jcarre
Members
-
Joined
-
Last visited
Everything posted by jcarre
-
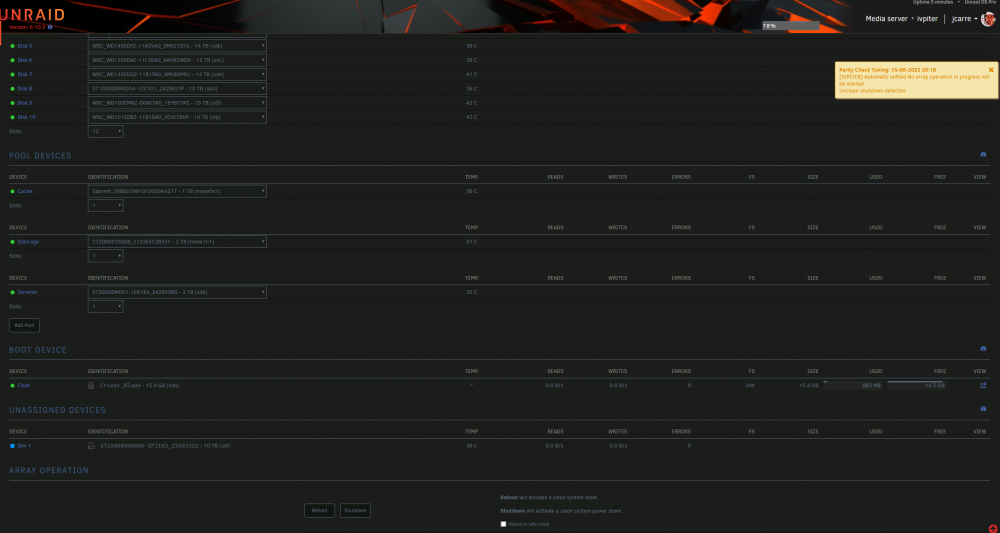
Hello, I posted a couple of days ago regarding my server acting up after nearly a year working flawlessly. I fixed that error with a new installation of postgres, but I am experiencing major issues with disk failure. I decided to fully restart the server, first time after the last update, and one parity drive gave write errors and was disabled (this was yesterday). I though nothing of it, and tried to fix the problem with my memory getting full. A couple of minutes ago I attempted to add the disabled parity drive back into the array, starting a new parity operation. Shortly after, disk7 shows write error and is also disabled. The parity operation was automatically stopped, and I am worried about losing data. I know that having two disks suddenly dying is not normal and that something else is probably going on. The last parity calculation was done on the 11th of January without issue. I set it to do it every 3 months. What is the best course of action? All my disks are connected with an HBA (LSI 9201-16i). I am worrying about it being the failure point. The server has been working fine for nearly a year, but it lacks an exhaust fan. Maybe the card is failing due to old thermal paste and bad airflow? The server is on a 4u case mounted on a rack with other computers nearby. The case has 3 Noctua industrial fans blowing air from the front, controlled with a plugin with the disk temperatures. This makes the server very quiet when not in use, but may get the card very hot most of the time?. I really don't know. Please see attached my syslog + diagnostics. Thank you very much. ivpiter-diagnostics-20240309-1959.zip ivpiter-syslog-20240309-1858.zip
-
This may be the culprit. It's a postgres database (tensorchord/pgvecto-rs:pg14-v0.2.0). I think it has a memory leak, since the last restart (yestarday) it accomulated 50gb+ of ram. It has 4 databases, but I'm currently only using if for nextcloud. I haven't changed anything and has been working fine for months. I'll keep an eye on it during the weekend. Thanks.
-
Hello, I've had this current installation working flawlessly for a year, but a few weeks back it started giving me weird issues. My docker services go down for a while and then up back again (not today). Sometimes the UI is unresponsive, but seems to be fixed after some time. Looking at the logs I see problems with memory, but I don't fully understand what's going on. Can someone guide to troubleshoot the issue? I attached both log + diagnostics before restarting the server. Thanks. ivpiter-diagnostics-20240307-1757.zip ivpiter-syslog-20240307-1656.zip
-
First of all thanks Squid for this awesome plugin! It really helped me with setting things up at the beginning of my Unraid journey! I was wondering if it was possible to outright omit some warnings Recently I uninstalled the auto update docker plugin, and use the new Appdata backup plugin instead. So now I'm updating every week, instead of every day. This makes Fix Common Problems alert me of new updates available. While I've been using the 'ignore this warning' option, managing 80+ docker applications is becoming a bit overwhelming. Is there an alternative to just keep ignoring this particular application ? Thanks in advance!
