




NLDer
Members
-
Joined
-
Last visited
Everything posted by NLDer
-
Good morning I apologize if this is posted in the wrong section, I'm new to the support forums as I don't ever have any issues. However, this past week I had to catch up on a bunch of updates as I had moved and hadn't gotten time to look at everything in a while. So, without further ado, here's the error message I get: 2022-10-17 08:18:59,036 DEBG 'radarr' stdout output: [Error] FluentMigrator.Runner.MigrationRunner: database disk image is malformed database disk image is malformed While Processing: "UPDATE "ImportListMovies" SET "MovieMetadataId" = (SELECT "MovieMetadata"."Id" FROM "MovieMetadata" WHERE "MovieMetadata"."TmdbId" = "ImportListMovies"."TmdbId")" [v4.2.4.6635] System.Exception: database disk image is malformed database disk image is malformed While Processing: "UPDATE "ImportListMovies" SET "MovieMetadataId" = (SELECT "MovieMetadata"."Id" FROM "MovieMetadata" WHERE "MovieMetadata"."TmdbId" = "ImportListMovies"."TmdbId")" ---> code = Corrupt (11), message = System.Data.SQLite.SQLiteException (0x800007EF): database disk image is malformed database disk image is malformed at System.Data.SQLite.SQLite3.Reset(SQLiteStatement stmt) at System.Data.SQLite.SQLite3.Step(SQLiteStatement stmt) at System.Data.SQLite.SQLiteDataReader.NextResult() at System.Data.SQLite.SQLiteDataReader..ctor(SQLiteCommand cmd, CommandBehavior behave) at System.Data.SQLite.SQLiteCommand.ExecuteReader(CommandBehavior behavior) at System.Data.SQLite.SQLiteCommand.ExecuteNonQuery(CommandBehavior behavior) at System.Data.SQLite.SQLiteCommand.ExecuteNonQuery() at FluentMigrator.Runner.Processors.SQLite.SQLiteProcessor.ExecuteNonQuery(String sql) --- End of inner exception stack trace --- I am running portainer as well and have an earlier image, however, I don't know how to recover this, or fix the DB malformed error. As I mentioned, I have never really had any difficulties other than initial setup and learning curves when I started using unraid for all of this. I was previously a Windows install ... some 3 or 4 years ago now, maybe more. Thanks in advance for anyone that can offer me any insight in to this and how to recover so I don't have to set up from scratch.
-
Good day... Wondering if anyone else is experiencing issues with Plex stating : There are no playable items. So far this happens on my Roku and Android Phone, however, It works from my windows tablet just fine.... same episode. Plex Version 4.59.2
-
I know this is an old thread.... though I am hoping I can tag on to this one with the following: My Plex Docker won't update past version 1.22.2.4282. The latest version is stated to be: 1.23.4.4805. I've run the update several times, and the command completes successfully, however the docker continues to remain on the same version. Also, since recently, my library's are showing no content. However the continue watching, recommendations, collections, and playlists all show just fine. Error: There was an unexpected error loading this library Please visit our forums if you continue to experience problems
-
THanks for fixing... am running it again on a different drive. The one from above I simply let unRaid rebuild it and take a chance. This second drive is now running pre-clear. Will update to let you know how it goes.... Thank you gfjardim
-
Apologies.... an old version of "UD" ? As in "Unassigned Devices" ?
-
I should add to this:
-
What I am unsure of at this time, is the Preclear still running, or not? There is no "duration" information shown on the Main page any more. However the red X to sop Preclear is still available. #AmConfused

-
I have one drive I am replacing at this time. ANd I have only 1 Parity disk.
