




joshbgosh10592
Members
-
Joined
-
Last visited
Everything posted by joshbgosh10592
-
Good luck. I've reinstalled the docker container and macOS, checked permissions, everything mentioned in these forums and I've never gotten more than the first backup to run successfully. I've given up.
-
I just updated from 6.10.0 to 6.10.3 immediately after doing a "shrink array" to replace an empty data drive with a much larger drive. I did select the "Parity is already valid" checkbox when I performed it Now, however, when I reboot the server, the array doesn't automatically start... The server is assigned a static IP address via it's NIC, and I have a somewhat complex NIC setup with two bonded (802.3ad) 10Gb NICs, two bonded (also 802.3ad) 1Gb NICs, as well as two other independent NICs with their own IPs. I'm wondering if the license check is happening before the NICs are activated? This wasn't an issue with any other version of unRAID though and I've had this setup since I believe 6.8.
-
Not OP, but I also have a similar annoyance. I have the API disconnect error as well. Going off what you're saying about the ALLOWED_ORIGINS, I access my server via nas.domain.com, but without any port forwarding so it's only accessible internally. Is there a way to add nas.domain.com to the ALLOWED_ORIGINS property, or is that a security hazard because technically domain.com is routable?
-
Didn't know that, thank you! I performed that, removed the existing disk from TM, and erased the .sparcebundle and allowed TimeMachine to create a new one and successfully creates the first backup. However, anything after, still the same thing for some reason... This is driving me nuts.. Attempting to mount 'smb://timemachine@timemachine._smb._tcp.local./TimeMachine' 2022-06-28 23:16:43 Mounted 'smb://timemachine@timemachine._smb._tcp.local./TimeMachine' at '/Volumes/.timemachine/timemachine._smb._tcp.local./714A1D80-0056-45C2-8FC5-4ADB7F096A65/TimeMachine' (208.91 GB of 536.87 GB available) 2022-06-28 23:16:43 Initial network volume parameters for 'TimeMachine' {disablePrimaryReconnect: 0, disableSecondaryReconnect: 0, reconnectTimeOut: 60, QoS: 0x0, attributes: 0x1C} 2022-06-28 23:16:44 Configured network volume parameters for 'TimeMachine' {disablePrimaryReconnect: 1, disableSecondaryReconnect: 0, reconnectTimeOut: 30, QoS: 0x20, attributes: 0x1C} 2022-06-28 23:16:44 Skipping periodic backup verification: not needed for an APFS sparsebundle 2022-06-28 23:16:45 'Josh’s MacBook Pro.sparsebundle' does not need resizing - current logical size is 510.03 GB (510,027,366,400 bytes), size limit is 510.03 GB (510,027,366,400 bytes) 2022-06-28 23:16:45 Mountpoint '/Volumes/.timemachine/timemachine._smb._tcp.local./714A1D80-0056-45C2-8FC5-4ADB7F096A65/TimeMachine' is still valid 2022-06-28 23:16:45 Checking for runtime corruption on '/Volumes/.timemachine/timemachine._smb._tcp.local./714A1D80-0056-45C2-8FC5-4ADB7F096A65/TimeMachine/MacBook Pro.sparsebundle' 2022-06-28 23:17:22 Failed to attach using DiskImages2 to url '/Volumes/.timemachine/timemachine._smb._tcp.local./714A1D80-0056-45C2-8FC5-4ADB7F096A65/TimeMachine/MacBook Pro.sparsebundle', error: Error Domain=NSPOSIXErrorDomain Code=19 "Operation not supported by device" UserInfo={DIErrorVerboseInfo=Failed to initialize IO manager: Failed opening folder for entries reading} 2022-06-28 23:17:22 Failed to unmount '/Volumes/.timemachine/timemachine._smb._tcp.local./714A1D80-0056-45C2-8FC5-4ADB7F096A65/TimeMachine', Disk Management error: { Target = "file: Target = "file:///Volumes/.timemachine/timemachine._smb._tcp.local./714A1D80-0056-45C2-8FC5-4ADB7F096A65/TimeMachine/"; 2022-06-28 23:17:22 Failed to unmount '/Volumes/.timemachine/timemachine._smb._tcp.local./714A1D80-0056-45C2-8FC5-2DDB7F096A54/TimeMachine', error: Error Domain=com.apple.diskmanagement Code=0 "No error" UserInfo={NSDebugDescription=No error, NSLocalizedDescription=No Error.