




bastl
Members
-
Joined
-
Last visited
-
Does this mean it is not possible anymore to connect to the server locally via lan ip and self signed cert and I am forced to install the Unraid Connect Plugin? If so, why?
-
Kann gut möglich sein, dass der CPU Takt in der VM einfach falsch angezeigt wird, vom Host quasi nicht an die VM korrekt weiter gegeben wird. Kann mich erinnern, dass ich das bei nem alten Threadripper System in ner VM auch schon gesehen hab, dass nur 800MHz angezeigt wurden, trotz dass auf dem Host auch der Boost aktiv war und funktionierte. Am besten einfach folgendes auf Unraid mal parallel zur aktiven VM laufen lassen watch grep \"cpu MHz\" /proc/cpuinfo Und noch paar Sachen am Rande: core0 nutzt Unraid grundsätzlich immer für sich um Tasks im Hintergrund zu bedienen. Ist nicht wirklich empfohlen den Kern gleichzeitig auch für eine VM zu verwenden. Angenommen deine VM veranstaltet im Hintergrund irgendwelche Updates, lastet die CPU stark aus, dann kann gleich direkt dein ganzer Server betroffen sein und Unraid wird extrem lahm bis hin zu freezes. 4 Kerne können Windows heutzutage in einer VM auch schon ganz schnell an die Grenze bringen. Großartig Performance ist da nicht zu erwarten. Wird sich definitiv langsamer anfühlen als wenn du Win10 direkt auf der Kiste laufen hast. Was auch noch ne extreme Bremse ist, wenn deine vdisk der VM nicht auf ner SSD/NVME liegt, sondern auf ner alten HDD vielleicht oder noch dazu auf ner Array Platte was nochmal stark bremst.
-
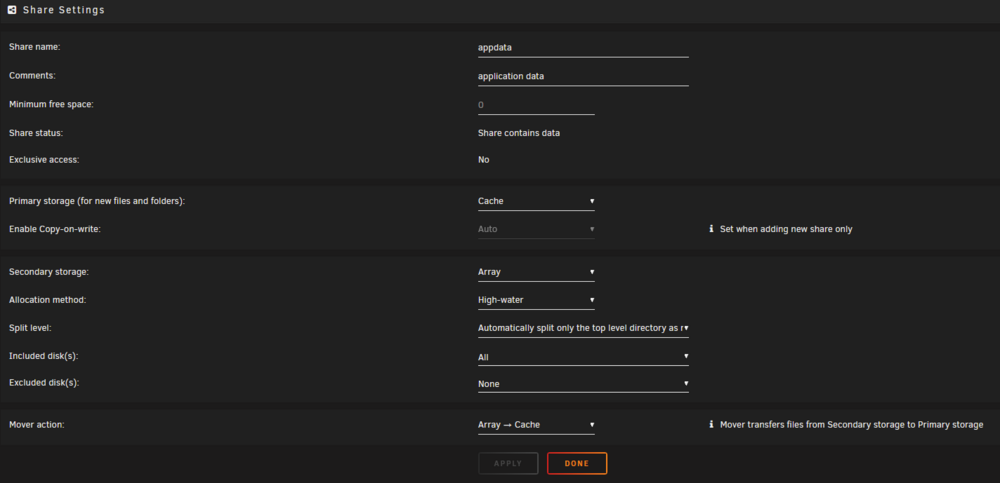
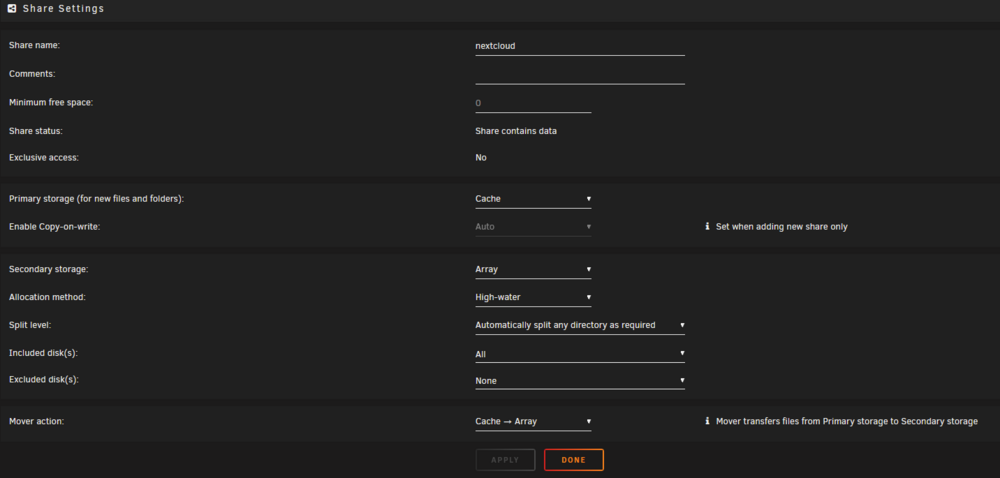
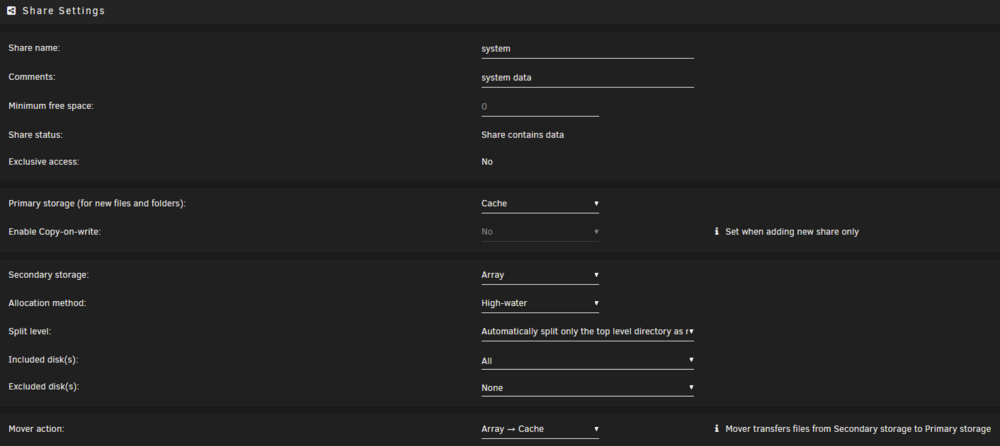
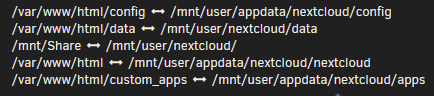
In one of the latest Unraid versions it changed slightly how shares are configured. Currently if you wanna use a cache drive combined with the array and move the data with mover to the array you have to define 2 options. In my case I have set the appdata share to be on the cache pool: I have set the primary storage as Cache and the secondary as Array and the Mover action "Array -> Cache" so if Mover starts it always will move files to the Cache pool. With this setup I see the same info as you because the files are not protected by the redundancy of the array if the cache pool only consists of 1 drive. If you have a mirrored pool with 2 or more drives the warning will go away. The reason why I have set it up this way is to be able to spin down the array disks. As an example if you use Nextcloud or Jellyfin/Plex you will always see some activity which will prevent the array disks to spin down. In my example if you switch the Mover action at the bottom of the share settings to "Cache -> Array" the unprotected files message will go away. In case of the drive failure for the