




jj_uk
Members
-
Joined
-
Last visited
-
I'm trying to figure out if my GPU or CPU is being used to do video encoding. When I start process, I see this in intel_gpu_top. My ARC A380 card is card1. The Video is 0.00%, but below that, the process is showing video to be about 75%. Confused... The command is run in the console of tdarr container. ffmpeg -hwaccel qsv -hwaccel_output_format qsv -qsv_device /dev/dri/card1 -i "/temp/test/test_in.mkv" -c:v av1_qsv -global_quality 30 -preset 4 -c:a copy -c:s copy -y "/temp/test/test_out.mkv" Is this CPU or GPU encoding?
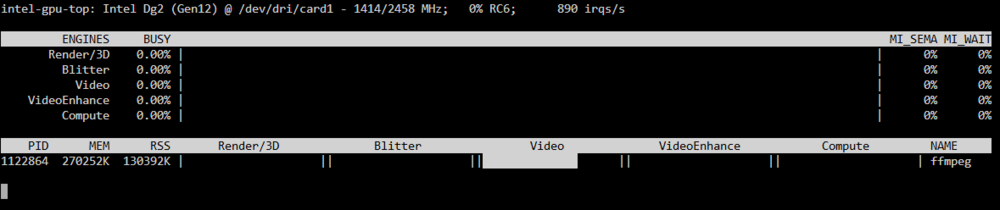
-
Is there a list of valid repositories that can be used for the updating of the container? I'm on lscr.io/linuxserver/nextcloud:28.0.3, tried lscr.io/linuxserver/nextcloud:28.0.9 but it said invalid.
-
Following an update from 6.12.13 to 6.12.14, I'm getting buffering when streaming music from Plex Media Server (as a docker), to a windows 10 PC in Chrome browser. I'm assuming this might be the issue mentioned in the release notes regarding a driver that needs to be uninstalled? As the release notes didn't give any specific instructions on what to uninstall and how to do it, I simply ignored the release notes - sorry. Can someone please take a look at my diagnostic logs from 6.12.14 (attached) and please give me a hint on what I need to do to fix this. I use music streaming a lot, and would also like to keep unraid up to date. I've rolled back to 6.12.13, and everything is working fine again. tower1-diagnostics-20241206-1806.zip
-
When running a docker scrub, the progress is never updated. Refreshing the page updates the progress. ( cache scrub updates progress every 1 second )
-
Doesn't seem to be doing anything? Should it rebuild on it's own? There's no button to press to force it as far as I can see?

-
I just pulled the 1st cache disk and replaced it as per the instructions. How do I know when the rebuid has finished? There's no indication anywhere that I can see that says the cache disks are rebuilding?
-
OK, yes, it's RAID1, so I should be good.
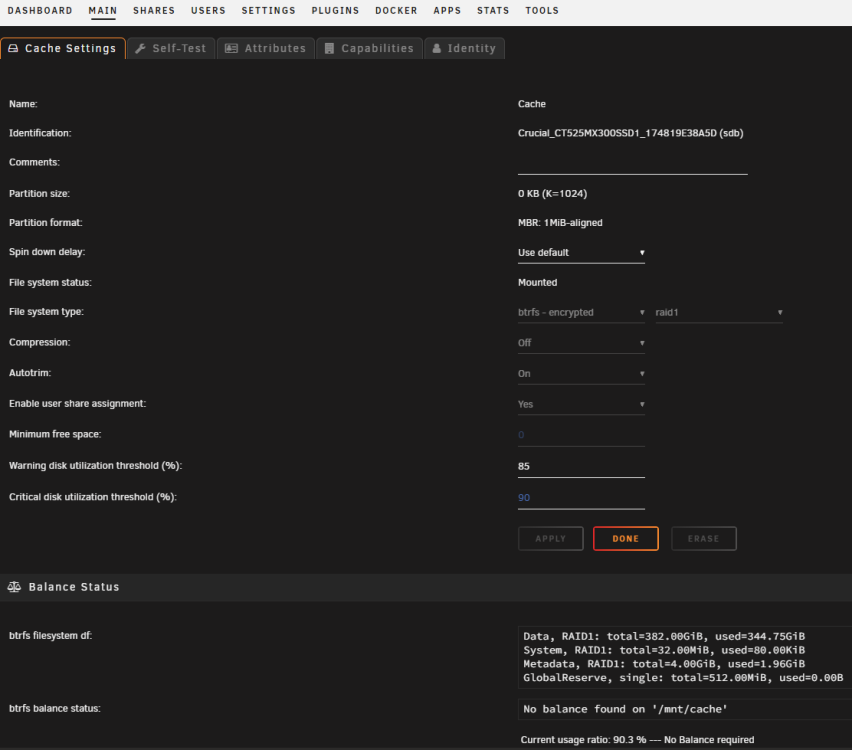
-
Thanks for the reply. I found this https://docs.unraid.net/unraid-os/manual/storage-management/#replace-a-disk-in-a-pool. What does "redundant" mean? It's the cache pool, so it's definitely in use!
-
What's the process for replacing both cache drives in a btrfs pool? Unplug a drive, plug in the new one, wait for rebuild, then repeat for the other disk? I'm replacing both disks with 1T drives.

