




rodan5150
Members
-
Joined
-
Last visited
Everything posted by rodan5150
-
@Delorean since your subnet's address range appears to be 192.168.122.X then you'd want to advertise the route of 192.168.122.0/24 which would be all addresses from 192.168.122.0 - 254
-
First thing, your containers need to have paths mapped like this: Container path: /data Host path: /mnt/user/data/******* I'd get rid of any other path mappings for anything media related, obviously keep the appdata path mappings and such. This is for all of the *arrs that would be manipulating files as well as sabnzbd and qbittorrent. This is so that Docker will treat it as one file system, so that atomic moves can happen. If the paths vary at all i.e. your container path on one is "/data" and on another it is "/data/media" this is seen as a separate file system by Docker, and thus no atomic moves. Your Sonarr and Radarr appear to have superfluous mappings to the same stuff, like your /media. There is no need for this. You just pass the "/data" path per above. That would go for Plex as well for that matter (not for atomic moves, but just for simplicity and consistency sake). If I'm setting this up for someone, I typically delete the default mappings to avoid confusion later. All I ever leave is the "/data" or equivalent. Once you have the correct path passed to the container, you just "drill down" to the proper sub directory within the app itself. e.g. in Plex the container needs to have the host mapping "/data/media" so you can internally within Plex, point the TV library to "/data/media/tv" and the movie library to "/data/media/movies" etc. Make sense? Another tip is to use all lower case, being that linux is case sensitive. TV is different from tv, Movies is different from movies, etc. So it is very easy to make a mistakes with path mappings if you mix case Windows style. For example, your radarr is pointed to a host path of "/mnt/user/data/media/Movies" which probably doesn't exist if you made it as "movies" following the trash guide. Straighten all of that out and see if it works. If you have directory permission errors, you can try running the "Docker Safe New Perms" tools under Tools. Hope this helps, and good luck!
-
Good news, I just reset everything DNS related, set it all back up from scratch to exact same settings and it is working now. Not sure if there was a fluke glitch or what. Nothing else on the network had DNS problems. Both of my unraid servers run 6.12.3 and only one had the issue.
-
I'm having the same issue with 1 out of 2 servers. I tried the exact above steps myself to no avail.
-
I would make sure that you have all of the PSU connections properly seated on your mobo, since that is the only thing you changed. That is where I’d start anyway, since you know the nvme drive is working.
-
Look into Photoprism, it will import and resize photos I believe. I do not use that functionality, but I've seen the options for it to do that.
-
Thanks again for your help. No rush on this, I'm primarily a Plex user, I'm just in testing phase with Jellyfin at this point. Looking to have a backup option for Plex. I've been a Plex user for a decade or so, and I get worried about the direction they are headed in sometimes. Plus, I love to support the open source community, so Jellyfin makes a lot of sense to me vs Emby.
-
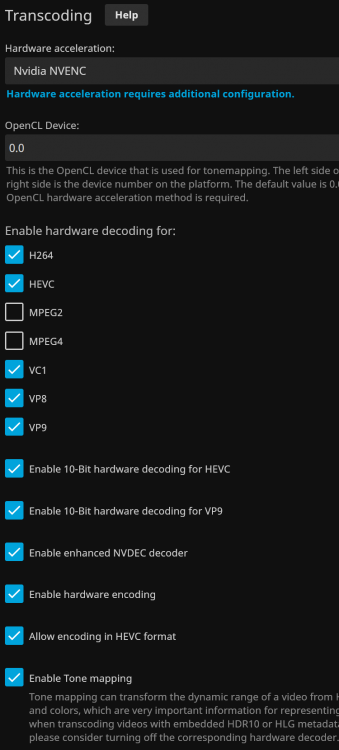
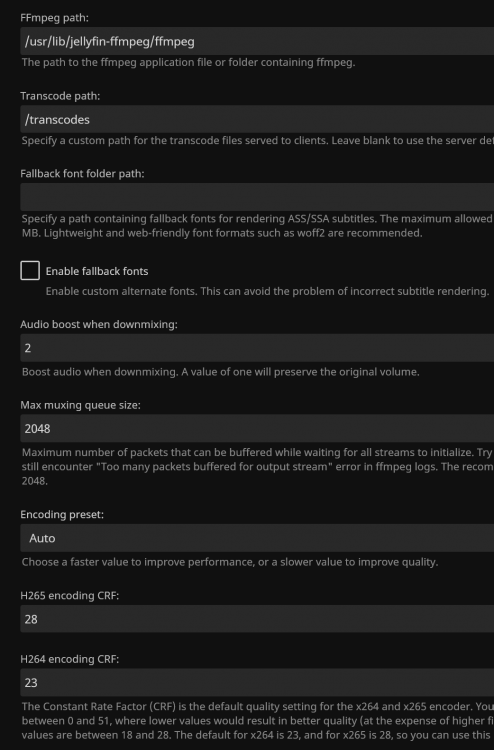
Not sure of the decode/encode difference between P400 and T400, that may be a factor. But no, I just have it default. I've attached screen shots. Thanks for the quick reply, you are a great asset to this community!