-
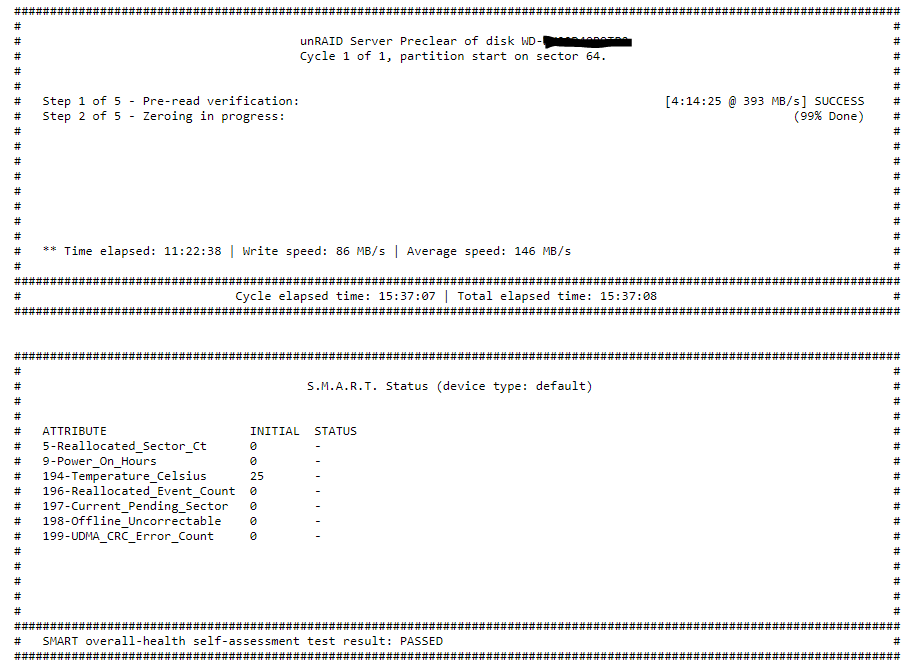
Any help would be appreciated. I am running in to PreClear errors... without any actual errors showing, except a warning? In the MAIN tab I see an error stating: "Error encountered, please verify the log" The log: Dec 10 08:15:08 Tower kernel: sd 1:0:0:0: [sdb] 11721045168 512-byte logical blocks: (6.00 TB/5.46 TiB) Dec 10 08:15:08 Tower kernel: sd 1:0:0:0: [sdb] 4096-byte physical blocks Dec 10 08:15:08 Tower kernel: sd 1:0:0:0: [sdb] Write Protect is off Dec 10 08:15:08 Tower kernel: sd 1:0:0:0: [sdb] Mode Sense: 7f 00 10 08 Dec 10 08:15:08 Tower kernel: sd 1:0:0:0: [sdb] Write cache: enabled, read cache: enabled, supports DPO and FUA Dec 10 08:15:08 Tower kernel: sd 1:0:0:0: [sdb] Attached SCSI disk Dec 10 08:15:32 Tower emhttpd: WD-XXXXXXX Dec 10 08:25:18 Tower preclear_disk_WD-XXXXXXX: Command: /usr/local/emhttp/plugins/preclear.disk/script/preclear_disk.sh --notify 2 --frequency 1 --cycles 1 --no-prompt /dev/sdb Dec 10 08:25:23 Tower preclear_disk_WD-XXXXXXX: Pre-Read: dd if=/dev/sdb of=/dev/null bs=2097152 skip=0 count=6001175126016 conv=notrunc,noerror iflag=nocache,count_bytes,skip_bytes Dec 10 08:30:31 Tower preclear.disk: Pausing preclear of disk 'sdb' Dec 10 08:30:51 Tower preclear.disk: Resuming preclear of disk 'sdb' Dec 10 12:40:07 Tower preclear_disk_WD-XXXXXXX: Zeroing: dd if=/dev/zero of=/dev/sdb bs=2097152 seek=2097152 count=6001173028864 conv=notrunc iflag=count_bytes,nocache,fullblock oflag=seek_bytes And the Preview shows the following: unRAID Server Preclear of disk WD-XXXXXXX Cycle 1 of 1, partition start on sector 64. Step 1 of 5 - Pre-read verification: [4:14:25 @ 393 MB/s] SUCCESS Step 2 of 5 - Zeroing in progress: (99% Done) Time elapsed: 11:22:38 | Write speed: 86 MB/s | Average speed: 146 MB/s Cycle elapsed time: 15:37:07 | Total elapsed time: 15:37:08 ##### # # # S.M.A.R.T. Status (device type: default) ATTRIBUTE INITIAL STATUS 5-Reallocated_Sector_Ct 0 - 9-Power_On_Hours 0 - 194-Temperature_Celsius 25 - 196-Reallocated_Event_Count 0 - 197-Current_Pending_Sector 0 - 198-Offline_Uncorrectable 0 - 199-UDMA_CRC_Error_Count 0 - SMART overall-health self-assessment test result: PASSED It looks to be running, but no time indicator anymore. I still have the red X option to "Stop Preclear" Anyone have any thoughts on this before I hit the X in error when I should be letting it do it's thing? At the bottom of my window it does state: "Read Check 46%" but I don't know if that is to do with the Preclear. I think this is to do with the Array Operation, not this disk itself since the disk size is 6TB and it is currently at: 10 TB Elapsed time:11 hours, 1 minute Current position:4.82 TB (48.2 %) Estimated speed:105.7 MB/sec Estimated finish:13 hours, 38 minutes I assume this is the Parity drive, which is a 10TB drive.
