




sunbear
Members
-
Joined
-
Last visited
Everything posted by sunbear
-
Can anyone tell me what the heck all these errors are? To me it looks like mover is attempting to move files from the same relative directory as the plugin (./plugins/user.scripts/./..., etc.) which seems crazy to me. It's attempting these move on what looks like every plugin I have in my /flash/config/plugins/ folder. WTF is going on? 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./js/visibility.js" "./plugins/user.scripts.enhanced/./js/visibility.js" "./plugins/user.scripts.enhanced/./js/visibility.js" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/categories_load.php" "./plugins/user.scripts.enhanced/./php/categories_load.php" "./plugins/user.scripts.enhanced/./php/categories_load.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/categories_load.php" "./plugins/user.scripts.enhanced/./php/categories_load.php" "./plugins/user.scripts.enhanced/./php/categories_load.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/categories_load.php" "./plugins/user.scripts.enhanced/./php/categories_load.php" "./plugins/user.scripts.enhanced/./php/categories_load.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/categories_save.php" "./plugins/user.scripts.enhanced/./php/categories_save.php" "./plugins/user.scripts.enhanced/./php/categories_save.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/categories_save.php" "./plugins/user.scripts.enhanced/./php/categories_save.php" "./plugins/user.scripts.enhanced/./php/categories_save.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/categories_save.php" "./plugins/user.scripts.enhanced/./php/categories_save.php" "./plugins/user.scripts.enhanced/./php/categories_save.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/config_loader.php" "./plugins/user.scripts.enhanced/./php/config_loader.php" "./plugins/user.scripts.enhanced/./php/config_loader.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/config_loader.php" "./plugins/user.scripts.enhanced/./php/config_loader.php" "./plugins/user.scripts.enhanced/./php/config_loader.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/config_loader.php" "./plugins/user.scripts.enhanced/./php/config_loader.php" "./plugins/user.scripts.enhanced/./php/config_loader.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/config_reset.php" "./plugins/user.scripts.enhanced/./php/config_reset.php" "./plugins/user.scripts.enhanced/./php/config_reset.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/config_reset.php" "./plugins/user.scripts.enhanced/./php/config_reset.php" "./plugins/user.scripts.enhanced/./php/config_reset.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/config_reset.php" "./plugins/user.scripts.enhanced/./php/config_reset.php" "./plugins/user.scripts.enhanced/./php/config_reset.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/delete_description_files_without_description.php" "./plugins/user.scripts.enhanced/./php/delete_description_files_without_description.php" "./plugins/user.scripts.enhanced/./php/delete_description_files_without_description.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/delete_description_files_without_description.php" "./plugins/user.scripts.enhanced/./php/delete_description_files_without_description.php" "./plugins/user.scripts.enhanced/./php/delete_description_files_without_description.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/delete_description_files_without_description.php" "./plugins/user.scripts.enhanced/./php/delete_description_files_without_description.php" "./plugins/user.scripts.enhanced/./php/delete_description_files_without_description.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/export.php" "./plugins/user.scripts.enhanced/./php/export.php" "./plugins/user.scripts.enhanced/./php/export.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/export.php" "./plugins/user.scripts.enhanced/./php/export.php" "./plugins/user.scripts.enhanced/./php/export.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/export.php" "./plugins/user.scripts.enhanced/./php/export.php" "./plugins/user.scripts.enhanced/./php/export.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/get_duplicate_scriptnames.php" "./plugins/user.scripts.enhanced/./php/get_duplicate_scriptnames.php" "./plugins/user.scripts.enhanced/./php/get_duplicate_scriptnames.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/get_duplicate_scriptnames.php" "./plugins/user.scripts.enhanced/./php/get_duplicate_scriptnames.php" "./plugins/user.scripts.enhanced/./php/get_duplicate_scriptnames.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/get_duplicate_scriptnames.php" "./plugins/user.scripts.enhanced/./php/get_duplicate_scriptnames.php" "./plugins/user.scripts.enhanced/./php/get_duplicate_scriptnames.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/get_not_matching_scriptnames.php" "./plugins/user.scripts.enhanced/./php/get_not_matching_scriptnames.php" "./plugins/user.scripts.enhanced/./php/get_not_matching_scriptnames.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/get_not_matching_scriptnames.php" "./plugins/user.scripts.enhanced/./php/get_not_matching_scriptnames.php" "./plugins/user.scripts.enhanced/./php/get_not_matching_scriptnames.php" to prevent breaking hardlinks 2025-09-09 21:06:09 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/get_not_matching_scriptnames.php" "./plugins/user.scripts.enhanced/./php/get_not_matching_scriptnames.php" "./plugins/user.scripts.enhanced/./php/get_not_matching_scriptnames.php" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/settings_page.php" "./plugins/user.scripts.enhanced/./php/settings_page.php" "./plugins/user.scripts.enhanced/./php/settings_page.php" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/settings_page.php" "./plugins/user.scripts.enhanced/./php/settings_page.php" "./plugins/user.scripts.enhanced/./php/settings_page.php" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/settings_page.php" "./plugins/user.scripts.enhanced/./php/settings_page.php" "./plugins/user.scripts.enhanced/./php/settings_page.php" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/tmp_delete.php" "./plugins/user.scripts.enhanced/./php/tmp_delete.php" "./plugins/user.scripts.enhanced/./php/tmp_delete.php" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/tmp_delete.php" "./plugins/user.scripts.enhanced/./php/tmp_delete.php" "./plugins/user.scripts.enhanced/./php/tmp_delete.php" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./php/tmp_delete.php" "./plugins/user.scripts.enhanced/./php/tmp_delete.php" "./plugins/user.scripts.enhanced/./php/tmp_delete.php" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./styles/page_settings.css" "./plugins/user.scripts.enhanced/./styles/page_settings.css" "./plugins/user.scripts.enhanced/./styles/page_settings.css" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./styles/page_settings.css" "./plugins/user.scripts.enhanced/./styles/page_settings.css" "./plugins/user.scripts.enhanced/./styles/page_settings.css" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./styles/page_settings.css" "./plugins/user.scripts.enhanced/./styles/page_settings.css" "./plugins/user.scripts.enhanced/./styles/page_settings.css" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./styles/page_userscripts.css" "./plugins/user.scripts.enhanced/./styles/page_userscripts.css" "./plugins/user.scripts.enhanced/./styles/page_userscripts.css" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./styles/page_userscripts.css" "./plugins/user.scripts.enhanced/./styles/page_userscripts.css" "./plugins/user.scripts.enhanced/./styles/page_userscripts.css" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