-
Anyone have luck with tone mapping using a Quadro P400? Hardware transcoding seems to work fine as long as I disable tone mapping. It would be nice to have tone mapping, but obviously not a deal breaker. Just a slight annoyance since my 4K HDR content looks pretty bad if it is transcoded without tone mapping.
-
I assume you are doing a file transfer and the speed is dropping off? I do not have Mellanox cards, but I do have the same Mikrotik switch. I have no issues sustained reads/writes, as long as the share is set to use cache, which are both NVME as in your setup. For me to get max speed, I have to use an MTU of 9000 for both machines. The fact that your speed is dropping after a period of time, tells me some sort of buffer is being filled up, would be my guess. Have you done testing with iperf3? You could run a test that is longer than 30s or whatever the time your file transfer drops off. That would prove out that its not the NICs or the switch, since it would run entirely from ram. If you aren't familiar with iperf3, the nerdtools plugin for unraid has iperf3 as one of the included packages. Once you have it installed, you'd run "iperf3 -s" on your unraid box. You also need iperf3 for windows of course, then you'd do something like "iperf3 -c <ip of unraid box> -t 60 -P 10" for 60 seconds and 10 streams. Adjust accordingly. To test the other direction add a "-R" to the end, which will just reverse the flow so that your windows box becomes the server. Other things to be sure of are cabling and infrastructure. Are you using copper, fiber, DAC cables? If copper, what type? CAT6, CAT6A? how long are the runs? Lots of factors could come into play. I always start with iperf though. If it tells me I'm good over a particular link, and then I go to do a test file transfer and it is much slower usually a misconfig (not using a share that is assigned to the NVME) or a disk performance issue (transferring a ton of small files like a Plex database kills performance, even on NVME drives). Hope this helps.
-
I was close to doing this, but I figured I'd tough it out and give 6.9.x a shot. So far, the br2 network for my containers I want to have their own IP, has been working well. No call traces yet and certainly no kernel panics. Of course, it is barely over a week out since I made that change. If I can say this a month out, then I will consider it good to go.
-
Yeah, I reverted the change of the C-states back to default. Only thing I have set now is the power supply idle control. So far, what has me "fixed" is I've move all of my docker containers that needed a custom network (static IP) over to a separate NIC (br2). I also disabled vlans in Unraid as well, since I wasn't using them anymore. No kernel panics or anything, yet anyway. It's been over a week now. Fingers are crossed!
-
thanks for the Reply JorgeB. I'm going to give the second NIC assignment a shot. I had been trying to do all of this through a single 10Gbe connection. I've got several 1Gbe ports open on my main switch, so its not a huge deal to just assign the containers to a second NIC. With any luck, this will solve it.
-
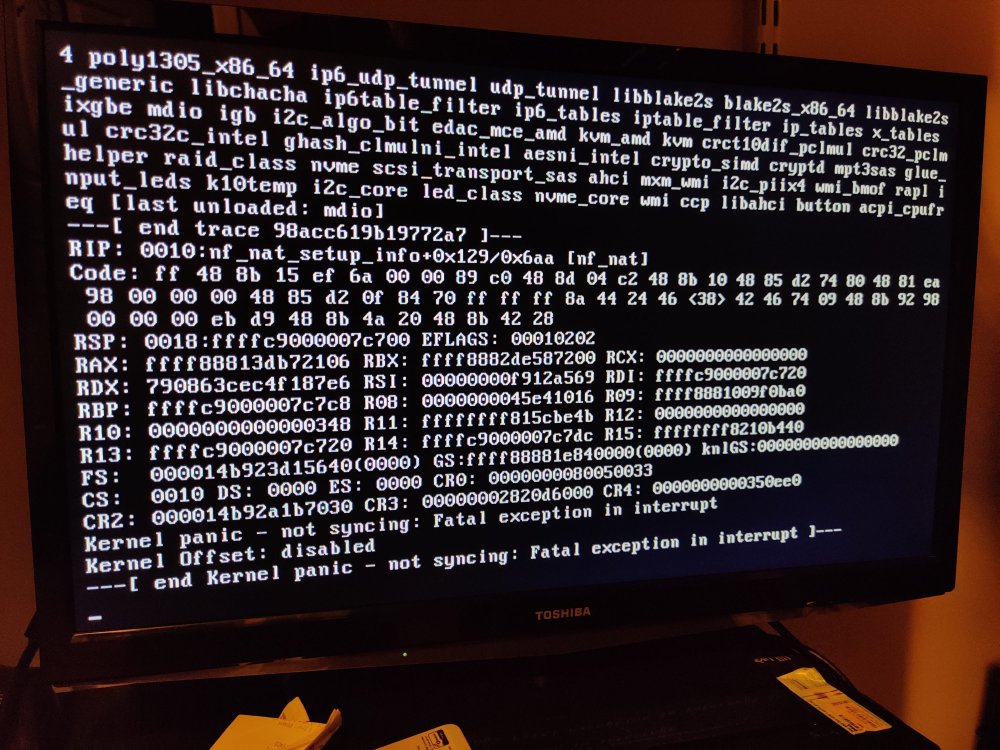
Bad news. So kernel panic is back. I thought I had figured it out by moving everything from br0 to br0.x but it looks like there has to be another issue going on, causing the call traces that ultimately end in a kernel panic. What else could I be missing? Darkhelmet syslog 5-21.txt
-
That's exactly where it was. I enabled the C-states option, and then set the idle current to typical instead of low. I've also created a Docker specific vlan, and moved all of the br0 over to br0.x so hopefully that will keep my call traces and kernel panics at bay. I will update if anything changes. So far so good, but it has only been about 18 hours or so. Longest it has gone in the past was 10ish days. So if I can hit 2 weeks+ I'll consider it a win.