} 2022-06-28 23:17:22 Waiting 60 seconds and trying again. 2022-06-28 23:17:22 Cancelling backup because volume '/Volumes/.timemachine/timemachine._smb._tcp.local./714A1D80-0056-45C2-8FC5-4ADB7F096A65/TimeMachine' was unmounted. 2022-06-28 23:17:22 Requested backup cancellation or termination 2022-06-28 23:17:23 Backup cancelled (22: BACKUP_CANCELED) 2022-06-28 23:17:23 Failed to unmount '/Volumes/.timemachine/timemachine._smb._tcp.local./714A1D80-0056-45C2-8FC5-4ADB7F096A65/TimeMachine', Disk Management error: { Target = "file: Target = "file:///Volumes/.timemachine/timemachine._smb._tcp.local./714A1D80-0056-45C2-8FC5-4ADB7F096A65/TimeMachine/"; 2022-06-28 23:17:23 Failed to unmount '/Volumes/.timemachine/timemachine._smb._tcp.local./714A1D80-0056-45C2-8FC5-4ADB7F096A65/TimeMachine', error: Error Domain=com.apple.diskmanagement Code=0 "No error" UserInfo={NSDebugDescription=No error, NSLocalizedDescription=No Error.} 2022-06-28 23:17:23 Cleared pending cancellation request
-
I have not, but actually, I'd rather not have time machine working than reinstall macOS and have to set everything up again lol
-
I figured I'd give it some time, but the initial backup was June 14th and multiple times a day, I've tried to kick off a manual backup to no avail..
-
Yup, that was my problem... I was trying to change the username and thought that was all I'd need, thank you! However... I had very high hopes of this! Setting up TM was super simple. However, I still cannot get it to sync after the first time.. I don't understand why it's throwing "Operation not supported by device"... 2022-06-25 01:02:02 Running for notifyd event com.apple.system.powersources.source 2022-06-25 01:02:32 TMPowerState: 2 2022-06-25 01:02:32 Not prioritizing backups with priority errors. lockState=0 2022-06-25 01:02:32 Starting automatic backup 2022-06-25 01:02:32 Attempting to mount 'smb://timemachine@timemachine._smb._tcp.local./TimeMachine' 2022-06-25 01:02:34 Mounted 'smb://timemachine@timemachine._smb._tcp.local./TimeMachine' at '/Volumes/.timemachine/timemachine._smb._tcp.local./365D6DA7-1C3D-454E-AA94-D1F38d7f34eaa/TimeMachine' (212.63 GB of 536.87 GB available) 2022-06-25 01:02:34 Initial network volume parameters for 'TimeMachine' {disablePrimaryReconnect: 0, disableSecondaryReconnect: 0, reconnectTimeOut: 60, QoS: 0x0, attributes: 0x1C} 2022-06-25 01:02:34 Configured network volume parameters for 'TimeMachine' {disablePrimaryReconnect: 1, disableSecondaryReconnect: 0, reconnectTimeOut: 30, QoS: 0x20, attributes: 0x1C} 2022-06-25 01:02:35 Skipping periodic backup verification: not needed for an APFS sparsebundle 2022-06-25 01:02:36 'MacBook Pro.sparsebundle' does not need resizing - current logical size is 510.03 GB (510,027,366,400 bytes), size limit is 510.03 GB (510,027,366,400 bytes) 2022-06-25 01:02:36 Mountpoint '/Volumes/.timemachine/timemachine._smb._tcp.local./365D6DA7-1C3D-454E-AA94-D1F38d7f34eaa/TimeMachine' is still valid 2022-06-25 01:02:36 Checking for runtime corruption on '/Volumes/.timemachine/timemachine._smb._tcp.local./365D6DA7-1C3D-454E-AA94-D1F3869E31C2/TimeMachine/MacBook Pro.sparsebundle' 2022-06-25 01:03:15 Failed to attach using DiskImages2 to url '/Volumes/.timemachine/timemachine._smb._tcp.local./365D6DA7-1C3D-454E-AA94-D1F38d7f34eaa/TimeMachine/MacBook Pro.sparsebundle', error: Error Domain=NSPOSIXErrorDomain Code=19 "Operation not supported by device" UserInfo={DIErrorVerboseInfo=Failed to initialize IO manager: Failed opening folder for entries reading} 2022-06-25 01:03:15 Failed to unmount '/Volumes/.timemachine/timemachine._smb._tcp.local./365D6DA7-1C3D-454E-AA94-D1F38d7f34eaa/TimeMachine', Disk Management error: { Target = "file: Target = "file:///Volumes/.timemachine/timemachine._smb._tcp.local./365D6DA7-1C3D-454E-AA94-D1F38d7f34eaa/TimeMachine/"; 2022-06-25 01:03:15 Failed to unmount '/Volumes/.timemachine/timemachine._smb._tcp.local./365D6DA7-1C3D-454E-AA94-D1F38d7f34eaa/TimeMachine', error: Error Domain=com.apple.diskmanagement Code=0 "No error" UserInfo={NSDebugDescription=No error, NSLocalizedDescription=No Error.