/user.scripts.enhanced/./styles/page_userscripts.css" "./plugins/user.scripts.enhanced/./styles/page_userscripts.css" "./plugins/user.scripts.enhanced/./styles/page_userscripts.css" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./99_persistent_usb_manager.rules" "./plugins/usb_manager/./99_persistent_usb_manager.rules" "./plugins/usb_manager/./99_persistent_usb_manager.rules" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./99_persistent_usb_manager.rules" "./plugins/usb_manager/./99_persistent_usb_manager.rules" "./plugins/usb_manager/./99_persistent_usb_manager.rules" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./99_persistent_usb_manager.rules" "./plugins/usb_manager/./99_persistent_usb_manager.rules" "./plugins/usb_manager/./99_persistent_usb_manager.rules" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./99_persistent_usb_manager6.10.rules" "./plugins/usb_manager/./99_persistent_usb_manager6.10.rules" "./plugins/usb_manager/./99_persistent_usb_manager6.10.rules" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./99_persistent_usb_manager6.10.rules" "./plugins/usb_manager/./99_persistent_usb_manager6.10.rules" "./plugins/usb_manager/./99_persistent_usb_manager6.10.rules" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./99_persistent_usb_manager6.10.rules" "./plugins/usb_manager/./99_persistent_usb_manager6.10.rules" "./plugins/usb_manager/./99_persistent_usb_manager6.10.rules" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./99_usb_manager_syslog.conf" "./plugins/usb_manager/./99_usb_manager_syslog.conf" "./plugins/usb_manager/./99_usb_manager_syslog.conf" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./99_usb_manager_syslog.conf" "./plugins/usb_manager/./99_usb_manager_syslog.conf" "./plugins/usb_manager/./99_usb_manager_syslog.conf" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./99_usb_manager_syslog.conf" "./plugins/usb_manager/./99_usb_manager_syslog.conf" "./plugins/usb_manager/./99_usb_manager_syslog.conf" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./LICENSE.md" "./plugins/usb_manager/./LICENSE.md" "./plugins/usb_manager/./LICENSE.md" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./LICENSE.md" "./plugins/usb_manager/./LICENSE.md" "./plugins/usb_manager/./LICENSE.md" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./LICENSE.md" "./plugins/usb_manager/./LICENSE.md" "./plugins/usb_manager/./LICENSE.md" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./README.md" "./plugins/usb_manager/./README.md" "./plugins/usb_manager/./README.md" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./README.md" "./plugins/usb_manager/./README.md" "./plugins/usb_manager/./README.md" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./README.md" "./plugins/usb_manager/./README.md" "./plugins/usb_manager/./README.md" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./USBDevices.php" "./plugins/usb_manager/./USBDevices.php" "./plugins/usb_manager/./USBDevices.php" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./USBDevices.php" "./plugins/usb_manager/./USBDevices.php" "./plugins/usb_manager/./USBDevices.php" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./USBDevices.php" "./plugins/usb_manager/./USBDevices.php" "./plugins/usb_manager/./USBDevices.php" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./USBEditSettings.page.save" "./plugins/usb_manager/./USBEditSettings.page.save" "./plugins/usb_manager/./USBEditSettings.page.save" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./USBEditSettings.page.save" "./plugins/usb_manager/./USBEditSettings.page.save" "./plugins/usb_manager/./USBEditSettings.page.save" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./USBEditSettings.page.save" "./plugins/usb_manager/./USBEditSettings.page.save" "./plugins/usb_manager/./USBEditSettings.page.save" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./assets/arrive.min.js" "./plugins/usb_manager/./assets/arrive.min.js" "./plugins/usb_manager/./assets/arrive.min.js" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./assets/arrive.min.js" "./plugins/usb_manager/./assets/arrive.min.js" "./plugins/usb_manager/./assets/arrive.min.js" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./assets/arrive.min.js" "./plugins/usb_manager/./assets/arrive.min.js" "./plugins/usb_manager/./assets/arrive.min.js" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./assets/lib_usb_manager.php" "./plugins/usb_manager/./assets/lib_usb_manager.php" "./plugins/usb_manager/./assets/lib_usb_manager.php" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./assets/lib_usb_manager.php" "./plugins/usb_manager/./assets/lib_usb_manager.php" "./plugins/usb_manager/./assets/lib_usb_manager.php" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./assets/lib_usb_manager.php" "./plugins/usb_manager/./assets/lib_usb_manager.php" "./plugins/usb_manager/./assets/lib_usb_manager.php" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./assets/sweetalert2.css" "./plugins/usb_manager/./assets/sweetalert2.css" "./plugins/usb_manager/./assets/sweetalert2.css" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./assets/sweetalert2.css" "./plugins/usb_manager/./assets/sweetalert2.css" "./plugins/usb_manager/./assets/sweetalert2.css" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./assets/sweetalert2.css" "./plugins/usb_manager/./assets/sweetalert2.css" "./plugins/usb_manager/./assets/sweetalert2.css" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./assets/sweetalert2.js" "./plugins/usb_manager/./assets/sweetalert2.js" "./plugins/usb_manager/./assets/sweetalert2.js" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./assets/sweetalert2.js" "./plugins/usb_manager/./assets/sweetalert2.js" "./plugins/usb_manager/./assets/sweetalert2.js" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./assets/sweetalert2.js" "./plugins/usb_manager/./assets/sweetalert2.js" "./plugins/usb_manager/./assets/sweetalert2.js" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./default.cfg" "./plugins/usb_manager/./default.cfg" "./plugins/usb_manager/./default.cfg" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./default.cfg" "./plugins/usb_manager/./default.cfg" "./plugins/usb_manager/./default.cfg" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./default.cfg" "./plugins/usb_manager/./default.cfg" "./plugins/usb_manager/./default.cfg" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./event/libvirt_started" "./plugins/usb_manager/./event/libvirt_started" "./plugins/usb_manager/./event/libvirt_started" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./event/libvirt_started" "./plugins/usb_manager/./event/libvirt_started" "./plugins/usb_manager/./event/libvirt_started" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./event/libvirt_started" "./plugins/usb_manager/./event/libvirt_started" "./plugins/usb_manager/./event/libvirt_started" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./event/stopping_libvirt" "./plugins/usb_manager/./event/stopping_libvirt" "./plugins/usb_manager/./event/stopping_libvirt" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./event/stopping_libvirt" "./plugins/usb_manager/./event/stopping_libvirt" "./plugins/usb_manager/./event/stopping_libvirt" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./event/stopping_libvirt" "./plugins/usb_manager/./event/stopping_libvirt" "./plugins/usb_manager/./event/stopping_libvirt" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./event/stopping_svcs" "./plugins/usb_manager/./event/stopping_svcs" "./plugins/usb_manager/./event/stopping_svcs" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./event/stopping_svcs" "./plugins/usb_manager/./event