-
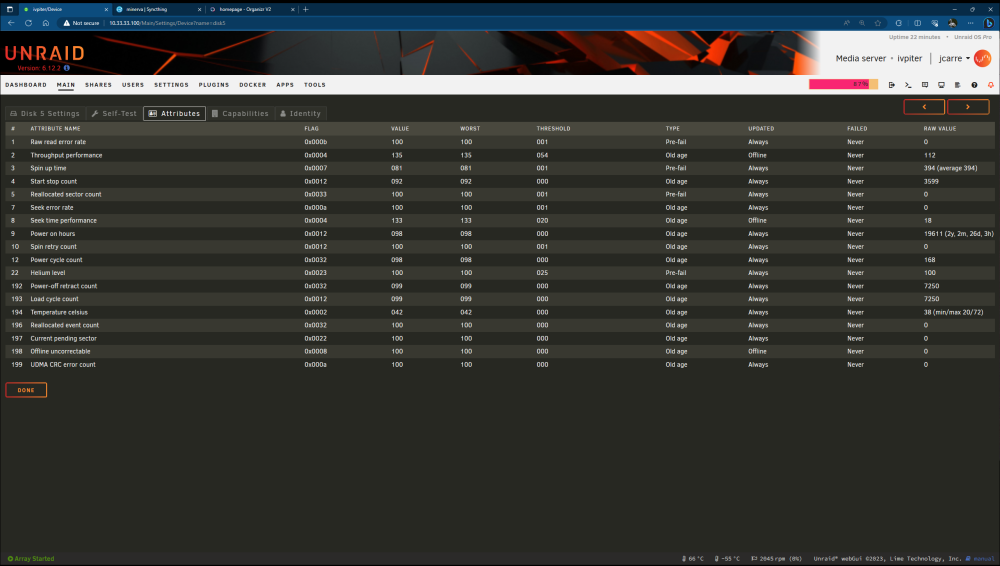
Hello everyone, This weekend the planned parity checked started and one of my disks became disabled with a bunch of errors after a few hours. I did a short smart test and the disk turned out to be fine. Thinking that it might have been an error with the HBA (it's really hot right now), I cranked the fans up and started the a rebuild process with the same disk. The rebuild turned out fine and everything appeared to be ok. So I started a check again, and the error showed once more within a few minutes. Is my disk dead? Is it just writing fine but unable to read? What shall I do? Thanks in advance. ivpiter-diagnostics-20230703-2101.zip ivpiter-syslog-20230703-1900.zip
-
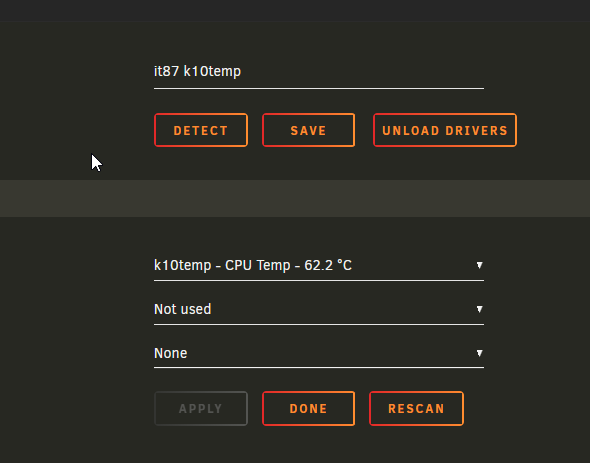
I'm having a problem with the new update regarding system temp/auto fan. The drivers load as usual but the array speed fan shows blank. I have an x570 Aorus Motherboad. None of the pwm fans are detected. EDIT: Fixed it by installing "ITE IT87 Driver" Plugin!!
