





DevXen
Members
-
Joined
-
Last visited
-
Okay thank you for the update.
-
i got a couple errors on my most recent backup: Description: Please check the backup log! Copying flash backup to destination failed! Description: Please check the backup log! Error While backing up VM XMLs. Please see the debug log. I couldn't find the log from either of these locations. It's backed them up without any problems for months. it also did send another email saying the backup completed.
-
Just Curious if this has been updated? it quit working awhile ago unfortunately
-
Hey Just Curious have there been any updates to this awesome script? My unraid connect icon is back to orange. but everything else is still blue.
-
About the multiples. When I originally posted it. It has an error. So I posted it again not knowing the other one did. Then about 20 hours later I couldn't find it in the general support forum so I posted it again then saw it was posted 3 times and tried to go in and delete the other 2. But I apologize it was posted more than once. Here's my diagnostics. Thank you. mediaxen-diagnostics-20241218-1007.zip
-
Unraid 6.12.8 I keep getting this error about every hour. I disabled swag thinking that was it but it's still popping up. I'm not sure what it is or how to fix it? Thanks, -Dev Dec 16 06:19:51 MediaXen nginx: 2024/12/16 06:19:51 [error] 28105#28105: peer: 216.21.170.80:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 06:19:51 MediaXen nginx: 2024/12/16 06:19:51 [error] 28105#28105: connect() to [2605:a601:f3ff:2::d815:aa50]:80 failed (101: Network is unreachable) while requesting certificate status, responder: r11.o.lencr.org, peer: [2605:a601:f3ff:2::d815:aa50]:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 07:02:32 MediaXen flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Dec 16 07:20:06 MediaXen nginx: 2024/12/16 07:20:06 [error] 28105#28105: OCSP responder timed out (110: Connection timed out) while requesting certificate status, responder: r11.o.lencr.org, peer: 216.21.170.80:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 07:20:06 MediaXen nginx: 2024/12/16 07:20:06 [error] 28105#28105: connect() to [2605:a601:f3ff:2::d815:aa50]:80 failed (101: Network is unreachable) while requesting certificate status, responder: r11.o.lencr.org, peer: [2605:a601:f3ff:2::d815:aa50]:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 08:02:33 MediaXen flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Dec 16 08:20:11 MediaXen nginx: 2024/12/16 08:20:11 [error] 28105#28105: OCSP responder timed out (110: Connection timed out) while requesting certificate status, responder: r11.o.lencr.org, peer: 216.21.170.80:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 08:20:11 MediaXen nginx: 2024/12/16 08:20:11 [error] 28105#28105: connect() to [2605:a601:f3ff:2::d815:aa50]:80 failed (101: Network is unreachable) while requesting certificate status, responder: r11.o.lencr.org, peer: [2605:a601:f3ff:2::d815:aa50]:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 08:34:53 MediaXen kernel: clocksource: timekeeping watchdog on CPU4: hpet wd-wd read-back delay of 77523ns Dec 16 08:34:53 MediaXen kernel: clocksource: wd-tsc-wd read-back delay of 117542ns, clock-skew test skipped! Dec 16 09:02:35 MediaXen flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Dec 16 09:20:24 MediaXen nginx: 2024/12/16 09:20:24 [error] 28105#28105: OCSP responder timed out (110: Connection timed out) while requesting certificate status, responder: r11.o.lencr.org, peer: 216.21.170.80:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 09:20:24 MediaXen nginx: 2024/12/16 09:20:24 [error] 28105#28105: connect() to [2605:a601:f3ff:2::d815:aa50]:80 