/stopping_svcs" "./plugins/usb_manager/./event/stopping_svcs" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./event/stopping_svcs" "./plugins/usb_manager/./event/stopping_svcs" "./plugins/usb_manager/./event/stopping_svcs" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./icons/historical.png" "./plugins/usb_manager/./icons/historical.png" "./plugins/usb_manager/./icons/historical.png" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./icons/historical.png" "./plugins/usb_manager/./icons/historical.png" "./plugins/usb_manager/./icons/historical.png" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./icons/historical.png" "./plugins/usb_manager/./icons/historical.png" "./plugins/usb_manager/./icons/historical.png" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./icons/nfs.png" "./plugins/usb_manager/./icons/nfs.png" "./plugins/usb_manager/./icons/nfs.png" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./icons/nfs.png" "./plugins/usb_manager/./icons/nfs.png" "./plugins/usb_manager/./icons/nfs.png" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./icons/nfs.png" "./plugins/usb_manager/./icons/nfs.png" "./plugins/usb_manager/./icons/nfs.png" to prevent breaking hardlinks 2025-09-09 21:06:10 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./icons/usb_manager.png" "./plugins/usb_manager/./icons/usb_manager.png" "./plugins/usb_manager/./icons/usb_manager.png" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./icons/usb_manager.png" "./plugins/usb_manager/./icons/usb_manager.png" "./plugins/usb_manager/./icons/usb_manager.png" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./icons/usb_manager.png" "./plugins/usb_manager/./icons/usb_manager.png" "./plugins/usb_manager/./icons/usb_manager.png" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./icons/usbip.png" "./plugins/usb_manager/./icons/usbip.png" "./plugins/usb_manager/./icons/usbip.png" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./icons/usbip.png" "./plugins/usb_manager/./icons/usbip.png" "./plugins/usb_manager/./icons/usbip.png" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./icons/usbip.png" "./plugins/usb_manager/./icons/usbip.png" "./plugins/usb_manager/./icons/usbip.png" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./images/isb_manager.png" "./plugins/usb_manager/./images/isb_manager.png" "./plugins/usb_manager/./images/isb_manager.png" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./images/isb_manager.png" "./plugins/usb_manager/./images/isb_manager.png" "./plugins/usb_manager/./images/isb_manager.png" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./images/isb_manager.png" "./plugins/usb_manager/./images/isb_manager.png" "./plugins/usb_manager/./images/isb_manager.png" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./include/Legacy.php" "./plugins/usb_manager/./include/Legacy.php" "./plugins/usb_manager/./include/Legacy.php" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./include/Legacy.php" "./plugins/usb_manager/./include/Legacy.php" "./plugins/usb_manager/./include/Legacy.php" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./include/Legacy.php" "./plugins/usb_manager/./include/Legacy.php" "./plugins/usb_manager/./include/Legacy.php" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./include/rc.usb_manager" "./plugins/usb_manager/./include/rc.usb_manager" "./plugins/usb_manager/./include/rc.usb_manager" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./include/rc.usb_manager" "./plugins/usb_manager/./include/rc.usb_manager" "./plugins/usb_manager/./include/rc.usb_manager" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./include/rc.usb_manager" "./plugins/usb_manager/./include/rc.usb_manager" "./plugins/usb_manager/./include/rc.usb_manager" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./makepkg.sh" "./plugins/usb_manager/./makepkg.sh" "./plugins/usb_manager/./makepkg.sh" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./makepkg.sh" "./plugins/usb_manager/./makepkg.sh" "./plugins/usb_manager/./makepkg.sh" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./makepkg.sh" "./plugins/usb_manager/./makepkg.sh" "./plugins/usb_manager/./makepkg.sh" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./scripts/copy_config.sh" "./plugins/usb_manager/./scripts/copy_config.sh" "./plugins/usb_manager/./scripts/copy_config.sh" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./scripts/copy_config.sh" "./plugins/usb_manager/./scripts/copy_config.sh" "./plugins/usb_manager/./scripts/copy_config.sh" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./scripts/copy_config.sh" "./plugins/usb_manager/./scripts/copy_config.sh" "./plugins/usb_manager/./scripts/copy_config.sh" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./scripts/install.sh" "./plugins/usb_manager/./scripts/install.sh" "./plugins/usb_manager/./scripts/install.sh" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./scripts/install.sh" "./plugins/usb_manager/./scripts/install.sh" "./plugins/usb_manager/./scripts/install.sh" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./scripts/install.sh" "./plugins/usb_manager/./scripts/install.sh" "./plugins/usb_manager/./scripts/install.sh" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./scripts/port_ping.sh" "./plugins/usb_manager/./scripts/port_ping.sh" "./plugins/usb_manager/./scripts/port_ping.sh" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./scripts/port_ping.sh" "./plugins/usb_manager/./scripts/port_ping.sh" "./plugins/usb_manager/./scripts/port_ping.sh" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./scripts/port_ping.sh" "./plugins/usb_manager/./scripts/port_ping.sh" "./plugins/usb_manager/./scripts/port_ping.sh" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./scripts/syslog_process.sh" "./plugins/usb_manager/./scripts/syslog_process.sh" "./plugins/usb_manager/./scripts/syslog_process.sh" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./scripts/syslog_process.sh" "./plugins/usb_manager/./scripts/syslog_process.sh" "./plugins/usb_manager/./scripts/syslog_process.sh" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./scripts/syslog_process.sh" "./plugins/usb_manager/./scripts/syslog_process.sh" "./plugins/usb_manager/./scripts/syslog_process.sh" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./scripts/uninstall.sh" "./plugins/usb_manager/./scripts/uninstall.sh" "./plugins/usb_manager/./scripts/uninstall.sh" to prevent breaking hardlinks 2025-09-09 21:06:11 serv-x570 move: Expected 1 files, got 3. Not moving "./plugins/usb_manager/./scripts/uninstall.sh" "./plugins/usb_manager/./scripts/uninstall.sh" "./plugins/usb_manager/./scripts/uninstall.sh" to prevent breaking hardlinks
-
Hello all, After updating to the new (non-squid) version of tuned mover, I am no longer able to call the "/usr/local/emhttp/plugins/ca.mover.tuning/age_mover" from a custom script as I used to, since it seems to ignore all passed arguments and only pull variables from the "/boot/config/plugins/ca.mover.tuning/ca.mover.tuning.cfg" that is set from the SETTINGS page. Is there any way I can run this new update script with custom variables passed as arguments like I was able to do with Squid's version? Thanks
-
That doesn't change the fact that it's the default behavior, as far as I'm aware. Unless you go into network adapters and manually bridge them yourself. My question still stands, though. What issues does this cause in Unraid as implied by the error message? If I am manually splitting the traffic by having SMB only access one and docker network on the other, what is the issue? Are you implying that one NIC will not broadcast anytime the other NIC is and vice versa, as windows implies?