-
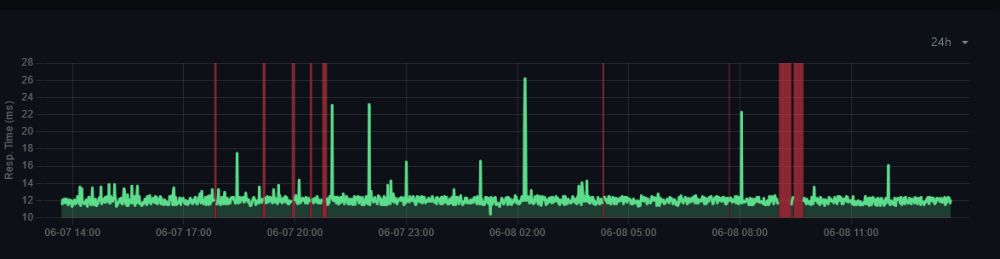
Hello, I've been encountering a frustrating issue with my Unraid setup, specifically with my Docker containers losing internet connectivity on and off. It's been going on for a while now, and I'm hoping to get some insights and suggestions from the community here. The problem manifests as intermittent periods where the Docker containers completely lose internet access for several minutes to an hour or two. Afterwards, they regain connectivity as if nothing happened. It's quite puzzling, and I've attached the logs and files. Here are a couple of graphs depicting the pings using uptime kuma: one during a 24-hour period from an outside server pinging one of my services. Another from the instance inside the server over the course of a week while experiencing the issue within my system. The only things losing connection are the internet services, the internal ips have a 100% uptime. Now, I'm reaching out to you all for any ideas or troubleshooting tips you might have. What could be causing this problem? And how can I further investigate and resolve it? I've already gone through the usual troubleshooting steps, such as checking network configurations, verifying container settings, and ensuring that the issue is not specific to any particular container. However, I'm still unable to pinpoint the root cause. The system has been running fine for month up until a month or so. It's also worth pointing out that during these outages I don't lose internet connection in my home network. I also have the outside uptime kuma pointing to my domain and it has a 100% uptime. Thanks in advance for your assistance! ivpiter-diagnostics-20230608-1325.zip ivpiter-syslog-20230608-1125.zip
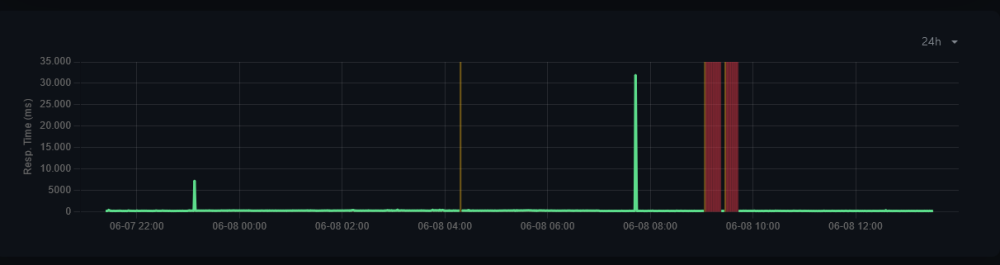
-
I am having exactly the same problem. Qbitorrent crashes with a: When this happens web ui becomes unresponsive, docker kill makes the ui work again, but qbitorrent won't restart correctly. The only fix is to restart docker, which will not start again for me until I fully restart. I also have the umount error while turning off the array. The problem seemed to go away after last update, I got a couple days uptime. But it happened twice yesterday.