single drive cache pool I have setup to backup the whole appdata folder each night. There are different ways to do this. "appdata backup" for example is a useful plugin for this. Most people have set it up this way that the appdata share housing all the docker configs and databases, sits on a fast ssd pool, single or multi drive, depends on the setup. In my case I use 20+ dockers and the size of the appdata share is 18GB. So it's not a big waste of space. As I said, depends on your usecase, you don't have to. Nextcloud for example if only using the array will prevent disks in the array to spin down if you use it on your phone, upload pictures, sync calendar and contacts. So it's better to combine it with the cache option. In my setup all my data I upload to Nextcloud will be stored on the cache pool first and moved to the array at night. The setup for the Nextcloud share hosting all the user data looks like this: primary storage: Cache secondary: Array Mover: Cache -> Array Usually best practice is to have data you access on a daily basis on a fast cache pool. If it's a single ssd you need to backup the data to prevent data loss. If you have a mirrored cache pool with more than 2 drives you have an extra layer of redundancy, but keep in mind raid is no backup. Depending on your network speed in most cases putting data on the cache first and let the mover transfering it to the array at night is the way to go. In case you have large amounts of data coming in exceeding the size of the cache, put it directly on the array as primary storage without a second storage or the mover take action. Not sure why you did that. In general the defaults are fine. docker.img in system share configs for the dockers in appdata share Short hint how docker and all the paths work in case you don't got it already. In most cases you basically have 3 paths where data is sitting. The application itself lets say Nextcloud is inside the docker.img file in the system share. In case you loss it, it's not big of a deal. You can easily recreate that file and reinstall all your dockers. The configurations for the dockers living in the appdata share. You should backup the appdata share regularly to don't loss any configurations in case of a drive failure. For both of these shares in most cases there is no need to change the defaults. The third path most of the containers use are where the userdata is in. Media files in Plex or uploads from your phone to Nextcloud for example. These paths are also shares in Unraid and can be configured as you like. Only on cache pools, on Array only or on Cache first and moved to the Array later. Depending on the amount of data coming in or used by these shares and depending on how large your pools are, you have to