




pervin_1
Members
-
Joined
-
Last visited
Everything posted by pervin_1
-
Thank you @Mainfrezzer
-
Thank you @Mainfrezzer. The upgrade to 6.12.6 went smooth, and the RAM-DISK is working perfectly. I appreciate the effort!
-
I went ahead and left the checksums from @Mainfrezzer's script unchanged. Its weird that I initially changed the checksums with my own, and the script aborted itself and threw the error code from @Mainfrezzer's original checksum codes, IDK why. Everything it seems to be working now. I still get about ~5Gb writen per day. But without the script, its about 32Gb daily. There are still uncessary writes, but I am very happy. My two cache drives are Pro 980 Samsung 1Tb models, and they are supposed to last about 600TBW. Which means about 300 years lol. Thank you! Thank you!
-
I am on the 12.4, and updated the compatibility code with my own checksums, and it got aborted upon the boot Error: RAM-Disk Mod found incompatible files: 45361157ef841f9a32a984b056da0564 /etc/rc.d/rc.docker 9f0269a6ca4cf551ef7125b85d7fd4e0 /usr/local/emhttp/plugins/dynamix/scripts/monitor
-
It’s the same version. I did run without the compatibility check, and everything is working from what I see. The RAM disk shows is created in the logs. But I am gonna update it and run again. I remember we used to change the settings for each docker and added additional parameters. It sounds like is no longer the case with the updated script?
-
Ran two md5sum checks on rc.docker and scripts monitor, the checksums are different. Which means I should change the compatibility code, correct? Thank you!
-
Wondering if anyone can help me with questions above? Thanks!
-
I am on 6.12.4, going to try this script. Was on 6.9.x and the old script worked great. With this new script, do I still need to edit the Paraments on my Dockers individually and extra line of code @mgutt @Mainfrezzer? BTW, how do you get the checksum for this script? I see two unique checksum codes. Thank you!
-
Excellent and detailed guide, thank you very much! I pretty much completed the first two steps. But did not want to gamble with the third step since I do have sensitive data with the rest of the containers. Not that the 3rd step is hard to follow, but as you mentioned, you don't want to implement these steps with sensitive information like database, Nextcloud and etc. My basic calculation show that my two NVME Adata drives had in average 180-192GB of random writes daily staring from 2018-2019. Glad randomly decided to read this topic delivered to my email box lol. Noneless, always make sure to have a backup. I made some mistakes, experienced some problems with my appdata folder with the "mover" function. Made a few important dockers unusable. Restored the dockers from the backup, boom - ready to Rock & Roll! Again, I appreciate the effort and all time taken to write this guide! You are awesome!
-
No solution tbh. I am stuck perhaps. We are going to figure this out, eventually. Let me know if you come up with any news or a solution. Would appreciate it!
-
Anybody have any idea why DuckDNS docker works 99% of times, it always succeeds updating my IP address, but when my internet goes down ( IP change overnight ), it fails to update my address with the usual message something went wrong please check your settings. The only to fix it is to restart the docker; then it works again. I would appreciate any help. Thank you in advance!
-
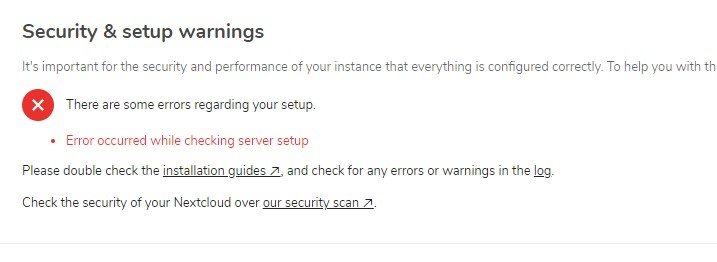
Does anybody have any idea why I am getting this message after upgrading MariaDB 10.3.15 today? Was running Nextcloud 15. Updated to the latest Nextcloud 16, the same error "Error occurred while checking server setup" is still persisting. edit: It had nothing to do with my setup or Maria DB. Checked the logs after, it turns out the Nextcloud.com was down. And that was causing the issues. Because part of the security scan is an online connection to their servers. All good Now!
-
Had the same problem after doing a reverse proxy setup, had to tweak some settings here and there. Are you using Collabora docker like me?
-
Have you found the solution yet? I checked this link to get an idea how to fix it, but I got confused even more at this link
-
Since the Last Unraid Update to 6.5.2, I am getting this error: "noVNC encountered an error" Script Error Here are the couple screenshots running VM and Krusader: Any ideas why? Thank you in advance!!!
-
True, thank you!!!
-
Hey binhex, can you help me with this warning line in the log file, Is it something I should worry about, Everything works just fine, have few extra plugins such as Extractor, Ltconfig, Blocklist and AutoAdd added, please. Thank you!!! 2018-05-03 13:31:19,995 DEBG 'deluge-web-script' stderr output:/usr/lib/python2.7/site-packages/pkg_resources/__init__.py:1235: UserWarning: /home/nobody/.cache/Python-Eggs is writable by group/others and vulnerable to attack when used with get_resource_filename. Consider a more secure location (set with .set_extraction_path or the PYTHON_EGG_CACHE environment variable).warnings.warn(msg, UserWarning)
-
True, I can do that too from the webUI, IDK how my seedbox provider does it through the web page, but after clicking the "restart" button on the webpage on my seedbox panel (BTW seedhost.eu) I can see the AutoDl starts with showing the version and loading trackers, maybe they somehow reload the IRSSI client, anyway, no worries, as you said, I can update the plugin and the settings from the webUI from now on!!! Thank you!!!
-
I don't want to reload the entire container with 500+ Torrents, was wondering if there is a way to reload the AutoDL plugin itself? I used to have a seedbox and there was an option to reload the AutoDL from the webUI, it was a shared seedbox based on Ubuntu.
-
Hey binhex, whats the command to reboot "autodl plugin only" in rtorrent docker? Thanks in advance
-
For someone, who is having issues with plugins like I had with throttle plugin, it was failing to start with webui, for this particular container just add this line to your rtorrent.rc file: execute = {sh,-c,/usr/bin/php /usr/share/webapps/rutorrent/php/initplugins.php web_user_name_goes_here &} Use web_user_name if you have one, which rtorrent requires to sign in. /usr/bin/php is your PHP binary path /usr/share/webapps/rutorrent/php/initplugins.php is the WEBROOT Link for more info https://github.com/Novik/ruTorrent/wiki/Plugins#starting-plugins-with-rtorrent Link for similar issue https://github.com/Novik/ruTorrent/issues/1508
-
Can confirm that everything works on my end, your magic did the trick, you are awesome, binhex!!! BTW forgot to ask, what's "throttle plugin has failed to start"? Does this container have one? Thank you!!! Edit: Never mind, its related to my rtorrent.rc settings, it has to do something with upload_rate and throttle lines I have in the config file, will figure it out myself, no worries, thank you again!!!
-
You are right about the VPN, I was able to run the 2nd container from the same image of your's last week and it worked with VPN enabled just fine, this time I was trying to do without VPN and it kept messing things up, glad to know you are on top it, god bless you and your hard work, binhex. Don't drink too much beer, haha, its addictive, can tell that from my beer belly..
-
Here you go supervisord.log
-
supervisord.log