-
Awesome, thanks for letting me know. I will revert the global C-state setting, and dig around and see if I can find the idle current setting.
-
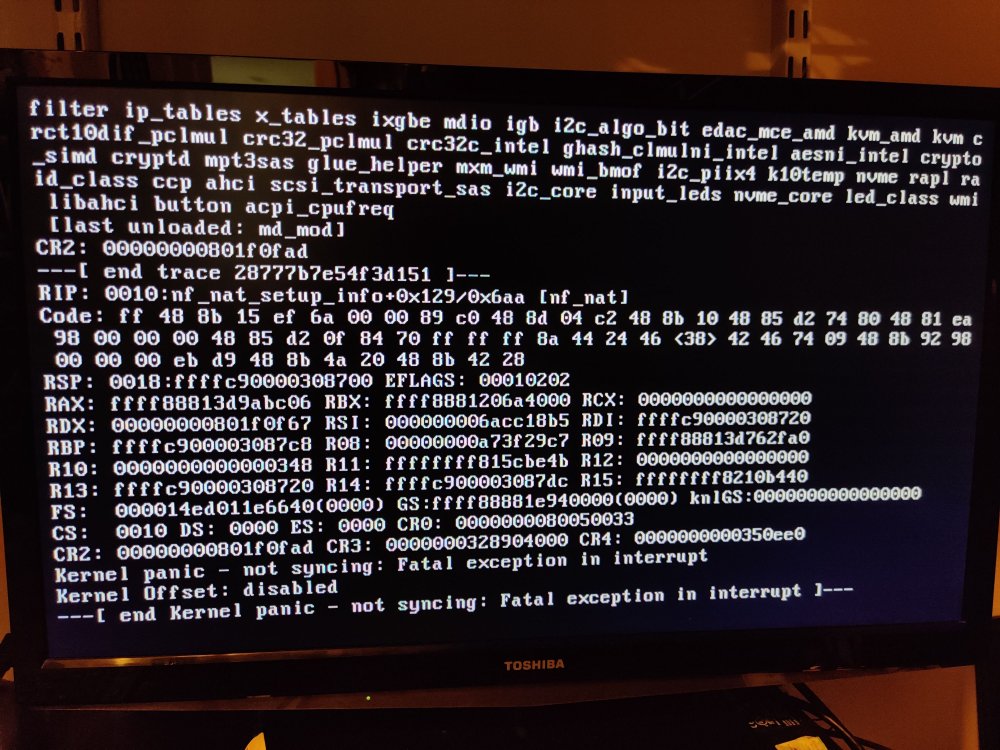
Hello all, I've been fighting a few issues since I "upgraded" to a Ryzen based system from an old dual Xeon Dell T410. New build is a Ryzen 3600, on a B450 chipset. It was getting unresponsive after a few days, and that seems to have gone away after disabling global C-states in the BIOS. The latest issue is I get a kernel panic after a week or so of uptime. I have syslog enabled, and was able to get it just before the panic. I also got a pic of the screen before I rebooted that tells the rest of the story after the syslog dropped. Looks like network related, maybe mac-vlan? Definitely a call trace happens, but not sure what can be done about it. thanks for any help in advance! Ross syslog 4-20-21.txt
-
I just installed the plugin for the first time. It will not let me sign in, I just get the perpetual spectra wave of death, regardless of browser or pop-up blocker settings. If it is down for others, that may explain it. I still have access to my server, so no big deal.
-
No worries. If you want budget, then I'd get a GTX 1050 or a Quadro P400 for Plex transcoding. I run a P400 I got off e-bay for like $70 over a year ago that works very well, no external power required.
-
I don't believe a GT730 will work. Not listed on the nvidia NVENC support matrix. https://developer.nvidia.com/video-encode-and-decode-gpu-support-matrix-new
-
figured so, thanks for the reply Squid!
-
Was Troubleshooting Mode removed? I'm not seeing where to activate it. Of course, I may have missed something! edit: I did find a "mirror syslog to flash" option under Syslog Server, Did this replace troubleshooting mode? I think this will probobaly do what I need. I'm currently chasing random lockups/partial crashes where I lose network access and am having issues with it writing diagnostics to flash via console commands.
-
Your problem may be due to the /transcode path not being something like /tmp if you wanted to transcode to ram or /tmp/PlexRamScratch if you use the size limited ram disk script as posted earlier in the thread. Since /transcode does not exist as a an actual directory in your setup most likely, I believe Plex is defaulting to transcoding within the docker image and that is why it is filling up.