configure these shares. example for my Nextcloud path mappings: As you can see all the configurations from Nextcloud are mapped to the /mnt/user/appdata/nextcloud path and the user data are in the /mnt/user/nextcloud share. Don't blindly try to replicate these bindings. They differ depending on which Nextcloud docker you're using. Just as an example. go settings >> docker and disable the docker service make sure your deafult paths matching the defaults you see in the picture above in case you have manually moved your docker.img somewhere else, move it back to /mnt/user/system/docker/ check your system and appdata share settings, for appdata see my first picture, the system share should look like the following go to the main page of unraid and start the mover by pressing "move" and wait till it's finished. As long as it's moving filles, the button will be grayed out. optional: go to the shares page and click on compute for the system and the appdata share to check where data is siiting on. After mover is done go back to the docker settings and enable the service again



-
Servus. Hier wird dein Problem liegen. Beim Boot der VM wird normalerweise die Karte initialisiert allerdings nur, wenn ein Monitor angeschlossen ist. Meine 1050ti funktioniert auch nur in einer Win VM, wenn ein Monitor dran klemmt. Es gibt auch HDMI Dongles, die der Karte einen Monitor vorgaukeln, wäre eine Option, wenn du keinen Monitor anklemmen willst. Das ist eins der Symptome wenn kein Display dran hängt. Die Karte wird nur als Basic Display Adapter erkannt versehen mit einer Warnung und Treiber lassen sich auch nicht installieren.
-
Ich bin ja nicht der Käufer, und selbst hab ich bisher immer einen Bogen um solche Angebote gemacht. Ausnahmen würde ich ja noch machen, wenn ich direkt beim Angebot sehe die Platte kommt aus nem Rechenzentrum und hat x Betriebsstunden, x TBW etc. Wenn die SMART Werte wie angegeben zurückgesetzt wurden und ich quasi 0 Möglichkeiten hab deren Gebrauch nachzuvollziehen sind es mir die paar Euro Ersparnis auch nicht wert. Kannst du in deinem Fall nachvollziehen bei welchen Modellen die hohen Werte vorhanden sind? Scheint ja so zu sein, dass es bei deinen 18TB Modellen auch nicht einheitlich ist. Kommt das nur ab einem gewissen Modelljahr vor, oder bei einer besonderen Firmware Version?
-
Ok. Das ist mir auch gerade neu. Die letzten Seagate Platten die ich hatte, zeigten das noch nicht so, allerdings auch schon paar Jahre her. 2-3TB Modelle waren das. Ich habe dennoch Bauchschmerzen bei "recertified" Platten. In einem Kommentar steht folgendes: Stell dir vor du kaufst nen gebrauchten PKW, bei dem einfach mal alle alten Unterlagen gelöscht und der Kilometerstand auf 0 gesetzt wurde für 20-30€ günstiger als Neuware.