-
Is the config file needed?
-
Actually, it doesn't work.. backup.log and config.json are missing from the copied files. Any idea why? Are these files locked when the port-run script is executed?
-
Thanks for the reply. I came up with this, seems to work. #!/bin/sh # Destination folder that will be cleared and will receive the copied data: dest="/mnt/user/backup/CommunityApplicationsAppdataBackup/appdata-latest" # The expected path of the source data (for sanity checking) src_must_contain="/mnt/user/backup/CommunityApplicationsAppdataBackup/appdata/ab_" # Sent arguments: post-run, destination path, true|false (true on backup success, false otherwise) today=$(date +'%Y-%m-%d_%H%M%S') logfile="/mnt/user/backup/CommunityApplicationsAppdataBackup/appdata/port-run-$today.log" { # required for logging, see EOF for closing brace. src="$2" backup_status="$3" echo "log: $logfile" echo echo "params:" echo "param 1 = $1" echo "param 2 = $2" echo "param 3 = $3" echo if [ $1 != "post-run" ]; then echo "ERROR: param 1 not \"post-run\", exiting." exit 0 fi # check param indicates the backup was successful: if [ $backup_status != "true" ]; then echo "ERROR: backup_status is not true, exiting." exit 0 fi # check source path contains the expected path: if [[ $src != *"$src_must_contain"* ]]; then echo "ERROR: src path appears to be at an unexpected location, exiting." exit 0 fi # check source is a directory: if [ -d $src ]; then echo "source: $src" else echo "ERROR: src is not a directory, exiting." exit 0 fi # check destination is a directory: if [ -d $dest ]; then echo "dest: $dest" else echo "ERROR: dest is not a directory, exiting." exit 0 fi # empty destination directory: rm -rf $dest/* echo "Copying src to dest..." # copy source to destination cp -r $src/ $dest/ echo echo echo "finished, exiting." exit 0 } 2>&1 | tee -a $logfile
-
I'd like to create a script to run after the backup has successfully completed. The script needs to run only if the backup was successful, then: Empty the `/mnt/user/CommunityApplicationsAppdataBackup/appdata-latest/` folder. Copy the folder that was just created by the backup tool to the above path. I've not written any scripts before. Does anyone have any example scripts?
-
I recently changed the fixed IP address that unraid is using to allow me to move it outside of the DCHP range. I've changed the proxy settings in radarr/sonarr to use the new unraid ip address:8118, and they can connect to the indexers again. But SAB can't connect to the downloader servers. Clicking the spanner in Sab, I see this: Local IPv4 address 10.27.4.254 Public IPv4 address Connection failed! IPv6 address None Nameserver / DNS Lookup OK Not sure what to do, I can't see a proxy setting in Sab to force the use of privoxy. Any idea?
-
Is it possible to exclude folders everywhere that have a certain name? I use the recycle bin plugin and I don't want to include .Recycle.Bin folders in my backups. I'd like to globally exclude .DS_Store, *.tmp, .Recycle.Bin