-
Hello everyone, I have been having some troubles that I'm unable to diagnose. I host some services through nginx proxy manager and it's been working fine for the most part. The problem is that sometimes I'll lose all connectivity to it and everything will come back on its own after a while (1 hour or more). While that happens I'm able to ping home through the Internet, but the ports that point to nginx show as closed (443 and 80). I'm also able to connect to one of the computers in my home network with teamviewer, so it's clear that I did not lose internet access. Today that happened at around 11:00 and recovered the connectivity at around 12:45. I was able to get to a computer and connect with teamviewer and the server was accessible in the home network, but the web ui was really slow and failed to load the docker tab. Looking at the logs I'm unable to find any clue as to what is going on. Just a bunch of errors of docker apps unable to download images. I have a 10gbe Mellanox card in the system. And I have it set it up so that it's the only up connection. Is it the card resetting? How can I tell? Thanks for the help! ivpiter-diagnostics-20221222-1258.zip ivpiter-syslog-20221222-1200.zip
-
Hello, Today 2 drives became disabled, after a restart and trying to rebuild them I see this error spammed: "Oct 13 15:11:55 ivpiter kernel: ata5: EH complete Oct 13 15:11:55 ivpiter kernel: ata5.00: exception Emask 0x10 SAct 0x70 SErr 0x90200 action 0xe frozen Oct 13 15:11:55 ivpiter kernel: ata5.00: irq_stat 0x00400000, PHY RDY changed Oct 13 15:11:55 ivpiter kernel: ata5: SError: { Persist PHYRdyChg 10B8B } Oct 13 15:11:55 ivpiter kernel: ata5.00: failed command: WRITE FPDMA QUEUED Oct 13 15:11:55 ivpiter kernel: ata5.00: cmd 61/00:20:38:3b:e2/04:00:00:00:00/40 tag 4 ncq dma 524288 out Oct 13 15:11:55 ivpiter kernel: res 40/00:20:38:3b:e2/00:00:00:00:00/40 Emask 0x10 (ATA bus error) Oct 13 15:11:55 ivpiter kernel: ata5.00: status: { DRDY } Oct 13 15:11:55 ivpiter kernel: ata5.00: failed command: WRITE FPDMA QUEUED" The rebuilding speed was really slow, I stopped it for now. Any ideas? Thanks ivpiter-diagnostics-20221013-1517.zip ivpiter-syslog-20221013-1313.zip
-