-
Wenn mal bei "Raw_Read_Error_Rate" 3-4 oder so steht und nicht hoch geht, würde ich mir garkeine Sorgen machen, aber 37673480 bei gerademal 256h Laufzeit ist nicht ok. Je nachdem wie man die Platte testet, wird es vielleicht garnicht direkt auffallen. Formatieren und Daten drauf kopieren mag vielleicht noch funktionieren, beim Lesen der Daten wird man es dann aber sicherlich merken. "recertified" wird denke mal nen Rückläufer sein. Jetzt weißt du auch warum. Wird keinen Sinn machen nen extended Selftest laufen zu lassen, wenn die Platte intern in ihrem eigenen Log schon Lesefehler verzeichnet hat. Probier mal ohne die Platte ob der Server stabil läuft
-
Eine deiner Festplatten (ST18000NM000J-2TV103) hat in den Smart Werten sehr hohe Werte bei den Fehlerraten. Mit der Platte stimmt definitiv was nicht Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE 1 Raw_Read_Error_Rate POSR-- 076 064 044 - 37673480 3 Spin_Up_Time PO---- 090 090 000 - 0 4 Start_Stop_Count -O--CK 100 100 020 - 17 5 Reallocated_Sector_Ct PO--CK 100 100 010 - 0 7 Seek_Error_Rate POSR-- 079 060 045 - 80588272 9 Power_On_Hours -O--CK 100 100 000 - 256 10 Spin_Retry_Count PO--C- 100 100 097 - 0 12 Power_Cycle_Count -O--CK 100 100 020 - 16 18 Unknown_Attribute PO-R-- 100 100 050 - 0 187 Reported_Uncorrect -O--CK 100 100 000 - 0 188 Command_Timeout -O--CK 100 100 000 - 0 190 Airflow_Temperature_Cel -O---K 075 063 000 - 25 (Min/Max 14/28) 192 Power-Off_Retract_Count -O--CK 100 100 000 - 15 193 Load_Cycle_Count -O--CK 100 100 000 - 27 194 Temperature_Celsius -O---K 025 040 000 - 25 (0 14 0 0 0) 197 Current_Pending_Sector -O--C- 100 100 000 - 0 198 Offline_Uncorrectable ----C- 100 100 000 - 0 199 UDMA_CRC_Error_Count -OSRCK 200 200 000 - 0 200 Multi_Zone_Error_Rate PO---K 100 100 001 - 0 240 Head_Flying_Hours ------ 100 100 000 - 255 (232 238 0) 241 Total_LBAs_Written ------ 100 253 000 - 51453398249 242 Total_LBAs_Read ------ 100 253 000 - 219259610467
-
@KluthR First of all, thanks for the plugin. I'am using it for quite some time now and never had any issues with it. Yesterday I switched from the old 2.5 version to the new one during the latest Unraid update and tested a bit. So far so good, compression works fine, copy flash backup to different location and also the grouping feature and the autoupdate dockers are working. Now to my issue I have. I have a mariadb and nextcloud container grouped together, stop-backup-start works, but the available update for the mariadb container isn't applied when grouped together. Is this a known bug or not yet implemented for the grouping feature? The logs show no errors and no hints that the plugin tries to update the container like it did on the netdata container which is in no group. -- [21.02.2024 22:20:37][ℹ️][nextcloud] Method: Stop all container before continuing. [21.02.2024 22:20:37][ℹ️][nextcloud][Nextcloud] Stopping Nextcloud... done! (took 1 seconds) [21.02.2024 22:20:38][ℹ️][nextcloud][MariaDB-Official] Stopping MariaDB-Official... done! (took 2 seconds) [21.02.2024 22:20:40][ℹ️][Main] Starting backup for containers [21.02.2024 22:20:40][ℹ️][Nextcloud] Should NOT backup external volumes, sanitizing them... [21.02.2024 22:20:40][ℹ️][Nextcloud] Calculated volumes to back up: /mnt/user/appdata/nextcloud/apps, /mnt/user/appdata/nextcloud/config, /mnt/user/appdata/nextcloud/nextcloud [21.02.2024 22:20:40][ℹ️][Nextcloud] Backing up Nextcloud... [21.02.2024 22:21:37][ℹ️][Nextcloud] Backup created without issues [21.02.2024 