




jserio
Members
-
Joined
-
Last visited
-
This plugin has been working fine for my Testa P40 and Quadro but the latest update seems to be broken. I removed the plugin, rebooted and reinstalled the plugin but it force installs the v490 driver instead of the v480. This results in the Nvidia plugin page hanging (requiring a phpfpm restart). Is there a way to manually install the v480 drivers?
-
I doubt they (@Limetech) will ever fix this. They have yet to acknowledge it. I'm tempted to switch back to SMB1 just to get this to work again. It's quite frustrating that this has been going on for the last few years.
-
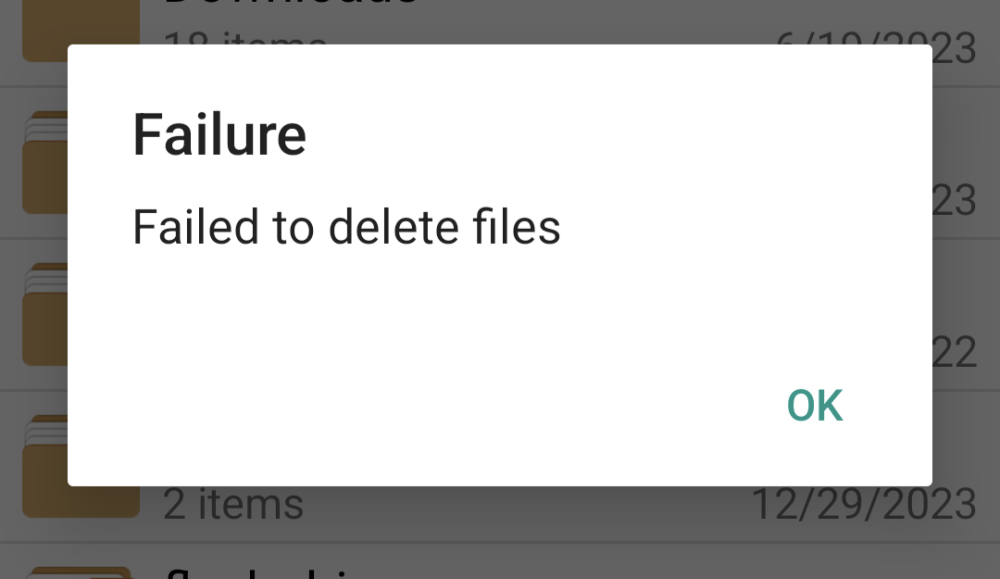
Other than pOpyraid, has anyone else got this working? Also, single file deletion and empty directories have always worked. It's deleting directories with multiple files/folders inside that result in the error.
-
I removed the Recycle Bin plug-in and duplicated your settings exactly and still get the error. Have you tried to delete a directory with files and folders inside? Deleting a single file is fine. It's the subdirectories that will give an error.
-
Unfortunately, it doesn't work for me either with the latest Solid Explorer and 7b2. Are you using the Recycle Bin plug-in? Also, would you mind sharing your SMB settings and custom parameters (if any)?
-
To answer my own question, it has nothing to do with folder caching or the recycle bin. However, if I comment out the min client directive in the Samba config (essentially enabling SMB1) and set the protocol to SMB1 in Solid Explorer, everything works. Seems to be an issue with SMB2/3 support in Unraid or the Samba version in the apps is incompatible.
-
I just tried File Manager + and received the same error. I wonder if this isn't related to Samba but perhaps the file caching or recycle bin plugins?
-
I hate to beat a dead horse, but has Lime Tech resolved this issue yet? I used to use Solid Explorer on Android all the time to manage files on my shares. Every since 6.11, I have also been experiencing failures when deleting directories with files. I've tried all of the file managers listed in this thread and none of them work. I'm sure I'm not the only one with the problem and it would be great if the devs prioritize this.
-
Hi guys. Is anyone able to get NVIDIA HW acceleration working with the Shinobi docker? I modified the template to include --nvidia=all and added the appropriate GPU ID and 'all' to the capabilities variables. However, Shinobi throws errors int he log: Unknown decoder 'h264_cuvid' Shelling into the container and running nvidia-smi shows the GPU status. However, ffmpeg does not show "--enable=nvidia" as a compiled in configuration. I searched apt for ffmpeg with nvidia but it doesn't exist and seems you need to compile it yourself. Is this correct or is there an easier way to make this work? BTW, Plex and Tdarr both work with my GPU so the issue is not Unraid or the passtrhough.
-
To answer my own question, it looks like it has something to do with "Use rich workplaces." Disabling this removes the icon.
-
I've been on v16 for some time and finally went through the multiple upgrade process to get to 18. Everything went well but my homepage shows what appears to be a spinning icon (as if it's scanning for something). The icon never goes away. Restarting the container doesn't help. This is on Firefox. Only add-on is UBlock Origin which is disabled for my Nextcloud host. Any ideas?

-
Hey guys. The latest Deemix docker seems to be broken. I noticed the port in the config still says 9666 but the documentation mentions 6595. Regardless of what I put in the configuration, I am unable to connect. Removing and adding the container doesn't seem to fix it.
-
Works great now. Thanks for the quick response.
-
Same here. AirVPN. Tried several new config files and get the "unable to resolve Google DNS error." Rolled back to 4.2.5-1-01 and all is good.
-
Hey guys. I'm having some trouble with file permissions after a transcode. Media directories are nobody:users 666 (rwrwrw). UID and PGID are 99 and 100 in the container settings for Tdarr. However, after a transcode, when Tdarr copies the new file to the original location, the file permissions are root:root 644. This causes problems when I need to write to those directories later. I have tried adding "-e UMASK_SET=0000" to the Extra Parameters section in the container and this has had no effect. I've also tried UMASK. I've also added these as variables in the container settins with no such lock. For kicks, I've tried other UMASK values and no change. Any ideas or suggestions?