failed (101: Network is unreachable) while requesting certificate status, responder: r11.o.lencr.org, peer: [2605:a601:f3ff:2::d815:aa50]:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 10:02:37 MediaXen flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Dec 16 10:20:40 MediaXen nginx: 2024/12/16 10:20:40 [error] 28105#28105: OCSP responder timed out (110: Connection timed out) while requesting certificate status, responder: r11.o.lencr.org, peer: 216.21.170.80:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 10:20:40 MediaXen nginx: 2024/12/16 10:20:40 [error] 28105#28105: connect() to [2605:a601:f3ff:2::d815:aa50]:80 failed (101: Network is unreachable) while requesting certificate status, responder: r11.o.lencr.org, peer: [2605:a601:f3ff:2::d815:aa50]:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 11:20:54 MediaXen nginx: 2024/12/16 11:20:54 [error] 28105#28105: OCSP responder timed out (110: Connection timed out) while requesting certificate status, responder: r11.o.lencr.org, peer: 216.21.170.80:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 11:20:54 MediaXen nginx: 2024/12/16 11:20:54 [error] 28105#28105: connect() to [2605:a601:f3ff:2::d815:aa50]:80 failed (101: Network is unreachable) while requesting certificate status, responder: r11.o.lencr.org, peer: [2605:a601:f3ff:2::d815:aa50]:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 12:02:38 MediaXen flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Dec 16 12:21:04 MediaXen nginx: 2024/12/16 12:21:04 [error] 28105#28105: OCSP responder timed out (110: Connection timed out) while requesting certificate status, responder: r11.o.lencr.org, peer: 216.21.170.80:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 12:21:04 MediaXen nginx: 2024/12/16 12:21:04 [error] 28105#28105: connect() to [2605:a601:f3ff:2::d815:aa50]:80 failed (101: Network is unreachable) while requesting certificate status, responder: r11.o.lencr.org, peer: [2605:a601:f3ff:2::d815:aa50]:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 12:22:51 MediaXen kernel: clocksource: timekeeping watchdog on CPU23: hpet wd-wd read-back delay of 78990ns Dec 16 12:22:51 MediaXen kernel: clocksource: wd-tsc-wd read-back delay of 124946ns, clock-skew test skipped! Dec 16 13:02:38 MediaXen flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Dec 16 13:21:18 MediaXen nginx: 2024/12/16 13:21:18 [error] 28105#28105: OCSP responder timed out (110: Connection timed out) while requesting certificate status, responder: r11.o.lencr.org, peer: 216.21.170.80:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 13:21:18 MediaXen nginx: 2024/12/16 13:21:18 [error] 28105#28105: connect() to [2605:a601:f3ff:2::d815:aa50]:80 failed (101: Network is unreachable) while requesting certificate status, responder: r11.o.lencr.org, peer: [2605:a601:f3ff:2::d815:aa50]:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 14:01:11 MediaXen kernel: clocksource: timekeeping watchdog on CPU16: hpet wd-wd read-back delay of 108393ns Dec 16 14:01:11 MediaXen kernel: clocksource: wd-tsc-wd read-back delay of 111885ns, clock-skew test skipped! Dec 16 14:02:38 MediaXen flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Dec 16 14:21:20 MediaXen nginx: 2024/12/16 14:21:20 [error] 28105#28105: OCSP responder timed out (110: Connection timed out) while requesting certificate status, responder: r11.o.lencr.org, peer: 216.21.170.80:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 14:21:20 MediaXen nginx: 2024/12/16 14:21:20 [error] 28105#28105: connect() to [2605:a601:f3ff:2::d815:aa50]:80 failed (101: Network is unreachable) while requesting certificate status, responder: r11.o.lencr.org, peer: [2605:a601:f3ff:2::d815:aa50]:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 15:02:39 MediaXen flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Dec 16 15:21:31 MediaXen nginx: 2024/12/16 15:21:31 [error] 28105#28105: OCSP responder timed out (110: Connection timed out) while requesting certificate status, responder: r11.o.lencr.org, peer: 216.21.170.80:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 15:21:31 MediaXen nginx: 2024/12/16 15:21:31 [error] 28105#28105: connect() to [2605:a601:f3ff:2::d815:aa50]:80 failed (101: Network is unreachable) while requesting certificate status, responder: r11.o.lencr.org, peer: [2605:a601:f3ff:2::d815:aa50]:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Dec 16 16:02:42 MediaXen flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update
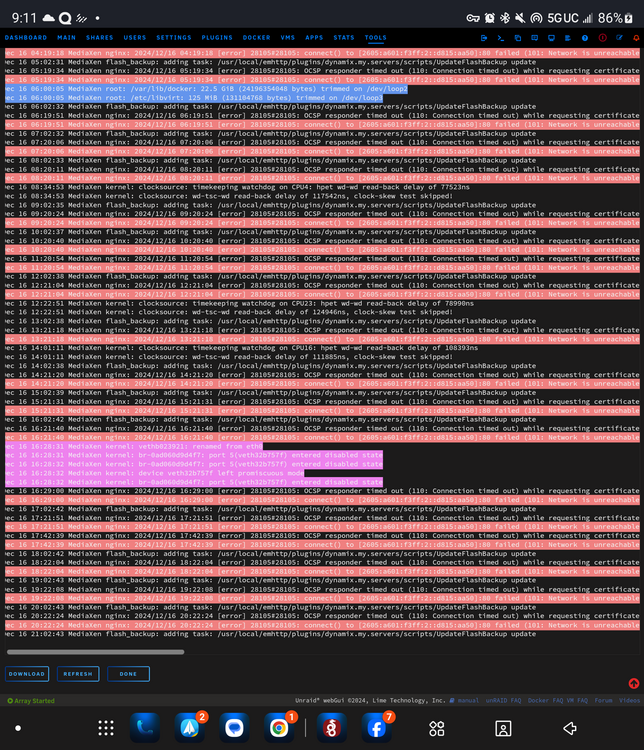
-
I read that in a few other posts on here. So I do keep the main page tab open, and plex's webgui and another dockers webgui. Which for years hasn't been a problem.. but for the last year I've been using a laptop which either gets shut down or put up sleep when it's not in use. So that should be the same as closing them when they aren't in use right? And booting to safe mode I can look up how to do that.. But how is that going to help? As far as I can tell that really is just to see if it still happens with the plugins disabled. But then how would I go through and fligure out what plugin it is if that was the case? Or was there another reason to go to safe mode? -Dev
-
There's a lot of this in the logs. No idea what it is
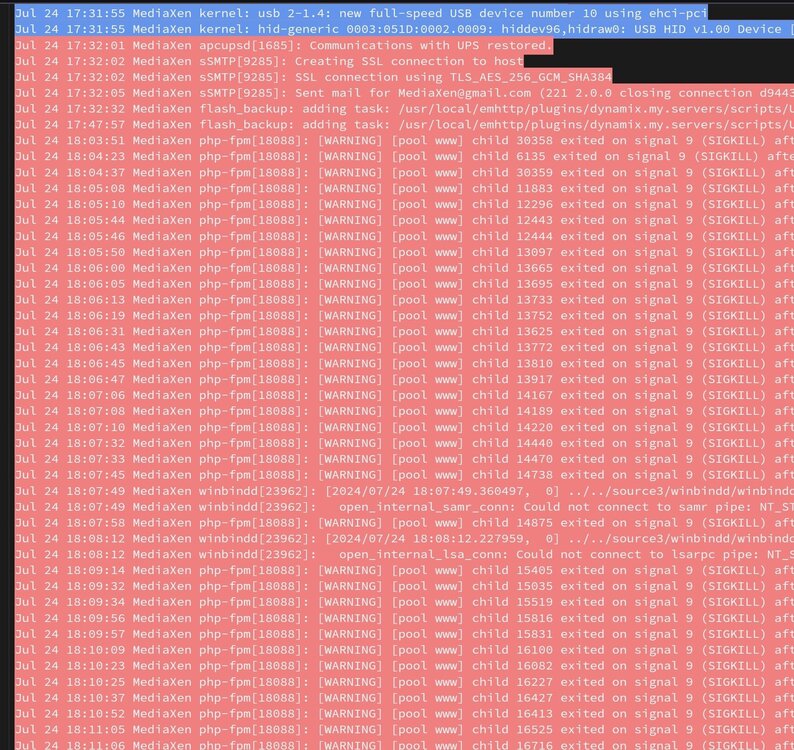
-
So about 2 months ago my server was unresponsive. The GUI pages would only partially load. So I restarted it. And when I restarted it. It didn't detect any of my hard drives. Wtf. So I restarted it again and noticed the adaptec 7000 series controller card didn't boot up. Figured the card just died. And was reluctant to work on it. I have a second server I bought from eBay a few weeks before that. It has a card in IT mode. But not knowing if it would mess up my data if I moved the other server. (I read a few horror stories. And it freaked me out.) - unless someone here has experience with this and can offer their experience in doing that. So last sat I decided what the heck and turned my server on. And the sooner controller card booted. And unraid saw the drives and it started to like normal. It did not do a parity check which was strange but I did get a bunch of emails saying rec hard drives has returned to normal operation or something. My working theory is the adaptec card got hot. (Worked for 5 months before that.) And turned off to protect it's self and the data. So when it cooled off and I turned it on. It worked. Everything has been fine since last sat. 4 days. Today I get to the house to work on it a little. Move some files around. Clear some space and all of a sudden it starts freezing for 1-3 minutes at a time roughly. My Plex is going down and coming up. And I figure it's cause I'm moving files to the array? But it's never done this before. I grabbed a diagnostics file I've attached to see if any of you guys can help me. Thank you, -Dev mediaxen-diagnostics-20240724-1941.zip
-
Thanks. Got the reply. My adaptec is also in hba mode and it died. Maybe from heat. I dunno. I think it died. It doesn't boot on startup to detect the drives. My new server has: Controller: AOC-S3008L-L8e HBA 12Gb/s appears it's not LSI as I thought it was oops. But I have been reading that the adaptec keeps the partitions out of the array. Which means the card in the new server may not be able to read them I guess. Also been bleeding to figure out how to see if the new card is in it mode.