-
I got the following error on my ECC protected server. I'm not super worried about the error. It happened right as I was shutting down docker. So I think I might have something corrupted in my docker image. The real issue I'm asking about is the following error from the error log after the FIX COMMON PROBLEMS plugin tried to run mcelog. 2024-06-04 15:46:58 hostname root: Fix Common Problems: Error: Machine Check Events detected on your server 2024-06-04 15:46:58 hostname root: mcelog: ERROR: AMD Processor family 23: mcelog does not support this processor. Please use the edac_mce_amd module instead. 2024-06-04 15:46:58 hostname root: CPU is unsupported 2024-06-04 15:47:00 hostname root: Fix Common Problems: Error: Multiple NICs on the same IPv4 network "CPU is unsopprted" is what caught my attention. Anyone know what this is? Is this something that needs to be updated on Unraid's end? I use an AMD Ryzen 3900X. Here's the original Hardware Error if it's of any use: 2024-06-04 15:43:07 hostname kernel: mce: [Hardware Error]: Machine check events logged 2024-06-04 15:43:07 hostname kernel: [Hardware Error]: Corrected error, no action required. 2024-06-04 15:43:07 hostname kernel: [Hardware Error]: CPU:1 (17:71:0) MC7_STATUS[-|CE|MiscV|AddrV|-|-|SyndV|CECC|-|-|-]: 0x9c2040000002010b 2024-06-04 15:43:07 hostname kernel: [Hardware Error]: Error Addr: 0x0000000000082900 2024-06-04 15:43:07 hostname kernel: [Hardware Error]: IPID: 0x000700b020b50000, Syndrome: 0x000000292a1f1900 2024-06-04 15:43:07 hostname kernel: [Hardware Error]: L3 Cache Ext. Error Code: 2, L3M Tag ECC Error. 2024-06-04 15:43:07 hostname kernel: [Hardware Error]: cache level: L3/GEN, tx: GEN, mem-tx: GEN

-
This is the default behavior in Windows if you have more than one network device, e.g. a LAN port + WIFI. Each device gets it's own IP on the local network. My server board has FOUR different NICs and I would like to have them in two bonded groups so I can separate my SMB and local access from by docker network and port forwarded IP address. Yet Unraid forces me to ignore this bright red critical error warning that is typically reserved for things like disk errors: What is this about? Is there actually anything wrong with this setup? Is it going to cause me issues as the warning claims? This is my network config:

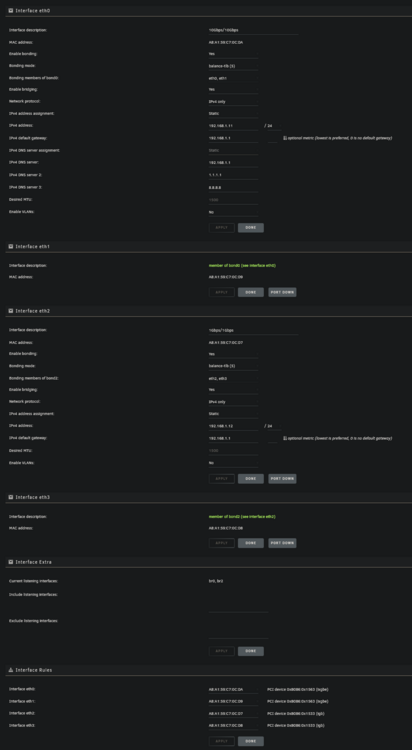
-
I will definitely do this when I have the time. Unfortunately I can't shutdown everything (specifically work-related nextcloud instance) at the moment to try to investigate. After googling these errors for the 100th time I did finally find some other people having similar issues on a TrueNAS forum. Everyone seems to think something wrong with avahi-daemon but no solutions in sight. https://www.truenas.com/community/threads/avahi-daemon-errors.94599/ There was one other unraid forum post where I saw a few people having the same issue but the thread went cold as well. Would really love to get this error out of my logs. I'm having some database performance issues that I've been trying to take care of for a while and can never quite be confident if this has anything to do with them. I did go and switch my network bonding mode back to Mode 5 (balance-tlb) since that seemed to have no effect. I know it supposedly is not supported. But it seems to work fine and allows me to use samba RSS/multi-channel
-
I spoke too soon. The errors are back. Now there is a new error. Any ideas? I've attached my diagnostics again. 2024-05-30 03:32:00 hostname winbindd[11909]: [2024/05/30 03:32:00.825353, 0] ../../source3/winbindd/winbindd_samr.c:111(open_internal_lsa_conn) 2024-05-30 03:32:00 hostname winbindd[11909]: open_internal_lsa_conn: Could not connect to lsarpc pipe: NT_STATUS_IO_TIMEOUT 2024-05-30 04:00:38 hostname emhttpd: spinning down /dev/sdm 2024-05-30 04:13:21 hostname winbindd[11909]: [2024/05/30 04:13:21.381296, 0] ../../source3/winbindd/winbindd_samr.c:71(open_internal_samr_conn) 2024-05-30 04:13:21 hostname winbindd[11909]: open_internal_samr_conn: Could not connect to samr pipe: NT_STATUS_IO_TIMEOUT 2024-05-30 04:13:22 hostname winbindd[11907]: [2024/05/30 04:13:22.370149, 0] ../../source3/winbindd/winbindd.c:821(winbind_client_processed) 2024-05-30 04:13:22 hostname winbindd[11907]: winbind_client_processed: request took 61.731066 seconds 2024-05-30 04:13:22 hostname winbindd[11907]: [struct process_request_state] ../../source3/winbindd/winbindd.c:437 [2024/05/30 04:12:20.489964] ../../source3/winbindd/winbindd.c:618 [2024/05/30 04:13:22.221030] [61.731066] -> TEVENT_REQ_DONE (2 0)) 2024-05-30 