jj_uk
Members
-
Joined
-
Last visited
Everything posted by jj_uk
-
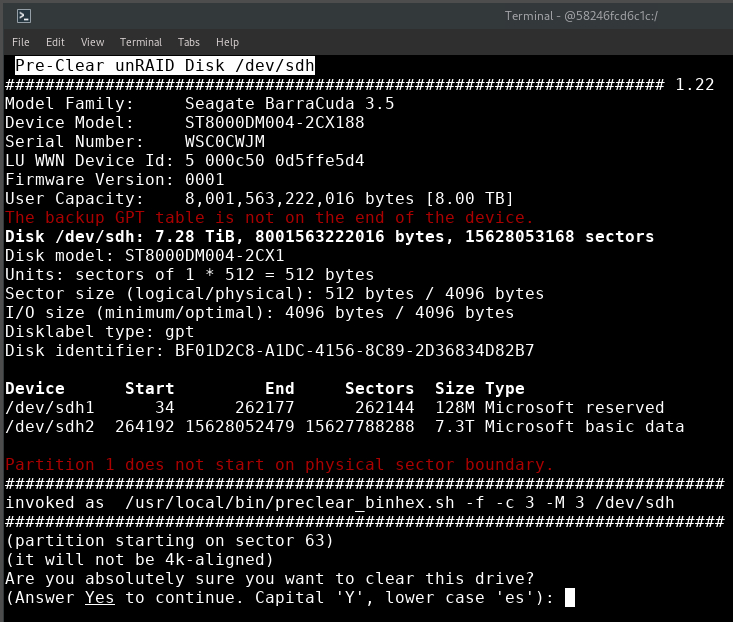
I pulled drive from a brand-new desktop-backup USB HDD and added it to my server (cheap way of getting drives). /usr/local/bin/preclear_binhex.sh -f -c 3 -M 3 /dev/sdh After executing the command as per instructions, i see there's 2 partitions, and the boot sector is in 63, not 64. I don't really know the significance of any of this, is it important? Is the disk OK to be precleared and used in unraid? I assume it's like this because its probably factory-formatted to windows for use with windows?
-
My cache drives are using btrfs, so i'm ok to just disable it?
-
Yes, I have the trim setting set to hourly. Is manually trimming on a schedule really required? Can the OS just trim when it deletes something instead?
-
12:00: 12:12: (seems back to normal) :
-
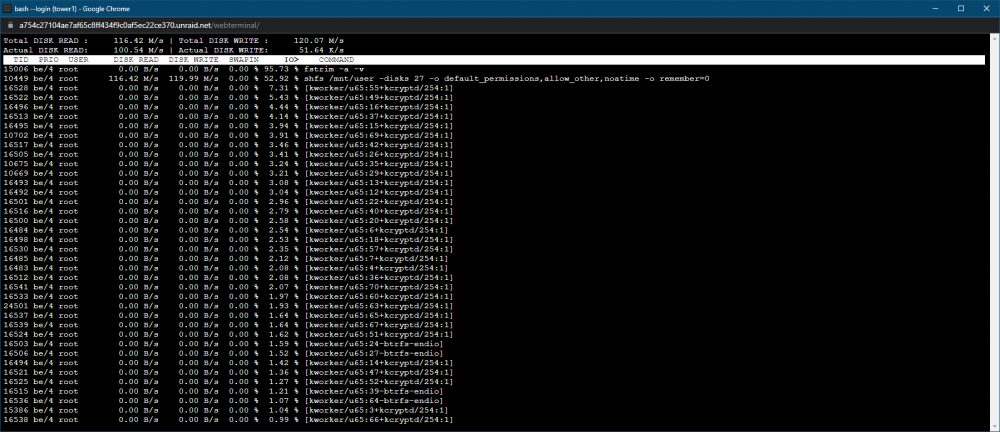
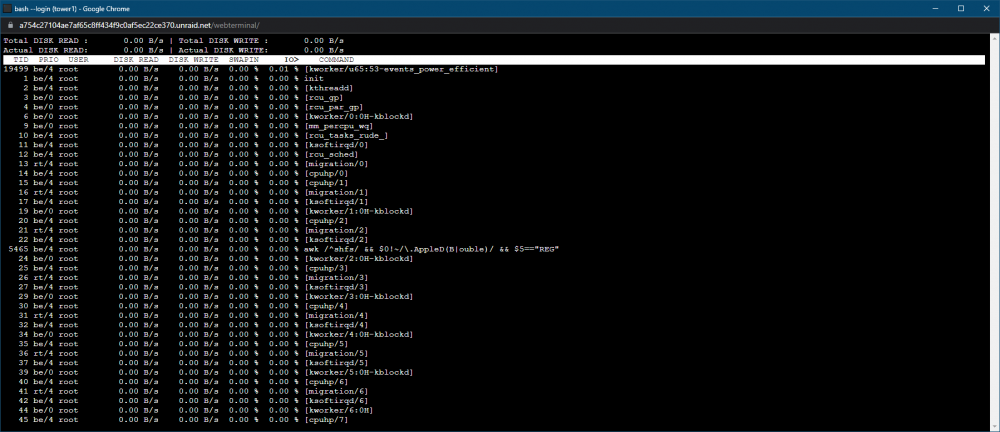
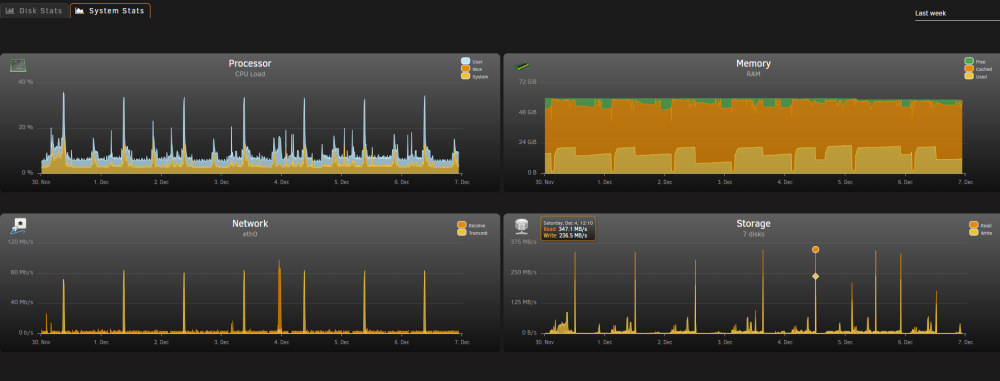
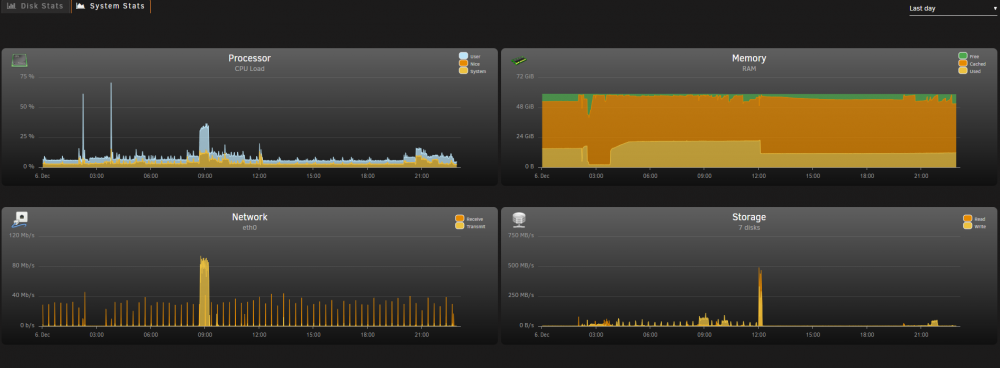
How can I find out what's causing the massive disk IO that occurs each day at 12-noon ? It's causing some containers to fall over. 3:30am is my CA backup, 8am my Duplicati backup begins, transferring to a different server, and it finishes at around 10:30am so I expect to see high disk and network usage peek a this time, but I have no idea what the 12-noon disk usage is? ssdtrim runs every hour, other than that, I have no idea.
-
OK, I've found the stats page. It seems that something is doing a huge amount of disk IO at noon each day. I'll post in the general support forum.
-
I need some help. Every day, between 12-noon and 12:05, all three of my MC servers crash. They fail with similar errors that seem to indicate that the server can't keep up. SERVER 1 SERVER 2: SERVER 3: I've looked in the unraid logs, and the only thing there is a ssdtrim on the cache, that happens every hour. I've looked at all my containers; I can't tell if one of them is doing anything that will swamp the server at that time. I'm not sure how to proceed in debugging this? Is there a way to get a global CPU usage graph in unraid?