22:21:37][ℹ️][Nextcloud] Verifying backup... [21.02.2024 22:22:20][ℹ️][MariaDB-Official] Should NOT backup external volumes, sanitizing them... [21.02.2024 22:22:20][ℹ️][MariaDB-Official] Calculated volumes to back up: /mnt/user/appdata/mariadb-official/data, /mnt/user/appdata/mariadb-official/config [21.02.2024 22:22:20][ℹ️][MariaDB-Official] Backing up MariaDB-Official... [21.02.2024 22:22:30][ℹ️][MariaDB-Official] Backup created without issues [21.02.2024 22:22:30][ℹ️][MariaDB-Official] Verifying backup... [21.02.2024 22:22:33][ℹ️][Main] Set containers to previous state [21.02.2024 22:22:33][ℹ️][MariaDB-Official] Starting MariaDB-Official... (try #1) done! [21.02.2024 22:22:35][ℹ️][Nextcloud] Starting Nextcloud... (try #1) done! [21.02.2024 22:22:38][ℹ️][netdata] Stopping netdata... done! (took 2 seconds) [21.02.2024 22:22:40][ℹ️][netdata] Should NOT backup external volumes, sanitizing them... [21.02.2024 22:22:40][ℹ️][netdata] Calculated volumes to back up: /mnt/user/appdata/netdata/lib, /mnt/user/appdata/netdata/cache, /mnt/user/appdata/netdata/config [21.02.2024 22:22:40][ℹ️][netdata] Backing up netdata... [21.02.2024 22:22:59][ℹ️][netdata] Backup created without issues [21.02.2024 22:22:59][ℹ️][netdata] Verifying backup... [21.02.2024 22:23:02][ℹ️][netdata] Installing planned update for netdata... [21.02.2024 22:23:28][ℹ️][netdata] Starting netdata... (try #1) done! --
-
@GatorMB Do you have a idle session to Unraids WebUI opened somewhere on your network? I have an issue the server freezing randomly if I have a websession opened from a Windows box with Firefox. Randomly every 1-2 days with root logged in to Unraid, the server will freeze without any errors catched in the logs. If I log off or shutdown the Windows pc the server won't crash.
-
If you're on 6.12.5 or 6.12.6 try to downgrade to Unraid 6.12.4. A couple of users reported similiar issues like yours with latest Unraid builds and PCI passthrough
-
unfortunately not for me. I already checked all the logs for nchan errors. Is there a chance to increase the log level from unraid to get more output?
-
@count-zero I have similiar issues, random crashes and nothing in the logs. For me all started with the 6.12.x builds. What I noticed during the last weeks as long as I'am not logged in Unraids webui it doesn't crash. I now close any VNC VM windows and logout from the webui if I don't need to use it. Firefox on a Windows machine I use tu administrate the server. @JorgeB did you heared about that "phenomenon"? I have tested basically everything. Disks are ok, no errors. Memtest no errors. Switched to different power outlets, configured all sorts of stuff in the BIOS, with or without virtualisation, different power saving modes, disabled all sorts of devices like wifi or BT cards. Also disabling Docker or VMs or even running Unraid in Save Mode for a couple days didn't help. It always crashes between 4hours uptime up to 3-4 days with nothing logged. Now the interesting part. During all that crashes I had a Firefox window on another Windows box with different Unraid pages opened. Sometimes the Docker page, next time the Dashboard or the Main tab. As soon as I log out and close the Firefox Tabs surprise surprise crashes are gone. I saw a lot of threads opened with random freezes and crashes with the 6.12.x Unraid builds. Most people had issues with MacVLAN, switching to IPVLAN didn't help for me. Maybe this is something you can tell the people to test to pin down the problem.