I just updated my bios, which was few versions behind. I also added the line in my usb, and I also changed the usb because I was running out of ideas. I still have the same problem, but now when the system boots, it shows the nvme correctly and I am able to browse it. After a while, it shows this errors: blk_update_request: I/O error, dev nvme1n1, sector 151748736 op 0x1:(WRITE) flags 0x104000 phys_seg 18 prio class 0 followed by many more. What also is troubling is the fact that my docker files are in my other nvme, but even though docker starts, none works, they all through a read error. Thanks for the help! Edit: After the error the nvme is showing incorrect data, which was not on there initially. ivpiter-syslog-20220925-1029.zip ivpiter-diagnostics-20220924-1449.zip After a reboot I started the array in maintenance mode and did a xfs_test which resulted in:
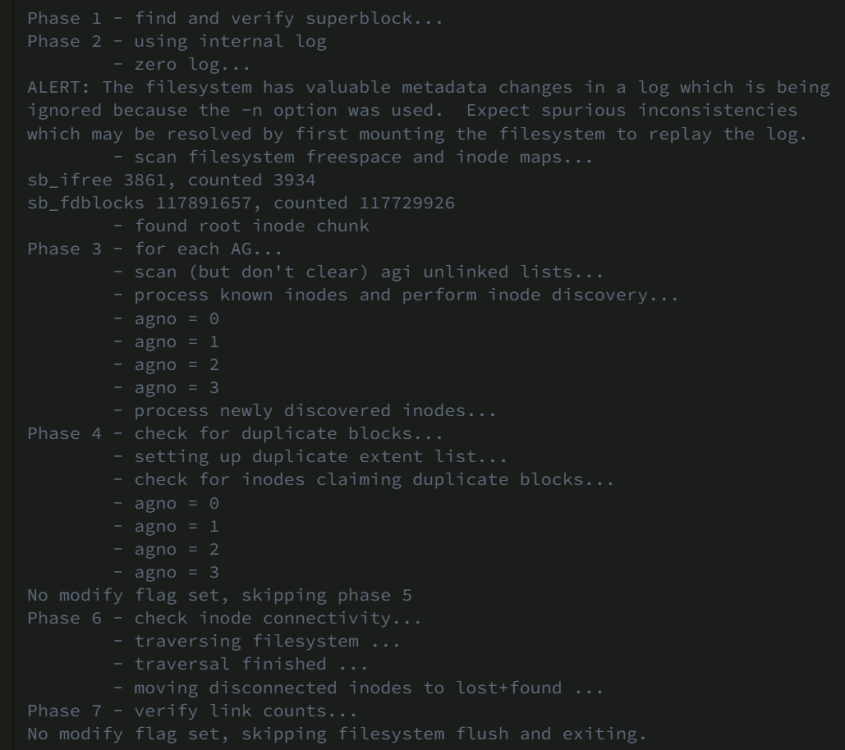
-
Hello everyone, Yesterday one of my cache nvme suddenly disappeared, I rebooted and was able to take it out of the array. I then proceed with and xfs_repair but it failed. Today It was not even found in the missing addon and I restarted again. Now it now longers detects it. In the logs it keeps saying: XFS (nvme0n1p1): log I/O error -5 Funnily enough another drive is missing, which was used as cache for downloads. How do I proceed? I can I format it through Unraid? Should I just take it out of the system? Edit: The cache nvme in which I have my appdata / domains is listed as mounted but is also not accessible. Which makes me think something else is going on. Thanks. ivpiter-diagnostics-20220924-1449.zip ivpiter-syslog-20220924-1248.zip
-
Sorry I had a busy weekend. I know have both disks out of the array + a brand new 14tb drive (also in unassigned). The ncdu command of disk 2 is: and disk 4 is: Looks like disk 2 is good to go, but disk 4 has nearly everything on lost + found.
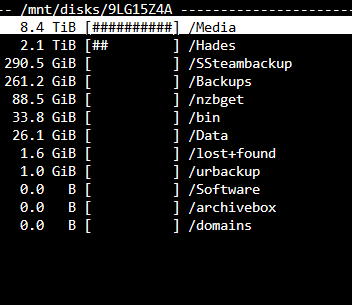
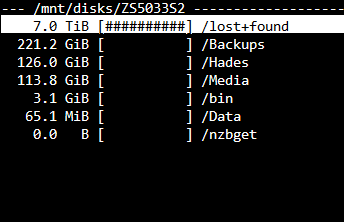
-
Yes this is disk 4. Looking at the contents of this disk with UD it looks like everything is in lost + found. That means that if I create a new config I'll lose parity and then I'll have to copy everything from the lost+found folder from the disk itself. Right now I have emulated lost+found with exactly the same data right?
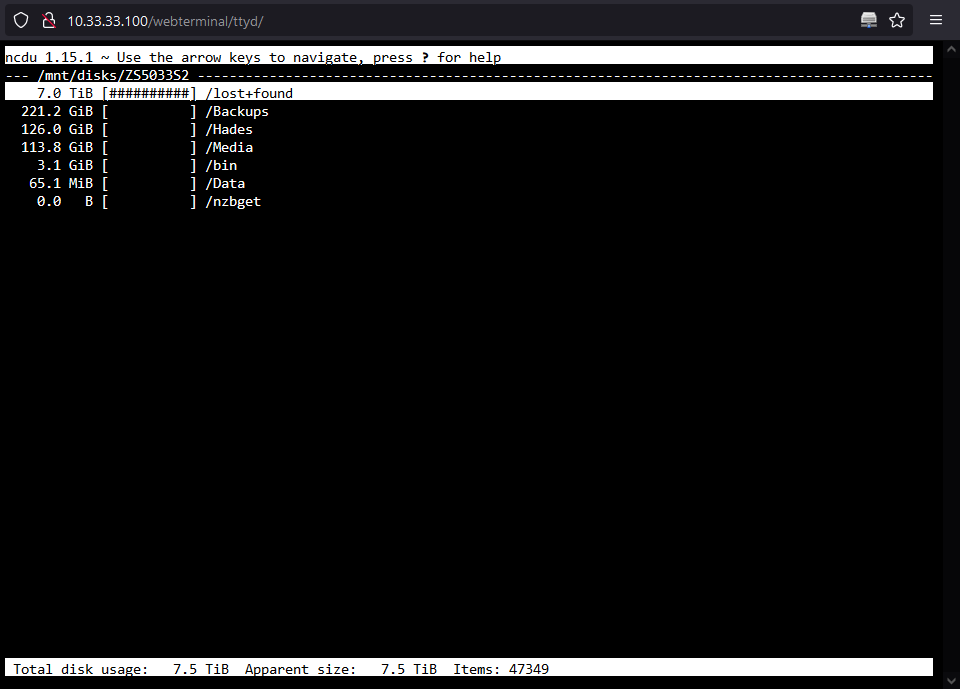
-
Disk 4 has always been attached, just out of the array. Here is a new diagnostics file. What I mean is that I'll have a brand-new disk today. Should I try rebuilding the array? Right now I have no parity whatsoever. ivpiter-diagnostics-20220617-1541.zip
-
The new disk should be arriving today, should I put it into the array as disk 4? And then try to recover data from the other disks? How do I go about this?