-
I asked why they decided to do that on their discord a while ago. Their reply was- to stop people blindly updating and breaking their server, then flooding the support forums.
-
Are you asking how can a 1.17.1 server be upgraded to a 18.1 server? I'd also be interested in this.
-
My server crashed again. Had to do a hard reset to get it back again. Any idea what caused this? The log is attached, The problems started at about 09:35 today (Nov 28). The logs are spammed with amdgpu which I can't fix, but it also looks like there was some other error that took the server down. syslog.zip
-
I think i've got it running now on v17. I can't test the external xbox -> crafty connections. I guess i'll find out tomorrow when the kids try to log on! Removing the version of java I was using was not cool 🤣 haha... Thanks for all your hard work
-
I had to restart the container after changing the MC server java paths in crafty. My 1.16.5 is now running on java 8, and my fabric 1.17.1 server is running on java 17. but my PaperMC server won't start on java 17, although their discord says it should, so i need to update PaperMC or one of the plugins etc that its using. In the mean-time, is there an easy way for me to get java 16 again so I can at least get it running for now?
-
My 1.17.1 and 1.16.5 were all using /usr/lib/jvm/java-16-openjdk/bin/java but now none of them will start (logs show that doesn't exist anymore). I've changed the path to /usr/lib/jvm/java-17-openjdk/bin/java, but i'm getting java not found errors. What's the path for the new java 17? crafty.log shows: 2021-11-22 20:59:27,503 - [Crafty] - CRITICAL - app.classes.minecraft_server - Minecraft server Java path does not exist...