-
How long did your restore take? Mine has been running for over 3 days now... 19GB in total size.
-
Hello, You mention excluding these folders from the backup config in CA Backup / Restore. Will this reduce the time it takes to restore? I have been running my restore for the last 3 days, and so far I see no indication of where it is at in its progress. Is it supposed to take this long to restore the AppData folder? It's about 19GB in size... I still think it should be faster than that. The two file paths above, are these all files related to the media itself? or does it also include the "watched" markers data? I ask because I would like to know where I am at with my shows, but I do not need to back up all the show metadata, album and cover pictures etc... Plex can re-scrape this info, as long as it still has the actual information of each show and movie. Just not the larger image files. Is it normal for a restore to take this long?
-
Well... seems there's more trouble in paradise.... In attempting to make this work, I figured I could play around with some other containers to see if I could get it to work externally with letsencrypts, etc. Since I have a wildcard, and validate by DNS, I figure I'd use Radarr and Sonarr to test with. Realizing I missed a step - changing the network to the proxynet - as per spaceninvaderone's labeling - however, as he shows in his video, one is supposed to still be able to access the page on the original local network/port number. This does not work for me, at all. Nor is external access available... I have double checked the docker settings and they are configured as per the video. I know this is straying from Jitsi - and I have looked around, but can't find anything. Hoping someone may have a rabbit up their sleeve on this one. Maybe it will make other problems clear for my Jitsi issues I am having. As it stands now, nothing is really accessible through the LetsEncrypt configs. (And yes, I have updated the conf files for the subdomains needed for Radarr and Sonarr.
-
Alright, so I have this almost working... It's been a bit of a pain, and recreating everything - fixing my own mistakes, etc... Thank you so far with everyone's support on previous posts. I feel that I have only one problem left.... I can now reach my jitsi server online through https://meet.mydomain.ca, however when I connect to it and create a meeting, the page turns to an error message which states: Unfortunately, something went wrong. We're trying to fix this. Reconnecting in X sec... " This counts down, and attempts to reconnect. So I do not get a prompt for authentication. And my meeting won't start.... Has anyone experienced this and knows where to resolve this problem?
-
Are you stopping the docker before moving the file in? It can't be running while you do that
-
Turns out my ISP is not the problem: Hello Andrew, We are sorry for the trouble caused. We confirm that no ports are being blocked from VMedia's end as we do not have access as such. May we kindly request you to connect hardwired to the modem and check if the issue still persists? If the issue still persists, kindly reset the modem and check again on a hardwired connection. ... So I also found out that I renamed some containers incorrectly. Went back to the video and made the changes. I will go through the video again to validate all the settings including those for Letsencrypt - although DNS validation is working. What I can do now is get to the local ip on port 8000 and this time I get the login prompt when creating a meeting. Still no video or audio... browser is blocking it, and can't change it for some stupid reason.