-
Disk 2 is the one that is now disabled in the array. Do you mean that the contents in the disk might be in better shape than the ones being emulated and now showing in Unraid? Disk 4 is the one that is not currently in the array. I installed unassigned plugins, mounted it and I can see some data in it, I assume that it is correct. This disk is the one that started giving me problems previously on my last post, so went it started getting errors again I took it out and ordered a replacement (assuming it was bad). I will probably rma it after the new one arrives. Knowing now that the errors continued to show after taking it, it would make sense to assume that it's not necessarly bad, and another issue may be the cause of all of the errors I am now seeing. This is a screenshot of the current state of the arra (All spin down disk are ok)
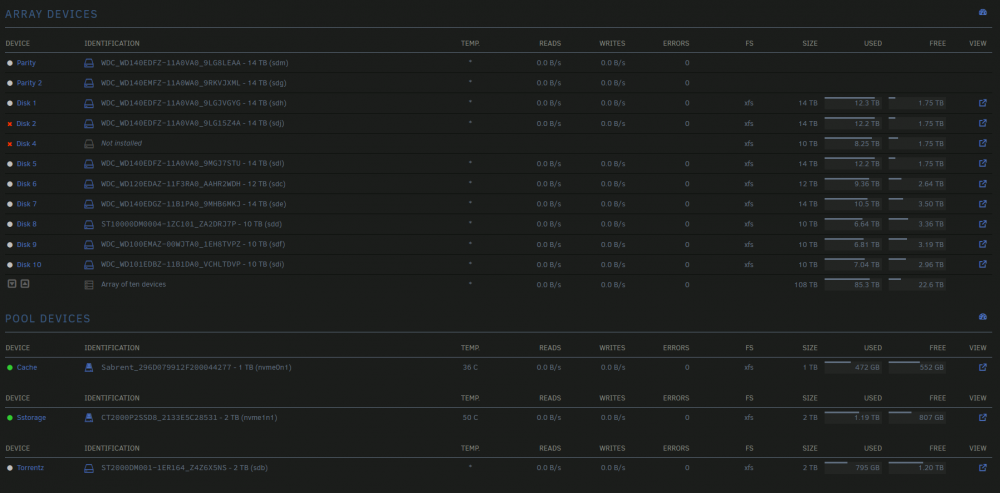
-
What should I do then? I do have backups of important files, but those 18tb are probably not part of them. There is really no way to salvage them? Is there any way to know which files are in there? I do have 1 disk ready (which was old disk4) and another one on the way. Should I try to put the old disk back into the array and start parity. Do I wait until Monday with the new one and do the two at the same time?
-
The sizes of files in disks 6,7 and 10 is relatively small, compared to the ones that I repaired today. 6 has 3.6GB, 7 1.8GB and just 6B on 10.
-
Oh yes, this was the very first day that I installed the new motherboard + cpu + ram combo, I think that because I had xmp enabled everything started to get corrupted. I changed that and all was good. It could be possible that I repaired the disks then. I meant the sizes of the "files" are a lot smaller, a lot less data in there.