-
Anyone have any ideas how to stop this? Resolved: Removed the card.
-
I have Stop, Start and Pre-start entries for a script. Which one is executed when the backup completes? Is it the Stop script?
-
Is it possible to run a script at the end of the backup, before the dockers restart, passing the name/path of the file just created to the script? I need to copy the created archive folder e.g. "/path/to/[email protected]/CA_backup.tar.gz" to a different location once it's been created (e.g. "/path/on/server/backup-latest/CA_backup.tar.gz"), so my script will empty the destination folder, then copy the most recent .gz there. The reason for this is because I keep 21 days of backups; these are then sent to a different server (backup 3-2-1 topology). I need to send only the latest backup to backblaze (offsite backup). Keeping 21 copies on backblaze is costing me too much money!
-
Did you eventually get this going?
-
How can I stop my graphics card from spamming the logs: Sep 14 18:19:36 tower1 kernel: [drm] PCIE GART of 256M enabled (table at 0x000000F400000000). Sep 14 18:19:36 tower1 kernel: [drm] UVD and UVD ENC initialized successfully. Sep 14 18:19:36 tower1 kernel: [drm] VCE initialized successfully. Sep 14 18:19:36 tower1 kernel: amdgpu 0000:02:00.0: [drm] Cannot find any crtc or sizes Sep 14 18:23:00 tower1 kernel: [drm] PCIE GART of 256M enabled (table at 0x000000F400000000). Sep 14 18:23:00 tower1 kernel: [drm] UVD and UVD ENC initialized successfully. Sep 14 18:23:00 tower1 kernel: [drm] VCE initialized successfully. Sep 14 18:23:00 tower1 kernel: amdgpu 0000:02:00.0: [drm] Cannot find any crtc or sizes Sep 14 18:23:06 tower1 kernel: [drm] PCIE GART of 256M enabled (table at 0x000000F400000000). Sep 14 18:23:06 tower1 kernel: [drm] UVD and UVD ENC initialized successfully. It's the graphics card that was installed in the server a long time ago, passed thru into a VM. tower1-diagnostics-20210914-1830.zip
-
Mover completed successfully after a reboot. Next I need to fix the AMD spam in the logs. I'll post a new topic for that.
-
I'm up and running again, but as soon as I clicked MOVE to start the mover, I got a segment fault again. What causes this? tower1-diagnostics-20210914-1311.zip
-
Thanks. That's worked and a docker container started ok. I forgot to select encrypted for the cache, so I'm repeating the process Quicker to redo the copy process from the backed-up cache than to let mover do it. Fingers crossed!
-
Attached. The array is currently stopped as i'm a bit worried about losing everything. tower1-diagnostics-20210914-0845.zip
-
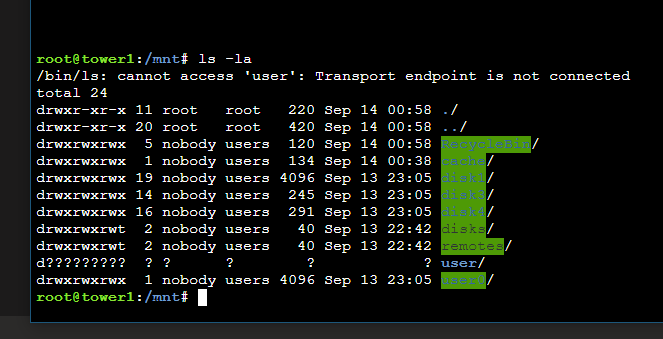
Managed to restore all the cache, deleted docker image, re-enabled docker. Installed the 1st container from the APPS -> previous Docker tag. The install failed with an error saying couldn't create /mnt/user/ and then all my shares disappeared! Any idea how to fix that? The 'user' share seems to be broken.
-
I've copied all the data off of the drives following the guide you posted above. I've stopped the array then run this command to erase the cache drives: blkdiscard -f /dev/sdb blkdiscard -f /dev/sdc I've stated the array, and fomatted the "unmountable" drives, which are the 2 cache drives. After the format completes, I get this error: "Unmountable: no pool uuid" I've removed both drives from the pool, and set slots to zero to delete the pool, then created a pool of 2 and re-added them, but the error persists. I can't mount the drives. EDIT: Solved the issue. I stopped the array, set all shares to 'Use Cache Pool? No', deleted the docker image in settings-docker, deleted the virtlib file by stopping VM and chosing delete from "Settings - VM Manager". Disabled the syslog server in settings, then deleted the syslog server files from the cache using MC. Then rebooted the server, added a cache pool, added the drives, stated the array, formatted the drives. I'm now copying the data back to the cache.

-
Thanks!!! I'll give this a try. Before I do, docker has created some files on the system share. Should I delete these before attempting the repair? The files will also be in the cache as system share is set to 'Prefer : Cache'