-
Hello everyone, coming from 6.12.2 with an stable server, the 6.12.4 update I did a week ago broke something. Once a day I find the server frozen, mostly in the morning. No WebUI, no SMB access, SSH or ping. No response. I have to force reboot the system. Main use for the server is for light media consumption with Jellyfin, Nextcloud sync from phone (CalDav, CardDav), Unifi etc. and from time to time some media conversation with Tdarr or Handbrake dockers, rarly some remote access with WG. Most dockers are running on idle also a VM or two doing nothing. Most time of the day the server is idle. No config changes on my side with the last update. No custom scripts running during this time. On 6.12.2 the server never had any issues or crashes. It started the night after the update. I activated the syslog server and catched the latest crash. Sep 29 19:13:48 mini root: /mnt/cache: 284 GiB (304924037120 bytes) trimmed on /dev/nvme0n1p1 Sep 30 02:44:09 mini kernel: general protection fault, maybe for address 0xffffc900033abe6c: 0000 [#1] PREEMPT SMP NOPTI Sep 30 02:44:09 mini kernel: CPU: 6 PID: 31855 Comm: ps Tainted: P O 6.1.49-Unraid #1 Sep 30 02:44:09 mini kernel: Hardware name: BESSTAR TECH LIMITED HM90/HM90, BIOS 5.16 10/13/2021 Sep 30 02:44:09 mini kernel: RIP: 0010:mntput_no_expire+0x59/0x1f2 Sep 30 02:44:09 mini kernel: Code: 2e e7 ff 48 8b 83 e8 00 00 00 48 85 c0 74 16 48 8b 7b 50 83 ce ff e8 2f ef ff ff e8 cc 7a e7 ff e9 78 01 00 00 e8 91 ed ff ff <f0> 83 44 24 fc 00 48 8b 7b 50 83 ce ff e8 0e ef ff ff 48 89 df e8 Sep 30 02:44:09 mini kernel: RSP: 0018:ffffc900033abe70 EFLAGS: 00010286 Sep 30 02:44:09 mini kernel: RAX: 0000000000000000 RBX: ffff888134bf0838 RCX: 0000000000000064 Sep 30 02:44:09 mini kernel: RDX: 0000000000000001 RSI: 00000000ffffffff RDI: ffff888134bf09c8 Sep 30 02:44:09 mini kernel: RBP: ffff888106220b00 R08: 0000000000000000 R09: ffff888134bf0858 Sep 30 02:44:09 mini kernel: R10: 0000000000000000 R11: 0000000000000000 R12: 00000000000a801d Sep 30 02:44:09 mini kernel: R13: ffff888134bf0858 R14: ffff88818ab54e40 R15: 0000000000000000 Sep 30 02:44:09 mini kernel: FS: 0000147c21ef77c0(0000) GS:ffff888712d80000(0000) knlGS:0000000000000000 Sep 30 02:44:09 mini kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Sep 30 02:44:09 mini kernel: CR2: 00000cdb8942f000 CR3: 000000033b1e2000 CR4: 0000000000350ee0 Sep 30 02:44:09 mini kernel: Call Trace: Sep 30 02:44:09 mini kernel: <TASK> Sep 30 02:44:09 mini kernel: ? __die_body+0x1a/0x5c Sep 30 02:44:09 mini kernel: ? die_addr+0x38/0x51 Sep 30 02:44:09 mini kernel: ? exc_general_protection+0x30f/0x345 Sep 30 02:44:09 mini kernel: ? asm_exc_general_protection+0x22/0x30 Sep 30 02:44:09 mini kernel: ? mntput_no_expire+0x59/0x1f2 Sep 30 02:44:09 mini kernel: ? mntput_no_expire+0x6b/0x1f2 Sep 30 02:44:09 mini kernel: ? dput+0x39/0x17b Sep 30 02:44:09 mini kernel: ? __fput+0x19f/0x1d2 Sep 30 02:44:09 mini kernel: ? task_work_run+0x6b/0x80 Sep 30 02:44:09 mini kernel: ? exit_to_user_mode_prepare+0x75/0x10d Sep 30 02:44:09 mini kernel: ? syscall_exit_to_user_mode+0x18/0x2c Sep 30 02:44:09 mini kernel: ? do_syscall_64+0x77/0x81 Sep 30 02:44:09 mini kernel: ? entry_SYSCALL_64_after_hwframe+0x64/0xce Sep 30 02:44:09 mini kernel: </TASK> Sep 30 02:44:09 mini kernel: Modules linked in: rpcsec_gss_krb5 nfsv4 dns_resolver nfs xt_CHECKSUM ipt_REJECT nf_reject_ipv4 ip6table_mangle ip6table_nat iptable_mangle vhost_net tun vhost vhost_iotlb tap xt_nat xt_tcpudp veth macvlan xt_conntrack nf_conntrack_netlink