




alexdodd
Members
-
Joined
-
Last visited
-
In a long running effort that I dip in and out of once every while*, i'd like to try and install these i2c-tools, python-smbus, python3-smbus, libi2c-dev so I can run a python script to tame my fans in my X8DTH and make them little nicer on my ears. The other solution is to upgrade the motherboard, and i'd be down with that but it's a whole lot of hassle if I could just get the fans to behave somewhat via software. I have i2c-tools ticked off because it was on https://slackware.pkgs.org/ The others, i started with libi2c-dev, it's not available pre-compiled, so i had a go at libi2c-dev from source and using the included autogen.sh to compile / make. After installing, autoconf-2.69-noarch-1, automake-1.15-noarch-1, m4-1.4.17-x86_64-1 i'm still running into this now: aclocal: warning: couldn't open directory 'm4': No such file or directory configure.ac:20: error: possibly undefined macro: AC_PROG_LIBTOOL If this token and others are legitimate, please use m4_pattern_allow. See the Autoconf documentation. autoreconf: /usr/bin/autoconf failed with exit status: 1 Error during autoreconf At which point i feel like i'm pretty deep down a rabbit hole and i'm not entirely sure what harm I can cause.... Surely i'm not the first to give this a go, or there is a simpler method i've overlooked? *I just checked it looks like last December, and then may before that 😂
-
Yeah I set it to cache prefer only to move the bulk of things, and now its set back to cache only, and i'll manually move these files from the disk1 to static, wish me luck The appdata path has never changed, just the underlying physical disk, which i'm not even convinced letsencrypt knows about, so this "move" isn't what the readme is referencing. //Edit: Sweet, nothing exploded, certs still valid, and everything still works!
-
Am I being an idiot? (50/50) In metadata manager > Refresh metadata > Refresh mode: Replace all metadate It says action queued, but I don't know where, or why, or how I force this through, my metadata is correct except for a recent IP and network overhaul, so i just want it to update the path ideally, but was going to just leave it chugging away if possible. I should probably ask this within the Jellyfin community, as I know this is the support thread for the binhex-docker. But its just in case. And i spend more time around these parts currently.
-
I've just moved my appdata to its own cache drive (long overdue). SWAG is the only thing I can't get to totally move, I guess its because the certs are loaded/protected? I set the share to prefer the static cache drive, and disabled docker in settings and run the mover. If i disable docker again and manually move these files will I break something*? (probably ) *I should say i have read the readme and its pretty clear: However does moving the files to the same place on the cache count as moving them?
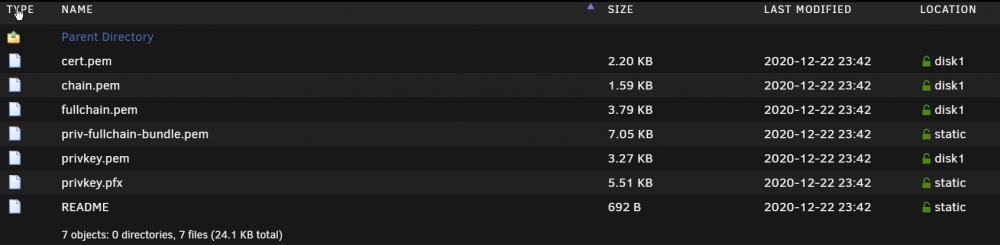
-
This really helped my thnking! Thanks!
-
Sweet and big thanks for the quick turnaroundand everything you do!
-
A few a second? How do the drives stay spun down if so?
-
Sweet, sorry I missed the update changelog, my bad! Good point, I'll have a play with plugins, I just think it's best the drives spin down, so I'll see if I can track down what is causing it.
-
I have two drives precleared that appear in unassigned devices to be incrementing reads every few seconds, i've never noticed this before, and just wondered what might be causing it, or if its a bug or if i should be even more worried 😂 Logs for scripts and the device dont shown anything, and the drives themselves are obviously unmounted and unformated, so i dont really understand what even could be read.... alexserver-diagnostics-20201231-1550.zip

-
The heatmap looks pretty incredible i'll grant you that. I have a few wobbly seagate SAS drives, which I will be moving out of service, but would probably be sufficient to test on if you want some feedback. Albeit i'm waiting on some new breakout cables first. Had quite the ride moving hardware the last week....
-
I was looking for a way to export, so I can use the data gained and the positions of the drives in my array to try and debug issues. It doesnt look like anything like that has been implemented yet? I'm running the latest, and I'll probably just old school copy and paste and screen shot, but it would be nice to have an export function!
-
It's ok i've got it, 1 file in each of the problem series had been corrupted from a data rebuild and a lot of moving above recently, and it turns out the file/folder parser doesnt fail gracefully in these circumstances. ssh in and rm the problem files, and we are back running fine!
-
I think i'm having permission issues, and i'm not sure what else to do or check. I've run Docker safe new permissions from the fix common problems plugin. I'm running latest container on offer, sonarr v2.0.0.5344 The two series i've noticed are: Sons of Anarchy & Dexter They both exist at \tv\show name\series\episode etc… on the disk but if i update series and scan disk on the series on sonarr, nothing is found, even though if i edit the series I can see its set as “/media/Sons of Anarchy/” /media is mapped to /tv All other series from what I can see work absolutely fine. I enabled debugging and ran the scan and this is the log: log: https://hastebin.com/ucosetapah.xml I think this: SameFileSpecification|No existing episode file, skipping suggests that it might be some sort of permissions issue and it cant read the files? Jellyfin in your docker image shows these two series just fine after a scan, so i think its something to do with sonarr and this docker container? I've posted direct on the sonarr board too, see if they can help, but I cant pinpoint if its sonarr or a docker permission problem.
-
I'm probably just going to just bite the bullet and go for this I think its missrepresented somehow, even though thats a "backups" folder there isnt actually anything really used in there just yet that I would miss I don't think. Its appdata backup and some other things like that. isos i could lose, seems ok to gamble.
-
😅oops, thanks, so i can delete those then from the setup, they are marked as required thats all, maybe the template needs updating?