} 2022-06-25 01:03:15 Waiting 60 seconds and trying again. 2022-06-25 01:03:15 Cancelling backup because volume '/Volumes/.timemachine/timemachine._smb._tcp.local./365D6DA7-1C3D-454E-AA94-D1F38d7f34eaa/TimeMachine' was unmounted. 2022-06-25 01:03:15 Requested backup cancellation or termination 2022-06-25 01:03:16 Backup cancelled (22: BACKUP_CANCELED) 2022-06-25 01:03:16 Failed to unmount '/Volumes/.timemachine/timemachine._smb._tcp.local./365D6DA7-1C3D-454E-AA94-D1F38d7f34eaa/TimeMachine', Disk Management error: { Target = "file: Target = "file:///Volumes/.timemachine/timemachine._smb._tcp.local./365D6DA7-1C3D-454E-AA94-D1F38d7f34eaa/TimeMachine/"; 2022-06-25 01:03:16 Failed to unmount '/Volumes/.timemachine/timemachine._smb._tcp.local./365D6DA7-1C3D-454E-AA94-D1F38d7f34eaa/TimeMachine', error: Error Domain=com.apple.diskmanagement Code=0 "No error" UserInfo={NSDebugDescription=No error, NSLocalizedDescription=No Error.} 2022-06-25 01:03:16 Cleared pending cancellation request
-
I cannot figure out what I'm doing wrong... I leave everything default (so the container creates the share required) and run the chown command, but timemachine still is writing to the docker image. I believe I've read everything in these two pages but haven't found anything I'm forgetting to do.
-
I removed the container and openrct2 folder and was able to get it to read an old .sv6 file I had previously, but I still get the "Unable to connect to server" error when I connect, but it lets me right in anyway without any other issues. Also, because OpenRCT2 now has their own save format, Name.park, is there anything besides changing the filename within the Docker settings that needs done to get the server to use that file? I tried and it just reverted to my old save file (not the docker default). But if I try to revert the save to the docker default's "docker.sv6", it doesn't honor my change.... Thank you, I really appreciate the help so far!
-
Assuming you mean /mnt/user/appdata/openrct2/user-data/config.ini, they are set to what I customized it to: player_name = "Josh" default_password = "CustomSecret" server_name = "CustomName" server_description = "Custom Description. advertise = true advertise_address = "" master_server_url = "" That's strange that since the password is on by default for your container, yet I am not prompted to enter it.. I also should note that currently I do not have ports forwarded so I manually entered my NAS's IP address in my OpenRCT2 client to connect locally. However I don't see my server being advertised within the master server. Maybe because the address property is null?
-
Thank you for looking into it! So, the server customization, such as the name and description (even though it's not prompting for a password or a welcome message, maybe because my client is already a known client with a key?), however the save file specified in the Docker settings isn't being honored for some reason. It keeps defaulting to "docker.sv6" instead of the filename I have listed. Somehow, even after I overwrite the "docker.sv6" with my own file. I'm confused on how that's even possible, unless that save file is cached somewhere..? Might also be something to note, when I do connect to the server running within Docker, I get a "unable to connect to server" red error right away, but it connects anyway.
