt/cache, stopped array, array stopped. Now the MAIN > Array operation tab only gives me the option to reboot or shutdown, no option to start array, array & cache configs look fine. guess I am rebooting! No glory, same issue exists but now I have no corruption errors
-
More detail, sdi1 may be a red herring (but still strange for a parity to have a btrfs superblock IMO ) in so far as the OP issue : root@QUAZAR:~# btrfs dev stat /mnt/cache/ [/dev/sdg1].write_io_errs 0 [/dev/sdg1].read_io_errs 0 [/dev/sdg1].flush_io_errs 0 [/dev/sdg1].corruption_errs 1 [/dev/sdg1].generation_errs 0 [/dev/sdk1].write_io_errs 0 [/dev/sdk1].read_io_errs 0 [/dev/sdk1].flush_io_errs 0 [/dev/sdk1].corruption_errs 0 [/dev/sdk1].generation_errs 0 root@QUAZAR:~# btrfs scrub start /mnt/cache/ scrub started on /mnt/cache/, fsid 9e26bfb5-cb8e-4261-afed-937a83aa6106 (pid=5914) Waiting to see where this takes us, thinking the corruption error is failing the array start mount of the cache, hoping scrub clears it and I can start the array as normal.
-
Just upgraded to 6.10.3 on primary system and cache drive fails to mount, pertinent log: Jun 26 22:49:12 QUAZAR emhttpd: shcmd (1455): mkdir -p /mnt/cache Jun 26 22:49:12 QUAZAR emhttpd: /mnt/cache uuid: 9e26bfb5-cb8e-4261-afed-937a83aa6106 Jun 26 22:49:12 QUAZAR emhttpd: /mnt/cache ERROR: system chunk array too small 34 < 97 Jun 26 22:49:12 QUAZAR emhttpd: /mnt/cache ERROR: system chunk array too small 34 < 97 Jun 26 22:49:12 QUAZAR emhttpd: /mnt/cache ERROR: superblock checksum matches but it has invalid members Jun 26 22:49:12 QUAZAR emhttpd: /mnt/cache ERROR: superblock checksum matches but it has invalid members Jun 26 22:49:12 QUAZAR emhttpd: /mnt/cache ERROR: cannot scan /dev/sdi1: Input/output error Jun 26 22:49:12 QUAZAR emhttpd: /mnt/cache ERROR: cannot scan /dev/sdi1: Input/output error Jun 26 22:49:12 QUAZAR emhttpd: /mnt/cache Label: none uuid: 9e26bfb5-cb8e-4261-afed-937a83aa6106 Jun 26 22:49:12 QUAZAR emhttpd: /mnt/cache Total devices 2 FS bytes used 80.77GiB Jun 26 22:49:12 QUAZAR emhttpd: /mnt/cache devid 3 size 223.57GiB used 92.48GiB path /dev/sdg1 Jun 26 22:49:12 QUAZAR emhttpd: /mnt/cache devid 5 size 223.57GiB used 92.48GiB path /dev/sdk1 Jun 26 22:49:12 QUAZAR emhttpd: /mnt/cache mount error: Invalid pool config Jun 26 22:49:12 QUAZAR emhttpd: shcmd (1456): umount /mnt/cache Jun 26 22:49:12 QUAZAR root: umount: /mnt/cache: not mounted. If however I manually: root@QUAZAR:~# mkdir -p /mnt/cache root@QUAZAR:~# mount /dev/disk/by-uuid/9e26bfb5-cb8e-4261-afed-937a83aa6106 /mnt/cache root@QUAZAR:~# mount | grep cache /dev/md1 on /mnt/disk1 type btrfs (rw,noatime,space_cache=v2,subvolid=5,subvol=/) /dev/md2 on /mnt/disk2 type btrfs (rw,noatime,space_cache=v2,subvolid=5,subvol=/) /dev/md3 on /mnt/disk3 type btrfs (rw,noatime,space_cache=v2,subvolid=5,subvol=/) /dev/md4 on /mnt/disk4 type btrfs (rw,noatime,space_cache=v2,subvolid=5,subvol=/) /dev/md5 on /mnt/disk5 type btrfs (rw,noatime,space_cache=v2,subvolid=5,subvol=/) /dev/md6 on /mnt/disk6 type btrfs (rw,noatime,space_cache=v2,subvolid=5,subvol=/) /dev/md8 on /mnt/disk8 type btrfs (rw,noatime,space_cache=v2,subvolid=5,subvol=/) /dev/sdg1 on /mnt/cache type btrfs (rw,relatime,ssd,space_cache=v2,subvolid=5,subvol=/) root@QUAZAR:~# ls -al /mnt/cache/ total 16 drwxrwxrwx 1 nobody users 52 Jun 26 04:40 ./ drwxr-xr-x 15 root root 300 Jun 26 22:58 ../ drwxrwx--- 1 nobody users 0 Jun 26 20:55 Svc.nextcloud/ drwxrwxrwx 1 nobody users 874 Nov 9 2021 appdata/ drwxrwxrwx 1 nobody users 26 Feb 1 2019 system/ root@QUAZAR:~# Mounts fine. Strange is that /dev/sdi1 is a parity disk and should not have a btrfs superblock. even if I clear the superblock ( wipefs -a /dev/sdi1 ) it comes back like a bad habit with the next array mount attempt. I have sort of cripple-started my system by mounting the array, manually mounting the cache then restarting docker but that's a bit of gibble. Any ideas on how to resolve this (without trying to rebuild the cache because the config looks accurate it is just keeps thinking /dev/sdi1 is a member for some reason looks like) Thanks!
-
Bump ... fyi i have a build for unraid 6.6.7 - 4.18.20 kernel vbox v5.2.26 if anybody needs it. Cheers.