04:13:22 hostname winbindd[11907]: [struct winbindd_getgroups_state] ../../source3/winbindd/winbindd_getgroups.c:53 [2024/05/30 04:12:20.489973] ../../source3/winbindd/winbindd_getgroups.c:112 [2024/05/30 04:13:22.192168] [61.702195] -> TEVENT_REQ_USER_ERROR (3 10483072397370982581)) 2024-05-30 04:13:22 hostname winbindd[11907]: [struct wb_lookupname_state] ../../source3/winbindd/wb_lookupname.c:47 [2024/05/30 04:12:21.115646] ../../source3/winbindd/wb_lookupname.c:99 [2024/05/30 04:13:22.157437] [61.041791] -> TEVENT_REQ_USER_ERROR (3 10483072397370982581)) 2024-05-30 04:13:22 hostname winbindd[11907]: [struct dcerpc_wbint_LookupName_state] librpc/gen_ndr/ndr_winbind_c.c:795 [2024/05/30 04:12:23.958279] librpc/gen_ndr/ndr_winbind_c.c:862 [2024/05/30 04:13:22.157427] [58.199148] -> TEVENT_REQ_DONE (2 0)) 2024-05-30 04:13:22 hostname winbindd[11907]: [struct dcerpc_wbint_LookupName_r_state] librpc/gen_ndr/ndr_winbind_c.c:707 [2024/05/30 04:12:24.072746] librpc/gen_ndr/ndr_winbind_c.c:742 [2024/05/30 04:13:22.157425] [58.084679] -> TEVENT_REQ_DONE (2 0)) 2024-05-30 04:13:22 hostname winbindd[11907]: [struct dcerpc_binding_handle_call_state] ../../librpc/rpc/binding_handle.c:370 [2024/05/30 04:12:24.194597] ../../librpc/rpc/binding_handle.c:520 [2024/05/30 04:13:22.133787] [57.939190] -> TEVENT_REQ_DONE (2 0)) 2024-05-30 04:13:22 hostname winbindd[11907]: [struct dcerpc_binding_handle_raw_call_state] ../../librpc/rpc/binding_handle.c:148 [2024/05/30 04:12:24.439673] ../../librpc/rpc/binding_handle.c:203 [2024/05/30 04:13:22.133753] [57.694080] -> TEVENT_REQ_DONE (2 0)) 2024-05-30 04:13:22 hostname winbindd[11907]: [struct wbint_bh_raw_call_state] ../../source3/winbindd/winbindd_dual_ndr.c:93 [2024/05/30 04:12:24.489950] ../../source3/winbindd/winbindd_dual_ndr.c:209 [2024/05/30 04:13:22.092667] [57.602717] -> TEVENT_REQ_DONE (2 0)) 2024-05-30 04:13:22 hostname winbindd[11907]: [struct wb_domain_request_state] ../../source3/winbindd/winbindd_dual.c:506 [2024/05/30 04:12:24.682640] ../../source3/winbindd/winbindd_dual.c:744 [2024/05/30 04:13:22.056905] [57.374265] -> TEVENT_REQ_DONE (2 0)) 2024-05-30 04:13:22 hostname winbindd[11907]: [struct wb_child_request_state] ../../source3/winbindd/winbindd_dual.c:202 [2024/05/30 04:12:24.769386] ../../source3/winbindd/winbindd_dual.c:305 [2024/05/30 04:13:22.056904] [57.287518] -> TEVENT_REQ_DONE (2 0)) 2024-05-30 04:13:22 hostname winbindd[11907]: [struct tevent_queue_wait_state] ../../tevent_queue.c:351 [2024/05/30 04:12:24.782706] ../../tevent_queue.c:371 [2024/05/30 04:12:24.782708] [0.000002] -> TEVENT_REQ_DONE (2 0)) 2024-05-30 04:13:22 hostname winbindd[11907]: [struct wb_simple_trans_state] ../../nsswitch/wb_reqtrans.c:375 [2024/05/30 04:12:24.804856] ../../nsswitch/wb_reqtrans.c:432 [2024/05/30 04:13:22.056892] [57.252036] -> TEVENT_REQ_DONE (2 0)) 2024-05-30 04:13:22 hostname winbindd[11907]: [struct req_write_state] ../../nsswitch/wb_reqtrans.c:158 [2024/05/30 04:12:24.804857] ../../nsswitch/wb_reqtrans.c:194 [2024/05/30 04:12:25.296970] [0.492113] -> TEVENT_REQ_DONE (2 0)) 2024-05-30 04:13:22 hostname winbindd[11907]: [struct writev_state] ../../lib/async_req/async_sock.c:267 [2024/05/30 04:12:24.804861] ../../lib/async_req/async_sock.c:373 [2024/05/30 04:12:25.296968] [0.492107] -> TEVENT_REQ_DONE (2 0)) 2024-05-30 04:13:22 hostname winbindd[11907]: [struct resp_read_state] ../../nsswitch/wb_reqtrans.c:222 [2024/05/30 04:12:25.296972] ../../nsswitch/wb_reqtrans.c:275 [2024/05/30 04:13:22.056892] [56.759920] -> TEVENT_REQ_DONE (2 0)) 2024-05-30 04:13:22 hostname winbindd[11907]: [struct read_packet_state] ../../lib/async_req/async_sock.c:480 [2024/05/30 04:12:25.296974] ../../lib/async_req/async_sock.c:568 [2024/05/30 04:13:22.056884] [56.759910] -> TEVENT_REQ_DONE (2 0)) 2024-05-30 04:13:22 hostname winbindd[11907]: [struct resp_write_state] ../../nsswitch/wb_reqtrans.c:307 [2024/05/30 04:13:22.192178] ../../nsswitch/wb_reqtrans.c:344 [2024/05/30 04:13:22.221029] [0.028851] -> TEVENT_REQ_DONE (2 0)) 2024-05-30 04:13:22 hostname winbindd[11907]: [struct writev_state] ../../lib/async_req/async_sock.c:267 [2024/05/30 04:13:22.192179] ../../lib/async_req/async_sock.c:373 [2024/05/30 04:13:22.192192] [0.000013] -> TEVENT_REQ_DONE (2 0)) serv-x570-diagnostics-20240530-0909.zip
-
I think that did it. Thanks!
-
I think you may be on to something. Giving it a try now. I originally removed that just so I didn't have to type the extra characters in the address bar (and hostname just looks better without the .local, silly I know). Didn't realize it may cause issues.
