

kysdaddy
-
Posts
197 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by kysdaddy
-
Help: Drives are not recognized by Unraid
kysdaddy replied to ranukaj's topic in Storage Devices and Controllers
Hello all, I recently passed my server on to another newbie. He set up his own unraid disk. He is using old drives of mine. He has the MD1000 as well but does not want to hook it up to begin with. I beleive that it was a perk 200 that I installed to communicate with the drive bay. He has not removed that card. he does not have a vga cord and is trying to use a vga to hdmi cord, but he is getting 0 video. he can log into idrac and get the system booted but it is stopping on hit f1 or f2 nothing apears in unassigned drives. Any suggestions on getting the drives recognized would be great stella-diagnostics-20230217-1322.zip -
You are correct, my mistake was not stopping docker and VM. The good news is my roundabout path did reach the destination and all is running properly now. Thanks again. Chas
-
Sorry, I had ran out of patience before your reply (patience with my system, not your communication) I think that I know what I was doing wrong, and I hope that I am moving the right way now. Docker and VMS were running on my system while mover was running, unless I am mistaken that requiered mover to check each and every file to see if it was in use before moving it. I'm not sure if it could or would move it if it was in use but I'm pretty sure that this check would slow down mover. I ran Mover Stop. Set all of my Shares to the yes: 1tb which is where the appdata was before I started this fiasco. I then erased the data in the 250gb share pool, unraid then asked me to format the drives 8^) I formatted and Unraid recreated the 240gb pool. Next I stopped docker and my vm, then set both docker and vms to no. Started mover again. I think that everything is working right now, if I go to shares and click on compute on my appdata share I see it moving to the array. Thank you for the assistance, I will update later if all works well, or if not I'll be back asking for help again. Chas
-
Well 30 hours later and Mover is still running, seems like there is an issue here, should I stop mover and try something different? Chas
-
So If I read this right, my error was changing the assigned cache pool before I change the cache setting to yes. I told mover to look in a share that did not have files for the files. Unfortunately I do not know the steps to correct this. Currently mover is running. I have appdata folders on both pools, they have different information in them (not sure how I did that) Pool# 2 appdata folder reflects dockers that I am currently running (set to auto start) Pool# 2 only has appdata on it (as of now, mover is running) pool # 1 is all of the dockers that are installed including ones that are not currently in use. Pool# 1 has all shares including appdata Not sure if it is possible to screw this up more than I have already. Pool # 1 Pool #2 Shares
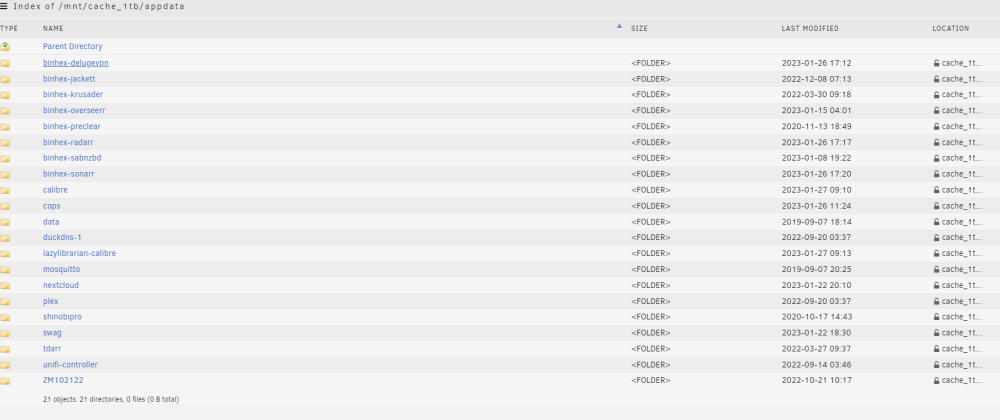
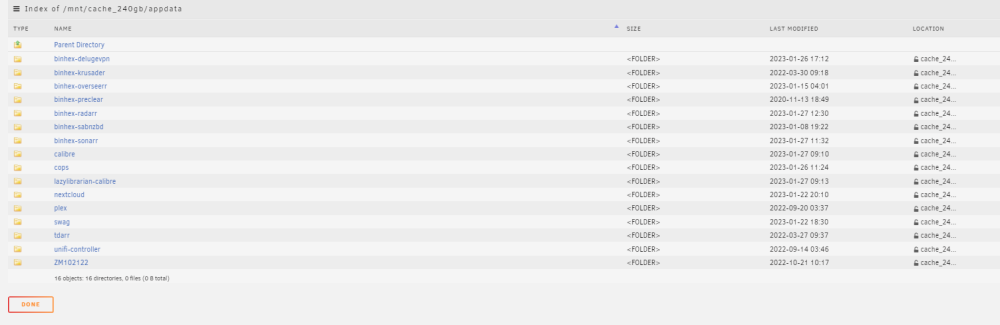
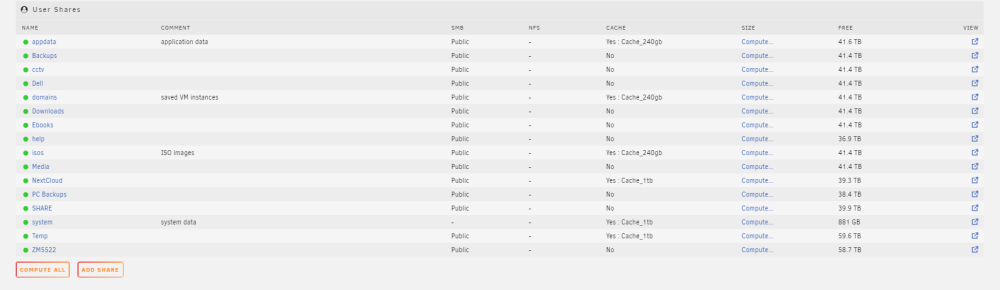


-
I am still getting these warnings in common problems. Should I have moved files manually?
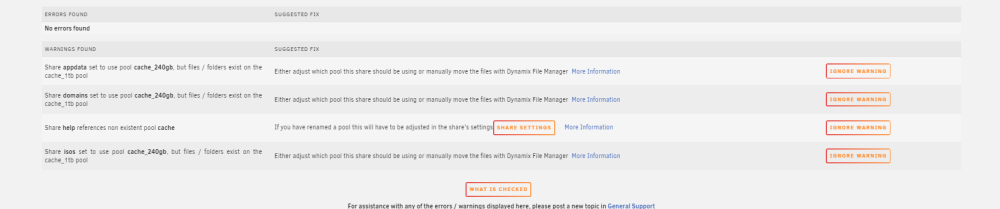
-
I'm thinking that my issue was because I didn't stop and start the array. I stopped mover. double checked that all shares that use the cache, were changed from prefer to yes. stopped the array, restarted the array and started mover. We will see if this works Chas
-
Sorry the 1tb drive has 121 gb not 1.21gb
-