-
the appdata share is set to prefer. I'm assuming it should be only? There's been plenty of room on that cache pool though, so it shouldn't have moved to an HDD.
-
(For OpenCTR2) Not the person who asked the question, but I'm also having that issue. I'm changing that value, as well as other values within /mnt/array_cache/appdata/openrct2/user-data/config.ini, such as default_password (that should require users to enter a password, right?) and it appears that the container is ignoring me partially. server_name, description is working, however.
-
I'm able to create the first backup without issues, but any backup afterwards just ends up "Preparing Backup" and then Stopping... macOS 12.3.1, unRAID 6.9.1
-
Yup, sorry, like I said, I felt like a complete noob and was making a stupid, simple mistake. Thank you! I'm very new to dockers and forgot that their data is just a folder inside the appdata share.
-
I also typically use nano, but when I try to edit it (using the container's CLI), no commands work - not nano, not ping, not even vi. I have a feeling I'm just doing something wrong and it's a simple mistake lol..
-
I feel like a complete noob, but how do you even edit the guacamole.properties? nano, vim, nor vi seem to work...
-
I accidentally filled up a share that uses only a cache pool to the point where unRAID reported I was using something like 3.3TB. The cache pool consists of one 2TB and one 3TB drive in a RAID0 format. Because of the miss-match size, I should have a usable of 4TB (2TB across both disks), right? I emptied the share down to 2.96TB. When I attempt to copy anything to the share on from any client, I receive an error, and when I try to nano via unRAID's CLI, I get Error writing test.txt: No medium found. Because of the issue with unRAID, I've ignored troubleshooting clients' issues, which is why I'm only saying that they return an error. I'm still getting this issue, even after a reboot. I can read perfectly normal from this share. Any ideas? Main page view: Balance Status of the cache pool: fdisk -l returns this for the two disks in ShareHDD (sdh and sdi): Disk /dev/sdh: 1.82 TiB, 2000398934016 bytes, 3907029168 sectors Disk model: WDC WD20EFRX-68E Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Disklabel type: dos Disk identifier: 0x00000000 Device Boot Start End Sectors Size Id Type /dev/sdh1 64 3907029167 3907029104 1.8T 83 Linux Disk /dev/sdi: 2.73 TiB, 3000592982016 bytes, 5860533168 sectors Disk model: WDC WD30EFRX-68E Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Disklabel type: gpt Disk identifier: CFDAB87B-8FBD-4B4F-B745-3C2DC2DF1340 Device Start End Sectors Size Type /dev/sdi1 64 5860533134 5860533071 2.7T Linux filesystem
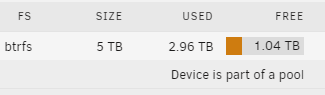
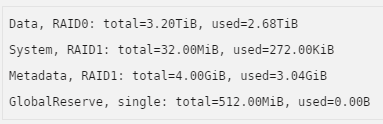
-
Yup, that's exactly what happened. Inside the share settings, it shows what I want, but in the share overview, it shows the old share name (You can see where the new share (Share A) I created shows "Array_cache". I toggle it to another cache pool and back, and now I'm writing to the cache correctly (well, for some reason it's moving the files in and back out through the VM instead of just moving it within the NAS. Previously, I was able to move at around 200MB/s while putting no strain on the VM NIC (something like NFS Offload). I'm assuming that's just how I have the shares mapped in the VM?) Thank you!!

-
So, it's set to use the original cache pool from pre-6.9, however I renamed it once I created the other pools. Could the rename of the cache pool have screwed it up, even though the GUI says it's correct?