-
I switch network config to active-backup and I'm still getting the same errors. 2024-05-16 03:08:47 hostname avahi-daemon[9274]: Record [_ssh._tcp.local#011IN#011PTR hostname._ssh._tcp.local ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-16 03:08:47 hostname avahi-daemon[9274]: Record [hostname._ssh._tcp.local#011IN#011TXT ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-16 03:08:47 hostname avahi-daemon[9274]: Record [hostname._ssh._tcp.local#011IN#011SRV 0 0 22 hostname.local ; ttl=120] not fitting in legacy unicast packet, dropping. 2024-05-16 03:38:47 hostname avahi-daemon[9274]: Record [_ssh._tcp.local#011IN#011PTR hostname._ssh._tcp.local ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-16 03:38:47 hostname avahi-daemon[9274]: Record [hostname._ssh._tcp.local#011IN#011TXT ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-16 03:38:47 hostname avahi-daemon[9274]: Record [hostname._ssh._tcp.local#011IN#011SRV 0 0 22 hostname.local ; ttl=120] not fitting in legacy unicast packet, dropping. 2024-05-16 04:03:03 hostname emhttpd: read SMART /dev/sdh 2024-05-16 04:08:47 hostname avahi-daemon[9274]: Record [_ssh._tcp.local#011IN#011PTR hostname._ssh._tcp.local ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-16 04:08:47 hostname avahi-daemon[9274]: Record [hostname._ssh._tcp.local#011IN#011TXT ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-16 04:08:47 hostname avahi-daemon[9274]: Record [hostname._ssh._tcp.local#011IN#011SRV 0 0 22 hostname.local ; ttl=120] not fitting in legacy unicast packet, dropping. 2024-05-16 04:12:56 hostname emhttpd: read SMART /dev/sdm 2024-05-16 04:38:47 hostname avahi-daemon[9274]: Record [_ssh._tcp.local#011IN#011PTR hostname._ssh._tcp.local ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-16 04:38:47 hostname avahi-daemon[9274]: Record [hostname._ssh._tcp.local#011IN#011TXT ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-16 04:38:47 hostname avahi-daemon[9274]: Record [hostname._ssh._tcp.local#011IN#011SRV 0 0 22 hostname.local ; ttl=120] not fitting in legacy unicast packet, dropping. 2024-05-16 04:53:05 hostname emhttpd: spinning down /dev/sdm 2024-05-16 04:53:09 hostname emhttpd: spinning down /dev/sdh 2024-05-16 05:03:01 hostname php-fpm[9925]: [WARNING] [pool www] child 16655 exited on signal 9 (SIGKILL) after 14.402451 seconds from start 2024-05-16 05:04:03 hostname php-fpm[9925]: [WARNING] [pool www] child 17275 exited on signal 9 (SIGKILL) after 74.725530 seconds from start 2024-05-16 05:08:47 hostname avahi-daemon[9274]: Record [_ssh._tcp.local#011IN#011PTR hostname._ssh._tcp.local ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-16 05:08:47 hostname avahi-daemon[9274]: Record [hostname._ssh._tcp.local#011IN#011TXT ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-16 05:08:47 hostname avahi-daemon[9274]: Record [hostname._ssh._tcp.local#011IN#011SRV 0 0 22 hostname.local ; ttl=120] not fitting in legacy unicast packet, dropping.
-
While someone knowledgeable is here, would you also happen to know how to get rid of the following message? sSMTP[1740]: 550 5.2.254 InvalidRecipientsException; Sender throttled due to continuous invalid recipients errors.; STOREDRV.Submission.Exception:InvalidRecipientsException; Failed to process message due to a permanent exception with message [BeginDiagnosticData]Recipient 'root' is not resolved. All recipients must be resolved before a message can be submitted. InvalidRecipientsException: Recipient 'root' is not resolved. All recipients must be resolved before a message can be submitted.[EndDiagnosticData] [Hostname=Hostname.namprd14.prod.outlook.com]
-
Thanks. I'll give this a try. Man, I'm just not going to be able to use my fancy 3 extra NIC's am I? Active Backup seems to be the only thing that works without errors and without a managed switch.
-
Can anyone give me any leads? What would it even mean for the avahi-daemon to be dropping legacy unicast packets for "not fitting". No clue what this is.
-
Unraid Version 6.12.10 2024-04-03 I get these errors all day every day. I don't seem to have any issues otherwise. Except for a laggy hanging webUI every once in a while. I've tried turning off ssh to no avail. Diagnostics attached. 2024-05-09 03:05:14 [hostname] avahi-daemon[17752]: Record [_ssh._tcp.local#011IN#011PTR [hostname]._ssh._tcp.local ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 03:05:14 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011TXT ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 03:05:14 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011SRV 0 0 22 [hostname].local ; ttl=120] not fitting in legacy unicast packet, dropping. 2024-05-09 03:07:21 [hostname] kernel: mdcmd (84): set md_write_method 1 2024-05-09 03:07:21 [hostname] kernel: 2024-05-09 03:34:55 [hostname] avahi-daemon[17752]: Record [_ssh._tcp.local#011IN#011PTR [hostname]._ssh._tcp.local ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 03:34:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011TXT ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 03:34:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011SRV 0 0 22 [hostname].local ; ttl=120] not fitting in legacy unicast packet, dropping. 2024-05-09 03:35:54 [hostname] emhttpd: spinning down /dev/sdh 2024-05-09 04:03:40 [hostname] winbindd[17714]: [2024/05/09 04:03:39.760536, 0] ../../source3/winbindd/winbindd_samr.c:111(open_internal_lsa_conn) 2024-05-09 04:03:40 [hostname] winbindd[17714]: open_internal_lsa_conn: Could not connect to lsarpc pipe: NT_STATUS_IO_TIMEOUT 2024-05-09 04:04:04 [hostname] winbindd[17711]: [2024/05/09 04:04:04.531496, 0] ../../source3/winbindd/winbindd.c:821(winbind_client_processed) 2024-05-09 04:04:04 [hostname] winbindd[17711]: winbind_client_processed: request took 61.469885 seconds 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct process_request_state] ../../source3/winbindd/winbindd.c:437 [2024/05/09 04:03:02.866594] ../../source3/winbindd/winbindd.c:618 [2024/05/09 04:04:04.336479] [61.469885] -> TEVENT_REQ_DONE (2 0)) 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct winbindd_getgroups_state] ../../source3/winbindd/winbindd_getgroups.c:53 [2024/05/09 04:03:02.866599] ../../source3/winbindd/winbindd_getgroups.c:112 [2024/05/09 04:04:03.974198] [61.107599] -> TEVENT_REQ_USER_ERROR (3 10483072397370982581)) 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct wb_lookupname_state] ../../source3/winbindd/wb_lookupname.c:47 [2024/05/09 04:03:03.209092] ../../source3/winbindd/wb_lookupname.c:99 [2024/05/09 04:04:03.974191] [60.765099] -> TEVENT_REQ_USER_ERROR (3 10483072397370982581)) 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct dcerpc_wbint_LookupName_state] librpc/gen_ndr/ndr_winbind_c.c:795 [2024/05/09 04:03:03.535294] librpc/gen_ndr/ndr_winbind_c.c:862 [2024/05/09 04:04:03.844672] [60.309378] -> TEVENT_REQ_DONE (2 0)) 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct dcerpc_wbint_LookupName_r_state] librpc/gen_ndr/ndr_winbind_c.c:707 [2024/05/09 04:03:03.535299] librpc/gen_ndr/ndr_winbind_c.c:742 [2024/05/09 04:04:03.844669] [60.309370] -> TEVENT_REQ_DONE (2 0)) 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct dcerpc_binding_handle_call_state] ../../librpc/rpc/binding_handle.c:370 [2024/05/09 04:03:03.620432] ../../librpc/rpc/binding_handle.c:520 [2024/05/09 04:04:03.822772] [60.202340] -> TEVENT_REQ_DONE (2 0)) 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct dcerpc_binding_handle_raw_call_state] ../../librpc/rpc/binding_handle.c:148 [2024/05/09 04:03:03.728022] ../../librpc/rpc/binding_handle.c:203 [2024/05/09 04:04:03.485933] [59.757911] -> TEVENT_REQ_DONE (2 0)) 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct wbint_bh_raw_call_state] ../../source3/winbindd/winbindd_dual_ndr.c:93 [2024/05/09 04:03:03.728024] ../../source3/winbindd/winbindd_dual_ndr.c:209 [2024/05/09 04:04:02.979118] [59.251094] -> TEVENT_REQ_DONE (2 0)) 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct wb_domain_request_state] ../../source3/winbindd/winbindd_dual.c:506 [2024/05/09 04:03:03.870951] ../../source3/winbindd/winbindd_dual.c:744 [2024/05/09 04:04:01.977377] [58.106426] -> TEVENT_REQ_DONE (2 0)) 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct wb_child_request_state] ../../source3/winbindd/winbindd_dual.c:202 [2024/05/09 04:03:41.441891] ../../source3/winbindd/winbindd_dual.c:305 [2024/05/09 04:04:01.977373] [20.535482] -> TEVENT_REQ_DONE (2 0)) 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct tevent_queue_wait_state] ../../tevent_queue.c:351 [2024/05/09 04:03:41.454067] ../../tevent_queue.c:371 [2024/05/09 04:03:41.454070] [0.000003] -> TEVENT_REQ_DONE (2 0)) 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct wb_simple_trans_state] ../../nsswitch/wb_reqtrans.c:375 [2024/05/09 04:03:41.454074] ../../nsswitch/wb_reqtrans.c:432 [2024/05/09 04:04:01.519530] [20.065456] -> TEVENT_REQ_DONE (2 0)) 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct req_write_state] ../../nsswitch/wb_reqtrans.c:158 [2024/05/09 04:03:41.454074] ../../nsswitch/wb_reqtrans.c:194 [2024/05/09 04:03:41.491912] [0.037838] -> TEVENT_REQ_DONE (2 0)) 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct writev_state] ../../lib/async_req/async_sock.c:267 [2024/05/09 04:03:41.454075] ../../lib/async_req/async_sock.c:373 [2024/05/09 04:03:41.491909] [0.037834] -> TEVENT_REQ_DONE (2 0)) 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct resp_read_state] ../../nsswitch/wb_reqtrans.c:222 [2024/05/09 04:03:41.491914] ../../nsswitch/wb_reqtrans.c:275 [2024/05/09 04:04:01.519528] [20.027614] -> TEVENT_REQ_DONE (2 0)) 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct read_packet_state] ../../lib/async_req/async_sock.c:480 [2024/05/09 04:03:41.491915] ../../lib/async_req/async_sock.c:568 [2024/05/09 04:04:01.139338] [19.647423] -> TEVENT_REQ_DONE (2 0)) 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct resp_write_state] ../../nsswitch/wb_reqtrans.c:307 [2024/05/09 04:04:04.054731] ../../nsswitch/wb_reqtrans.c:344 [2024/05/09 04:04:04.336478] [0.281747] -> TEVENT_REQ_DONE (2 0)) 2024-05-09 04:04:04 [hostname] winbindd[17711]: [struct writev_state] ../../lib/async_req/async_sock.c:267 [2024/05/09 04:04:04.054732] ../../lib/async_req/async_sock.c:373 [2024/05/09 04:04:04.136932] [0.082200] -> TEVENT_REQ_DONE (2 0)) 2024-05-09 04:05:05 [hostname] avahi-daemon[17752]: Record [_ssh._tcp.local#011IN#011PTR [hostname]._ssh._tcp.local ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 04:05:05 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011TXT ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 04:05:05 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011SRV 0 0 22 [hostname].local ; ttl=120] not fitting in legacy unicast packet, dropping. 2024-05-09 04:05:14 [hostname] winbindd[17714]: [2024/05/09 04:05:13.092684, 0] ../../source3/winbindd/winbindd_samr.c:71(open_internal_samr_conn) 2024-05-09 04:05:14 [hostname] winbindd[17714]: open_internal_samr_conn: Could not connect to samr pipe: NT_STATUS_IO_TIMEOUT 2024-05-09 04:09:54 [hostname] emhttpd: read SMART /dev/sdh 2024-05-09 04:16:48 [hostname] emhttpd: read SMART /dev/sdm 2024-05-09 04:34:55 [hostname] avahi-daemon[17752]: Record [_ssh._tcp.local#011IN#011PTR [hostname]._ssh._tcp.local ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 04:34:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011TXT ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 04:34:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011SRV 0 0 22 [hostname].local ; ttl=120] not fitting in legacy unicast packet, dropping. 2024-05-09 04:56:26 [hostname] emhttpd: spinning down /dev/sdm 2024-05-09 04:59:17 [hostname] emhttpd: spinning down /dev/sdh 2024-05-09 05:04:55 [hostname] avahi-daemon[17752]: Record [_ssh._tcp.local#011IN#011PTR [hostname]._ssh._tcp.local ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 05:04:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011TXT ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 05:04:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011SRV 0 0 22 [hostname].local ; ttl=120] not fitting in legacy unicast packet, dropping. 2024-05-09 05:25:18 [hostname] winbindd[17714]: [2024/05/09 05:25:18.601226, 0] ../../source3/winbindd/winbindd_samr.c:71(open_internal_samr_conn) 2024-05-09 05:25:18 [hostname] winbindd[17714]: open_internal_samr_conn: Could not connect to samr pipe: NT_STATUS_CONNECTION_DISCONNECTED 2024-05-09 05:34:55 [hostname] avahi-daemon[17752]: Record [_ssh._tcp.local#011IN#011PTR [hostname]._ssh._tcp.local ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 05:34:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011TXT ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 05:34:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011SRV 0 0 22 [hostname].local ; ttl=120] not fitting in legacy unicast packet, dropping. 