Hello all, O am looking for a bit of direction here. I made a major server upgrade over the past week. I upgraded from a dell 710 to a supermicro x10, increased my parity drives to 12tb, my cache pool to 1tb. The issue was timing or project management. My goal is to have to parity protected cache pools , a 1 tb pool and a 240gb pool. I want to use the 1 tb for downloads and temp files TDAR and plex. and the 240 for everything else. My mistake was starting the system with only the 1tb. I think that I have fouled things up. I added the second pool yesterday. changed the cache that the shares pointed to and ran mover. Nothing happened it ran for under 10 minutes. My next mistake (possibly) was that I set the shares to yes, expecting the data to be pulled of "both" pools and moved to the array, and ran mover. 12 hrs later mover is still running, no change in the 1tb drive it is still showing 1.21gb used and the 240 went from 40mb to 1.06gb used. I am showing reads and writes but do not think that this is working properly. Thoughts diag attached. Thanks Chas tower-diagnostics-20230127-0823.zip
-
I just found two disabled disks on my system, any chance that these are same and can be re added to the system, I have 2 parity drives. Thanks for any help Chas tower-diagnostics-20220717-2215.zip
-
I have found that once the data base craps the bed your best bet is to rebuild from scratch. That being said, once you have rebuilt, shut down ZM and copy the entire appdata folder to another drive. Now when the database fails, damn near every time the system shuts down unclean. All I have to do is copy the appdata folder back to the original folder. All of my cameras come back with a restart. If you copy the folder without shutting ZM down it doesn't work. Chas
-
Hello, I am sorry to keep beating this horse, but it is so frustrating. I love Zoneminder. I just can't understand why the database is so fragile it seems every time that my server has a bad shutdown, I lose the database and have to completely reinstall. I get it I should shut it down correctly, I really do get it but sometimes *(%^%* happens. Most recently I was using Tdarr to transition to h265 and my cache filled up, couldn't do a clean shutdown. rebooted, 20 dockers still worked no issues, Plex all of the arr's, calibre, my homeassistant VM all worked fine, Zoneminder toast! That was 2 weeks ago, I decided to try shinobi again, don't get me wrong, there are some things in shinobi that I love, the reduced resource use for one, but I still like Zoneminder more. Yesterday I reinstalled and set ZM up again, but used my head. I set it up then shut it down and copied the app data folder to another drive. About an hour ago, a storm knocked my power out. Guess what? Yep everything came right back except ZM. This time it wasn't too bad, pasted the copied files to zm app data, overwrote the existing and ZM started. The old images aren't seen by Zm but because it was only a day, easy to delete. OK I know this has been quite a rant, my question is this. Is there something that I am missing, is the data base really this fragile? If I used a separate database, would it help? CA Backup and restore only allows one instance per machine, correct, IOW I backup and restore all or some but I can't set up one session to backup ZM and another to do all others Correct? Is there a script anywhere that shuts down a specific docker, and copies its app data to a mapped location? Rant complete. Thanks for any answers provided.
-
[Support] spaceinvaderone - Shinobi Pro
kysdaddy replied to SpaceInvaderOne's topic in Docker Containers