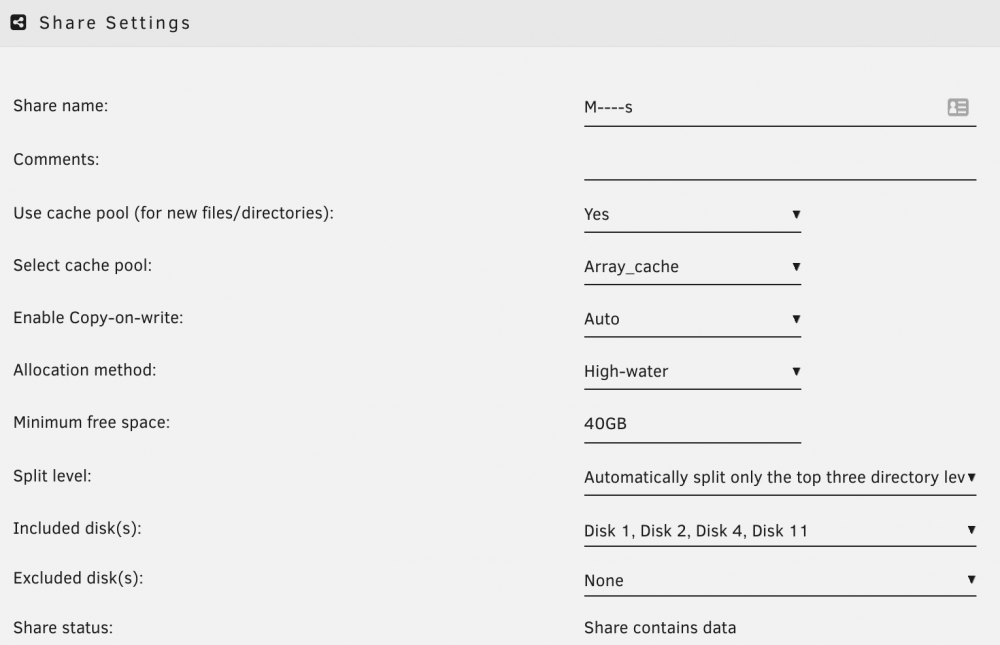
-
I'd rather be slightly generic publicly on the share names (unless my explanation below doesn't make sense and it's just too confusing). Share A is named "T------s" in the configs (short term), and Share B is "M----s" (long term). When I'm done working the files in the short term share (Share A), I copy them to the long term (Share B). This is to prevent the spinning disks in Share B from constantly being awake (and bogged down by the work being performed.
-
Nope, they're new files to Share B.
-
Thank you! Here it is. So this isn't expected behavior then? I know, this is me manually moving files from one share (cache only) to another share (cache enabled, using a different cache pool than original.) Thank you though nas-diagnostics-20210819-1917.zip
-
Kind of confusing, but I'm having an issue where I try to copy a file from a share A that is set to only use cache pool A, to share B that uses cache pool B, but mover moves files to the array. Cache A is RAID5 NVME SSDs and Cache B is RAID1 NVME SSDs. When I use Windows (so, SMB) to copy from share A to share B, the copy writes directly to the array disks, which are HDDs, thus making the copy process MUCH slower. Is this expected behavior? I originally was using Share A via unassigned devices and I wrote to the cache of share B but wanted to be able to control it natively.
-
I've also noticed the /var/log/nginx throwing the out of shared memory error... Spamming this: 2021/06/19 01:10:53 [crit] 6642#6642: ngx_slab_alloc() failed: no memory 2021/06/19 01:10:53 [error] 6642#6642: shpool alloc failed 2021/06/19 01:10:53 [error] 6642#6642: nchan: Out of shared memory while allocating channel /cpuload. Increase nchan_max_reserved_memory. 2021/06/19 01:10:53 [error] 6642#6642: *5824862 nchan: error publishing message (HTTP status code 507), client: unix:, server: , request: "POST /pub/cpuload?buffer_length=1 HTTP/1.1", host: "localhost" 2021/06/19 01:10:53 [crit] 6642#6642: ngx_slab_alloc() failed: no memory 2021/06/19 01:10:53 [error] 6642#6642: shpool alloc failed 2021/06/19 01:10:53 [error] 6642#6642: nchan: Out of shared memory while allocating channel /var. Increase nchan_max_reserved_memory. 2021/06/19 01:10:53 [alert] 6642#6642: *5824863 header already sent while keepalive, client: 10.9.0.240, server: 0.0.0.0:80 2021/06/19 01:10:53 [alert] 27152#27152: worker process 6642 exited on signal 11 2021/06/19 01:10:53 [crit] 6798#6798: ngx_slab_alloc() failed: no memory