nfnetlink xfrm_user xfrm_algo xt_addrtype br_netfilter dm_crypt dm_mod xfs nfsd auth_rpcgss oid_registry lockd grace sunrpc md_mod zfs(PO) zunicode(PO) zzstd(O) zlua(O) zavl(PO) icp(PO) zcommon(PO) znvpair(PO) spl(O) it87 tcp_diag inet_diag hwmon_vid vendor_reset(O) iptable_nat xt_MASQUERADE nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 wireguard curve25519_x86_64 libcurve25519_generic libchacha20poly1305 chacha_x86_64 poly1305_x86_64 ip6_udp_tunnel udp_tunnel libchacha ip6table_filter ip6_tables iptable_filter ip_tables x_tables efivarfs bridge stp llc igc r8169 realtek amdgpu edac_mce_amd edac_core intel_rapl_msr intel_rapl_common iosf_mbi gpu_sched drm_buddy kvm_amd i2c_algo_bit drm_ttm_helper ttm drm_display_helper kvm Sep 30 02:44:09 mini kernel: drm_kms_helper drm crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel sha512_ssse3 btusb btrtl aesni_intel btbcm btintel crypto_simd cryptd bluetooth agpgart i2c_piix4 syscopyarea rapl ahci ecdh_generic nvme sysfillrect i2c_core k10temp libahci amd_sfh ecc sysimgblt ccp fb_sys_fops nvme_core tpm_crb tpm_tis video tpm_tis_core wmi tpm backlight acpi_cpufreq button unix [last unloaded: igc] Sep 30 02:44:09 mini kernel: ---[ end trace 0000000000000000 ]--- Sep 30 02:44:09 mini kernel: RIP: 0010:mntput_no_expire+0x59/0x1f2 Sep 30 02:44:09 mini kernel: Code: 2e e7 ff 48 8b 83 e8 00 00 00 48 85 c0 74 16 48 8b 7b 50 83 ce ff e8 2f ef ff ff e8 cc 7a e7 ff e9 78 01 00 00 e8 91 ed ff ff <f0> 83 44 24 fc 00 48 8b 7b 50 83 ce ff e8 0e ef ff ff 48 89 df e8 Sep 30 02:44:09 mini kernel: RSP: 0018:ffffc900033abe70 EFLAGS: 00010286 Sep 30 02:44:09 mini kernel: RAX: 0000000000000000 RBX: ffff888134bf0838 RCX: 0000000000000064 Sep 30 02:44:09 mini kernel: RDX: 0000000000000001 RSI: 00000000ffffffff RDI: ffff888134bf09c8 Sep 30 02:44:09 mini kernel: RBP: ffff888106220b00 R08: 0000000000000000 R09: ffff888134bf0858 Sep 30 02:44:09 mini kernel: R10: 0000000000000000 R11: 0000000000000000 R12: 00000000000a801d Sep 30 02:44:09 mini kernel: R13: ffff888134bf0858 R14: ffff88818ab54e40 R15: 0000000000000000 Sep 30 02:44:09 mini kernel: FS: 0000147c21ef77c0(0000) GS:ffff888712d80000(0000) knlGS:0000000000000000 Sep 30 02:44:09 mini kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Sep 30 02:44:09 mini kernel: CR2: 00000cdb8942f000 CR3: 000000033b1e2000 CR4: 0000000000350ee0 Sep 30 02:44:09 mini kernel: note: ps[31855] exited with preempt_count 2 mini-diagnostics-20230930-1231.zip No idea how to fix this issue. Any help is appreciated. syslog-10.0.0.4.log
-
Danke für den Link zu meinem eigenen Thread mit nem ähnlichen Thema 😂 Bin ich irgendwie nicht darauf gekommen, dass dort jemand etwas Ähnliches gefragt haben könnte und habs auch scheinbar verpasst. docker network create -o parent=virbr9 --driver macvlan --subnet 10.30.10.0/24 --gateway 10.30.10.1 labnet Hiermit hab ich mir ein "labnet" erstellt, und erfolgreich getestet. Die Docker sind nun in dem Privaten Netz mit ner Test-VM. Mit "Preserve user defined networks" in den Docker Settings bleibt das Netz auch nach nem Reboot erhalten und ich hab beim Erstellen eines Dockers die Option für das Netz zur Auswahl und brauche nur eine feste IP vergeben. Genau wie ich das wollte. Gefummel war das garnicht und ne Pfsense VM hatte ich ja bereits für Tests und zum bisl üben was Routing und die ganze Funktionalität angeht. Auch ganz praktisch, wenn man Backups von seiner physikalisch existenten Pfsense Kiste hin und wieder testen will. Danke nochmal 👍