-
That could very well be a problem, since the card doesn't have a fan and it's been really hot in here lately. I use a Norco Rack Case with three fans at the front, but nothing on the back. Perhaps I could zip tie a one of those 40mm fans in the heat sink of the card. In terms of power I have the server connected directly to a UPS which is connected directly into the wall. I am having a lot of power outages though since de AC sometimes triggers the breakers. It could be possible that I did sometime ago, I can't remember. The sizes on these drives are a lot smaller though.
-
I don't remember doing any filesystem repair prior to the last thread that I started which was 2 weeks ago. On the previous one I did disk 8 and disk 4. Today I did 2, 4 and 8. So I have no idea why 6,7 and 10 are appearing here. I had one disk fail once, which I replaced and rebuild from parity. And there was also a lot of changes due to replacing drives, but the parity operation always showed 0 errors. I also used to do monthly parity checks (I set them to once every 3 months now), and never had problem.
-
Yes, disk3 was taken out of the array a long time ago (to shrink the array). Disk2 is disabled and disk4 is out of the array I still have it inside the case. I am waiting on a replacement for it. All the other drives are green. Here is a screenshot of the lost+found share + ncdu command, it looks like 18+TB of data are on there Now I have a new drive on the way which should arrive on Monday + the one that I took out before (the Seagate). What is the best course of action?

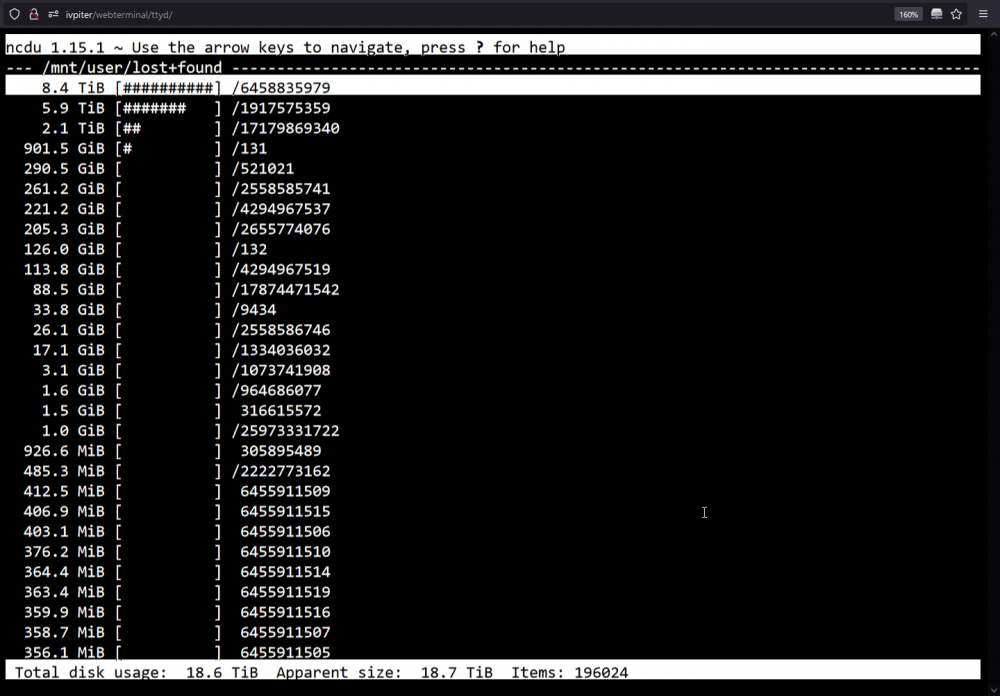
-
After yet another reboot, the array came back online but disk 2 is still disabled. ivpiter-diagnostics-20220615-2155.zip
-
It has been working rock solid for 1 year +, it started behaving erratically two weeks ago. Nothing in the configuration changed. I tested the ram last time, have no idea how to further test it. Could it by any chance a problem with the usb drive? I remember having problems with them in the past. I brought the server back up and started the array which looked fine for a second but then I got this message: Automatic Unraid no array operation will start. And the array seems like it's not started + it doesn't give me any option, just shutdown or reboot. ivpiter-diagnostics-20220615-2020.zip