2024-05-09 06:00:04 [hostname] kernel: mdcmd (85): set md_write_method 1 2024-05-09 06:00:04 [hostname] kernel: 2024-05-09 06:00:04 [hostname] root: Starting Mover 2024-05-09 06:00:04 [hostname] root: Forcing turbo write on 2024-05-09 06:00:04 [hostname] root: ionice -c 2 -n 7 nice -n 5 /usr/local/emhttp/plugins/ca.mover.tuning/age_mover start 15 0 0 '' '' '' '' no 85 '' '' 10 2024-05-09 06:00:04 [hostname] root: Restoring original turbo write mode 2024-05-09 06:00:04 [hostname] kernel: mdcmd (86): set md_write_method auto 2024-05-09 06:00:04 [hostname] kernel: 2024-05-09 06:04:55 [hostname] avahi-daemon[17752]: Record [_ssh._tcp.local#011IN#011PTR [hostname]._ssh._tcp.local ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 06:04:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011TXT ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 06:04:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011SRV 0 0 22 [hostname].local ; ttl=120] not fitting in legacy unicast packet, dropping. 2024-05-09 06:34:51 [hostname] winbindd[17714]: [2024/05/09 06:34:51.676105, 0] ../../source3/winbindd/winbindd_samr.c:71(open_internal_samr_conn) 2024-05-09 06:34:51 [hostname] winbindd[17714]: open_internal_samr_conn: Could not connect to samr pipe: NT_STATUS_CONNECTION_DISCONNECTED 2024-05-09 06:34:56 [hostname] avahi-daemon[17752]: Record [_ssh._tcp.local#011IN#011PTR [hostname]._ssh._tcp.local ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 06:34:56 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011TXT ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 06:34:56 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011SRV 0 0 22 [hostname].local ; ttl=120] not fitting in legacy unicast packet, dropping. 2024-05-09 07:01:30 [hostname] emhttpd: read SMART /dev/sdh 2024-05-09 07:04:55 [hostname] avahi-daemon[17752]: Record [_ssh._tcp.local#011IN#011PTR [hostname]._ssh._tcp.local ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 07:04:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011TXT ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 07:04:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011SRV 0 0 22 [hostname].local ; ttl=120] not fitting in legacy unicast packet, dropping. 2024-05-09 07:33:31 [hostname] emhttpd: spinning down /dev/sdh 2024-05-09 07:34:55 [hostname] avahi-daemon[17752]: Record [_ssh._tcp.local#011IN#011PTR [hostname]._ssh._tcp.local ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 07:34:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011TXT ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 07:34:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011SRV 0 0 22 [hostname].local ; ttl=120] not fitting in legacy unicast packet, dropping. 2024-05-09 08:04:55 [hostname] avahi-daemon[17752]: Record [_ssh._tcp.local#011IN#011PTR [hostname]._ssh._tcp.local ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 08:04:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011TXT ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 08:04:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011SRV 0 0 22 [hostname].local ; ttl=120] not fitting in legacy unicast packet, dropping. 2024-05-09 08:34:55 [hostname] avahi-daemon[17752]: Record [_ssh._tcp.local#011IN#011PTR [hostname]._ssh._tcp.local ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 08:34:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011TXT ; ttl=4500] not fitting in legacy unicast packet, dropping. 2024-05-09 08:34:55 [hostname] avahi-daemon[17752]: Record [[hostname]._ssh._tcp.local#011IN#011SRV 0 0 22 [hostname].local ; ttl=120] not fitting in legacy unicast packet, dropping. serv-x570-diagnostics-20240509-2122.zip
-
Any luck with this? I'm having the same issue. Think it's something off with my smb-extra settings.
-
Has anyone been able to get this to work with an ASROCK RACK X570D4U or X570D4U-2L2T? The previous plugin version had a patch that was supposed to work for these models but it doesn't work with this new plugin. All readings and communication seem to be working but when I do a CONFIGURE for the fans, it only detects ONE of my 5 fans. And control doesn't seem to be working.
-
You're the best! Thank you!
-
In other words, the same performance, regardless which path I use?
-
Yes, I would be very interested! Thanks. I'm wondering what the GUI will show for a pool that I modify in this way? I assume capacity/usage calculations will still work correctly with the additional mirror (I guess the capacity would stay the same).
-
Is there a specific path that I need to reference in order to get the supposed IO performance boost from using exclusive shares? In other words do I need to use the following path: /mnt/pool/exclusive-share Or the following: /mnt/user/exclusive-share Or does it not matter?
-
I know currently if you already have a vdev of mirrors, the unraid GUI will let you add an identical vdev of mirrors striped, increasing your pool capacity (I assume this is raid01 like you mention). I'm just not sure if it will let you do the inverse (add an identical group of striped drives in mirror config (i.e. raid10). I haven't been able to find anyone discuss such a configuration and I'd like to know it's possible before I spend the money on the drives. I was hoping to avoid command line because I'm a noob. But I suppose that can be my last resort.
-
I am currently running two pcie4.0 NVME drives in zfs raid0 for that sweet sweet performance. However, I am worried about the lack of error correction/drive failure protection. If I were to buy 2 more NVME drives, would it be possible to then run the two new drives raid0/stripped and the mirror both sets for drive protection? Please note that I am not asking if you can stripe two sets of mirrors, which I know you can do and easily add mirror groups within raid. I'm asking if it is possible to MIRROR two sets of STRIPED drives. The former gives you the 2X read speeds but doesn't give you the benefit of 2X write speeds, while the later gives you both 2X read speeds and 2X write speeds (theoretically of course). Thanks.
-
Is the new version available in the apps store yet? How do I install otherwise?
-
So if a user is adding multiple identical drives, can I assume that it will generally always make more sense to add a raid-protected pool rather than adding individual drives to the parity-protected array? Thanks so much for the responses, btw. These are super helpful!
-
Awesome, thank you. Would you say there is any difference in the feature set between ZFS protection and File Integrity's protection (blake3)? Or do they both just provide notification of corruption and that's it? Lately, the File Integrity plugin has been very processor intensive when running checks, so I'm wondering if ZFS may be better. Am I correct in assuming ZFS has no "scanning" process and the detection is done automatically? Or is it like the btrfs check which is quite quick? Last thing, so if I have a mirrored or raidz2 pool is it possible to ALSO have it protected under the array parity drive, or is it just like another cache pool?