I was told the same thing on Discord, monitors simply go black every now and again "Reconnect stream turns red but does nothing if I click it, refreshing the screen brings it back. I also have an issue with the "Monitor Group" function, I had two groups set up and wanted to change them, I deleted the old groups but can't seem to get new ones working. I love the limited resource use, and would love the app if I could figure out how to enlarge a monitor view without having to back up and select individual monitor. Any assistance would be appreciated. Chas -
Sorry for the newbie question. I have installed Tdarr and the Tdarr node on my unraid server, it seems to be working. I am concerned as after the first few files finished (while the Quadro p2000 was still transcoding other files (Set to 3)) when I tried to play the new file on my fire tv cube (6.72) it did not play properly. Is that because the fire tv cube does not have a codec to play H265 ? and the p2000 was overloaded transcoding other files? If that is the case is there a way to reduce file size using H264? Also is there a way to pause Tdarr other than pausing the docker, when I pause the docker am I damaging the firles that Tdarr is working on? Thanks
-
Data rebuild @3515 days New disk showing as DISK_INVALID in diag
kysdaddy replied to kysdaddy's topic in General Support
Thank you both for the input. I think that I will be adding a second parity after I get this back up and running, I think. I'm guessing that I need to wait before adding but I am usually wrong Should I stop and start this again with a second parity? Can I do that? Chas -
Data rebuild @3515 days New disk showing as DISK_INVALID in diag
kysdaddy replied to kysdaddy's topic in General Support
So if I am hearing this correctly, I should stop the clearing script/process. and 1. Make sure that the drive or drives you are removing have been removed from any inclusions or exclusions for all shares, including in the global share settings. Shares should be changed from the default of "All" to "Include". This include list should contain only the drives that will be retained. 2. Make sure you have a copy of your array assignments, especially the parity drive. You may need this list if the "Retain current configuration" option doesn't work correctly 3. Stop the array (if it is started) 4. Go to Tools then New Config 5. Click on the Retain current configuration box (says None at first), click on the box for All, then click on close 6. Click on the box for Yes I want to do this, then click Apply then Done 7. Return to the Main page, and check all assignments. If any are missing, correct them. Unassign the drive(s) you are removing. Double check all of the assignments, especially the parity drive(s)! 8. Do not click the check box for Parity is already valid; make sure it is NOT checked; parity is not valid now and won't be until the parity build completes 9. Start the array to commit the changes; system is usable now, but it will take a long time rebuilding parity Correct? -
Data rebuild @3515 days New disk showing as DISK_INVALID in diag
kysdaddy replied to kysdaddy's topic in General Support
JorgeB, I was hoping that I could get a bit of information/direction from you. I currently have 19 disks in my array including my parity and one of the disks is missing Failed last week.. I only have one parity. When I try to add the 20th disk to the array to replace the missing disk, is when I get the 3515 days to rebuild. Disk#23 is now showing as failed, but there is nothing on it. I am currently trying The "Clear Drive Then Remove Drive" Method, to shrink the array. https://wiki.unraid.net/Shrink_array Disk 23 is about 6 hours from zeroing out.. My question is am I better to do this or to simply remove 22 there was like two movies on it before it died and 23 the rebuild the parity from scratch or continue what I am doing remove 23, tell the system that the parity is good and then replace 22. Or a I way off base and going the complete wrong direction. I thought about adding a second parity but can because of the 3515 day issue. Any suggestions? Chas -