-
I have that done... not sure where to go from here now. Maybe I'll trash and reinstall... 🙄
-
Hmmm.... well, I wonder and wonder... I've tried Chrome and FIreFox (IE not supported) I've changed the default permissions in FF to allow camera and mic, still nothing.... This... is frustrating. Back to the port 8000 ... is this something that needs to be forwarded also on the FIrewall?
-
I use Chrome.... I checked those settings and I am unable to change them. The Camera and Mic are both blocked, and grayed out? Odd, I am an admin on that system with full privileges.
-
Ok, I can also... however there is no notification to allow the system to use the camera and microphone. I just get a blank screen pretty much. No add blocker in effect for my local server IP....
-
I have my own domain - which I point to my public IP since it never changes (Hasn't in three years). I used the DNS validation for Let's Encrypt, also allowing me to do a wildcard cert. CNAME is "meet" that points to the root domain "mydomain.ca". So, in theory I should be bale to get to "meet.mydomain.ca". When I check online for open ports using my public IP both 80 and 443 are unreachable. Using the meet.mydomain.ca 443 and 80 are open. I'm starting to think that my ISP blocks 80 and 443 inbound, and therefore does not reach my server. meet.mydomain.ca is open because of the CLoudFlare handling of the proxy, but from CloudFlare to my server, nothing works. I have run packet captures on my firewall and see nothing hitting my interface on 80 or 443 to give me any indication that it is reaching me. SO now I am left with trying to figure out how to get CoudFlare to use a different port to proxy the connectoin, while maintaining the use of letsencrypt certificate. let's encrypt includes my jitsy domain as the default "meet.*;" (or something to that effect) since I am using a wildcard that should cover any subdomain I point back to my server. The container includes mydomain.ca I think I am officially starting to tunnel vision on the problem. I'm starting to lean to the ISP blocking this traffic being the root cause, though am still checking all my configs regardless. I wish there was a way to get to it locally, to see if I can even get it to work on my LAN network - I just don't know how to do this. In portainer I can see the port allocations, but clicking on them - as SpaceInvader already mentioned int he video - does not result in anything. Wondering if anyone else is running in to this problem - it started with CloudFlare's 522 Connectoin Timeout Error when attempting to connect to the meet.mydomain.ca URL which of course is not "mydomain" (used to illustrate the method)
-
@enigma27 I followed all the steps, I think to a T... and in setting up the networks I used SpaceInvader's letsencrypt video. Created the "proxynet" etc... When it came to adding the Jitsi stack, I followed along and configured all 4 instances to use the proxynet, and removed the self-created networks. So here is a question: Do i need to configure the proxynet in my local network to ensure that I can allow this network access to the outside? I run an enterprise FortiGate firewall at home, so nothing is permitted unless I tell it to. However, I got the impression from the videos that the proxynet is an internal virtual network created within unRaid which it will use to handle proxied traffic. Therefor I am to believe that I need nothing for this on my actual LAN to configure, nor any policies to allow it. My real unRaid server IP has access as it needs.
-
I'm worried, because I do not see this record at all in the ENV section. Should it be there? My problem to date, after going through this setup, and before that the setup for LetsEncrypt - because I didn't have it yet - and connecting to cloudflare, etc... is that when I try to go to my meeting URL i get a CLoudFlare 522 Connection Timeout Error. Could this be related to the fact that I do not see this field at all?
-
@SpaceInvaderOne I'm sure you've gotten the notifications from this forum... I, and many others here, would love to know if this is something you are looking in to. I am prepared to help fund your time on this project to make even a "quick and dirty" video guide (even a written step-by-step procedure) to get a functioning docker container install guide for Jitsi. Your guides are awesome! Please, help us... and please provide a donation link in this thread for this project. With respect, Andrew
-
+1 demand unit Would love this to be in the community apps... I just discovered Jitsi today and it works great.
-
So, by adding the container agian, the image was there and has restored my configuration. I'm still not able to get: 1. the logo to show 2. the WebUI option to show - I manually go to the address to open unmanic. Can anyone steer me int he right direction perhaps?