-
Hey. Any ideas what would happen if you moved from that adaptec card to an LSI card? I bought a new server a few months ago. And if has a lsi card. Your other post you linked scares the crap out of me in trying to move my hard drives over. But today my adaptec just died (as far as I can tell.) so I'm trying to find a new one. But I'd rather just hook my drives up to the new server. It's faster and holds more. -Dev
-
Awesome. I'll update tomorrow. Thank you.
-
i didn't see it in the release notes. but does this resolve the adaptec 7000 series card issues that .6 had. i had to roll back to .4 to fix it,. it was an issue with the then current version of the kernel i guess. but if it's not fixed then I guess i'm stuck on .4 still.
-
just saw this all over my logs. any idea how to fix it? Mar 2 15:59:52 MediaXen kernel: clocksource: timekeeping watchdog on CPU12: hpet wd-wd read-back delay of 108603ns Mar 2 15:59:52 MediaXen kernel: clocksource: wd-tsc-wd read-back delay of 102736ns, clock-skew test skipped! Mar 2 16:47:46 MediaXen flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Mar 2 16:59:55 MediaXen kernel: clocksource: timekeeping watchdog on CPU18: hpet wd-wd read-back delay of 66279ns Mar 2 16:59:55 MediaXen kernel: clocksource: wd-tsc-wd read-back delay of 104761ns, clock-skew test skipped! Mar 2 17:05:44 MediaXen kernel: clocksource: timekeeping watchdog on CPU21: hpet wd-wd read-back delay of 62577ns Mar 2 17:05:44 MediaXen kernel: clocksource: wd-tsc-wd read-back delay of 102806ns, clock-skew test skipped! Mar 2 17:15:01 MediaXen kernel: clocksource: timekeeping watchdog on CPU6: hpet wd-wd read-back delay of 61530ns Mar 2 17:15:01 MediaXen kernel: clocksource: wd-tsc-wd read-back delay of 179911ns, clock-skew test skipped! Mar 2 17:24:10 MediaXen kernel: clocksource: timekeeping watchdog on CPU1: hpet wd-wd read-back delay of 56850ns Mar 2 17:24:10 MediaXen kernel: clocksource: wd-tsc-wd read-back delay of 178514ns, clock-skew test skipped! Mar 2 17:52:08 MediaXen kernel: clocksource: timekeeping watchdog on CPU20: hpet wd-wd read-back delay of 97707ns Mar 2 17:52:08 MediaXen kernel: clocksource: wd-tsc-wd read-back delay of 117263ns, clock-skew test skipped! Mar 2 17:59:45 MediaXen monitor: Stop running nchan processes Mar 2 19:02:57 MediaXen kernel: clocksource: timekeeping watchdog on CPU18: hpet wd-wd read-back delay of 106927ns Mar 2 19:02:57 MediaXen kernel: clocksource: wd-tsc-wd read-back delay of 106228ns, clock-skew test skipped!
-
2 issues... 1. Starting with my backup last week I started getting errors for directories it says aren't there. Event: Appdata Backup Subject: [AppdataBackup] Error! Description: Please check the backup log! Importance: alert '/mnt/disks/SSD/appdata/apache-php/logs' does NOT exist! Please check your mappings! Skipping it for now. --- '/mnt/disks/SSD/www' does NOT exist! Please check your mappings! Skipping it for now. --- '/dev/shfs' does NOT exist! Please check your mappings! Skipping it for now. --- '/mnt/disks/Docker_SSD/plex-utills/logs' does NOT exist! Please check your mappings! Skipping it for now. *Side note I've never had a docker_ssd mapping or drive* --- '/tmp/xteve' does NOT exist! Please check your mappings! Skipping it for now. ---- 2. Last week it took 4 and a half hours. Which is typical.. But that one last night took over 8 hours. Nothing has changed on my server in the last week. Event: Appdata Backup Subject: Appdata Backup Description: Backup done [4h, 29m]! Importance: normal The backup was successful and took 4h, 29m! --- Event: Appdata Backup Subject: Appdata Backup Description: Backup done [8h, 5m]! Importance: normal The backup was successful and took 8h, 5m!