Data rebuild @3515 days New disk showing as DISK_INVALID in diag
kysdaddy replied to kysdaddy's topic in General Support
Also disk 22 and 23 have nothing on them, they were, just added, but then there were problems -
Data rebuild @3515 days New disk showing as DISK_INVALID in diag
kysdaddy replied to kysdaddy's topic in General Support
It says errors occurred posted diagnostic. Chas tower-diagnostics-20220319-1103.zip
-
Data rebuild @3515 days New disk showing as DISK_INVALID in diag
kysdaddy replied to kysdaddy's topic in General Support
@JorgeB I have run into another problem on my array and was hoping that you could help as you have in the past. See above. I have started an extended self-test on drive 23 as suggested, I will post the results when it finishes along with a new diagnostic. Chas -
Data rebuild @3515 days New disk showing as DISK_INVALID in diag
kysdaddy replied to kysdaddy's topic in General Support
JorgeB I hope that this isn't in bad form, but you've helped me so much before, I was hoping that you could tell me what I've messed up this time. I am trying to replace a disk but am getting extremely slow rebuild times. Up to 3315 days at 25KBS. I stopped the rebuild after pulling a diagnostic. I pulled the new disk out of the array and restarted with the disk being emulated and pulled a second diagnostic. I'm not sure what I have done wrong, but I'm sure that someone much smarter than me at this stuff will see my error. Thanks in advance for any assistance. tower-diagnostics-20220318-2010.zip tower-diagnostics-20220318-1959.zip -
Hello I am trying to replace a disk but am getting extremely slow rebuild times. Up to 3315 days at 25KBS. I stopped the rebuild after pulling a diagnostic. I pulled the new disk out of the array and restarted with the disk being emulated and pulled a second diagnostic. I'm not sure what I have done wrong, but I'm sure that someone much smarter than me at this stuff will see my error. Thanks in advance for any assistance. JorgeB, if you're out there bail me out again please. Chas tower-diagnostics-20220318-1959.zip tower-diagnostics-20220318-2010.zip
-
I'm remote, I told the system to reboot, and checked back later, perhaps it failed to do so. Trying again. I guess that it didn't reboot the first time, it is back and working, the VM was named right as my Homeassistant is working too. Thank you for your help. Chas
-
Hello, I just lost my VM with a Libvirt Service failed to start. error. I am a complete noob at VM, I have been running Homeassistant as a docker for years, moved to the VM HA OS about 2 months ago, loved it. Last night it died, I am sure that it wasn't a natural death, that I did something stupid and killed it accidently. I am posting my diagnostic. BTW I just tried to restore my VM from a backup but neglected to write down the format of the name, that was done after the Libvirt Service failed to start. so it is not the cause. However if the format is not accurate please feel free to correct my stupidity. Than you Chas tower-diagnostics-20220308-0730.zip
-
I have reoccurring read errors on two disks, this question seems kind of rhetorical but do I need to replace them? I guess the better question would be is there anything that can be done to avoid repair them? Thanks for any suggestions Diagnostic is attached. Chas tower-diagnostics-20220228-0802.zip






